Hadoop生态圈-使用MapReduce处理HBase数据
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
一.对HBase表中数据进行单词统计(TableInputFormat)
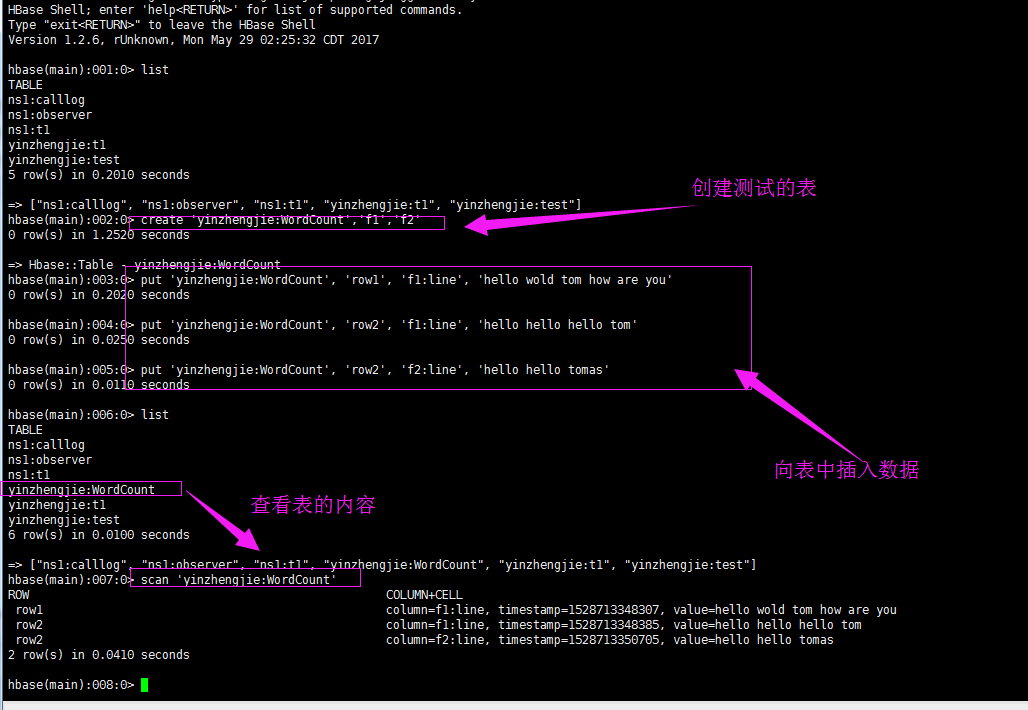
1>.准备环境
create_namespace 'yinzhengjie'
create 'yinzhengjie:WordCount','f1','f2'
put 'yinzhengjie:WordCount', 'row1', 'f1:line', 'hello wold tom how are you'
put 'yinzhengjie:WordCount', 'row2', 'f1:line', 'hello hello hello tom'
put 'yinzhengjie:WordCount', 'row2', 'f2:line', 'hello hello tomas'
scan 'yinzhengjie:WordCount'
2>.编写Map端代码
1 /* 2 @author :yinzhengjie 3 Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E7%94%9F%E6%80%81%E5%9C%88/ 4 EMAIL:y1053419035@qq.com 5 */ 6 package cn.org.yinzhengjie.hbase.tableinput; 7 8 import org.apache.hadoop.hbase.Cell; 9 import org.apache.hadoop.hbase.CellUtil; 10 import org.apache.hadoop.hbase.client.Result; 11 import org.apache.hadoop.hbase.io.ImmutableBytesWritable; 12 import org.apache.hadoop.hbase.util.Bytes; 13 import org.apache.hadoop.io.IntWritable; 14 import org.apache.hadoop.io.Text; 15 import org.apache.hadoop.mapreduce.Mapper; 16 17 import java.io.IOException; 18 import java.util.List; 19 20 /** 21 * 使用hbase表做wordcount 22 */ 23 public class TableInputMapper extends Mapper<ImmutableBytesWritable,Result, Text,IntWritable> { 24 25 /** 26 * 27 * @param key : 可以理解为HBase中的rowkey 28 * @param value : 输入端的结果集 29 * @param context : 和reduce端进行数据传输的上下文 30 */ 31 @Override 32 protected void map(ImmutableBytesWritable key, Result value, Context context) throws IOException, InterruptedException { 33 //将输入端的结果集编程一个集合 34 List<Cell> cells = value.listCells(); 35 //遍历集合,拿到每个元素的值,然后在按照空格进行切分,并将处理的结果传给reduce端 36 for (Cell cell : cells) { 37 String line = Bytes.toString(CellUtil.cloneValue(cell)); 38 String[] arr = line.split(" "); 39 for(String word : arr){ 40 context.write(new Text(word), new IntWritable(1)); 41 } 42 } 43 } 44 }
3>.编写Reducer端代码
1 /* 2 @author :yinzhengjie 3 Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E7%94%9F%E6%80%81%E5%9C%88/ 4 EMAIL:y1053419035@qq.com 5 */ 6 package cn.org.yinzhengjie.hbase.tableinput; 7 8 import org.apache.hadoop.io.IntWritable; 9 import org.apache.hadoop.io.Text; 10 import org.apache.hadoop.mapreduce.Reducer; 11 12 import java.io.IOException; 13 14 public class TableInputReducer extends Reducer<Text,IntWritable,Text,IntWritable> { 15 16 @Override 17 protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { 18 int sum = 0; 19 for (IntWritable value : values) { 20 sum += value.get(); 21 } 22 context.write(key,new IntWritable(sum)); 23 } 24 }
4>.编写主程序代码
1 /* 2 @author :yinzhengjie 3 Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E7%94%9F%E6%80%81%E5%9C%88/ 4 EMAIL:y1053419035@qq.com 5 */ 6 package cn.org.yinzhengjie.hbase.tableinput; 7 8 import org.apache.hadoop.conf.Configuration; 9 import org.apache.hadoop.fs.Path; 10 import org.apache.hadoop.hbase.HBaseConfiguration; 11 import org.apache.hadoop.hbase.mapreduce.TableInputFormat; 12 import org.apache.hadoop.io.IntWritable; 13 import org.apache.hadoop.io.Text; 14 import org.apache.hadoop.mapreduce.Job; 15 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; 16 17 import static org.apache.hadoop.hbase.mapreduce.TableInputFormat.INPUT_TABLE; 18 import static org.apache.hadoop.hbase.mapreduce.TableInputFormat.SCAN_COLUMN_FAMILY; 19 20 public class App { 21 22 public static void main(String[] args) throws Exception { 23 //创建一个conf对象 24 Configuration conf = HBaseConfiguration.create(); 25 //设置输入表,即指定源数据来自HBase的那个表 26 conf.set(INPUT_TABLE,"yinzhengjie:WordCount"); 27 //设置扫描列族 28 conf.set(SCAN_COLUMN_FAMILY,"f1"); 29 //创建一个任务对象job,别忘记把conf传进去哟! 30 Job job = Job.getInstance(conf); 31 //给任务起个名字 32 job.setJobName("Table WC"); 33 //指定main函数所在的类,也就是当前所在的类名 34 job.setJarByClass(App.class); 35 //设置自定义的Map程序和Reduce程序 36 job.setMapperClass(TableInputMapper.class); 37 job.setReducerClass(TableInputReducer.class); 38 //设置输入格式 39 job.setInputFormatClass(TableInputFormat.class); 40 //设置输出路径 41 FileOutputFormat.setOutputPath(job,new Path("file:///D:\BigData\yinzhengjieData\out")); 42 //设置输出k-v 43 job.setOutputKeyClass(Text.class); 44 job.setOutputValueClass(IntWritable.class); 45 //等待任务执行结束 46 job.waitForCompletion(true); 47 } 48 }
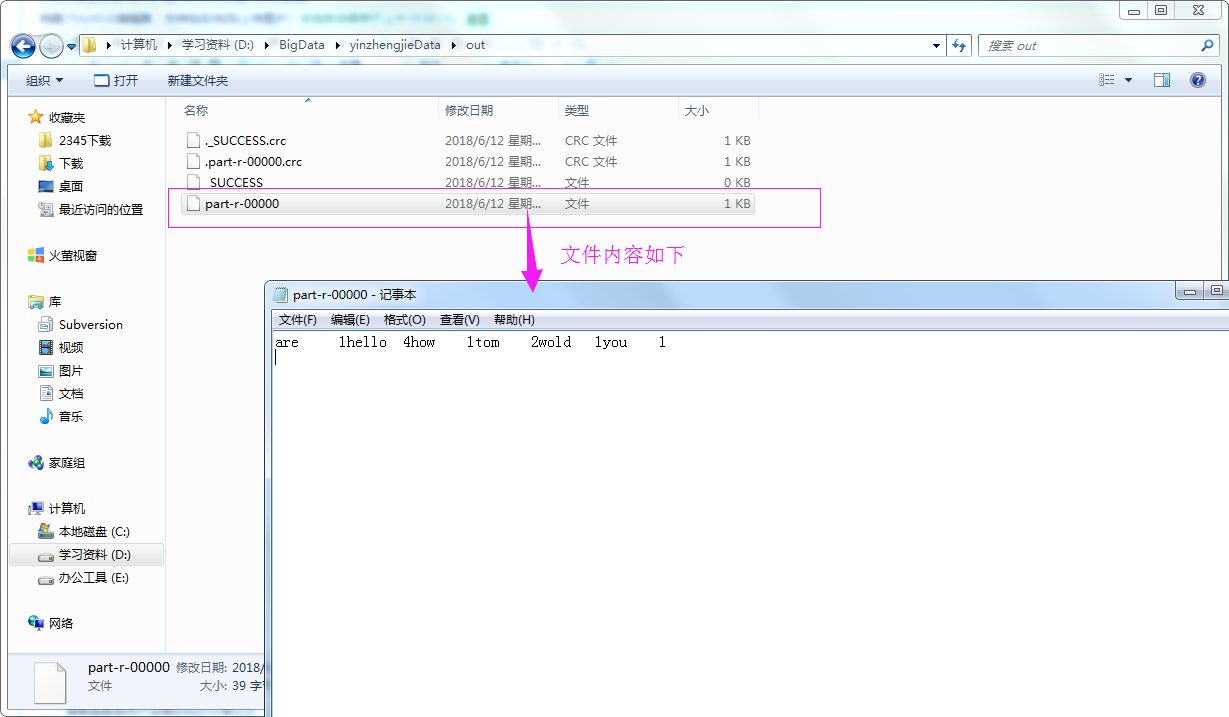
5>.查看测试结果
二.将本地文件进行单词统计的结果输出到HBase中(TableOutputFormat)
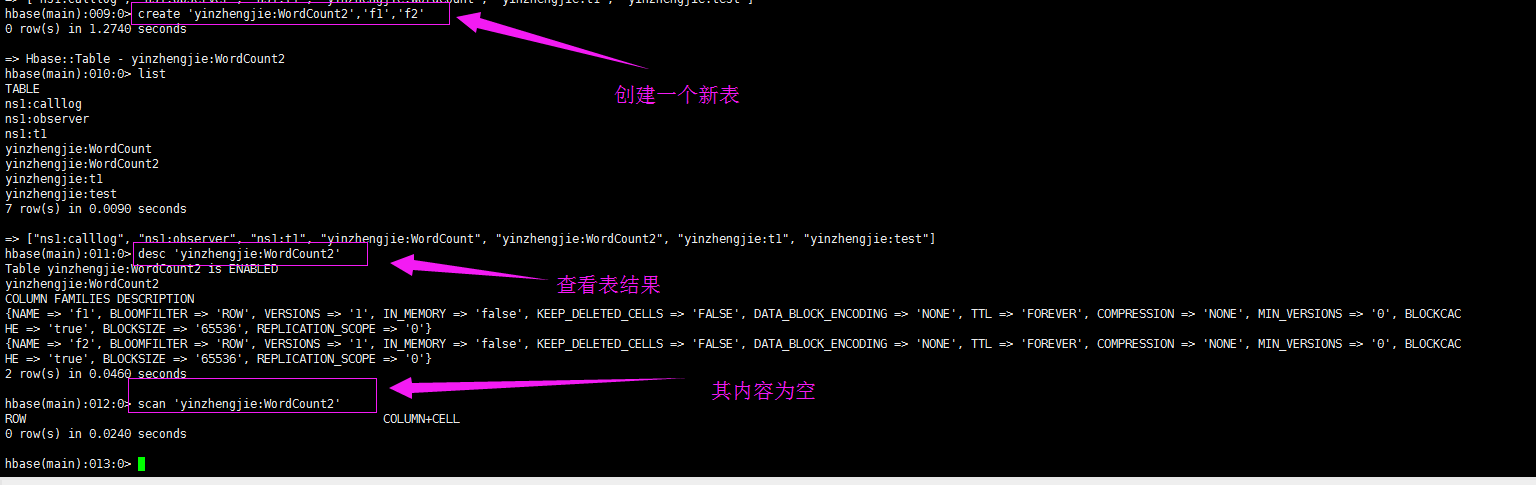
1>.准备环境
list
create 'yinzhengjie:WordCount2','f1','f2'
list
desc 'yinzhengjie:WordCount2'
scan 'yinzhengjie:WordCount2'
2>.编写Map端代码
1 /* 2 @author :yinzhengjie 3 Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E7%94%9F%E6%80%81%E5%9C%88/ 4 EMAIL:y1053419035@qq.com 5 */ 6 package cn.org.yinzhengjie.hbase.tableoutput; 7 8 import org.apache.hadoop.io.IntWritable; 9 import org.apache.hadoop.io.LongWritable; 10 import org.apache.hadoop.io.Text; 11 import org.apache.hadoop.mapreduce.Mapper; 12 import java.io.IOException; 13 14 public class TableOutputMapper extends Mapper<LongWritable, Text, Text, IntWritable> { 15 @Override 16 protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { 17 //得到一行数据 18 String line = value.toString(); 19 //按空格进行切分 20 String[] arr = line.split(" "); 21 //遍历切分后的数据,并将每个单词数的赋初始值为1 22 for (String word : arr){ 23 context.write(new Text(word),new IntWritable(1)); 24 } 25 } 26 }
3>.编写Reducer端代码
1 /* 2 @author :yinzhengjie 3 Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E7%94%9F%E6%80%81%E5%9C%88/ 4 EMAIL:y1053419035@qq.com 5 */ 6 package cn.org.yinzhengjie.hbase.tableoutput; 7 8 import org.apache.hadoop.hbase.client.Put; 9 import org.apache.hadoop.hbase.util.Bytes; 10 import org.apache.hadoop.io.IntWritable; 11 import org.apache.hadoop.io.NullWritable; 12 import org.apache.hadoop.io.Text; 13 import org.apache.hadoop.mapreduce.Reducer; 14 import java.io.IOException; 15 16 public class TableOutputReducer extends Reducer<Text,IntWritable,NullWritable,Put> { 17 @Override 18 protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { 19 //对同一个key的出现的次数进行相加操作,算出一个单词出现的次数 20 int sum = 0; 21 for (IntWritable value : values) { 22 sum += value.get(); 23 } 24 25 /** 26 * 注意,“key.toString().length() > 0”的目的是排除空串,所谓空转就是两个连续的空格链接在一起, 27 * 比如“hello world”,有两个空格,如果以空格切分的话,由于有两个空格,因此hello和world之间会被切割 28 * 两次,这也就意味着会出现三个对象,即"hello","","world"。由于这个空串("")的长度为0,因此,如果我 29 * 们指向统计单词的个数,只需要让长度大于0,就可以轻松过滤出“hello”和“world”两个参数啦! 30 */ 31 if(key.toString().length() > 0){ 32 Put put = new Put(Bytes.toBytes(key.toString())); 33 //添加每列的数据 34 put.addColumn(Bytes.toBytes("f1"),Bytes.toBytes("count"),Bytes.toBytes(sum+"")); 35 context.write(NullWritable.get(),put); 36 } 37 } 38 }
4>.编写主程序代码
1 /* 2 @author :yinzhengjie 3 Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E7%94%9F%E6%80%81%E5%9C%88/ 4 EMAIL:y1053419035@qq.com 5 */ 6 package cn.org.yinzhengjie.hbase.tableoutput; 7 8 import org.apache.hadoop.conf.Configuration; 9 import org.apache.hadoop.fs.Path; 10 import org.apache.hadoop.hbase.HBaseConfiguration; 11 import org.apache.hadoop.hbase.client.Put; 12 import org.apache.hadoop.hbase.mapreduce.TableOutputFormat; 13 import org.apache.hadoop.io.IntWritable; 14 import org.apache.hadoop.io.NullWritable; 15 import org.apache.hadoop.io.Text; 16 import org.apache.hadoop.mapreduce.Job; 17 import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; 18 19 public class App { 20 public static void main(String[] args) throws Exception { 21 //创建一个conf对象 22 Configuration conf = HBaseConfiguration.create(); 23 //设置输出表,即指定将数据存储在哪个HBase表 24 conf.set(TableOutputFormat.OUTPUT_TABLE,"yinzhengjie:WordCount2"); 25 //创建一个任务对象job,别忘记把conf传进去哟! 26 Job job = Job.getInstance(conf); 27 //给任务起个名字 28 job.setJobName("Table WordCount2"); 29 //指定main函数所在的类,也就是当前所在的类名 30 job.setJarByClass(App.class); 31 //设置自定义的Map程序和Reduce程序 32 job.setMapperClass(TableOutputMapper.class); 33 job.setReducerClass(TableOutputReducer.class); 34 //设置输出格式 35 job.setOutputFormatClass(TableOutputFormat.class); 36 //设置输入路径 37 FileInputFormat.addInputPath(job,new Path("file:///D:\BigData\yinzhengjieData\word.txt")); 38 //设置输出k-v 39 job.setOutputKeyClass(NullWritable.class); 40 job.setOutputValueClass(Put.class); 41 //设置map端输出k-v 42 job.setMapOutputKeyClass(Text.class); 43 job.setMapOutputValueClass(IntWritable.class); 44 //等待任务执行结束 45 job.waitForCompletion(true); 46 } 47 }
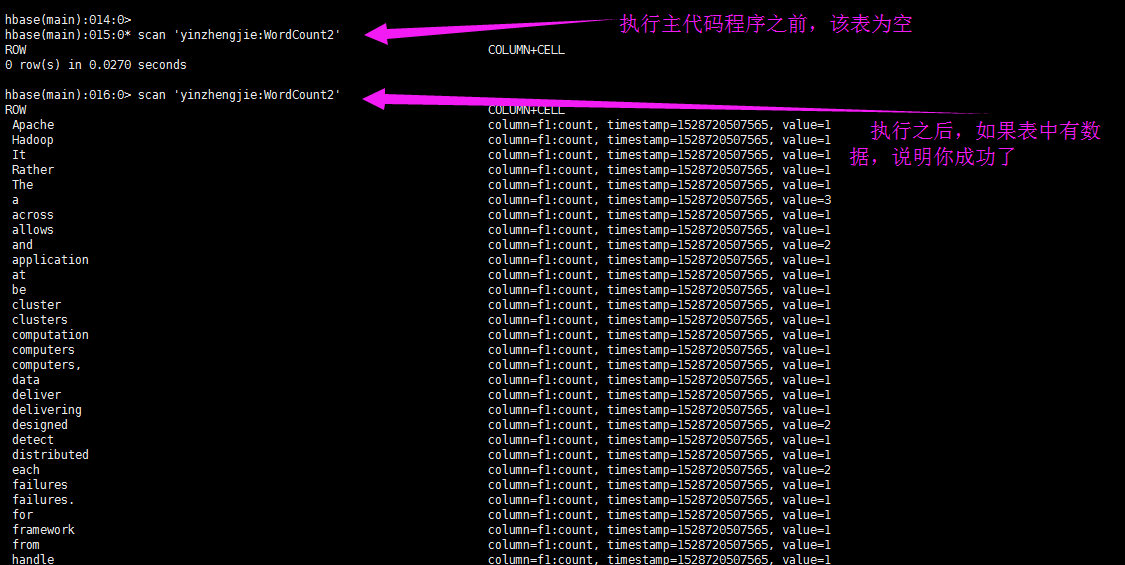
5>.查看测试结果(需要执行主代码程序)


hbase(main):015:0* scan 'yinzhengjie:WordCount2' ROW COLUMN+CELL 0 row(s) in 0.0270 seconds hbase(main):016:0> scan 'yinzhengjie:WordCount2' ROW COLUMN+CELL Apache column=f1:count, timestamp=1528720507565, value=1 Hadoop column=f1:count, timestamp=1528720507565, value=1 It column=f1:count, timestamp=1528720507565, value=1 Rather column=f1:count, timestamp=1528720507565, value=1 The column=f1:count, timestamp=1528720507565, value=1 a column=f1:count, timestamp=1528720507565, value=3 across column=f1:count, timestamp=1528720507565, value=1 allows column=f1:count, timestamp=1528720507565, value=1 and column=f1:count, timestamp=1528720507565, value=2 application column=f1:count, timestamp=1528720507565, value=1 at column=f1:count, timestamp=1528720507565, value=1 be column=f1:count, timestamp=1528720507565, value=1 cluster column=f1:count, timestamp=1528720507565, value=1 clusters column=f1:count, timestamp=1528720507565, value=1 computation column=f1:count, timestamp=1528720507565, value=1 computers column=f1:count, timestamp=1528720507565, value=1 computers, column=f1:count, timestamp=1528720507565, value=1 data column=f1:count, timestamp=1528720507565, value=1 deliver column=f1:count, timestamp=1528720507565, value=1 delivering column=f1:count, timestamp=1528720507565, value=1 designed column=f1:count, timestamp=1528720507565, value=2 detect column=f1:count, timestamp=1528720507565, value=1 distributed column=f1:count, timestamp=1528720507565, value=1 each column=f1:count, timestamp=1528720507565, value=2 failures column=f1:count, timestamp=1528720507565, value=1 failures. column=f1:count, timestamp=1528720507565, value=1 for column=f1:count, timestamp=1528720507565, value=1 framework column=f1:count, timestamp=1528720507565, value=1 from column=f1:count, timestamp=1528720507565, value=1 handle column=f1:count, timestamp=1528720507565, value=1 hardware column=f1:count, timestamp=1528720507565, value=1 high-availability, column=f1:count, timestamp=1528720507565, value=1 highly-available column=f1:count, timestamp=1528720507565, value=1 is column=f1:count, timestamp=1528720507565, value=3 itself column=f1:count, timestamp=1528720507565, value=1 large column=f1:count, timestamp=1528720507565, value=1 layer, column=f1:count, timestamp=1528720507565, value=1 library column=f1:count, timestamp=1528720507565, value=2 local column=f1:count, timestamp=1528720507565, value=1 machines, column=f1:count, timestamp=1528720507565, value=1 may column=f1:count, timestamp=1528720507565, value=1 models. column=f1:count, timestamp=1528720507565, value=1 of column=f1:count, timestamp=1528720507565, value=6 offering column=f1:count, timestamp=1528720507565, value=1 on column=f1:count, timestamp=1528720507565, value=2 processing column=f1:count, timestamp=1528720507565, value=1 programming column=f1:count, timestamp=1528720507565, value=1 prone column=f1:count, timestamp=1528720507565, value=1 rely column=f1:count, timestamp=1528720507565, value=1 scale column=f1:count, timestamp=1528720507565, value=1 servers column=f1:count, timestamp=1528720507565, value=1 service column=f1:count, timestamp=1528720507565, value=1 sets column=f1:count, timestamp=1528720507565, value=1 simple column=f1:count, timestamp=1528720507565, value=1 single column=f1:count, timestamp=1528720507565, value=1 so column=f1:count, timestamp=1528720507565, value=1 software column=f1:count, timestamp=1528720507565, value=1 storage. column=f1:count, timestamp=1528720507565, value=1 than column=f1:count, timestamp=1528720507565, value=1 that column=f1:count, timestamp=1528720507565, value=1 the column=f1:count, timestamp=1528720507565, value=3 thousands column=f1:count, timestamp=1528720507565, value=1 to column=f1:count, timestamp=1528720507565, value=5 top column=f1:count, timestamp=1528720507565, value=1 up column=f1:count, timestamp=1528720507565, value=1 using column=f1:count, timestamp=1528720507565, value=1 which column=f1:count, timestamp=1528720507565, value=1 67 row(s) in 0.1600 seconds hbase(main):017:0>