本期内容 :
- Spark Streaming数据清理原理和现象
- Spark Streaming数据清理代码解析
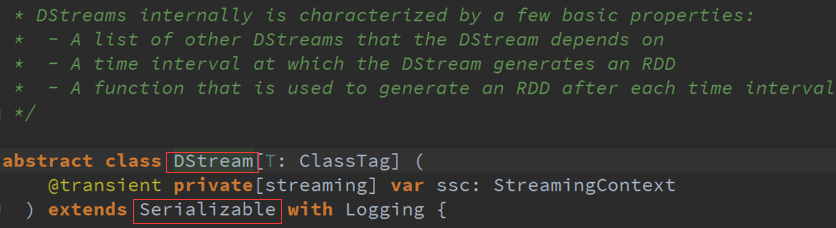
Spark Streaming一直在运行的,在计算的过程中会不断的产生RDD ,如每秒钟产生一个BachDuration同时也会产生RDD,
在这个过程中除了基本的RDD外还有累加器、广播变量等,对应Spark Streaming也有自己的对象、源数据及数据清理机制,
在运行中每个BachDuration会触发了Job ,由于会自动产生对象、数据及源数据等运行完成后肯定要自动进行回收 。
一、 数据源 :
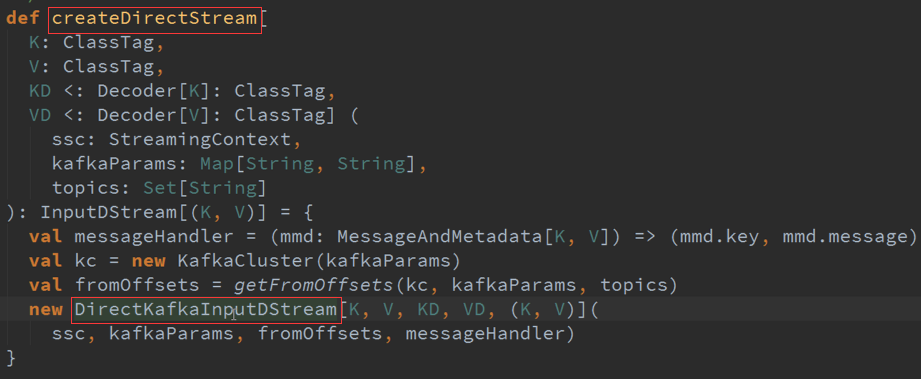
创建Kafka ,源数据的操作。

二、 处理数据的输出 :
从研究其生命周期的话,需要进行下一步 ,输出进行考虑,ForEachRDD属于Materialized(物化),物化也就是存储到外部设备上。
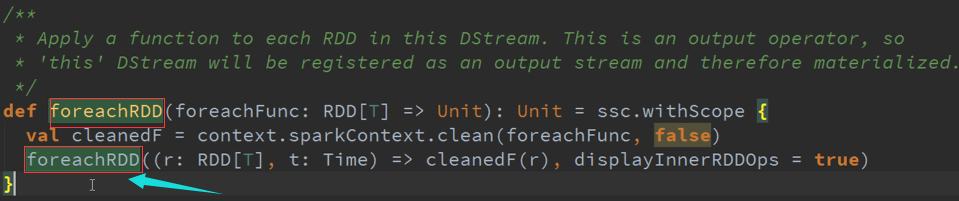

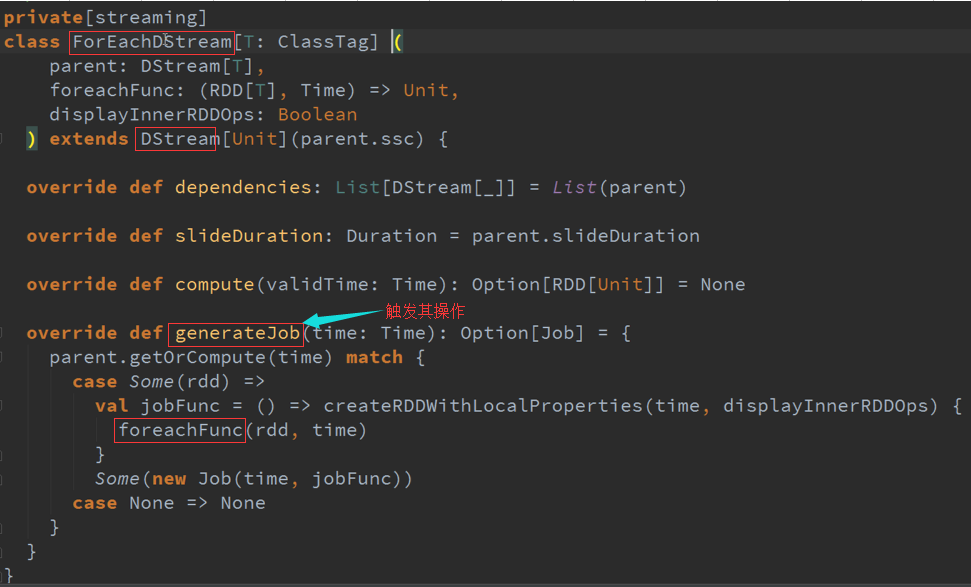
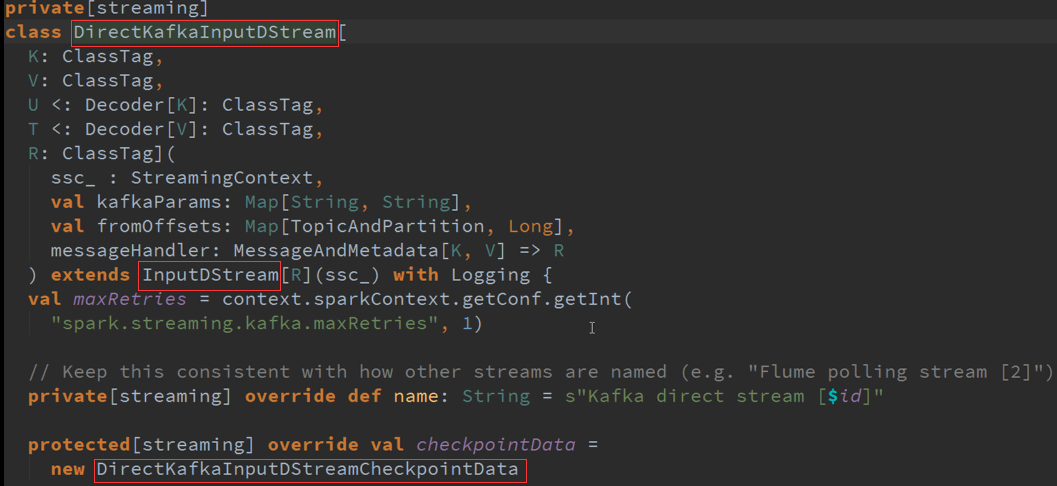
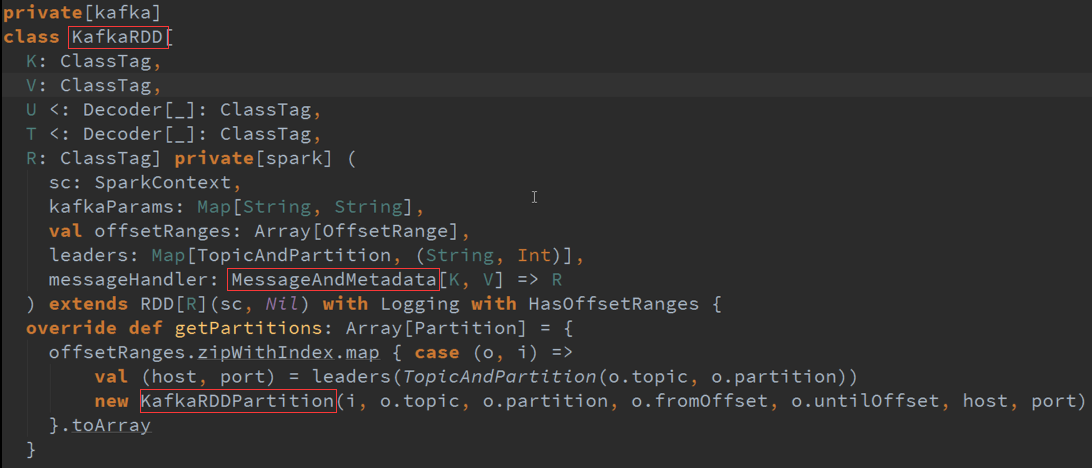
基于数据来源Kafka,DStreams随着时间的进行会不断的自己的内存数据结构GeneratedRDD中维护一个HashMap ,这个HashMap的时间窗口的RDD的实例,
按照BachDuration来存储这个RDD及删除RDD。

内存缓存结构,有时会调用Cache的操作,其实是对DStreams进行标记,指定StorageLevel最终作用于RDD ,也会有相关的Cache操作。

三、 JobGenerator 清理的过程 :
不断循环的产生事件(消息循环器) :
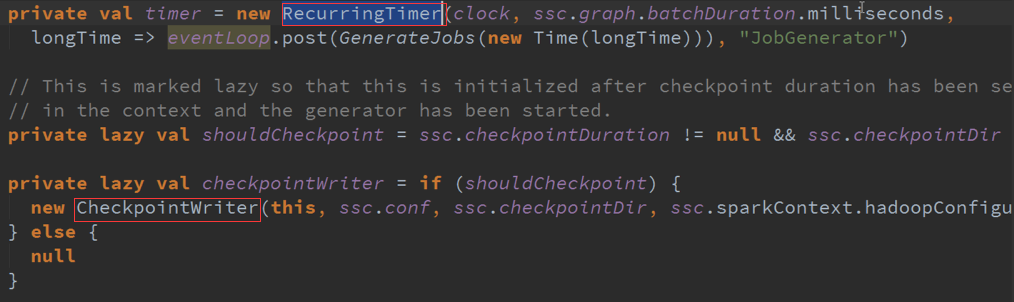
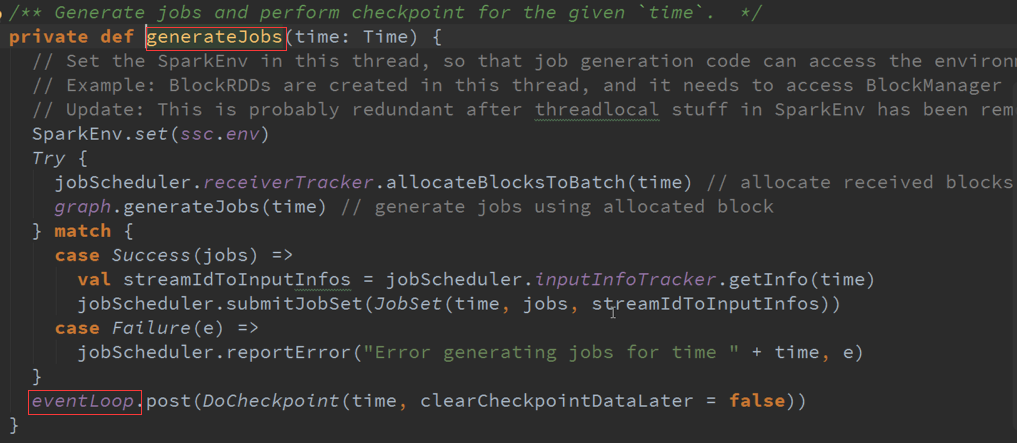
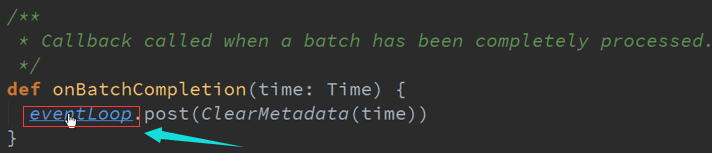

事件触发以时间为单位:
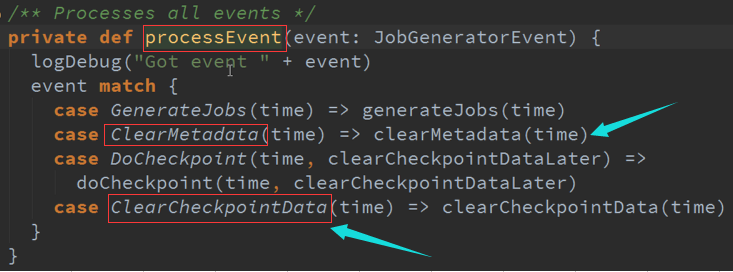
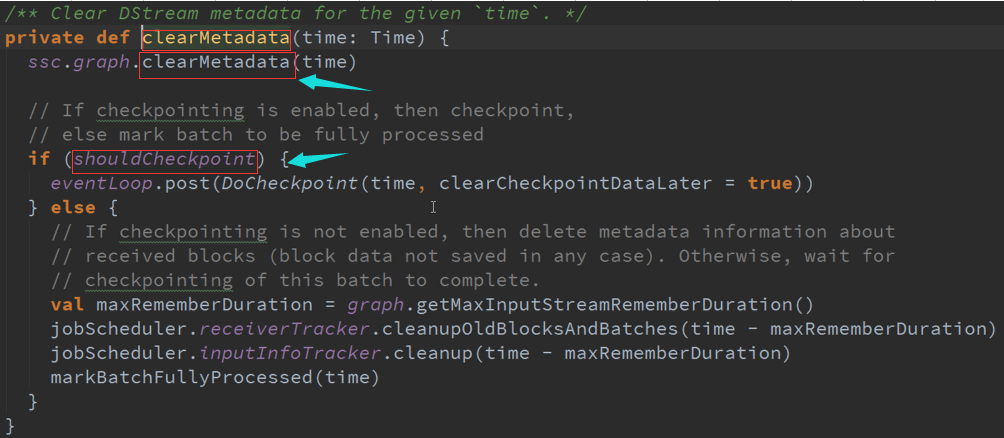

Spark Streaming在每次一个作业处理完成之后,也就是每个BachDuration处理完成之后都会进行清理,首先是输出的DStreams进行清理,然后对他的依赖关系进行清理,
清理的时候,默认下是会清理RDD的数据等相关的部分,及Metadata元数据的清理。