Hadoop生态圈-Hive快速入门篇之Hive环境搭建
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
一.数据仓库(理论性知识大多摘自百度百科)
1>.什么是数据仓库
数据仓库,英文名称为Data Warehouse,可简写为DW或DWH。数据仓库,是为企业所有级别的决策制定过程,提供所有类型数据支持的战略集合。它是单个数据存储,出于分析性报告和决策支持目的而创建。 为需要业务智能的企业,提供指导业务流程改进、监视时间、成本、质量以及控制。
2>.数据仓库的特点
第一:数据仓库是面向主题的
操作型数据库的数据组织面向事务处理任务,而数据仓库中的数据是按照一定的主题域进行组织。主题是指用户使用数据仓库进行决策时所关心的重点方面,一个主题通常与多个操作型信息系统相关。


1 首先,主题是一个抽象的概念,是较高层次上企业信息系统中的数据综合,归类并进行分析利用的抽象。在逻辑意义上,它是对应 2 企业中某个宏观分析领域所涉及的分析对象。面向主题的数据组织方式,就是在较高层次上对分析队形的数据的一个完整,一致的描述。 3 能完整,统一的刻画对象所设计的各项数据,以及数据之间的联系。所谓较高层次是相对面向应用的数据组织方式而言的,是指按照主题 4 进行数据组织的方式更高的数据抽象级别。
第二:数据仓库的数据是集成的
数据仓库中的数据是在对原有分散的数据库数据抽取、清理的基础上经过系统加工、汇总和整理得到的,必须消除源数据中的不一致性,以保证数据仓库内的信息是关于整个企业的一致的全局信息。
数据仓库中的数据是在对原有分散的数据库数据抽取、清理的基础上经过系统加工、汇总和整理得到的,必须消除源数据中的不一致性, 以保证数据仓库内的信息是关于整个企业的一致的全局信息。 数据仓库的数据主要供企业决策分析之用,所涉及的数据操作主要是数据查询,一旦某个数据进入数据仓库以后,一般情况下将被长期保留, 也就是数据仓库中一般有大量的查询操作,但修改和删除操作很少,通常只需要定期的加载、刷新。 数据仓库中的数据通常包含历史信息,系统记录了企业从过去某一时点(如开始应用数据仓库的时点)到当前的各个阶段的信息,通过这些信息, 可以对企业的发展历程和未来趋势做出定量分析和预测。 数据仓库中的数据是在对原有分散的数据库数据抽取,操作性数据与DSS分析数据之间差别甚大。第一,数据仓库的每一个主题所对应的元数据 在原有的各分散数据库中有许多重复和不一致的地方,且来源于不同的联机系统的数据都和不同的应用逻辑捆绑在一起;第二,数据仓库中的综合数据 不能从原有的数据库系统直接得到。因此在数据进入数据仓库之前,必须要经过统一与综合,这一步是数据仓库建设中最关键,最复杂的一步,所要 完成的工作有以下两点, 1>.要统一源数据中所有矛盾之处,如字段的同名异义,异义同义,单位不统一,字长不统一等; 2>.进行数据综合和计算,数据仓库中的数据综合工作可以在原有数据库抽取数据时生成,但许多是在数据仓库内部生成的,即进入数据仓库以后进行综合生成的;
第三:数据仓库的数据是不可更新的
数据仓库主要是为决策分析提供数据,所涉及的操作主要是数据的查询,一般情况下并不进行修改操作。
数据仓库的数据反映的是一段相当长的时间内历史数据的内容,是不同时点的数据库快照集合,以及基于这些快照进行统计, 综合和重组的导出数据,而不是联机处理的数据。数据库中进行联机处理的数据经过集成输入到数据仓库中,一旦数据仓库存放的 数据已经超过数据仓库的数据存储期限,这些数据将从当前的数据仓库中删去。因为数据仓库只进行数查询操作,所以数据仓库管理 系统相比数据库管理而言要简单得多。数据库管理系统中许多技术难点,如完整性保护,并发控制等等,在数据仓库的管理中几乎可以 省去。但是由于数据仓库的查询量往往很大,所以对数据查询提出了更高的要求,它需要采用各种复杂的索引技术;同时由于数据仓库 面向的是商业企业的高层管理者,他们会对数据查询的界面友好性和数据表示提出更高的要求
第四:数据仓库的数据是随时间不断变化的
传统的关系数据库系统比较适合处理格式化的数据,能够较好的满足商业商务处理的需求。稳定的数据以只读格式保存,且不随时间改变。数据仓库中的数据不可更新是针对应用来说的,也就是说,数据仓库的用户进行处理是不进行数据更新操作的。但并不是说,在从数据集成输入数据仓库开始到最终被删除的整个数据数据生存周期中,所有的数据仓库数据都是永远不变的。
数据仓库丶数据是随时间的变化而不断变化的,这是数据仓库数据的第四个特征。这第四个特征表现在以下3个方面: 1>.数据仓库随时间变化不断增加新的数据内容。数据仓库系统必须不断捕捉OLTP数据库中变化的数据,追加到数据仓库中去, 也就是要不断生成OLTP数据库的快照,经统一集成后增加到数据仓库中去;但对于确实不再变化的数据库快照,如果捕捉到新的的 变化数据,则只生成一个新的数据库快照增加进去,而不会对原有的数据库快照进行修改。 2>.数据仓库随时间变化不断删去旧的的数据内容。数据仓库的数据也有存储期限,一点超过了这个期限,过期数据就要被删除。 只要数据仓库内的数据时限要远远长于操作型环境中的数据时限。在操作型环境中一般只保存有60-90天的数据,而在数据仓库中则 需要保存较长时限的数据(如5~10年),以适应DSS进行趋势分析的要求。 3>.数据仓库中包含有大量的综合数据,这些数据中有很多跟时间有关,如数据经常按照时间段进行综合,或隔一定的时间片进 行抽样等等。这些数据要随着时间的变化不断的进行重新综合。因此,数据仓库的特征都包含时间项,一标明数据的历史时期。
上面是数据仓库主要的四个特点,处理以上明显的四个特点外,还有其他的特点,我这里就不搬砖了,详情请参考百度百科吧。
3>.数据仓库的发展历程
数据仓库中发展大致经历了以下三个过程:
第一:简单报表阶段
这个阶段,系统的主要目标是解决一些日常工作中业务人员需要的报表,以及生成一些简单的能够帮助领导进行决策所需要的汇总数据。这个阶段的大部分表现形式为数据库的前端报表工具。
第二:数据集市阶段
这个阶段,主要是根据meo某个业务部门的需要,进行一定的数据采集,整理,按照业务人员的需要,进行多维报表的展现,能够提供对特定业务指导的数据,并且能够提供的领导决策数据。
第三:数据仓库阶段
这个阶段,主要是按照一定的数据模型,对整个企业的数据进行采集,整理,并且能够按照莫也给业务部门的需要,提供跨部门的,完全一致的业务报表数据,能够通过数据仓库生成对应的业务具有指导性的数据,同时,为领导决策提供全面的数据支持。
二.Hive基本概念
1>.什么是Hive
Hive是由Facebook公司开源用于解决海量结构化日志的数据统计。Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张表,并提供类SQL查询功能。Hive的本质是:将HQL(Hive SQL)转化成MapReduce程序。Hive处理的数据存储在HDFS上,Hive分析数据底层的实现是MapReduce,执行程序运行在Yarn上。
2>.Hive的优缺点
Hive的优点如下:
1>.操作接口采用类SQL语法,提供快速开发的能力(简单、容易上手)
2>.避免了去写MapReduce,减少开发人员的学习成本。
3>.Hive的执行延迟比较高,因此Hive常用于数据分析,对实时性要求不高的场合;
4>.Hive优势在于处理大数据,对于处理小数据没有优势,因为Hive的执行延迟比较高。
5>.Hive支持用户自定义函数,用户可以根据自己的需求来实现自己的函数。
Hive的缺点如下:
1>.Hive的HQL表达能力有限,比如:
(1)迭代式算法无法表达
(2)数据挖掘方面不擅长
2>.Hive的效率比较低,比如:
(1)Hive自动生成的MapReduce作业,通常情况下不够智能化
(2)Hive调优比较困难,粒度较粗
3>.hive架构原理
如下图所示,Hive通过给用户提供的一系列交互接口,接收到用户的指令(SQL),使用自己的Driver,结合元数据(MetaStore),将这些指令翻译成MapReduce,提交到Hadoop中执行,最后,将执行返回的结果输出到用户交互接口。
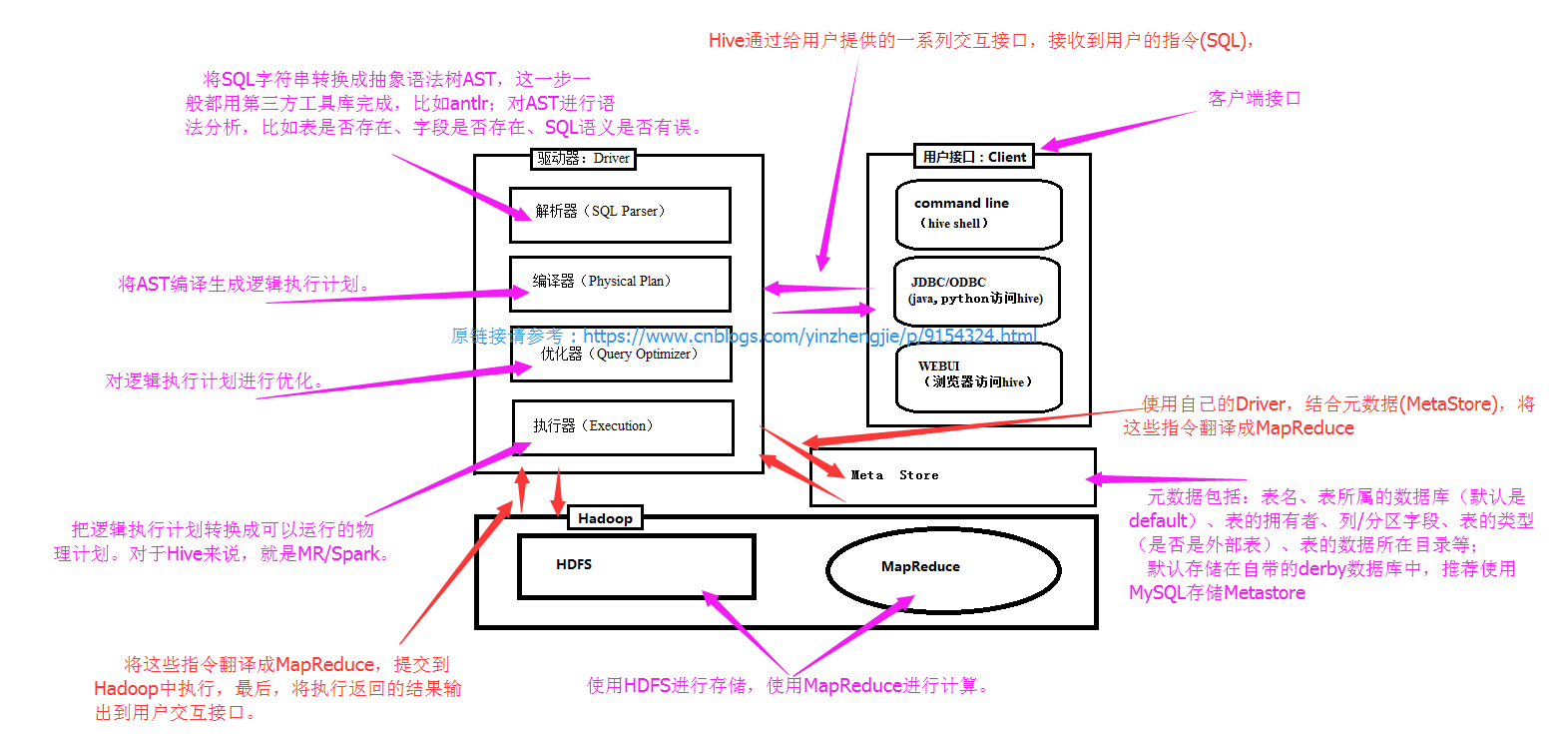
1)用户接口:Client CLI(hive shell)、JDBC/ODBC(java访问hive)、WEBUI(浏览器访问hive) 2)元数据:Metastore 元数据包括:表名、表所属的数据库(默认是default)、表的拥有者、列/分区字段、表的类型(是否是外部表)、表的数据所在目录等; 默认存储在自带的derby数据库中,推荐使用MySQL存储Metastore 3)Hadoop 使用HDFS进行存储,使用MapReduce进行计算。 4)驱动器:Driver (1)解析器(SQL Parser):将SQL字符串转换成抽象语法树AST,这一步一般都用第三方工具库完成,比如antlr;对AST进行语法分析,比如表是否存在、字段是否存在、SQL语义是否有误。 (2)编译器(Physical Plan):将AST编译生成逻辑执行计划。 (3)优化器(Query Optimizer):对逻辑执行计划进行优化。 (4)执行器(Execution):把逻辑执行计划转换成可以运行的物理计划。对于Hive来说,就是MR/Spark。
三.Hive和数据库的差异比较
由于 Hive 采用了类似SQL 的查询语言 HQL(Hive Query Language),因此很容易将 Hive 理解为数据库。其实从结构上来看,Hive 和数据库除了拥有类似的查询语言,再无类似之处。本文将从多个方面来阐述 Hive 和数据库的差异。数据库可以用在 Online 的应用中,但是Hive 是为数据仓库而设计的,清楚这一点,有助于从应用角度理解 Hive 的特性。
1>.查询语言
答:由于SQL被广泛的应用在数据仓库中,因此,专门针对Hive的特性设计了类SQL的查询语言HQL。熟悉SQL开发的开发者可以很方便的使用Hive进行开发。
2>.数据存储位置
答:Hive 是建立在 Hadoop 之上的,所有 Hive 的数据都是存储在 HDFS 中的。而数据库则可以将数据保存在块设备或者本地文件系统中。
3>.数据更新
答:由于Hive是针对数据仓库应用设计的,而数据仓库的内容是读多写少的。因此,Hive中不支持对数据的改写和添加,所有的数据都是在加载的时候确定好的。而数据库中的数据通常是需要经常进行修改的,因此可以使用 INSERT INTO … VALUES 添加数据,使用 UPDATE … SET修改数据。
4>.索引
答:Hive在加载数据的过程中不会对数据进行任何处理,甚至不会对数据进行扫描,因此也没有对数据中的某些Key建立索引。Hive要访问数据中满足条件的特定值时,需要暴力扫描整个数据,因此访问延迟较高。由于 MapReduce 的引入, Hive 可以并行访问数据,因此即使没有索引,对于大数据量的访问,Hive 仍然可以体现出优势。数据库中,通常会针对一个或者几个列建立索引,因此对于少量的特定条件的数据的访问,数据库可以有很高的效率,较低的延迟。由于数据的访问延迟较高,决定了 Hive 不适合在线数据查询。
5>.执行
答:Hive中大多数查询的执行是通过 Hadoop 提供的 MapReduce 来实现的。而数据库通常有自己的执行引擎。
6>.执行延迟
答:Hive 在查询数据的时候,由于没有索引,需要扫描整个表,因此延迟较高。另外一个导致 Hive 执行延迟高的因素是 MapReduce框架。由于MapReduce 本身具有较高的延迟,因此在利用MapReduce 执行Hive查询时,也会有较高的延迟。相对的,数据库的执行延迟较低。当然,这个低是有条件的,即数据规模较小,当数据规模大到超过数据库的处理能力的时候,Hive的并行计算显然能体现出优势。
7>.可扩展性
答:由于Hive是建立在Hadoop之上的,因此Hive的可扩展性是和Hadoop的可扩展性是一致的(世界上最大的Hadoop 集群在 Yahoo!,2009年的规模在4000 台节点左右)。而数据库由于 ACID 语义的严格限制,扩展行非常有限。目前最先进的并行数据库 Oracle 在理论上的扩展能力也只有100台左右。
8>.数据规模
答:由于Hive建立在集群上并可以利用MapReduce进行并行计算,因此可以支持很大规模的数据;对应的,数据库可以支持的数据规模较小。
四.Hive的安装部署
1>. Hive安装地址
1>.Hive官网地址: http://hive.apache.org/
2>.文档查看地址: https://cwiki.apache.org/confluence/display/Hive/GettingStarted
3>.下载地址: http://archive.apache.org/dist/hive/
4>.github地址: https://github.com/apache/hive
2>.安装hadoop的详细步骤(由于Hive存储和计算依赖Hadoop集群,因此必须启动hdfs和yarn哟!)
1>.解压 [yinzhengjie@s101 ~]$ tar zxf apache-hive-2.1.1-bin.tar.gz -C /soft/ 2>.配置软连接 [yinzhengjie@s101 ~]$ ln -s /soft/apache-hive-2.1.1-bin/ /soft/hive 3>.添加环境变量 [yinzhengjie@s101 ~]$ tail -3 /etc/profile #ADD hive HIVE_HOME=/soft/hive PATH=$PATH:$HIVE_HOME/bin [yinzhengjie@s101 ~]$ 4>.使得环境变量生效 [yinzhengjie@s101 ~]$ source /etc/profile [yinzhengjie@s101 ~]$ 5>.验证是否安装成功 [yinzhengjie@s101 ~]$ hive --version which: no hbase in (/usr/local/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/soft/jdk//bin:/soft/hadoop//bin:/soft/hadoop//sbin:/soft/zk/bin:/home/yinzhengjie/.local/bin:/home/yinzhengjie/bin:/soft/jdk//bin:/soft/hadoop//bin:/soft/hadoop//sbin:/soft/zk/bin:/soft/hive/bin:/soft/jdk//bin:/soft/hadoop//bin:/soft/hadoop//sbin:/soft/zk/bin:/soft/hive/bin) Hive 2.1.1 Subversion git://jcamachorodriguez-rMBP.local/Users/jcamachorodriguez/src/workspaces/hive/HIVE-release2/hive -r 1af77bbf8356e86cabbed92cfa8cc2e1470a1d5c Compiled by jcamachorodriguez on Tue Nov 29 19:46:12 GMT 2016 From source with checksum 569ad6d6e5b71df3cb04303183948d90 [yinzhengjie@s101 ~]$ 6>.初始化hive的Schema [yinzhengjie@s101 ~]$ schematool -initSchema -dbType derby which: no hbase in (/usr/local/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/soft/jdk//bin:/soft/hadoop//bin:/soft/hadoop//sbin:/soft/zk/bin:/home/yinzhengjie/.local/bin:/home/yinzhengjie/bin:/soft/jdk//bin:/soft/hadoop//bin:/soft/hadoop//sbin:/soft/zk/bin:/soft/hive/bin:/soft/jdk//bin:/soft/hadoop//bin:/soft/hadoop//sbin:/soft/zk/bin:/soft/hive/bin) SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/soft/apache-hive-2.1.1-bin/lib/log4j-slf4j-impl-2.4.1.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/soft/hadoop-2.7.3/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory] Metastore connection URL: jdbc:derby:;databaseName=metastore_db;create=true Metastore Connection Driver : org.apache.derby.jdbc.EmbeddedDriver Metastore connection User: APP Starting metastore schema initialization to 2.1.0 Initialization script hive-schema-2.1.0.derby.sql Initialization script completed schemaTool completed [yinzhengjie@s101 ~]$
3>.配置hive使用Windows操作系统的mysql存放元数据
一.mysql服务端进行授权操作 1>.创建数据库 mysql> select version(); +-----------+ | version() | +-----------+ | 5.5.45 | +-----------+ 1 row in set (0.00 sec) mysql> mysql> create database hive; Query OK, 1 row affected (0.00 sec) mysql> mysql> show databases; +--------------------+ | Database | +--------------------+ | information_schema | | hive | | mysql | | performance_schema | | test | +--------------------+ 5 rows in set (0.00 sec) mysql> 2>.进行授权操作,并刷新授权 mysql> mysql> grant all PRIVILEGES on *.* to 'root'@'s101' identified by 'yinzhengjie'; mysql> FLUSH PRIVILEGES; 3>.将对应的jar放在hive类库中/soft/hive/lib mysql-connector-java-5.1.41.jar (这个按照包针对的是MySQL5.6以下版本使用,我把百度云连接放在这:https://pan.baidu.com/s/1EJed7lj-bBOajQVWWX6Ynw 密码:rq08) 二.修改hive的配置文件 1>.拷贝源文件到目标文件 [yinzhengjie@s101 ~]$ cp /soft/hive/conf/hive-default.xml.template /soft/hive/conf/hive-site.xml [yinzhengjie@s101 ~]$ 2>.编辑hive-site的配置文件(配置连接数据库的四大参数) [yinzhengjie@s101 ~]$ sed -i 's@${system:java.io.tmpdir}@/home/yinzhengjie@g' /soft/hive/conf/hive-site.xml [yinzhengjie@s101 ~]$ sed -i 's/${system:user.name}/yinzhengjie/g' /soft/hive/conf/hive-site.xml [yinzhengjie@s101 ~]$ 注意:处理修改上面的参数,还需要修改以下的几个参数信息哟!(即连接MySQL数据的四大参数) <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> <description>JDBC元数据库的类名</description> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>root</value> <description>元数据库的用户名</description> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>yinzhengjie</value> <description>元数据库的密码</description> </property> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://172.30.100.1:3306/hive</value> <description>元数据库连接串</description> </property> [yinzhengjie@s101 ~]$ 3>.拷贝hive的环境变量脚本 [yinzhengjie@s101 ~]$ cp /soft/hive/conf/hive-env.sh.template /soft/hive/conf/hive-env.sh [yinzhengjie@s101 ~]$ 4>.修改hive-env.sh的配置文件 [yinzhengjie@s101 ~]$ sed -i 's@# HADOOP_HOME=${bin}/../../hadoop@HADOOP_HOME=/soft/hadoop@g' /soft/hive/conf/hive-env.sh [yinzhengjie@s101 ~]$ 三.初始化hive元数据库 1>.初始化操作 [yinzhengjie@s101 ~]$ schematool -initSchema -dbType mysql which: no hbase in (/usr/local/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/soft/jdk//bin:/soft/hadoop//bin:/soft/hadoop//sbin:/soft/zk/bin:/home/yinzhengjie/.local/bin:/home/yinzhengjie/bin:/soft/jdk//bin:/soft/hadoop//bin:/soft/hadoop//sbin:/soft/zk/bin:/soft/hive/bin:/soft/jdk//bin:/soft/hadoop//bin:/soft/hadoop//sbin:/soft/zk/bin:/soft/hive/bin) SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/soft/apache-hive-2.1.1-bin/lib/log4j-slf4j-impl-2.4.1.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/soft/hadoop-2.7.3/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory] Metastore connection URL: jdbc:mysql://172.30.100.1:5200/hive Metastore Connection Driver : com.mysql.jdbc.Driver Metastore connection User: root Starting metastore schema initialization to 2.1.0 Initialization script hive-schema-2.1.0.mysql.sql Initialization script completed schemaTool completed [yinzhengjie@s101 ~]$ 2>.登录数据库 [yinzhengjie@s101 ~]$ hive which: no hbase in (/usr/local/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/soft/jdk//bin:/soft/hadoop//bin:/soft/hadoop//sbin:/soft/zk/bin:/home/yinzhengjie/.local/bin:/home/yinzhengjie/bin:/soft/jdk//bin:/soft/hadoop//bin:/soft/hadoop//sbin:/soft/zk/bin:/soft/hive/bin:/soft/jdk//bin:/soft/hadoop//bin:/soft/hadoop//sbin:/soft/zk/bin:/soft/hive/bin) SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/soft/apache-hive-2.1.1-bin/lib/log4j-slf4j-impl-2.4.1.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/soft/hadoop-2.7.3/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory] Logging initialized using configuration in jar:file:/soft/apache-hive-2.1.1-bin/lib/hive-common-2.1.1.jar!/hive-log4j2.properties Async: true Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases. hive> > show databases; OK default Time taken: 1.0 seconds, Fetched: 1 row(s) hive> > > > quit; [yinzhengjie@s101 ~]$
4>.配置hive使用Linux操作系统的mysql存放元数据
关于MySQL的yum源以及rpm安装包我已经下载好了,存放在百度云链接:https://pan.baidu.com/s/1wZS2f-ZiJv0VcpUBZ2hcZQ 密码:yzl7
一.安装MySQL5.6.3版本的数据库 1>.安装mysql的源 [yinzhengjie@s101 ~]$ sudo rpm -ivh mysql-community-release-el7-5.noarch.rpm [sudo] password for yinzhengjie: Preparing... ################################# [100%] Updating / installing... 1:mysql-community-release-el7-5 ################################# [100%] [yinzhengjie@s101 ~]$
2>.本地安装MySQL [yinzhengjie@s101 ~]$ cd mysql [yinzhengjie@s101 mysql]$ sudo yum -y localinstall *.rpm 二.启动mysql并将其开机启动 [yinzhengjie@s101 mysql]$ systemctl start mysqld ==== AUTHENTICATING FOR org.freedesktop.systemd1.manage-units === Authentication is required to manage system services or units. Authenticating as: root Password: ==== AUTHENTICATION COMPLETE === [yinzhengjie@s101 mysql]$ systemctl enable mysqld ==== AUTHENTICATING FOR org.freedesktop.systemd1.manage-unit-files === Authentication is required to manage system service or unit files. Authenticating as: root Password: ==== AUTHENTICATION COMPLETE === ==== AUTHENTICATING FOR org.freedesktop.systemd1.reload-daemon === Authentication is required to reload the systemd state. Authenticating as: root Password: ==== AUTHENTICATION COMPLETE === [yinzhengjie@s101 mysql]$ [yinzhengjie@s101 mysql]$ 三.更新mysql密码并创建数据库(刚开始安装没有密码) [yinzhengjie@s101 mysql]$ mysql -uroot Welcome to the MySQL monitor. Commands end with ; or g. Your MySQL connection id is 2 Server version: 5.6.38 MySQL Community Server (GPL) Copyright (c) 2000, 2017, Oracle and/or its affiliates. All rights reserved. Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners. Type 'help;' or 'h' for help. Type 'c' to clear the current input statement. mysql> use mysql Reading table information for completion of table and column names You can turn off this feature to get a quicker startup with -A Database changed mysql> UPDATE user SET Password=PASSWORD('yinzhengjie') where USER='root'; Query OK, 4 rows affected (0.00 sec) Rows matched: 4 Changed: 4 Warnings: 0 mysql> flush privileges; Query OK, 0 rows affected (0.00 sec) mysql> create database hive; Query OK, 1 row affected (0.00 sec) mysql> quit; Bye [yinzhengjie@s101 mysql]$ 四.将mysql-connector-java-5.1.41.jar数据库连接驱动放在hive的lib库中 五.修改hive的配置文件 1>.拷贝源文件到目标文件 [yinzhengjie@s101 ~]$ cp /soft/hive/conf/hive-default.xml.template /soft/hive/conf/hive-site.xml [yinzhengjie@s101 ~]$
2>.编辑hive-site的配置文件(配置连接数据库的四大参数) [yinzhengjie@s101 ~]$ sed -i 's@${system:java.io.tmpdir}@/home/yinzhengjie@g' /soft/hive/conf/hive-site.xml [yinzhengjie@s101 ~]$ sed -i 's/${system:user.name}/yinzhengjie/g' /soft/hive/conf/hive-site.xml [yinzhengjie@s101 ~]$ 注意:处理修改上面的参数,还需要修改以下的几个参数信息哟(即连接MySQL数据的四大参数)! <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> <description>JDBC元数据库的类名</description> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>root</value> <description>元数据库的用户名</description> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>yinzhengjie</value> <description>元数据库的密码</description> </property> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://s101:3306/hive</value> <description>元数据库连接串</description> </property> [yinzhengjie@s101 ~]$
3>.拷贝hive的环境变量脚本 [yinzhengjie@s101 ~]$ cp /soft/hive/conf/hive-env.sh.template /soft/hive/conf/hive-env.sh [yinzhengjie@s101 ~]$
4>.修改hive-env.sh的配置文件 [yinzhengjie@s101 ~]$ sed -i 's@# HADOOP_HOME=${bin}/../../hadoop@HADOOP_HOME=/soft/hadoop@g' /soft/hive/conf/hive-env.sh [yinzhengjie@s101 ~]$ 六.初始化hive元数据库 1>.初始化操作 [yinzhengjie@s101 ~]$ schematool -initSchema -dbType mysql which: no hbase in (/usr/local/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/soft/jdk//bin:/soft/hadoop//bin:/soft/hadoop//sbin:/soft/zk/bin:/home/yinzhengjie/.local/bin:/home/yinzhengjie/bin:/soft/jdk//bin:/soft/hadoop//bin:/soft/hadoop//sbin:/soft/zk/bin:/soft/hive/bin:/soft/jdk//bin:/soft/hadoop//bin:/soft/hadoop//sbin:/soft/zk/bin:/soft/hive/bin) SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/soft/apache-hive-2.1.1-bin/lib/log4j-slf4j-impl-2.4.1.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/soft/hadoop-2.7.3/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory] Metastore connection URL: jdbc:mysql://172.30.100.1:5200/hive Metastore Connection Driver : com.mysql.jdbc.Driver Metastore connection User: root Starting metastore schema initialization to 2.1.0 Initialization script hive-schema-2.1.0.mysql.sql Initialization script completed schemaTool completed [yinzhengjie@s101 ~]$
2>.登录数据库 [yinzhengjie@s101 lib]$ hive which: no hbase in (/usr/local/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/soft/jdk//bin:/soft/hadoop//bin:/soft/hadoop//sbin:/soft/zk/bin:/home/yinzhengjie/.local/bin:/home/yinzhengjie/bin:/soft/jdk//bin:/soft/hadoop//bin:/soft/hadoop//sbin:/soft/zk/bin:/soft/hive/bin:/soft/jdk//bin:/soft/hadoop//bin:/soft/hadoop//sbin:/soft/zk/bin:/soft/hive/bin) SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/soft/apache-hive-2.1.1-bin/lib/log4j-slf4j-impl-2.4.1.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/soft/hadoop-2.7.3/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory] Logging initialized using configuration in jar:file:/soft/apache-hive-2.1.1-bin/lib/hive-common-2.1.1.jar!/hive-log4j2.properties Async: true Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases. hive> > show databases; OK default Time taken: 1.131 seconds, Fetched: 1 row(s) hive>