HDFS集群优化篇
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
一.操作系统级别优化
1>.优化文件系统(推荐使用EXT4和XFS文件系统,相比较而言,更推荐后者,因为XFS已经帮我们做了大量的优化。为服务器存储目录挂载时添加noatime属性)
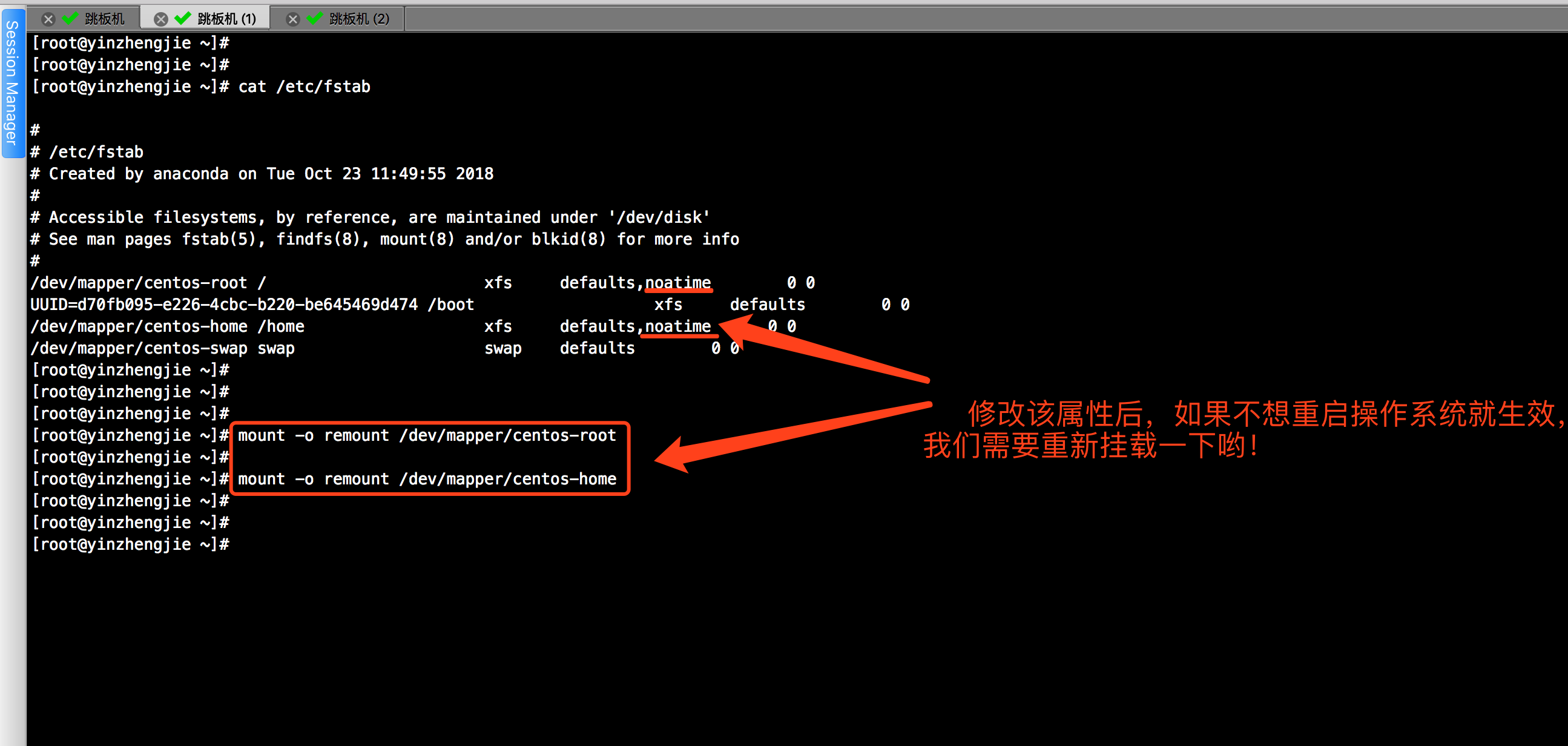
2>.预读缓冲
blockdev 工具允许从命令行调用区块设备控制程序,常用参数如下: --getra 读取预读值 --getfra 读取文件系统预读 --setfra FSREADAHEAD 设置文件系统预读 --setra READAHEAD 设置设备预读 --getra 读取设备的预读值 --setbsz BLOCKSIZE 在文件描述符打开块设备的时候设置块大小 --getioopt 读取设备优化IO大小 --getiomin 读取设备最小IO大小 -–setro 设置设备为只读 -–getro 读取设备是否为只读(成功为1,0则为可读写) -–setrw 设置设别为可读写 -–getss 打印设备的扇区大小也叫逻辑块大小,通常是512 --getpbsz 读取设备物理块大小,通常是4096 --getbsz 读取设备块大小,通常是4096 -–getsize(-getsz) 打印设备的容量,按照一个扇区512个字节计算 --getsize64 打印设备的容量,以字节为单位显示 -–setra N 设置预读扇区(512字节)为N个.Set readahead to N 512-byte sectors. -–getra 打印readahead(预读扇区) -–flushbufs 刷新缓冲 -–rereadpt 重读分区表。
我们可以将默认的预读值(256 sectors,128KB)调大,具体操作如下:

3>.放弃RAID和LVM磁盘管理方式,选用JBOD
不使用RAID
应避免在TaskTracker和DataNode所在的节点上进行RAID。RAID为保证数据可靠性,根据类型的不同会做一些额外的操作,HDFS有自己的备份机制,无需使用RAID来保证数据的高可用性。
不使用LVM
LVM是建立在磁盘和分区之上的逻辑层,将Linux文件系统建立在LVM之上,可实现灵活的磁盘分区管理能力。DataNode上的数据主要用于批量的读写,不需要这种特性,建议将每个磁盘单独分区,分别挂载到不同的存储目录下,从而使得数据跨磁盘分布,不同数据块的读操作可并行执行,有助于提升读性能。
JBOD
JBOD是在一个底板上安装的带有多个磁盘驱动器的存储设备,JBOD没有使用前端逻辑来管理磁盘数据,每个磁盘可实现独立并行的寻址。将DataNode部署在配置JBOD设备的服务器上可提高DataNode性能。
4>.内存调优
避免使用swap分区,将Hadoop守护进程的数据交换到磁盘的行为可能会导致操作超时。温馨提示,避免使用swap分区并不意味着就不会使用swap分区,而是通过配置降低swap使用的可能性。详情请参考:https://www.cnblogs.com/yinzhengjie/p/9994207.html。
5>.调整内存分配策略
6>.网络参数调优
详情请参考:https://www.cnblogs.com/yinzhengjie/p/9995756.html。
二.HDFS集群性能优化
1>.归档
存档是用来备份的时候标识用的,说白就是做个标记,表示这个文档在上次备份之后有没有被修改过,比如当月1号,你给全盘做了一次备份,那么所有的文档的存档属性都会被清除,表示备份过了。此后,如果你修改了某个文件,那么这个文件的存档属性就会被加上。当几天后,你再做“增量”备份时候,系统就会只备份那些具有“存档”属性的文件 每个文件均按块方式存储,每个块的元数据存储在namenode的内存中,因此hadoop存储小文件会非常低效。因为大量的小文件会耗尽namenode中的大部分内存(文件大小为5kb,产生的元数据为150kb,得不偿失)。一个1MB的文件以大小为128MB的块存储,使用的是1MB的磁盘空间,而不是128MB。 Hadoop存档文件或HAR文件,是一个更高效的文件存档工具,它将文件存入HDFS块,在减少namenode内存使用的同时,允许对文件进行透明的访问。具体说来,Hadoop存档文件可以用作MapReduce的输入。 Hdfs归档相当于把所有文件归档在一个文件夹里面了,该文件夹以.har命名的。当有很多的小文件时,可以通过归档来解决: 归档指令: Hadoop archive–archiveName myhar.har –p /user/Ubuntu /user/my 【查看归档】 Hdfs dfs –lsrhar:///user/my/myhar.har 【解归档】 Hdfs dfs –cphar:///user/my/my.har /user/your
2>.压缩
三.HDFS集群配置优化
HDFS提供了十分丰富的配置选项,几乎每个HDFS配置项都具有默认值,一些涉及性能的配置项的默认值一般都偏于保守。根据业务需求和服务器配置合理设置这些选项可以有效提高HDFS的性能。我的集群调优针对的是配置较高的服务器(我的HDFS集群配置是:12*8T硬盘,32core,128G内存空间。)
1>.dfs.namenode.handler.count
NameNode中用于处理RPC调用的线程数,默认为10。对于较大的集群和配置较好的服务器,可适当增加这个数值来提升NameNode RPC服务的并发度。
服务线程个数,调大一些,一般原则是将其设置为集群大小的自然对数乘以20,即20logN,N为集群大小。下图是CDH的配置参数:

2>.dfs.datanode.handler.count
DataNode中用于处理RPC调用的线程数,默认为3。可适当增加这个数值来提升DataNode RPC服务的并发度(推荐值:20)。 注意:线程数的提高将增加DataNode的内存需求,因此,不宜过度调整这个数值。 
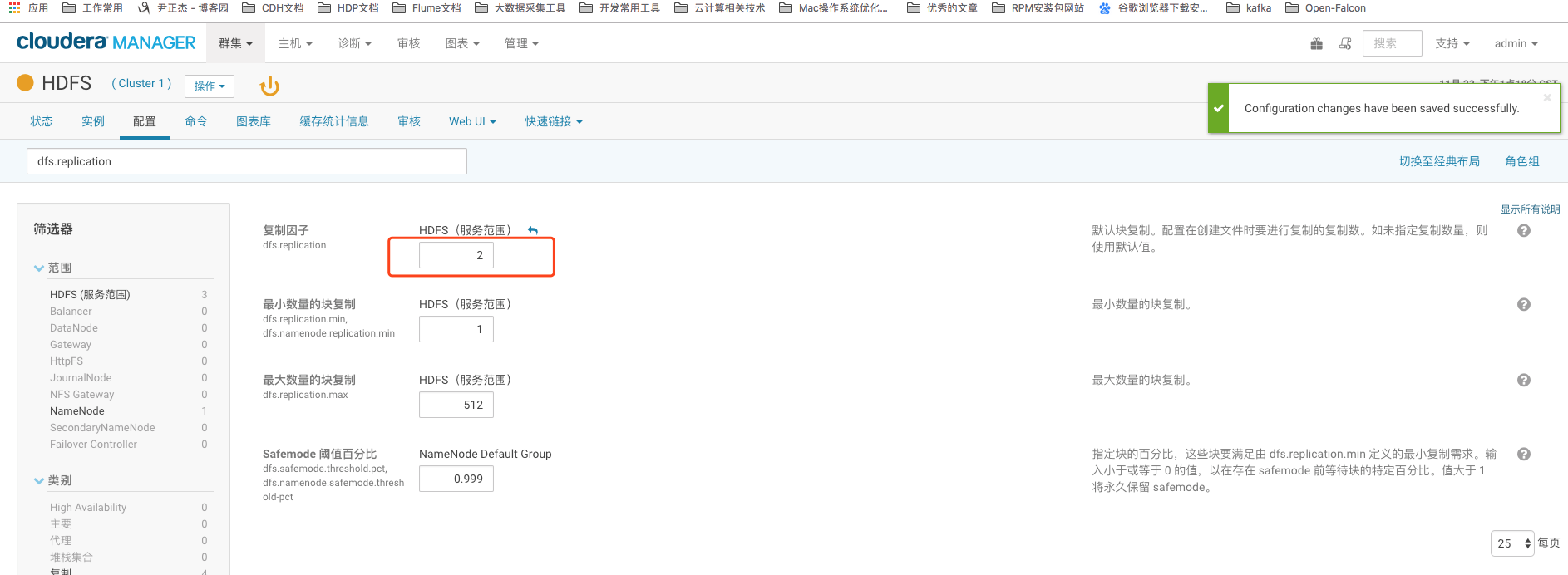
3>.dfs.replication
数据块的备份数,也有人叫复制因子。默认值为3,对于一些重要数据,可适当增加备份数。这个得根据你的集群容量和数据的重要性来考虑,如果数据不是很重要的话,你可以设置成1份,如果数据非常重要的话,你可以配置为5份,我这里推荐值为:2。并不是说你副本数配置越高数据就越丢失不了(副本数越多,只是存放同一份数据的机器运行宕机的个数为N-1(这里的N是副本数),当然如果有必要的话,你也可以考虑一下机甲感知,从而减少同时宕机的概率。),只不过你副本数存储的越多,那么你的集群存储的数据量也会收到相应的影响。他们是成反比的。
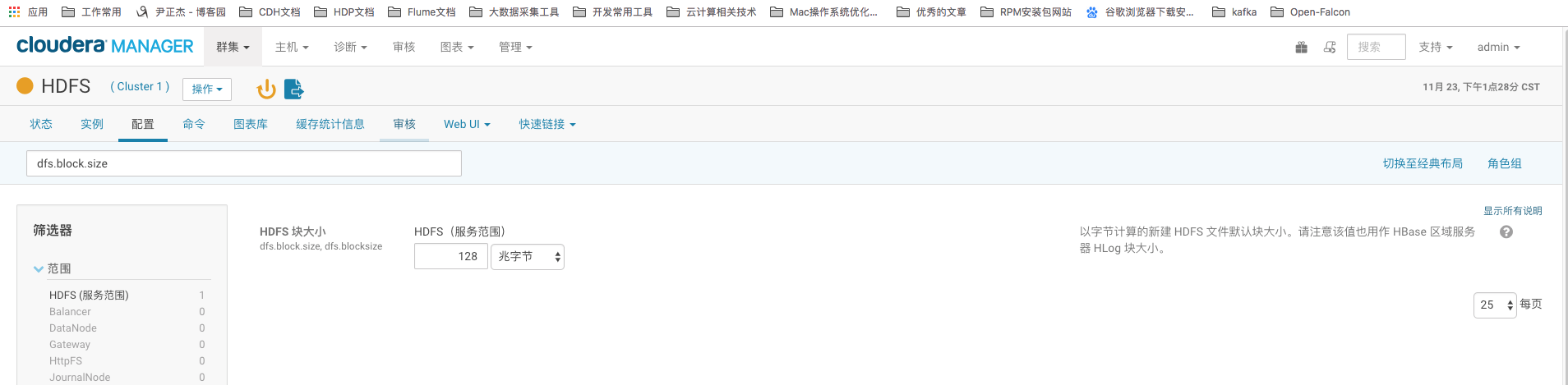
4>.dfs.block.size
HDFS数据块的大小,Hadoop1.x版本默认值为64M,Hadoop2.x版本默认值是128M。数据块设置太小会增加NameNode的压力。数据块设置过大会增加定位数据的时间。这个值跟你的磁盘转速有关,我之前在的博客里有解释为什么是128M,其实这个跟磁盘的转速有关。我们可以自定义这个块大小,考虑2个因素,第一,查看你的集群文件大致范围都是多大?如果文件基本上都是64M~128M左右的话,建议你不要修改。如果大部分文件都在200M~256M之间的话,你可以将配置块大小改为256,当然你也得考虑你的磁盘读写性能。
5>.dfs.datanode.data.dir
HDFS数据存储目录。将数据存储分布在各个磁盘上可充分利用节点的I/O读写性能。因此在实际生产环境中,这就是为什么我们将磁盘不选择RAID和LVM,而非要选择JBOD的原因。推荐设置多个磁盘目录,以增加磁盘IO的性能,多个目录用逗号进行分隔。

6>.hadoop.tmp.dir
Hadoop临时目录,默认为系统目录/tmp。在每个磁盘上都建立一个临时目录,可提高HDFS和MapReduce的I/O效率。 这里也推荐设置多个目录。如果你使用的是CDH的话,需要在高级选项的配置中自定义。

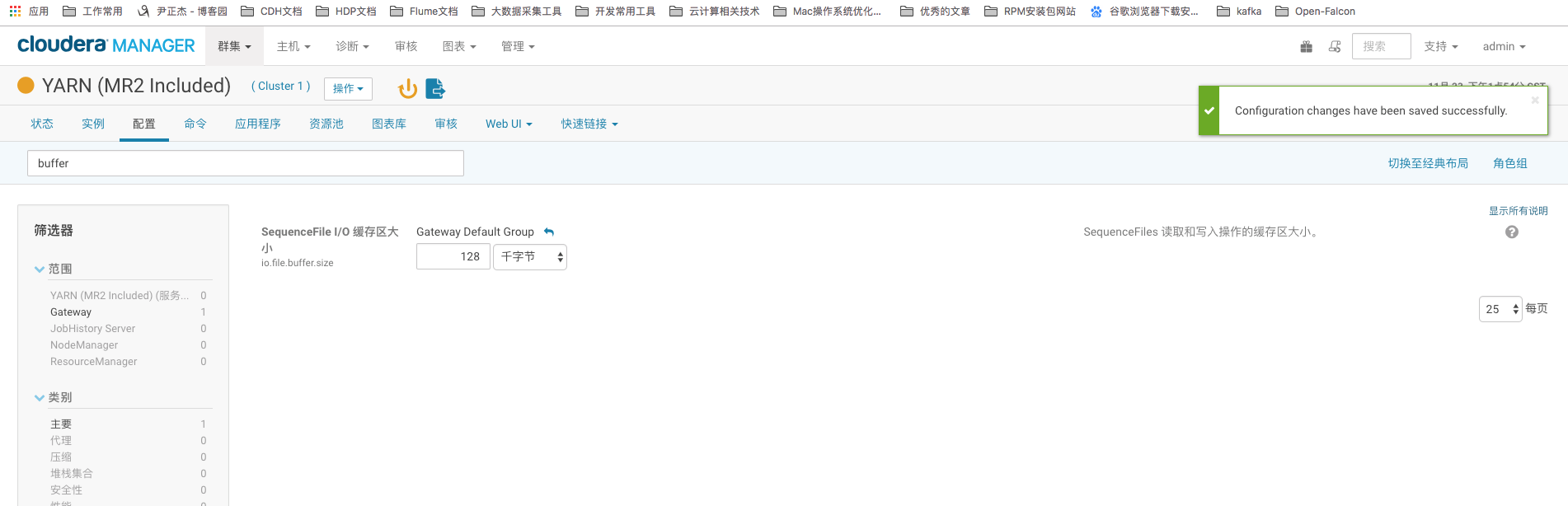
7>.io.file.buffer.size
HDFS文件缓冲区大小,默认为4096(即4K)。 推荐值:131072(128K)。这个得编辑core-site.xml配置文件,如果你用的CDH的话,直接在YARN服务里修改即可。
8>.fs.trash.interval
HDFS清理回收站的时间周期,单位为分钟。默认为0,表示不使用回收站特性。推荐开启它,时间你自己定义,推荐4~7天均可。

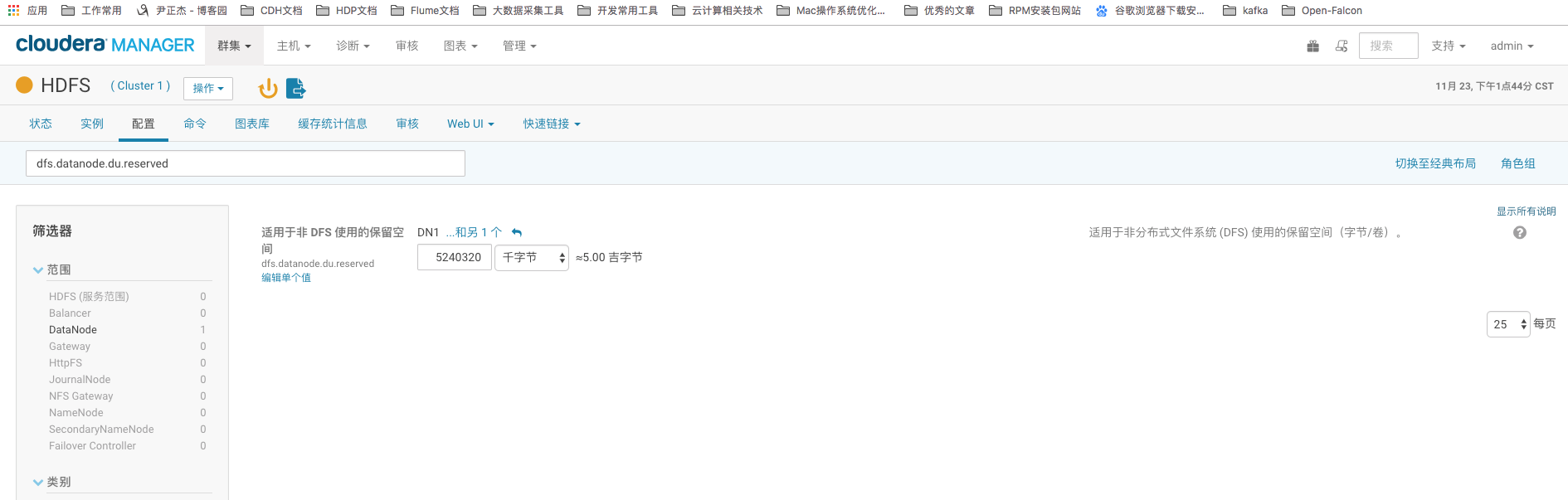
9>.dfs.datanode.du.reserved
DataNode保留空间大小,单位为字节。默认情况下,DataNode会占用全部可用的磁盘空间,该配置项可以使DataNode保留部分磁盘空间工其他应用程序使用。这个得视具体应用而定,推荐稍微空出点空间,5G~10G均可。
10>.机架感知
对于较大的集群,建议启用HDFS的机架感应功能。启用机架感应功能可以使HDFS优化数据块备份的分布,增强HDFS的性能和可靠性。可参考的案例:https://www.cnblogs.com/yinzhengjie/p/9142230.html。
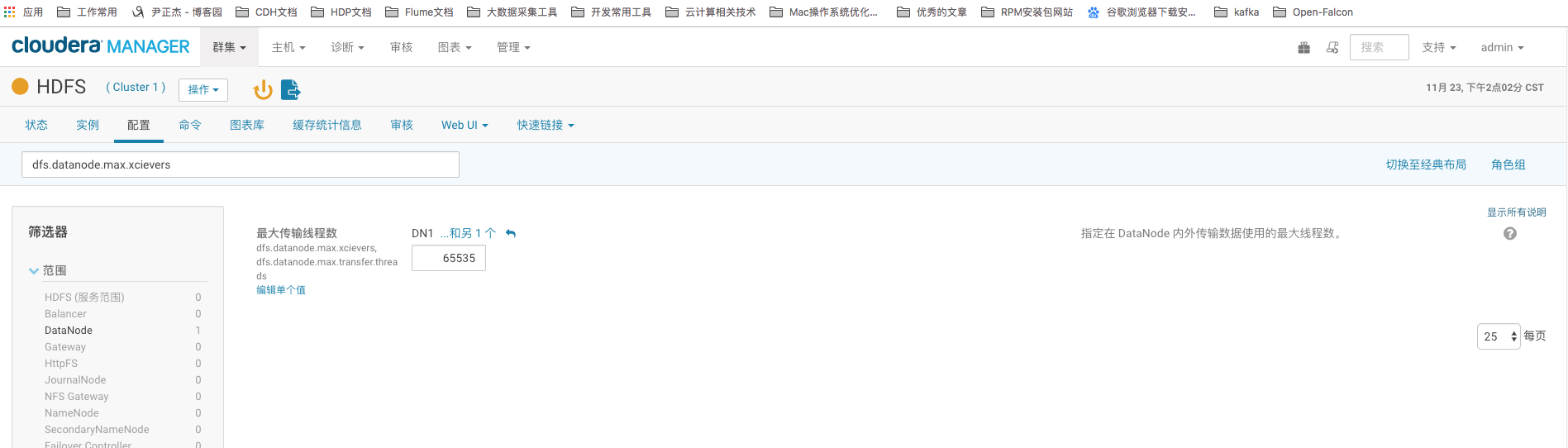
11>.dfs.datanode.max.xcievers
这个值是指定 datanode 可同時处理的最大文件数量,推荐将这个值调大,默认是256,最大值可以配置为65535。
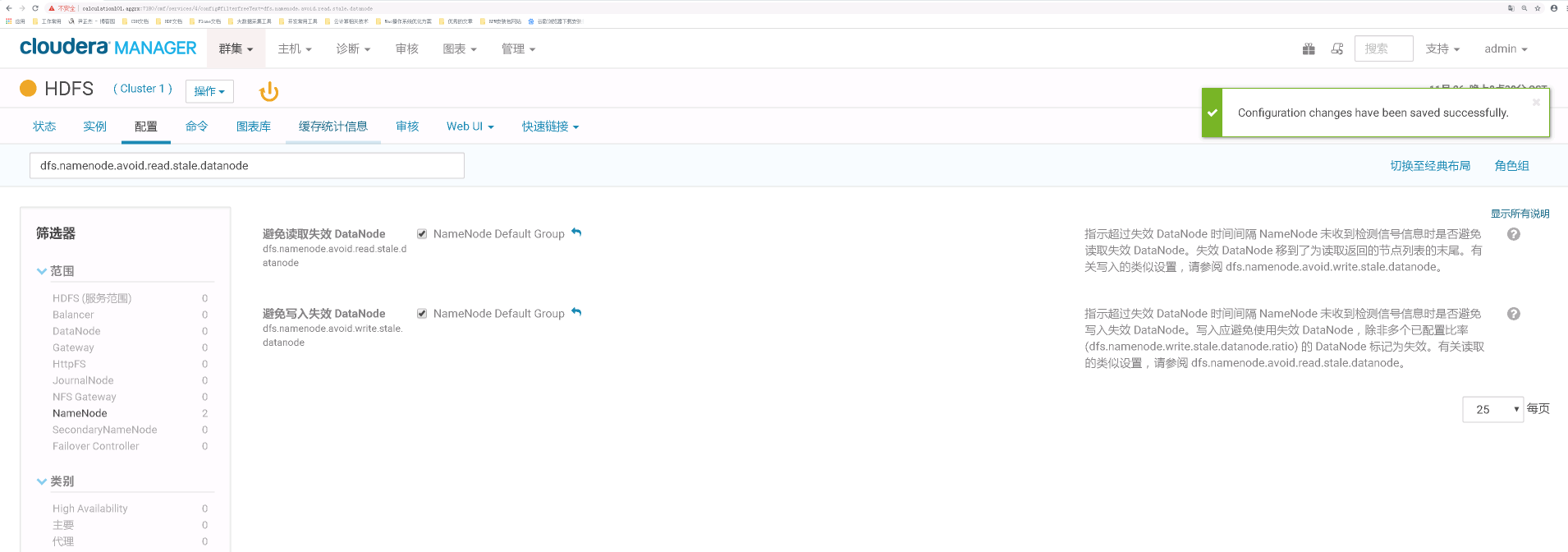
12>.避免脏读写操作
dfs.namenode.avoid.read.stale.datanode。
dfs.namenode.avoid.write.stale.datanode
13>.增大Service Monitor 将使用配置属性列表,搜索:“dfs.datanode.socket”,默认都是3秒,我这里改成了30s。
