Hadoop生态圈-Sqoop部署以及基本使用方法
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
一.部署Sqoop工具
1>.下载Sqoop软件(下载地址:http://mirrors.hust.edu.cn/apache/sqoop/1.4.7/,建议下载最新版本,截止2018-06-14时,最新版本为1.4.7。)

2>.解压并创建符号链接
[yinzhengjie@s101 data]$ tar zxf sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz -C /soft/
[yinzhengjie@s101 data]$ ln -s /soft/sqoop-1.4.7.bin__hadoop-2.6.0/ /soft/sqoop
[yinzhengjie@s101 data]$
3>.配置环境变量并使之生效
[yinzhengjie@s101 ~]$ sudo vi /etc/profile
[sudo] password for yinzhengjie:
[yinzhengjie@s101 ~]$ tail -3 /etc/profile
#ADD SQOOP
SQOOP_HOME=/soft/sqoop
PATH=$PATH:$SQOOP_HOME/bin
[yinzhengjie@s101 ~]$
[yinzhengjie@s101 ~]$ source /etc/profile
[yinzhengjie@s101 ~]$
4>.创建sqoop-env.sh配置文件
[yinzhengjie@s101 ~]$ cp /soft/sqoop/conf/sqoop-env-template.sh /soft/sqoop/conf/sqoop-env.sh [yinzhengjie@s101 ~]$ [yinzhengjie@s101 ~]$ more /soft/sqoop/conf/sqoop-env.sh | grep -v ^# | grep -v ^$ export HADOOP_COMMON_HOME=/soft/hadoop export HADOOP_MAPRED_HOME=/soft/hadoop export HBASE_HOME=/soft/hbase export HIVE_HOME=/soft/hive export ZOOCFGDIR=/soft/zk/conf [yinzhengjie@s101 ~]$
5>.将mysql驱动放置在sqoop/lib下
[yinzhengjie@s101 ~]$ cp /soft/hive/lib/mysql-connector-java-5.1.41.jar /soft/sqoop/lib/ [yinzhengjie@s101 ~]$
6>.sqoop version验证安装
[yinzhengjie@s101 ~]$ sqoop version Warning: /soft/sqoop-1.4.7.bin__hadoop-2.6.0/bin/../../hcatalog does not exist! HCatalog jobs will fail. Please set $HCAT_HOME to the root of your HCatalog installation. Warning: /soft/sqoop-1.4.7.bin__hadoop-2.6.0/bin/../../accumulo does not exist! Accumulo imports will fail. Please set $ACCUMULO_HOME to the root of your Accumulo installation. Warning: /soft/sqoop-1.4.7.bin__hadoop-2.6.0/bin/../../zookeeper does not exist! Accumulo imports will fail. Please set $ZOOKEEPER_HOME to the root of your Zookeeper installation. 18/06/14 00:30:34 INFO sqoop.Sqoop: Running Sqoop version: 1.4.7 Sqoop 1.4.7 git commit id 2328971411f57f0cb683dfb79d19d4d19d185dd8 Compiled by maugli on Thu Dec 21 15:59:58 STD 2017 [yinzhengjie@s101 ~]$
二.基本使用
1>.使用sqoop命令行链接MySQL数据库
[yinzhengjie@s101 ~]$ sqoop list-databases --connect jdbc:mysql://s101 --username root -P Warning: /soft/sqoop-1.4.7.bin__hadoop-2.6.0/bin/../../hcatalog does not exist! HCatalog jobs will fail. Please set $HCAT_HOME to the root of your HCatalog installation. Warning: /soft/sqoop-1.4.7.bin__hadoop-2.6.0/bin/../../accumulo does not exist! Accumulo imports will fail. Please set $ACCUMULO_HOME to the root of your Accumulo installation. Warning: /soft/sqoop-1.4.7.bin__hadoop-2.6.0/bin/../../zookeeper does not exist! Accumulo imports will fail. Please set $ZOOKEEPER_HOME to the root of your Zookeeper installation. 18/06/14 00:33:02 INFO sqoop.Sqoop: Running Sqoop version: 1.4.7 Enter password: 18/06/14 00:33:07 INFO manager.MySQLManager: Preparing to use a MySQL streaming resultset. SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/soft/hadoop-2.7.3/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/soft/hbase-1.2.6/lib/phoenix-4.10.0-HBase-1.2-client.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/soft/hbase-1.2.6/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory] information_schema hive mysql performance_schema [yinzhengjie@s101 ~]$
2>.sqoop查看帮助


[yinzhengjie@s101 ~]$ sqoop help Warning: /soft/sqoop-1.4.7.bin__hadoop-2.6.0/bin/../../hcatalog does not exist! HCatalog jobs will fail. Please set $HCAT_HOME to the root of your HCatalog installation. Warning: /soft/sqoop-1.4.7.bin__hadoop-2.6.0/bin/../../accumulo does not exist! Accumulo imports will fail. Please set $ACCUMULO_HOME to the root of your Accumulo installation. Warning: /soft/sqoop-1.4.7.bin__hadoop-2.6.0/bin/../../zookeeper does not exist! Accumulo imports will fail. Please set $ZOOKEEPER_HOME to the root of your Zookeeper installation. 18/06/14 01:50:37 INFO sqoop.Sqoop: Running Sqoop version: 1.4.7 usage: sqoop COMMAND [ARGS] Available commands: codegen Generate code to interact with database records create-hive-table Import a table definition into Hive eval Evaluate a SQL statement and display the results export Export an HDFS directory to a database table help List available commands import Import a table from a database to HDFS import-all-tables Import tables from a database to HDFS import-mainframe Import datasets from a mainframe server to HDFS job Work with saved jobs list-databases List available databases on a server list-tables List available tables in a database merge Merge results of incremental imports metastore Run a standalone Sqoop metastore version Display version information See 'sqoop help COMMAND' for information on a specific command. [yinzhengjie@s101 ~]$
[yinzhengjie@s101 ~]$ sqoop import --help Warning: /soft/sqoop-1.4.7.bin__hadoop-2.6.0/bin/../../hcatalog does not exist! HCatalog jobs will fail. Please set $HCAT_HOME to the root of your HCatalog installation. Warning: /soft/sqoop-1.4.7.bin__hadoop-2.6.0/bin/../../accumulo does not exist! Accumulo imports will fail. Please set $ACCUMULO_HOME to the root of your Accumulo installation. Warning: /soft/sqoop-1.4.7.bin__hadoop-2.6.0/bin/../../zookeeper does not exist! Accumulo imports will fail. Please set $ZOOKEEPER_HOME to the root of your Zookeeper installation. 18/06/14 01:51:04 INFO sqoop.Sqoop: Running Sqoop version: 1.4.7 usage: sqoop import [GENERIC-ARGS] [TOOL-ARGS] Common arguments: --connect <jdbc-uri> Specify JDBC connect string --connection-manager <class-name> Specify connection manager class name --connection-param-file <properties-file> Specify connection parameters file --driver <class-name> Manually specify JDBC driver class to use --hadoop-home <hdir> Override $HADOOP_MAPR ED_HOME_ARG --hadoop-mapred-home <dir> Override $HADOOP_MAPR ED_HOME_ARG --help Print usage instructions --metadata-transaction-isolation-level <isolationlevel> Defines the transaction isolation level for metadata queries. For more details check java.sql.Con nection javadoc or the JDBC specificaito n --oracle-escaping-disabled <boolean> Disable the escaping mechanism of the Oracle/OraOo p connection managers -P Read password from console --password <password> Set authenticati on password --password-alias <password-alias> Credential provider password alias --password-file <password-file> Set authenticati on password file path --relaxed-isolation Use read-uncommi tted isolation for imports --skip-dist-cache Skip copying jars to distributed cache --temporary-rootdir <rootdir> Defines the temporary root directory for the import --throw-on-error Rethrow a RuntimeExcep tion on error occurred during the job --username <username> Set authenticati on username --verbose Print more information while working Import control arguments: --append Imports data in append mode --as-avrodatafile Imports data to Avro data files --as-parquetfile Imports data to Parquet files --as-sequencefile Imports data to SequenceFile s --as-textfile Imports data as plain text (default) --autoreset-to-one-mapper Reset the number of mappers to one mapper if no split key available --boundary-query <statement> Set boundary query for retrieving max and min value of the primary key --columns <col,col,col...> Columns to import from table --compression-codec <codec> Compression codec to use for import --delete-target-dir Imports data in delete mode --direct Use direct import fast path --direct-split-size <n> Split the input stream every 'n' bytes when importing in direct mode -e,--query <statement> Import results of SQL 'statement' --fetch-size <n> Set number 'n' of rows to fetch from the database when more rows are needed --inline-lob-limit <n> Set the maximum size for an inline LOB -m,--num-mappers <n> Use 'n' map tasks to import in parallel --mapreduce-job-name <name> Set name for generated mapreduce job --merge-key <column> Key column to use to join results --split-by <column-name> Column of the table used to split work units --split-limit <size> Upper Limit of rows per split for split columns of Date/Time/Ti mestamp and integer types. For date or timestamp fields it is calculated in seconds. split-limit should be greater than 0 --table <table-name> Table to read --target-dir <dir> HDFS plain table destination --validate Validate the copy using the configured validator --validation-failurehandler <validation-failurehandler> Fully qualified class name for ValidationFa ilureHandler --validation-threshold <validation-threshold> Fully qualified class name for ValidationTh reshold --validator <validator> Fully qualified class name for the Validator --warehouse-dir <dir> HDFS parent for table destination --where <where clause> WHERE clause to use during import -z,--compress Enable compression Incremental import arguments: --check-column <column> Source column to check for incremental change --incremental <import-type> Define an incremental import of type 'append' or 'lastmodified' --last-value <value> Last imported value in the incremental check column Output line formatting arguments: --enclosed-by <char> Sets a required field enclosing character --escaped-by <char> Sets the escape character --fields-terminated-by <char> Sets the field separator character --lines-terminated-by <char> Sets the end-of-line character --mysql-delimiters Uses MySQL's default delimiter set: fields: , lines: escaped-by: optionally-enclosed-by: ' --optionally-enclosed-by <char> Sets a field enclosing character Input parsing arguments: --input-enclosed-by <char> Sets a required field encloser --input-escaped-by <char> Sets the input escape character --input-fields-terminated-by <char> Sets the input field separator --input-lines-terminated-by <char> Sets the input end-of-line char --input-optionally-enclosed-by <char> Sets a field enclosing character Hive arguments: --create-hive-table Fail if the target hive table exists --external-table-dir <hdfs path> Sets where the external table is in HDFS --hive-database <database-name> Sets the database name to use when importing to hive --hive-delims-replacement <arg> Replace Hive record 0x01 and row delimiters ( ) from imported string fields with user-defined string --hive-drop-import-delims Drop Hive record 0x01 and row delimiters ( ) from imported string fields --hive-home <dir> Override $HIVE_HOME --hive-import Import tables into Hive (Uses Hive's default delimiters if none are set.) --hive-overwrite Overwrite existing data in the Hive table --hive-partition-key <partition-key> Sets the partition key to use when importing to hive --hive-partition-value <partition-value> Sets the partition value to use when importing to hive --hive-table <table-name> Sets the table name to use when importing to hive --map-column-hive <arg> Override mapping for specific column to hive types. HBase arguments: --column-family <family> Sets the target column family for the import --hbase-bulkload Enables HBase bulk loading --hbase-create-table If specified, create missing HBase tables --hbase-row-key <col> Specifies which input column to use as the row key --hbase-table <table> Import to <table> in HBase HCatalog arguments: --hcatalog-database <arg> HCatalog database name --hcatalog-home <hdir> Override $HCAT_HOME --hcatalog-partition-keys <partition-key> Sets the partition keys to use when importing to hive --hcatalog-partition-values <partition-value> Sets the partition values to use when importing to hive --hcatalog-table <arg> HCatalog table name --hive-home <dir> Override $HIVE_HOME --hive-partition-key <partition-key> Sets the partition key to use when importing to hive --hive-partition-value <partition-value> Sets the partition value to use when importing to hive --map-column-hive <arg> Override mapping for specific column to hive types. HCatalog import specific options: --create-hcatalog-table Create HCatalog before import --drop-and-create-hcatalog-table Drop and Create HCatalog before import --hcatalog-storage-stanza <arg> HCatalog storage stanza for table creation Accumulo arguments: --accumulo-batch-size <size> Batch size in bytes --accumulo-column-family <family> Sets the target column family for the import --accumulo-create-table If specified, create missing Accumulo tables --accumulo-instance <instance> Accumulo instance name. --accumulo-max-latency <latency> Max write latency in milliseconds --accumulo-password <password> Accumulo password. --accumulo-row-key <col> Specifies which input column to use as the row key --accumulo-table <table> Import to <table> in Accumulo --accumulo-user <user> Accumulo user name. --accumulo-visibility <vis> Visibility token to be applied to all rows imported --accumulo-zookeepers <zookeepers> Comma-separated list of zookeepers (host:port) Code generation arguments: --bindir <dir> Output directory for compiled objects --class-name <name> Sets the generated class name. This overrides --package-name. When combined with --jar-file, sets the input class. --escape-mapping-column-names <boolean> Disable special characters escaping in column names --input-null-non-string <null-str> Input null non-string representation --input-null-string <null-str> Input null string representation --jar-file <file> Disable code generation; use specified jar --map-column-java <arg> Override mapping for specific columns to java types --null-non-string <null-str> Null non-string representation --null-string <null-str> Null string representation --outdir <dir> Output directory for generated code --package-name <name> Put auto-generated classes in this package Generic Hadoop command-line arguments: (must preceed any tool-specific arguments) Generic options supported are -conf <configuration file> specify an application configuration file -D <property=value> use value for given property -fs <local|namenode:port> specify a namenode -jt <local|resourcemanager:port> specify a ResourceManager -files <comma separated list of files> specify comma separated files to be copied to the map reduce cluster -libjars <comma separated list of jars> specify comma separated jar files to include in the classpath. -archives <comma separated list of archives> specify comma separated archives to be unarchived on the compute machines. The general command line syntax is bin/hadoop command [genericOptions] [commandOptions] At minimum, you must specify --connect and --table Arguments to mysqldump and other subprograms may be supplied after a '--' on the command line. [yinzhengjie@s101 ~]$
3>.sqoop列出表
[yinzhengjie@s101 ~]$ sqoop list-tables --connect jdbc:mysql://s101/yinzhengjie --username root -P Warning: /soft/sqoop-1.4.7.bin__hadoop-2.6.0/bin/../../hcatalog does not exist! HCatalog jobs will fail. Please set $HCAT_HOME to the root of your HCatalog installation. Warning: /soft/sqoop-1.4.7.bin__hadoop-2.6.0/bin/../../accumulo does not exist! Accumulo imports will fail. Please set $ACCUMULO_HOME to the root of your Accumulo installation. Warning: /soft/sqoop-1.4.7.bin__hadoop-2.6.0/bin/../../zookeeper does not exist! Accumulo imports will fail. Please set $ZOOKEEPER_HOME to the root of your Zookeeper installation. 18/06/14 01:56:20 INFO sqoop.Sqoop: Running Sqoop version: 1.4.7 Enter password: 18/06/14 01:56:23 INFO manager.MySQLManager: Preparing to use a MySQL streaming resultset. SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/soft/hadoop-2.7.3/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/soft/hbase-1.2.6/lib/phoenix-4.10.0-HBase-1.2-client.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/soft/hbase-1.2.6/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory] Classmate word [yinzhengjie@s101 ~]$
4>.Sqoop列出数据库
[yinzhengjie@s101 ~]$ sqoop list-databases --connect jdbc:mysql://s101 --username root -P Warning: /soft/sqoop-1.4.7.bin__hadoop-2.6.0/bin/../../hcatalog does not exist! HCatalog jobs will fail. Please set $HCAT_HOME to the root of your HCatalog installation. Warning: /soft/sqoop-1.4.7.bin__hadoop-2.6.0/bin/../../accumulo does not exist! Accumulo imports will fail. Please set $ACCUMULO_HOME to the root of your Accumulo installation. Warning: /soft/sqoop-1.4.7.bin__hadoop-2.6.0/bin/../../zookeeper does not exist! Accumulo imports will fail. Please set $ZOOKEEPER_HOME to the root of your Zookeeper installation. 18/06/14 02:05:10 INFO sqoop.Sqoop: Running Sqoop version: 1.4.7 Enter password: 18/06/14 02:05:13 INFO manager.MySQLManager: Preparing to use a MySQL streaming resultset. SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/soft/hadoop-2.7.3/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/soft/hbase-1.2.6/lib/phoenix-4.10.0-HBase-1.2-client.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/soft/hbase-1.2.6/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory] information_schema hive mysql performance_schema yinzhengjie [yinzhengjie@s101 ~]$
三.Sqoop将数据导入HDFS(需要启动hdfs,yarn,MySQL等相关服务)
1>.在数据库进行授权操作
mysql> grant all PRIVILEGES on *.* to root@'s101' identified by 'yinzhengjie'; Query OK, 0 rows affected (0.31 sec) mysql> grant all PRIVILEGES on *.* to root@'s102' identified by 'yinzhengjie'; Query OK, 0 rows affected (0.02 sec) mysql> grant all PRIVILEGES on *.* to root@'s103' identified by 'yinzhengjie'; Query OK, 0 rows affected (0.00 sec) mysql> grant all PRIVILEGES on *.* to root@'s104' identified by 'yinzhengjie'; Query OK, 0 rows affected (0.00 sec) mysql> grant all PRIVILEGES on *.* to root@'s105' identified by 'yinzhengjie'; Query OK, 0 rows affected (0.00 sec) mysql> flush privileges; Query OK, 0 rows affected (0.02 sec) mysql>
2>.将数据库的数据导入到hdfs中
[yinzhengjie@s101 ~]$ sqoop import --connect jdbc:mysql://s101/yinzhengjie --username root -P --table word --fields-terminated-by ' ' --target-dir /wc -m 1 Warning: /soft/sqoop-1.4.7.bin__hadoop-2.6.0/bin/../../hcatalog does not exist! HCatalog jobs will fail. Please set $HCAT_HOME to the root of your HCatalog installation. Warning: /soft/sqoop-1.4.7.bin__hadoop-2.6.0/bin/../../accumulo does not exist! Accumulo imports will fail. Please set $ACCUMULO_HOME to the root of your Accumulo installation. Warning: /soft/sqoop-1.4.7.bin__hadoop-2.6.0/bin/../../zookeeper does not exist! Accumulo imports will fail. Please set $ZOOKEEPER_HOME to the root of your Zookeeper installation. 18/06/14 02:16:01 INFO sqoop.Sqoop: Running Sqoop version: 1.4.7 Enter password: 18/06/14 02:16:03 INFO manager.MySQLManager: Preparing to use a MySQL streaming resultset. 18/06/14 02:16:03 INFO tool.CodeGenTool: Beginning code generation SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/soft/hadoop-2.7.3/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/soft/hbase-1.2.6/lib/phoenix-4.10.0-HBase-1.2-client.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/soft/hbase-1.2.6/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory] 18/06/14 02:16:04 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `word` AS t LIMIT 1 18/06/14 02:16:04 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `word` AS t LIMIT 1 18/06/14 02:16:04 INFO orm.CompilationManager: HADOOP_MAPRED_HOME is /soft/hadoop Note: /tmp/sqoop-yinzhengjie/compile/506dbf41a3a9165eebe93e9d2ec30818/word.java uses or overrides a deprecated API. Note: Recompile with -Xlint:deprecation for details. 18/06/14 02:16:05 INFO orm.CompilationManager: Writing jar file: /tmp/sqoop-yinzhengjie/compile/506dbf41a3a9165eebe93e9d2ec30818/word.jar 18/06/14 02:16:05 WARN manager.MySQLManager: It looks like you are importing from mysql. 18/06/14 02:16:05 WARN manager.MySQLManager: This transfer can be faster! Use the --direct 18/06/14 02:16:05 WARN manager.MySQLManager: option to exercise a MySQL-specific fast path. 18/06/14 02:16:05 INFO manager.MySQLManager: Setting zero DATETIME behavior to convertToNull (mysql) 18/06/14 02:16:05 INFO mapreduce.ImportJobBase: Beginning import of word 18/06/14 02:16:06 INFO Configuration.deprecation: mapred.jar is deprecated. Instead, use mapreduce.job.jar 18/06/14 02:16:06 INFO Configuration.deprecation: mapred.map.tasks is deprecated. Instead, use mapreduce.job.maps 18/06/14 02:16:14 INFO db.DBInputFormat: Using read commited transaction isolation 18/06/14 02:16:14 INFO mapreduce.JobSubmitter: number of splits:1 18/06/14 02:16:15 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1528967628934_0002 18/06/14 02:16:15 INFO impl.YarnClientImpl: Submitted application application_1528967628934_0002 18/06/14 02:16:15 INFO mapreduce.Job: The url to track the job: http://s101:8088/proxy/application_1528967628934_0002/ 18/06/14 02:16:15 INFO mapreduce.Job: Running job: job_1528967628934_0002 18/06/14 02:16:22 INFO mapreduce.Job: Job job_1528967628934_0002 running in uber mode : false 18/06/14 02:16:22 INFO mapreduce.Job: map 0% reduce 0% 18/06/14 02:16:27 INFO mapreduce.Job: Task Id : attempt_1528967628934_0002_m_000000_0, Status : FAILED Error: java.lang.RuntimeException: java.lang.RuntimeException: java.sql.SQLException: null, message from server: "Host 's105' is not allowed to connect to this MySQL server" at org.apache.sqoop.mapreduce.db.DBInputFormat.setDbConf(DBInputFormat.java:170) at org.apache.sqoop.mapreduce.db.DBInputFormat.setConf(DBInputFormat.java:161) at org.apache.hadoop.util.ReflectionUtils.setConf(ReflectionUtils.java:76) at org.apache.hadoop.util.ReflectionUtils.newInstance(ReflectionUtils.java:136) at org.apache.hadoop.mapred.MapTask.runNewMapper(MapTask.java:749) at org.apache.hadoop.mapred.MapTask.run(MapTask.java:341) at org.apache.hadoop.mapred.YarnChild$2.run(YarnChild.java:164) at java.security.AccessController.doPrivileged(Native Method) at javax.security.auth.Subject.doAs(Subject.java:422) at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1698) at org.apache.hadoop.mapred.YarnChild.main(YarnChild.java:158) Caused by: java.lang.RuntimeException: java.sql.SQLException: null, message from server: "Host 's105' is not allowed to connect to this MySQL server" at org.apache.sqoop.mapreduce.db.DBInputFormat.getConnection(DBInputFormat.java:223) at org.apache.sqoop.mapreduce.db.DBInputFormat.setDbConf(DBInputFormat.java:168) ... 10 more Caused by: java.sql.SQLException: null, message from server: "Host 's105' is not allowed to connect to this MySQL server" at com.mysql.jdbc.SQLError.createSQLException(SQLError.java:964) at com.mysql.jdbc.SQLError.createSQLException(SQLError.java:897) at com.mysql.jdbc.SQLError.createSQLException(SQLError.java:886) at com.mysql.jdbc.MysqlIO.doHandshake(MysqlIO.java:1040) at com.mysql.jdbc.ConnectionImpl.coreConnect(ConnectionImpl.java:2205) at com.mysql.jdbc.ConnectionImpl.connectOneTryOnly(ConnectionImpl.java:2236) at com.mysql.jdbc.ConnectionImpl.createNewIO(ConnectionImpl.java:2035) at com.mysql.jdbc.ConnectionImpl.<init>(ConnectionImpl.java:790) at com.mysql.jdbc.JDBC4Connection.<init>(JDBC4Connection.java:47) at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method) at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62) at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45) at java.lang.reflect.Constructor.newInstance(Constructor.java:423) at com.mysql.jdbc.Util.handleNewInstance(Util.java:425) at com.mysql.jdbc.ConnectionImpl.getInstance(ConnectionImpl.java:400) at com.mysql.jdbc.NonRegisteringDriver.connect(NonRegisteringDriver.java:330) at java.sql.DriverManager.getConnection(DriverManager.java:664) at java.sql.DriverManager.getConnection(DriverManager.java:247) at org.apache.sqoop.mapreduce.db.DBConfiguration.getConnection(DBConfiguration.java:302) at org.apache.sqoop.mapreduce.db.DBInputFormat.getConnection(DBInputFormat.java:216) ... 11 more Container killed by the ApplicationMaster. Container killed on request. Exit code is 143 Container exited with a non-zero exit code 143 18/06/14 02:16:35 INFO mapreduce.Job: map 100% reduce 0% 18/06/14 02:16:36 INFO mapreduce.Job: Job job_1528967628934_0002 completed successfully 18/06/14 02:16:36 INFO mapreduce.Job: Counters: 31 File System Counters FILE: Number of bytes read=0 FILE: Number of bytes written=140325 FILE: Number of read operations=0 FILE: Number of large read operations=0 FILE: Number of write operations=0 HDFS: Number of bytes read=87 HDFS: Number of bytes written=74 HDFS: Number of read operations=4 HDFS: Number of large read operations=0 HDFS: Number of write operations=2 Job Counters Failed map tasks=1 Launched map tasks=2 Other local map tasks=2 Total time spent by all maps in occupied slots (ms)=8181 Total time spent by all reduces in occupied slots (ms)=0 Total time spent by all map tasks (ms)=8181 Total vcore-milliseconds taken by all map tasks=8181 Total megabyte-milliseconds taken by all map tasks=8377344 Map-Reduce Framework Map input records=4 Map output records=4 Input split bytes=87 Spilled Records=0 Failed Shuffles=0 Merged Map outputs=0 GC time elapsed (ms)=80 CPU time spent (ms)=1120 Physical memory (bytes) snapshot=104509440 Virtual memory (bytes) snapshot=2086359040 Total committed heap usage (bytes)=19701760 File Input Format Counters Bytes Read=0 File Output Format Counters Bytes Written=74 18/06/14 02:16:36 INFO mapreduce.ImportJobBase: Transferred 74 bytes in 29.3085 seconds (2.5249 bytes/sec) 18/06/14 02:16:36 INFO mapreduce.ImportJobBase: Retrieved 4 records. [yinzhengjie@s101 ~]$ hdfs dfs -cat /wc/part-m-00000 1 hello world 2 yinzhengjie hadoop 2 yinzhengjie hive 2 yinzhengjie hbase [yinzhengjie@s101 ~]$
[yinzhengjie@s101 ~]$ hdfs dfs -cat /wc/part-m-00000 1 hello world 2 yinzhengjie hadoop 2 yinzhengjie hive 2 yinzhengjie hbase [yinzhengjie@s101 ~]$
3>.在hdfs的WebUI中查看数据
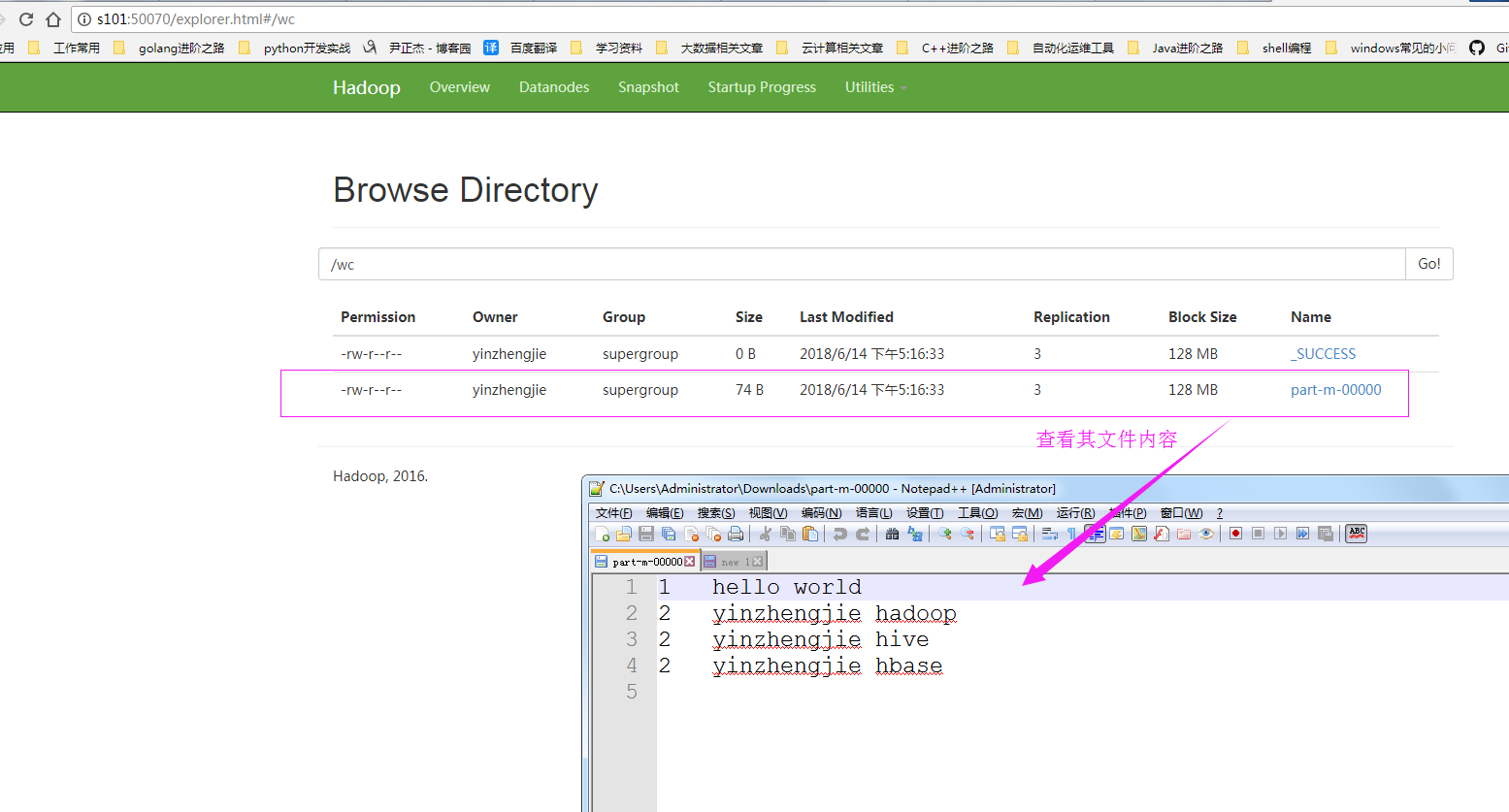
4>.其他参数介绍
--table //指定导入mysql表 -m //mapper数量 --target-dir //指定导入hdfs的目录 --fields-terminated-by //指定列分隔符 --lines-terminated-by //指定行分隔符 --append //追加 --as-avrodatafile //设置文件格式为avrodatafile --as-parquetfile · //设置文件格式为parquetfile --as-sequencefile //设置文件格式为sequencefile --as-textfile //设置文件格式为textfile --columns <col,col,col...> //指定导入的mysql列 --compression-codec <codec> //制定压缩
四.sqoop导入mysql数据到hive(需要启动hdfs,yarn,MySQL等相关服务,hive不需要手动启动,因为导入的时候它自己会自行启动)
1>.修改sqoop-env.sh
[yinzhengjie@s101 ~]$ tail -2 /soft/sqoop/conf/sqoop-env.sh #ADD BY YINZHENGJIE export HIVE_CONF_DIR=/soft/hive/conf [yinzhengjie@s101 ~]$
2>.编辑环境变量
[yinzhengjie@s101 ~]$ sudo vi /etc/profile [sudo] password for yinzhengjie: [yinzhengjie@s101 ~]$ [yinzhengjie@s101 ~]$ tail -2 /etc/profile #ADD sqool import hive export HADOOP_CLASSPATH=$HADOOP_CLASSPATH:$HIVE_HOME/lib/* [yinzhengjie@s101 ~]$ [yinzhengjie@s101 ~]$ source /etc/profile [yinzhengjie@s101 ~]$
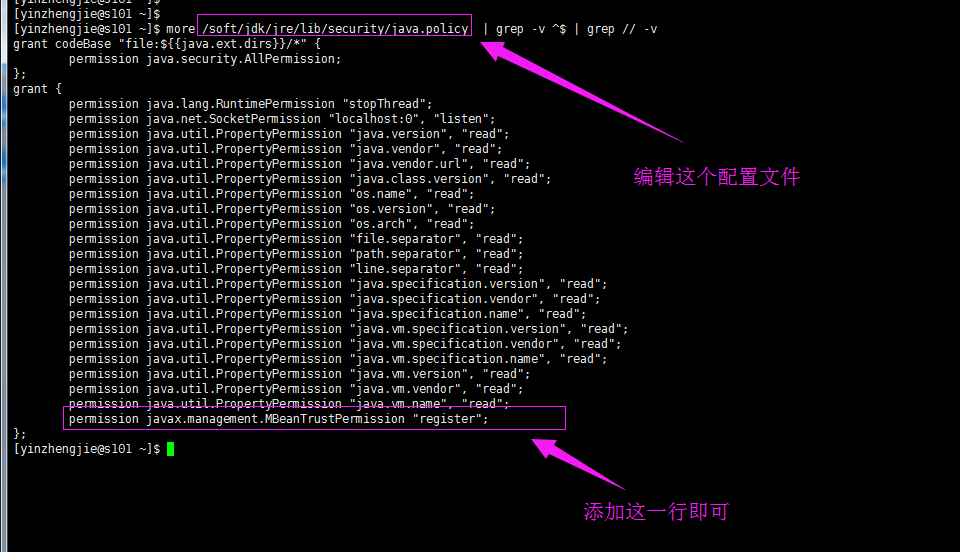
3>.关闭安全方面的异常信息(不修改也不会影响测试结果)
4>.导入数据到hive中
0: jdbc:hive2://s101:10000> show tables; +---------------+--+ | tab_name | +---------------+--+ | pv | | user_orc | | user_parquet | | user_rc | | user_seq | | user_text | | users | +---------------+--+ 7 rows selected (0.061 seconds) 0: jdbc:hive2://s101:10000>
[yinzhengjie@s101 ~]$ sqoop import --connect jdbc:mysql://s101/yinzhengjie --username root -P --table word --fields-terminated-by ' ' --hive-import --create-hive-table --hive-database yinzhengjie --hive-table wc -m 1 Warning: /soft/sqoop-1.4.7.bin__hadoop-2.6.0/bin/../../hcatalog does not exist! HCatalog jobs will fail. Please set $HCAT_HOME to the root of your HCatalog installation. Warning: /soft/sqoop-1.4.7.bin__hadoop-2.6.0/bin/../../accumulo does not exist! Accumulo imports will fail. Please set $ACCUMULO_HOME to the root of your Accumulo installation. Warning: /soft/sqoop-1.4.7.bin__hadoop-2.6.0/bin/../../zookeeper does not exist! Accumulo imports will fail. Please set $ZOOKEEPER_HOME to the root of your Zookeeper installation. 18/06/14 03:00:35 INFO sqoop.Sqoop: Running Sqoop version: 1.4.7 Enter password: 18/06/14 03:00:39 INFO manager.MySQLManager: Preparing to use a MySQL streaming resultset. 18/06/14 03:00:39 INFO tool.CodeGenTool: Beginning code generation SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/soft/hadoop-2.7.3/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/soft/hbase-1.2.6/lib/phoenix-4.10.0-HBase-1.2-client.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/soft/hbase-1.2.6/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/soft/apache-hive-2.1.1-bin/lib/log4j-slf4j-impl-2.4.1.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory] 18/06/14 03:00:40 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `word` AS t LIMIT 1 18/06/14 03:00:40 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `word` AS t LIMIT 1 18/06/14 03:00:40 INFO orm.CompilationManager: HADOOP_MAPRED_HOME is /soft/hadoop Note: /tmp/sqoop-yinzhengjie/compile/a904d79d3e86841540489a5459400e8b/word.java uses or overrides a deprecated API. Note: Recompile with -Xlint:deprecation for details. 18/06/14 03:00:43 INFO orm.CompilationManager: Writing jar file: /tmp/sqoop-yinzhengjie/compile/a904d79d3e86841540489a5459400e8b/word.jar 18/06/14 03:00:43 WARN manager.MySQLManager: It looks like you are importing from mysql. 18/06/14 03:00:43 WARN manager.MySQLManager: This transfer can be faster! Use the --direct 18/06/14 03:00:43 WARN manager.MySQLManager: option to exercise a MySQL-specific fast path. 18/06/14 03:00:43 INFO manager.MySQLManager: Setting zero DATETIME behavior to convertToNull (mysql) 18/06/14 03:00:43 INFO mapreduce.ImportJobBase: Beginning import of word 18/06/14 03:00:43 INFO Configuration.deprecation: mapred.jar is deprecated. Instead, use mapreduce.job.jar 18/06/14 03:00:44 INFO Configuration.deprecation: mapred.map.tasks is deprecated. Instead, use mapreduce.job.maps 18/06/14 03:00:56 INFO db.DBInputFormat: Using read commited transaction isolation 18/06/14 03:00:57 INFO mapreduce.JobSubmitter: number of splits:1 18/06/14 03:00:57 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1528967628934_0005 18/06/14 03:00:59 INFO impl.YarnClientImpl: Submitted application application_1528967628934_0005 18/06/14 03:00:59 INFO mapreduce.Job: The url to track the job: http://s101:8088/proxy/application_1528967628934_0005/ 18/06/14 03:00:59 INFO mapreduce.Job: Running job: job_1528967628934_0005 18/06/14 03:01:18 INFO mapreduce.Job: Job job_1528967628934_0005 running in uber mode : false 18/06/14 03:01:18 INFO mapreduce.Job: map 0% reduce 0% 18/06/14 03:01:41 INFO mapreduce.Job: map 100% reduce 0% 18/06/14 03:01:42 INFO mapreduce.Job: Job job_1528967628934_0005 completed successfully 18/06/14 03:01:43 INFO mapreduce.Job: Counters: 30 File System Counters FILE: Number of bytes read=0 FILE: Number of bytes written=140344 FILE: Number of read operations=0 FILE: Number of large read operations=0 FILE: Number of write operations=0 HDFS: Number of bytes read=87 HDFS: Number of bytes written=74 HDFS: Number of read operations=4 HDFS: Number of large read operations=0 HDFS: Number of write operations=2 Job Counters Launched map tasks=1 Other local map tasks=1 Total time spent by all maps in occupied slots (ms)=19876 Total time spent by all reduces in occupied slots (ms)=0 Total time spent by all map tasks (ms)=19876 Total vcore-milliseconds taken by all map tasks=19876 Total megabyte-milliseconds taken by all map tasks=20353024 Map-Reduce Framework Map input records=4 Map output records=4 Input split bytes=87 Spilled Records=0 Failed Shuffles=0 Merged Map outputs=0 GC time elapsed (ms)=82 CPU time spent (ms)=1120 Physical memory (bytes) snapshot=89550848 Virtual memory (bytes) snapshot=2086518784 Total committed heap usage (bytes)=18808832 File Input Format Counters Bytes Read=0 File Output Format Counters Bytes Written=74 18/06/14 03:01:43 INFO mapreduce.ImportJobBase: Transferred 74 bytes in 58.4206 seconds (1.2667 bytes/sec) 18/06/14 03:01:43 INFO mapreduce.ImportJobBase: Retrieved 4 records. 18/06/14 03:01:43 INFO mapreduce.ImportJobBase: Publishing Hive/Hcat import job data to Listeners for table word 18/06/14 03:01:43 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `word` AS t LIMIT 1 18/06/14 03:01:44 INFO hive.HiveImport: Loading uploaded data into Hive 18/06/14 03:01:45 INFO conf.HiveConf: Found configuration file file:/soft/hive/conf/hive-site.xml Logging initialized using configuration in jar:file:/soft/apache-hive-2.1.1-bin/lib/hive-common-2.1.1.jar!/hive-log4j2.properties Async: true 18/06/14 03:01:48 INFO SessionState: Logging initialized using configuration in jar:file:/soft/apache-hive-2.1.1-bin/lib/hive-common-2.1.1.jar!/hive-log4j2.properties Async: true 18/06/14 03:01:51 INFO metastore.HiveMetaStore: 0: Opening raw store with implementation class:org.apache.hadoop.hive.metastore.ObjectStore 18/06/14 03:01:57 INFO metastore.ObjectStore: ObjectStore, initialize called 18/06/14 03:01:57 INFO DataNucleus.Persistence: Property hive.metastore.integral.jdo.pushdown unknown - will be ignored 18/06/14 03:01:57 INFO DataNucleus.Persistence: Property datanucleus.cache.level2 unknown - will be ignored 18/06/14 03:02:00 INFO metastore.ObjectStore: Setting MetaStore object pin classes with hive.metastore.cache.pinobjtypes="Table,StorageDescriptor,SerDeInfo,Partition,Database,Type,FieldSchema,Order" 18/06/14 03:02:04 INFO metastore.MetaStoreDirectSql: Using direct SQL, underlying DB is MYSQL 18/06/14 03:02:04 INFO metastore.ObjectStore: Initialized ObjectStore 18/06/14 03:02:05 INFO metastore.HiveMetaStore: Added admin role in metastore 18/06/14 03:02:05 INFO metastore.HiveMetaStore: Added public role in metastore 18/06/14 03:02:05 INFO metastore.HiveMetaStore: No user is added in admin role, since config is empty 18/06/14 03:02:05 INFO metastore.HiveMetaStore: 0: get_all_functions 18/06/14 03:02:05 INFO HiveMetaStore.audit: ugi=yinzhengjie ip=unknown-ip-addr cmd=get_all_functions 18/06/14 03:02:05 INFO metadata.Hive: Registering function parsejson cn.org.yinzhengjie.udf.ParseJson 18/06/14 03:02:06 WARN metadata.Hive: Failed to register persistent function parsejson:cn.org.yinzhengjie.udf.ParseJson. Ignore and continue. 18/06/14 03:02:06 INFO metadata.Hive: Registering function parsejson cn.org.yinzhengjie.udf.MyUDTF 18/06/14 03:02:06 WARN metadata.Hive: Failed to register persistent function parsejson:cn.org.yinzhengjie.udf.MyUDTF. Ignore and continue. 18/06/14 03:02:06 INFO metadata.Hive: Registering function todate cn.org.yinzhengjie.udf.MyUDTF 18/06/14 03:02:06 WARN metadata.Hive: Failed to register persistent function todate:cn.org.yinzhengjie.udf.MyUDTF. Ignore and continue. 18/06/14 03:02:06 INFO session.SessionState: Created HDFS directory: /tmp/hive/yinzhengjie/ab78aeaa-274a-4ed6-bff0-ffa488a2c8df 18/06/14 03:02:07 INFO session.SessionState: Created local directory: /home/yinzhengjie/yinzhengjie/ab78aeaa-274a-4ed6-bff0-ffa488a2c8df 18/06/14 03:02:07 INFO session.SessionState: Created HDFS directory: /tmp/hive/yinzhengjie/ab78aeaa-274a-4ed6-bff0-ffa488a2c8df/_tmp_space.db 18/06/14 03:02:07 INFO conf.HiveConf: Using the default value passed in for log id: ab78aeaa-274a-4ed6-bff0-ffa488a2c8df 18/06/14 03:02:07 INFO session.SessionState: Updating thread name to ab78aeaa-274a-4ed6-bff0-ffa488a2c8df main 18/06/14 03:02:07 INFO conf.HiveConf: Using the default value passed in for log id: ab78aeaa-274a-4ed6-bff0-ffa488a2c8df 18/06/14 03:02:07 INFO ql.Driver: Compiling command(queryId=yinzhengjie_20180614030207_d95714d9-84da-405e-97b6-d9f36436e2f2): CREATE TABLE `yinzhengjie`.`wc` ( `id` INT, `string` STRING) COMMENT 'Imported by sqoop on 2018/06/14 03:01:43' ROW FORMAT DELIMITED FIELDS TERMINATED BY '�11' LINES TERMINATED BY '�12' STORED AS TEXTFILE 18/06/14 03:02:08 INFO parse.CalcitePlanner: Starting Semantic Analysis 18/06/14 03:02:08 INFO parse.CalcitePlanner: Creating table yinzhengjie.wc position=13 18/06/14 03:02:09 INFO metastore.HiveMetaStore: 0: get_database: yinzhengjie 18/06/14 03:02:09 INFO HiveMetaStore.audit: ugi=yinzhengjie ip=unknown-ip-addr cmd=get_database: yinzhengjie 18/06/14 03:02:09 INFO sqlstd.SQLStdHiveAccessController: Created SQLStdHiveAccessController for session context : HiveAuthzSessionContext [sessionString=ab78aeaa-274a-4ed6-bff0-ffa488a2c8df, clientType=HIVECLI] 18/06/14 03:02:09 WARN session.SessionState: METASTORE_FILTER_HOOK will be ignored, since hive.security.authorization.manager is set to instance of HiveAuthorizerFactory. 18/06/14 03:02:09 INFO hive.metastore: Mestastore configuration hive.metastore.filter.hook changed from org.apache.hadoop.hive.metastore.DefaultMetaStoreFilterHookImpl to org.apache.hadoop.hive.ql.security.authorization.plugin.AuthorizationMetaStoreFilterHook 18/06/14 03:02:09 INFO metastore.HiveMetaStore: 0: Cleaning up thread local RawStore... 18/06/14 03:02:09 INFO HiveMetaStore.audit: ugi=yinzhengjie ip=unknown-ip-addr cmd=Cleaning up thread local RawStore... 18/06/14 03:02:09 INFO metastore.HiveMetaStore: 0: Done cleaning up thread local RawStore 18/06/14 03:02:09 INFO HiveMetaStore.audit: ugi=yinzhengjie ip=unknown-ip-addr cmd=Done cleaning up thread local RawStore 18/06/14 03:02:09 INFO ql.Driver: Semantic Analysis Completed 18/06/14 03:02:09 INFO ql.Driver: Returning Hive schema: Schema(fieldSchemas:null, properties:null) 18/06/14 03:02:09 INFO ql.Driver: Completed compiling command(queryId=yinzhengjie_20180614030207_d95714d9-84da-405e-97b6-d9f36436e2f2); Time taken: 2.447 seconds 18/06/14 03:02:09 INFO ql.Driver: Concurrency mode is disabled, not creating a lock manager 18/06/14 03:02:09 INFO ql.Driver: Executing command(queryId=yinzhengjie_20180614030207_d95714d9-84da-405e-97b6-d9f36436e2f2): CREATE TABLE `yinzhengjie`.`wc` ( `id` INT, `string` STRING) COMMENT 'Imported by sqoop on 2018/06/14 03:01:43' ROW FORMAT DELIMITED FIELDS TERMINATED BY '�11' LINES TERMINATED BY '�12' STORED AS TEXTFILE 18/06/14 03:02:10 INFO ql.Driver: Starting task [Stage-0:DDL] in serial mode 18/06/14 03:02:10 INFO exec.DDLTask: creating table yinzhengjie.wc on null 18/06/14 03:02:10 INFO metastore.HiveMetaStore: 0: create_table: Table(tableName:wc, dbName:yinzhengjie, owner:yinzhengjie, createTime:1528970530, lastAccessTime:0, retention:0, sd:StorageDescriptor(cols:[FieldSchema(name:id, type:int, comment:null), FieldSchema(name:string, type:string, comment:null)], location:null, inputFormat:org.apache.hadoop.mapred.TextInputFormat, outputFormat:org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat, compressed:false, numBuckets:-1, serdeInfo:SerDeInfo(name:null, serializationLib:org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe, parameters:{serialization.format= , line.delim= , field.delim= }), bucketCols:[], sortCols:[], parameters:{}, skewedInfo:SkewedInfo(skewedColNames:[], skewedColValues:[], skewedColValueLocationMaps:{}), storedAsSubDirectories:false), partitionKeys:[], parameters:{totalSize=0, numRows=0, rawDataSize=0, COLUMN_STATS_ACCURATE={"BASIC_STATS":"true"}, numFiles=0, comment=Imported by sqoop on 2018/06/14 03:01:43}, viewOriginalText:null, viewExpandedText:null, tableType:MANAGED_TABLE, privileges:PrincipalPrivilegeSet(userPrivileges:{yinzhengjie=[PrivilegeGrantInfo(privilege:INSERT, createTime:-1, grantor:yinzhengjie, grantorType:USER, grantOption:true), PrivilegeGrantInfo(privilege:SELECT, createTime:-1, grantor:yinzhengjie, grantorType:USER, grantOption:true), PrivilegeGrantInfo(privilege:UPDATE, createTime:-1, grantor:yinzhengjie, grantorType:USER, grantOption:true), PrivilegeGrantInfo(privilege:DELETE, createTime:-1, grantor:yinzhengjie, grantorType:USER, grantOption:true)]}, groupPrivileges:null, rolePrivileges:null), temporary:false) 18/06/14 03:02:10 INFO HiveMetaStore.audit: ugi=yinzhengjie ip=unknown-ip-addr cmd=create_table: Table(tableName:wc, dbName:yinzhengjie, owner:yinzhengjie, createTime:1528970530, lastAccessTime:0, retention:0, sd:StorageDescriptor(cols:[FieldSchema(name:id, type:int, comment:null), FieldSchema(name:string, type:string, comment:null)], location:null, inputFormat:org.apache.hadoop.mapred.TextInputFormat, outputFormat:org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat, compressed:false, numBuckets:-1, serdeInfo:SerDeInfo(name:null, serializationLib:org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe, parameters:{serialization.format= , line.delim= , field.delim= }), bucketCols:[], sortCols:[], parameters:{}, skewedInfo:SkewedInfo(skewedColNames:[], skewedColValues:[], skewedColValueLocationMaps:{}), storedAsSubDirectories:false), partitionKeys:[], parameters:{totalSize=0, numRows=0, rawDataSize=0, COLUMN_STATS_ACCURATE={"BASIC_STATS":"true"}, numFiles=0, comment=Imported by sqoop on 2018/06/14 03:01:43}, viewOriginalText:null, viewExpandedText:null, tableType:MANAGED_TABLE, privileges:PrincipalPrivilegeSet(userPrivileges:{yinzhengjie=[PrivilegeGrantInfo(privilege:INSERT, createTime:-1, grantor:yinzhengjie, grantorType:USER, grantOption:true), PrivilegeGrantInfo(privilege:SELECT, createTime:-1, grantor:yinzhengjie, grantorType:USER, grantOption:true), PrivilegeGrantInfo(privilege:UPDATE, createTime:-1, grantor:yinzhengjie, grantorType:USER, grantOption:true), PrivilegeGrantInfo(privilege:DELETE, createTime:-1, grantor:yinzhengjie, grantorType:USER, grantOption:true)]}, groupPrivileges:null, rolePrivileges:null), temporary:false) 18/06/14 03:02:10 INFO metastore.HiveMetaStore: 0: Opening raw store with implementation class:org.apache.hadoop.hive.metastore.ObjectStore 18/06/14 03:02:10 INFO metastore.ObjectStore: ObjectStore, initialize called 18/06/14 03:02:10 INFO metastore.MetaStoreDirectSql: Using direct SQL, underlying DB is MYSQL 18/06/14 03:02:10 INFO metastore.ObjectStore: Initialized ObjectStore 18/06/14 03:02:10 INFO common.FileUtils: Creating directory if it doesn't exist: hdfs://mycluster/user/hive/warehouse/yinzhengjie.db/wc 18/06/14 03:02:11 INFO metadata.Hive: Dumping metastore api call timing information for : execution phase 18/06/14 03:02:11 INFO metadata.Hive: Total time spent in this metastore function was greater than 1000ms : createTable_(Table, )=1144 18/06/14 03:02:11 INFO ql.Driver: Completed executing command(queryId=yinzhengjie_20180614030207_d95714d9-84da-405e-97b6-d9f36436e2f2); Time taken: 1.668 seconds OK 18/06/14 03:02:11 INFO ql.Driver: OK Time taken: 4.152 seconds 18/06/14 03:02:11 INFO CliDriver: Time taken: 4.152 seconds 18/06/14 03:02:11 INFO conf.HiveConf: Using the default value passed in for log id: ab78aeaa-274a-4ed6-bff0-ffa488a2c8df 18/06/14 03:02:11 INFO session.SessionState: Resetting thread name to main 18/06/14 03:02:11 INFO conf.HiveConf: Using the default value passed in for log id: ab78aeaa-274a-4ed6-bff0-ffa488a2c8df 18/06/14 03:02:11 INFO session.SessionState: Updating thread name to ab78aeaa-274a-4ed6-bff0-ffa488a2c8df main 18/06/14 03:02:11 INFO ql.Driver: Compiling command(queryId=yinzhengjie_20180614030211_2b878339-754f-4d7d-985d-fe9b86f5ec88): LOAD DATA INPATH 'hdfs://mycluster/user/yinzhengjie/word' INTO TABLE `yinzhengjie`.`wc` 18/06/14 03:02:11 INFO metastore.HiveMetaStore: 0: get_table : db=yinzhengjie tbl=wc 18/06/14 03:02:11 INFO HiveMetaStore.audit: ugi=yinzhengjie ip=unknown-ip-addr cmd=get_table : db=yinzhengjie tbl=wc 18/06/14 03:02:12 INFO ql.Driver: Semantic Analysis Completed 18/06/14 03:02:12 INFO ql.Driver: Returning Hive schema: Schema(fieldSchemas:null, properties:null) 18/06/14 03:02:12 INFO ql.Driver: Completed compiling command(queryId=yinzhengjie_20180614030211_2b878339-754f-4d7d-985d-fe9b86f5ec88); Time taken: 0.987 seconds 18/06/14 03:02:12 INFO ql.Driver: Concurrency mode is disabled, not creating a lock manager 18/06/14 03:02:12 INFO ql.Driver: Executing command(queryId=yinzhengjie_20180614030211_2b878339-754f-4d7d-985d-fe9b86f5ec88): LOAD DATA INPATH 'hdfs://mycluster/user/yinzhengjie/word' INTO TABLE `yinzhengjie`.`wc` 18/06/14 03:02:12 INFO ql.Driver: Starting task [Stage-0:MOVE] in serial mode Loading data to table yinzhengjie.wc 18/06/14 03:02:12 INFO exec.Task: Loading data to table yinzhengjie.wc from hdfs://mycluster/user/yinzhengjie/word 18/06/14 03:02:12 INFO metastore.HiveMetaStore: 0: get_table : db=yinzhengjie tbl=wc 18/06/14 03:02:12 INFO HiveMetaStore.audit: ugi=yinzhengjie ip=unknown-ip-addr cmd=get_table : db=yinzhengjie tbl=wc 18/06/14 03:02:12 INFO metastore.HiveMetaStore: 0: get_table : db=yinzhengjie tbl=wc 18/06/14 03:02:12 INFO HiveMetaStore.audit: ugi=yinzhengjie ip=unknown-ip-addr cmd=get_table : db=yinzhengjie tbl=wc 18/06/14 03:02:12 ERROR hdfs.KeyProviderCache: Could not find uri with key [dfs.encryption.key.provider.uri] to create a keyProvider !! 18/06/14 03:02:13 INFO metastore.HiveMetaStore: 0: alter_table: db=yinzhengjie tbl=wc newtbl=wc 18/06/14 03:02:13 INFO HiveMetaStore.audit: ugi=yinzhengjie ip=unknown-ip-addr cmd=alter_table: db=yinzhengjie tbl=wc newtbl=wc 18/06/14 03:02:13 INFO ql.Driver: Starting task [Stage-1:STATS] in serial mode 18/06/14 03:02:13 INFO exec.StatsTask: Executing stats task 18/06/14 03:02:13 INFO metastore.HiveMetaStore: 0: get_table : db=yinzhengjie tbl=wc 18/06/14 03:02:13 INFO HiveMetaStore.audit: ugi=yinzhengjie ip=unknown-ip-addr cmd=get_table : db=yinzhengjie tbl=wc 18/06/14 03:02:13 INFO metastore.HiveMetaStore: 0: get_table : db=yinzhengjie tbl=wc 18/06/14 03:02:13 INFO HiveMetaStore.audit: ugi=yinzhengjie ip=unknown-ip-addr cmd=get_table : db=yinzhengjie tbl=wc 18/06/14 03:02:13 INFO metastore.HiveMetaStore: 0: alter_table: db=yinzhengjie tbl=wc newtbl=wc 18/06/14 03:02:13 INFO HiveMetaStore.audit: ugi=yinzhengjie ip=unknown-ip-addr cmd=alter_table: db=yinzhengjie tbl=wc newtbl=wc 18/06/14 03:02:13 INFO hive.log: Updating table stats fast for wc 18/06/14 03:02:13 INFO hive.log: Updated size of table wc to 74 18/06/14 03:02:13 INFO exec.StatsTask: Table yinzhengjie.wc stats: [numFiles=1, numRows=0, totalSize=74, rawDataSize=0] 18/06/14 03:02:13 INFO ql.Driver: Completed executing command(queryId=yinzhengjie_20180614030211_2b878339-754f-4d7d-985d-fe9b86f5ec88); Time taken: 0.858 seconds OK 18/06/14 03:02:13 INFO ql.Driver: OK Time taken: 1.847 seconds 18/06/14 03:02:13 INFO CliDriver: Time taken: 1.847 seconds 18/06/14 03:02:13 INFO conf.HiveConf: Using the default value passed in for log id: ab78aeaa-274a-4ed6-bff0-ffa488a2c8df 18/06/14 03:02:13 INFO session.SessionState: Resetting thread name to main 18/06/14 03:02:13 INFO conf.HiveConf: Using the default value passed in for log id: ab78aeaa-274a-4ed6-bff0-ffa488a2c8df 18/06/14 03:02:13 INFO session.SessionState: Deleted directory: /tmp/hive/yinzhengjie/ab78aeaa-274a-4ed6-bff0-ffa488a2c8df on fs with scheme hdfs 18/06/14 03:02:13 INFO session.SessionState: Deleted directory: /home/yinzhengjie/yinzhengjie/ab78aeaa-274a-4ed6-bff0-ffa488a2c8df on fs with scheme file 18/06/14 03:02:13 INFO metastore.HiveMetaStore: 0: Cleaning up thread local RawStore... 18/06/14 03:02:13 INFO HiveMetaStore.audit: ugi=yinzhengjie ip=unknown-ip-addr cmd=Cleaning up thread local RawStore... 18/06/14 03:02:13 INFO metastore.HiveMetaStore: 0: Done cleaning up thread local RawStore 18/06/14 03:02:13 INFO HiveMetaStore.audit: ugi=yinzhengjie ip=unknown-ip-addr cmd=Done cleaning up thread local RawStore 18/06/14 03:02:13 INFO hive.HiveImport: Hive import complete. 18/06/14 03:02:13 INFO hive.HiveImport: Export directory is contains the _SUCCESS file only, removing the directory. [yinzhengjie@s101 ~]$
0: jdbc:hive2://s101:10000> show tables; +---------------+--+ | tab_name | +---------------+--+ | pv | | user_orc | | user_parquet | | user_rc | | user_seq | | user_text | | users | | wc | +---------------+--+ 8 rows selected (0.19 seconds) 0: jdbc:hive2://s101:10000> select * from wc; +--------+---------------------+--+ | wc.id | wc.string | +--------+---------------------+--+ | 1 | hello world | | 2 | yinzhengjie hadoop | | 2 | yinzhengjie hive | | 2 | yinzhengjie hbase | +--------+---------------------+--+ 4 rows selected (2.717 seconds) 0: jdbc:hive2://s101:10000>
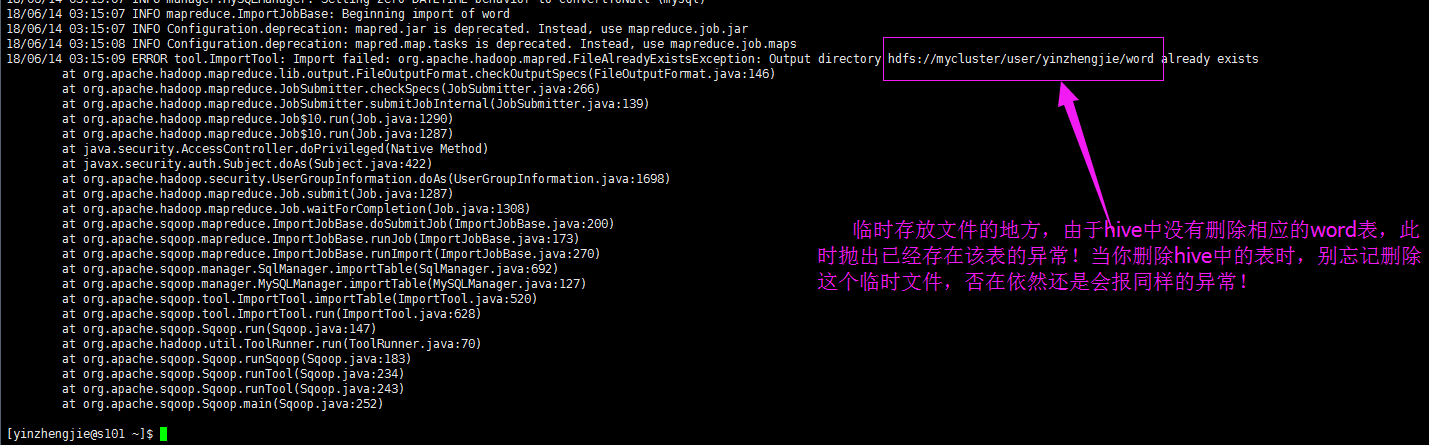
注意:将数据导入到hive的过程中,估计大家也发现了一个显现,数据会临时保存到hdfs上,等MapReduce运行完毕之后,再将数据load到服务器上,将数据加载到hive之后,hdfs临时存在的文件就会被自动删除。这个时候如果你在重新将同一张表导入到hive的同一个数据库时,就会抛出表已经存在的异常(如下图)。想要解决这个问题,除了删除hive中的表还要删除hdfs的临时文件,否在再次运行该命令依然会抛出同样的异常哟!
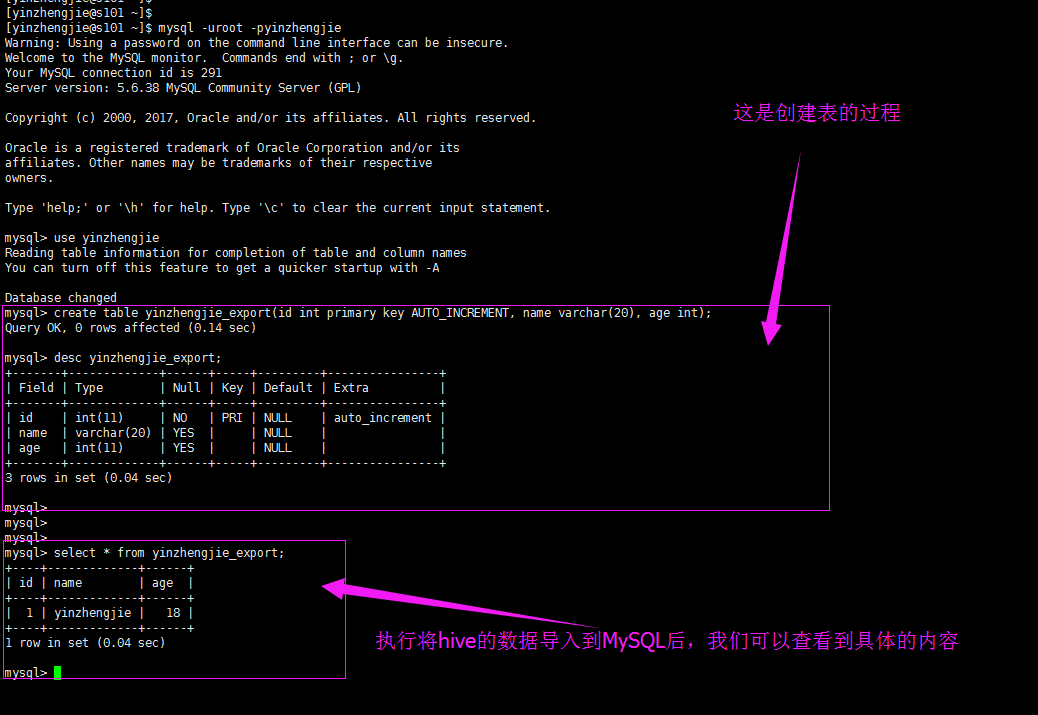
5>.Sqoop将MySQL数据导入到hive中不需要启动服务,验证如下(我们需要编写配置文件“.hiverc”)
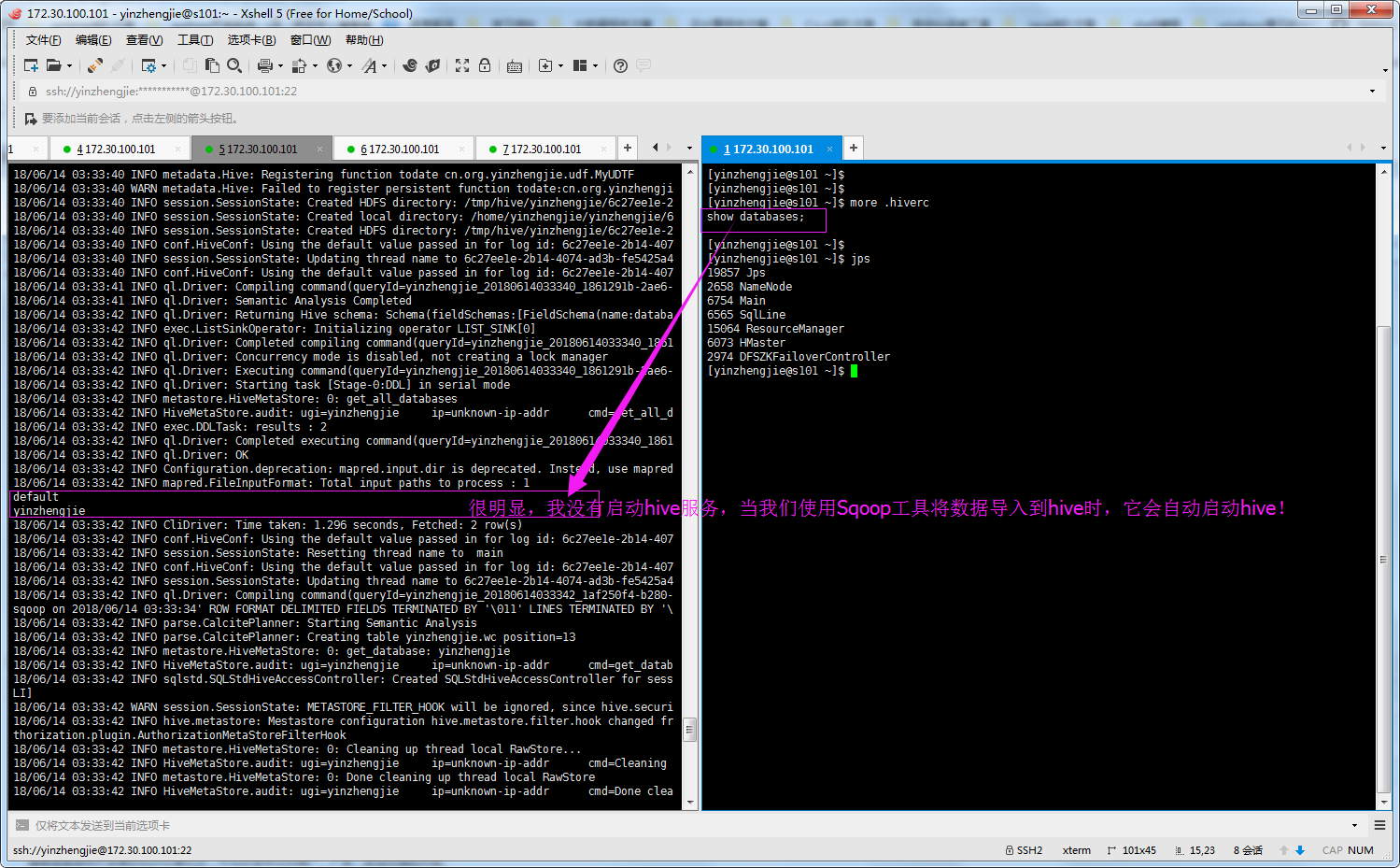
6>.其他常用参数介绍
--create-hive-table //改参数表示如果表不存在就创建,若存在就忽略该参数 --external-table-dir <hdfs path> //指定外部表路径 --hive-database <database-name> //指定hive的数据库 --hive-import //指定导入hive表 --hive-partition-key <partition-key> //指定分区的key --hive-partition-value <partition-value> //指定分区的value --hive-table <table-name> //指定hive的表
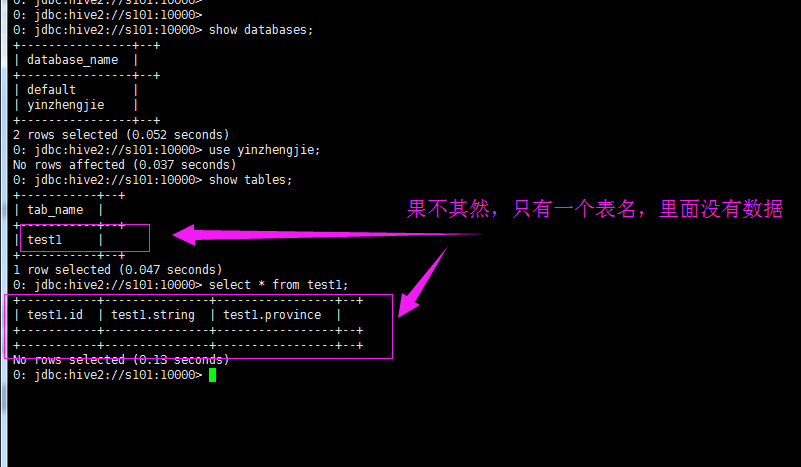
7>.sqoop只创建hive表
[yinzhengjie@s101 ~]$ sqoop create-hive-table --connect jdbc:mysql://s101/yinzhengjie --username root -P --table word --fields-terminated-by ' ' --hive-database yinzhengjie --hive-table test1 --hive-partition-key province --hive-partition-value beijing Warning: /soft/sqoop-1.4.7.bin__hadoop-2.6.0/bin/../../hcatalog does not exist! HCatalog jobs will fail. Please set $HCAT_HOME to the root of your HCatalog installation. Warning: /soft/sqoop-1.4.7.bin__hadoop-2.6.0/bin/../../accumulo does not exist! Accumulo imports will fail. Please set $ACCUMULO_HOME to the root of your Accumulo installation. Warning: /soft/sqoop-1.4.7.bin__hadoop-2.6.0/bin/../../zookeeper does not exist! Accumulo imports will fail. Please set $ZOOKEEPER_HOME to the root of your Zookeeper installation. 18/06/14 06:32:31 INFO sqoop.Sqoop: Running Sqoop version: 1.4.7 Enter password: 18/06/14 06:32:35 INFO manager.MySQLManager: Preparing to use a MySQL streaming resultset. SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/soft/hadoop-2.7.3/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/soft/hbase-1.2.6/lib/phoenix-4.10.0-HBase-1.2-client.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/soft/hbase-1.2.6/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/soft/apache-hive-2.1.1-bin/lib/log4j-slf4j-impl-2.4.1.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory] 18/06/14 06:32:35 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `word` AS t LIMIT 1 18/06/14 06:32:35 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `word` AS t LIMIT 1 18/06/14 06:32:36 INFO hive.HiveImport: Loading uploaded data into Hive 18/06/14 06:32:36 INFO conf.HiveConf: Found configuration file file:/soft/hive/conf/hive-site.xml Logging initialized using configuration in jar:file:/soft/apache-hive-2.1.1-bin/lib/hive-common-2.1.1.jar!/hive-log4j2.properties Async: true 18/06/14 06:32:39 INFO SessionState: Logging initialized using configuration in jar:file:/soft/apache-hive-2.1.1-bin/lib/hive-common-2.1.1.jar!/hive-log4j2.properties Async: true 18/06/14 06:32:40 INFO metastore.HiveMetaStore: 0: Opening raw store with implementation class:org.apache.hadoop.hive.metastore.ObjectStore 18/06/14 06:32:40 INFO metastore.ObjectStore: ObjectStore, initialize called 18/06/14 06:32:40 INFO DataNucleus.Persistence: Property hive.metastore.integral.jdo.pushdown unknown - will be ignored 18/06/14 06:32:40 INFO DataNucleus.Persistence: Property datanucleus.cache.level2 unknown - will be ignored 18/06/14 06:32:41 INFO metastore.ObjectStore: Setting MetaStore object pin classes with hive.metastore.cache.pinobjtypes="Table,StorageDescriptor,SerDeInfo,Partition,Database,Type,FieldSchema,Order" 18/06/14 06:32:43 INFO metastore.MetaStoreDirectSql: Using direct SQL, underlying DB is MYSQL 18/06/14 06:32:43 INFO metastore.ObjectStore: Initialized ObjectStore 18/06/14 06:32:43 INFO metastore.HiveMetaStore: Added admin role in metastore 18/06/14 06:32:43 INFO metastore.HiveMetaStore: Added public role in metastore 18/06/14 06:32:43 INFO metastore.HiveMetaStore: No user is added in admin role, since config is empty 18/06/14 06:32:44 INFO metastore.HiveMetaStore: 0: get_all_functions 18/06/14 06:32:44 INFO HiveMetaStore.audit: ugi=yinzhengjie ip=unknown-ip-addr cmd=get_all_functions 18/06/14 06:32:44 INFO metadata.Hive: Registering function parsejson cn.org.yinzhengjie.udf.ParseJson 18/06/14 06:32:44 WARN metadata.Hive: Failed to register persistent function parsejson:cn.org.yinzhengjie.udf.ParseJson. Ignore and continue. 18/06/14 06:32:44 INFO metadata.Hive: Registering function parsejson cn.org.yinzhengjie.udf.MyUDTF 18/06/14 06:32:44 WARN metadata.Hive: Failed to register persistent function parsejson:cn.org.yinzhengjie.udf.MyUDTF. Ignore and continue. 18/06/14 06:32:44 INFO metadata.Hive: Registering function todate cn.org.yinzhengjie.udf.MyUDTF 18/06/14 06:32:44 WARN metadata.Hive: Failed to register persistent function todate:cn.org.yinzhengjie.udf.MyUDTF. Ignore and continue. 18/06/14 06:32:44 INFO session.SessionState: Created HDFS directory: /tmp/hive/yinzhengjie/96f23e30-9bca-4881-9019-beb3260c29c0 18/06/14 06:32:44 INFO session.SessionState: Created local directory: /home/yinzhengjie/yinzhengjie/96f23e30-9bca-4881-9019-beb3260c29c0 18/06/14 06:32:44 INFO session.SessionState: Created HDFS directory: /tmp/hive/yinzhengjie/96f23e30-9bca-4881-9019-beb3260c29c0/_tmp_space.db 18/06/14 06:32:44 INFO conf.HiveConf: Using the default value passed in for log id: 96f23e30-9bca-4881-9019-beb3260c29c0 18/06/14 06:32:44 INFO session.SessionState: Updating thread name to 96f23e30-9bca-4881-9019-beb3260c29c0 main 18/06/14 06:32:44 INFO conf.HiveConf: Using the default value passed in for log id: 96f23e30-9bca-4881-9019-beb3260c29c0 18/06/14 06:32:45 INFO ql.Driver: Compiling command(queryId=yinzhengjie_20180614063244_016a0a4f-e1c4-4624-907f-6990016f3010): show databases 18/06/14 06:32:46 INFO ql.Driver: Semantic Analysis Completed 18/06/14 06:32:46 INFO ql.Driver: Returning Hive schema: Schema(fieldSchemas:[FieldSchema(name:database_name, type:string, comment:from deserializer)], properties:null) 18/06/14 06:32:46 INFO exec.ListSinkOperator: Initializing operator LIST_SINK[0] 18/06/14 06:32:46 INFO ql.Driver: Completed compiling command(queryId=yinzhengjie_20180614063244_016a0a4f-e1c4-4624-907f-6990016f3010); Time taken: 1.491 seconds 18/06/14 06:32:46 INFO ql.Driver: Concurrency mode is disabled, not creating a lock manager 18/06/14 06:32:46 INFO ql.Driver: Executing command(queryId=yinzhengjie_20180614063244_016a0a4f-e1c4-4624-907f-6990016f3010): show databases 18/06/14 06:32:46 INFO ql.Driver: Starting task [Stage-0:DDL] in serial mode 18/06/14 06:32:46 INFO metastore.HiveMetaStore: 0: get_all_databases 18/06/14 06:32:46 INFO HiveMetaStore.audit: ugi=yinzhengjie ip=unknown-ip-addr cmd=get_all_databases 18/06/14 06:32:46 INFO exec.DDLTask: results : 2 18/06/14 06:32:46 INFO ql.Driver: Completed executing command(queryId=yinzhengjie_20180614063244_016a0a4f-e1c4-4624-907f-6990016f3010); Time taken: 0.036 seconds 18/06/14 06:32:46 INFO ql.Driver: OK 18/06/14 06:32:46 INFO Configuration.deprecation: mapred.input.dir is deprecated. Instead, use mapreduce.input.fileinputformat.inputdir 18/06/14 06:32:46 INFO mapred.FileInputFormat: Total input paths to process : 1 default yinzhengjie 18/06/14 06:32:46 INFO CliDriver: Time taken: 1.534 seconds, Fetched: 2 row(s) 18/06/14 06:32:46 INFO conf.HiveConf: Using the default value passed in for log id: 96f23e30-9bca-4881-9019-beb3260c29c0 18/06/14 06:32:46 INFO session.SessionState: Resetting thread name to main 18/06/14 06:32:46 INFO conf.HiveConf: Using the default value passed in for log id: 96f23e30-9bca-4881-9019-beb3260c29c0 18/06/14 06:32:46 INFO session.SessionState: Updating thread name to 96f23e30-9bca-4881-9019-beb3260c29c0 main 18/06/14 06:32:46 INFO ql.Driver: Compiling command(queryId=yinzhengjie_20180614063246_b8444d13-d69e-40c4-b717-7917e2bce6af): CREATE TABLE IF NOT EXISTS `yinzhengjie`.`test1` ( `id` INT, `string` STRING) COMMENT 'Imported by sqoop on 2018/06/14 06:32:35' PARTITIONED BY (province STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY '�11' LINES TERMINATED BY '�12' STORED AS TEXTFILE 18/06/14 06:32:46 INFO parse.CalcitePlanner: Starting Semantic Analysis 18/06/14 06:32:46 INFO parse.CalcitePlanner: Creating table yinzhengjie.test1 position=27 18/06/14 06:32:46 INFO metastore.HiveMetaStore: 0: get_table : db=yinzhengjie tbl=test1 18/06/14 06:32:46 INFO HiveMetaStore.audit: ugi=yinzhengjie ip=unknown-ip-addr cmd=get_table : db=yinzhengjie tbl=test1 18/06/14 06:32:46 INFO metastore.HiveMetaStore: 0: get_database: yinzhengjie 18/06/14 06:32:46 INFO HiveMetaStore.audit: ugi=yinzhengjie ip=unknown-ip-addr cmd=get_database: yinzhengjie 18/06/14 06:32:46 INFO sqlstd.SQLStdHiveAccessController: Created SQLStdHiveAccessController for session context : HiveAuthzSessionContext [sessionString=96f23e30-9bca-4881-9019-beb3260c29c0, clientType=HIVECLI] 18/06/14 06:32:46 WARN session.SessionState: METASTORE_FILTER_HOOK will be ignored, since hive.security.authorization.manager is set to instance of HiveAuthorizerFactory. 18/06/14 06:32:46 INFO hive.metastore: Mestastore configuration hive.metastore.filter.hook changed from org.apache.hadoop.hive.metastore.DefaultMetaStoreFilterHookImpl to org.apache.hadoop.hive.ql.security.authorization.plugin.AuthorizationMetaStoreFilterHook 18/06/14 06:32:46 INFO metastore.HiveMetaStore: 0: Cleaning up thread local RawStore... 18/06/14 06:32:46 INFO HiveMetaStore.audit: ugi=yinzhengjie ip=unknown-ip-addr cmd=Cleaning up thread local RawStore... 18/06/14 06:32:46 INFO metastore.HiveMetaStore: 0: Done cleaning up thread local RawStore 18/06/14 06:32:46 INFO HiveMetaStore.audit: ugi=yinzhengjie ip=unknown-ip-addr cmd=Done cleaning up thread local RawStore 18/06/14 06:32:46 INFO ql.Driver: Semantic Analysis Completed 18/06/14 06:32:46 INFO ql.Driver: Returning Hive schema: Schema(fieldSchemas:null, properties:null) 18/06/14 06:32:46 INFO ql.Driver: Completed compiling command(queryId=yinzhengjie_20180614063246_b8444d13-d69e-40c4-b717-7917e2bce6af); Time taken: 0.176 seconds 18/06/14 06:32:46 INFO ql.Driver: Concurrency mode is disabled, not creating a lock manager 18/06/14 06:32:46 INFO ql.Driver: Executing command(queryId=yinzhengjie_20180614063246_b8444d13-d69e-40c4-b717-7917e2bce6af): CREATE TABLE IF NOT EXISTS `yinzhengjie`.`test1` ( `id` INT, `string` STRING) COMMENT 'Imported by sqoop on 2018/06/14 06:32:35' PARTITIONED BY (province STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY '�11' LINES TERMINATED BY '�12' STORED AS TEXTFILE 18/06/14 06:32:46 INFO ql.Driver: Starting task [Stage-0:DDL] in serial mode 18/06/14 06:32:46 INFO exec.DDLTask: creating table yinzhengjie.test1 on null 18/06/14 06:32:46 INFO metastore.HiveMetaStore: 0: create_table: Table(tableName:test1, dbName:yinzhengjie, owner:yinzhengjie, createTime:1528983166, lastAccessTime:0, retention:0, sd:StorageDescriptor(cols:[FieldSchema(name:id, type:int, comment:null), FieldSchema(name:string, type:string, comment:null)], location:null, inputFormat:org.apache.hadoop.mapred.TextInputFormat, outputFormat:org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat, compressed:false, numBuckets:-1, serdeInfo:SerDeInfo(name:null, serializationLib:org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe, parameters:{serialization.format= , line.delim= , field.delim= }), bucketCols:[], sortCols:[], parameters:{}, skewedInfo:SkewedInfo(skewedColNames:[], skewedColValues:[], skewedColValueLocationMaps:{}), storedAsSubDirectories:false), partitionKeys:[FieldSchema(name:province, type:string, comment:null)], parameters:{comment=Imported by sqoop on 2018/06/14 06:32:35}, viewOriginalText:null, viewExpandedText:null, tableType:MANAGED_TABLE, privileges:PrincipalPrivilegeSet(userPrivileges:{yinzhengjie=[PrivilegeGrantInfo(privilege:INSERT, createTime:-1, grantor:yinzhengjie, grantorType:USER, grantOption:true), PrivilegeGrantInfo(privilege:SELECT, createTime:-1, grantor:yinzhengjie, grantorType:USER, grantOption:true), PrivilegeGrantInfo(privilege:UPDATE, createTime:-1, grantor:yinzhengjie, grantorType:USER, grantOption:true), PrivilegeGrantInfo(privilege:DELETE, createTime:-1, grantor:yinzhengjie, grantorType:USER, grantOption:true)]}, groupPrivileges:null, rolePrivileges:null), temporary:false) 18/06/14 06:32:46 INFO HiveMetaStore.audit: ugi=yinzhengjie ip=unknown-ip-addr cmd=create_table: Table(tableName:test1, dbName:yinzhengjie, owner:yinzhengjie, createTime:1528983166, lastAccessTime:0, retention:0, sd:StorageDescriptor(cols:[FieldSchema(name:id, type:int, comment:null), FieldSchema(name:string, type:string, comment:null)], location:null, inputFormat:org.apache.hadoop.mapred.TextInputFormat, outputFormat:org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat, compressed:false, numBuckets:-1, serdeInfo:SerDeInfo(name:null, serializationLib:org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe, parameters:{serialization.format= , line.delim= , field.delim= }), bucketCols:[], sortCols:[], parameters:{}, skewedInfo:SkewedInfo(skewedColNames:[], skewedColValues:[], skewedColValueLocationMaps:{}), storedAsSubDirectories:false), partitionKeys:[FieldSchema(name:province, type:string, comment:null)], parameters:{comment=Imported by sqoop on 2018/06/14 06:32:35}, viewOriginalText:null, viewExpandedText:null, tableType:MANAGED_TABLE, privileges:PrincipalPrivilegeSet(userPrivileges:{yinzhengjie=[PrivilegeGrantInfo(privilege:INSERT, createTime:-1, grantor:yinzhengjie, grantorType:USER, grantOption:true), PrivilegeGrantInfo(privilege:SELECT, createTime:-1, grantor:yinzhengjie, grantorType:USER, grantOption:true), PrivilegeGrantInfo(privilege:UPDATE, createTime:-1, grantor:yinzhengjie, grantorType:USER, grantOption:true), PrivilegeGrantInfo(privilege:DELETE, createTime:-1, grantor:yinzhengjie, grantorType:USER, grantOption:true)]}, groupPrivileges:null, rolePrivileges:null), temporary:false) 18/06/14 06:32:46 INFO metastore.HiveMetaStore: 0: Opening raw store with implementation class:org.apache.hadoop.hive.metastore.ObjectStore 18/06/14 06:32:46 INFO metastore.ObjectStore: ObjectStore, initialize called 18/06/14 06:32:46 INFO metastore.MetaStoreDirectSql: Using direct SQL, underlying DB is MYSQL 18/06/14 06:32:46 INFO metastore.ObjectStore: Initialized ObjectStore 18/06/14 06:32:46 INFO common.FileUtils: Creating directory if it doesn't exist: hdfs://mycluster/user/hive/warehouse/yinzhengjie.db/test1 18/06/14 06:32:47 INFO ql.Driver: Completed executing command(queryId=yinzhengjie_20180614063246_b8444d13-d69e-40c4-b717-7917e2bce6af); Time taken: 0.334 seconds OK 18/06/14 06:32:47 INFO ql.Driver: OK Time taken: 0.511 seconds 18/06/14 06:32:47 INFO CliDriver: Time taken: 0.511 seconds 18/06/14 06:32:47 INFO conf.HiveConf: Using the default value passed in for log id: 96f23e30-9bca-4881-9019-beb3260c29c0 18/06/14 06:32:47 INFO session.SessionState: Resetting thread name to main 18/06/14 06:32:47 INFO conf.HiveConf: Using the default value passed in for log id: 96f23e30-9bca-4881-9019-beb3260c29c0 18/06/14 06:32:47 INFO session.SessionState: Deleted directory: /tmp/hive/yinzhengjie/96f23e30-9bca-4881-9019-beb3260c29c0 on fs with scheme hdfs 18/06/14 06:32:47 INFO session.SessionState: Deleted directory: /home/yinzhengjie/yinzhengjie/96f23e30-9bca-4881-9019-beb3260c29c0 on fs with scheme file 18/06/14 06:32:47 INFO metastore.HiveMetaStore: 0: Cleaning up thread local RawStore... 18/06/14 06:32:47 INFO HiveMetaStore.audit: ugi=yinzhengjie ip=unknown-ip-addr cmd=Cleaning up thread local RawStore... 18/06/14 06:32:47 INFO metastore.HiveMetaStore: 0: Done cleaning up thread local RawStore 18/06/14 06:32:47 INFO HiveMetaStore.audit: ugi=yinzhengjie ip=unknown-ip-addr cmd=Done cleaning up thread local RawStore 18/06/14 06:32:47 INFO hive.HiveImport: Hive import complete. [yinzhengjie@s101 ~]$ echo $? 0 [yinzhengjie@s101 ~]$
8>.sqoop导入hive分区表(hive导入分区表时会进行自动创建,hive导入分区表只能静态导入,支持一个分区 省去创建文件夹流程)
[yinzhengjie@s101 ~]$ sqoop import --connect jdbc:mysql://s101/yinzhengjie --username root -P --table word --fields-terminated-by ' ' --hive-import --create-hive-table --hive-database yinzhengjie --hive-table test2 --hive-partition-key province --hive-partition-value beijing -m 1 Warning: /soft/sqoop-1.4.7.bin__hadoop-2.6.0/bin/../../hcatalog does not exist! HCatalog jobs will fail. Please set $HCAT_HOME to the root of your HCatalog installation. Warning: /soft/sqoop-1.4.7.bin__hadoop-2.6.0/bin/../../accumulo does not exist! Accumulo imports will fail. Please set $ACCUMULO_HOME to the root of your Accumulo installation. Warning: /soft/sqoop-1.4.7.bin__hadoop-2.6.0/bin/../../zookeeper does not exist! Accumulo imports will fail. Please set $ZOOKEEPER_HOME to the root of your Zookeeper installation. 18/06/14 06:49:37 INFO sqoop.Sqoop: Running Sqoop version: 1.4.7 Enter password: 18/06/14 06:49:48 INFO manager.MySQLManager: Preparing to use a MySQL streaming resultset. 18/06/14 06:49:48 INFO tool.CodeGenTool: Beginning code generation SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/soft/hadoop-2.7.3/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/soft/hbase-1.2.6/lib/phoenix-4.10.0-HBase-1.2-client.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/soft/hbase-1.2.6/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/soft/apache-hive-2.1.1-bin/lib/log4j-slf4j-impl-2.4.1.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory] 18/06/14 06:49:48 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `word` AS t LIMIT 1 18/06/14 06:49:49 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `word` AS t LIMIT 1 18/06/14 06:49:49 INFO orm.CompilationManager: HADOOP_MAPRED_HOME is /soft/hadoop Note: /tmp/sqoop-yinzhengjie/compile/2ff01e5a4aa9de071eea44aba493fc22/word.java uses or overrides a deprecated API. Note: Recompile with -Xlint:deprecation for details. 18/06/14 06:49:52 INFO orm.CompilationManager: Writing jar file: /tmp/sqoop-yinzhengjie/compile/2ff01e5a4aa9de071eea44aba493fc22/word.jar 18/06/14 06:49:52 WARN manager.MySQLManager: It looks like you are importing from mysql. 18/06/14 06:49:52 WARN manager.MySQLManager: This transfer can be faster! Use the --direct 18/06/14 06:49:52 WARN manager.MySQLManager: option to exercise a MySQL-specific fast path. 18/06/14 06:49:52 INFO manager.MySQLManager: Setting zero DATETIME behavior to convertToNull (mysql) 18/06/14 06:49:52 INFO mapreduce.ImportJobBase: Beginning import of word 18/06/14 06:49:52 INFO Configuration.deprecation: mapred.jar is deprecated. Instead, use mapreduce.job.jar 18/06/14 06:49:53 INFO Configuration.deprecation: mapred.map.tasks is deprecated. Instead, use mapreduce.job.maps 18/06/14 06:49:54 ERROR tool.ImportTool: Import failed: org.apache.hadoop.mapred.FileAlreadyExistsException: Output directory hdfs://mycluster/user/yinzhengjie/word already exists at org.apache.hadoop.mapreduce.lib.output.FileOutputFormat.checkOutputSpecs(FileOutputFormat.java:146) at org.apache.hadoop.mapreduce.JobSubmitter.checkSpecs(JobSubmitter.java:266) at org.apache.hadoop.mapreduce.JobSubmitter.submitJobInternal(JobSubmitter.java:139) at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1290) at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1287) at java.security.AccessController.doPrivileged(Native Method) at javax.security.auth.Subject.doAs(Subject.java:422) at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1698) at org.apache.hadoop.mapreduce.Job.submit(Job.java:1287) at org.apache.hadoop.mapreduce.Job.waitForCompletion(Job.java:1308) at org.apache.sqoop.mapreduce.ImportJobBase.doSubmitJob(ImportJobBase.java:200) at org.apache.sqoop.mapreduce.ImportJobBase.runJob(ImportJobBase.java:173) at org.apache.sqoop.mapreduce.ImportJobBase.runImport(ImportJobBase.java:270) at org.apache.sqoop.manager.SqlManager.importTable(SqlManager.java:692) at org.apache.sqoop.manager.MySQLManager.importTable(MySQLManager.java:127) at org.apache.sqoop.tool.ImportTool.importTable(ImportTool.java:520) at org.apache.sqoop.tool.ImportTool.run(ImportTool.java:628) at org.apache.sqoop.Sqoop.run(Sqoop.java:147) at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:70) at org.apache.sqoop.Sqoop.runSqoop(Sqoop.java:183) at org.apache.sqoop.Sqoop.runTool(Sqoop.java:234) at org.apache.sqoop.Sqoop.runTool(Sqoop.java:243) at org.apache.sqoop.Sqoop.main(Sqoop.java:252) [yinzhengjie@s101 ~]$ hdfs dfs -rm -r /user/yinzhengjie/word SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/soft/hadoop-2.7.3/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/soft/apache-hive-2.1.1-bin/lib/log4j-slf4j-impl-2.4.1.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory] 18/06/14 06:50:25 INFO fs.TrashPolicyDefault: Namenode trash configuration: Deletion interval = 0 minutes, Emptier interval = 0 minutes. Deleted /user/yinzhengjie/word [yinzhengjie@s101 ~]$ [yinzhengjie@s101 ~]$ [yinzhengjie@s101 ~]$ [yinzhengjie@s101 ~]$ [yinzhengjie@s101 ~]$ [yinzhengjie@s101 ~]$ sqoop import --connect jdbc:mysql://s101/yinzhengjie --username root -P --table word --fields-terminated-by ' ' --hive-import --create-hive-table --hive-database yinzhengjie --hive-table test2 --hive-partition-key province --hive-partition-value beijing -m 1 Warning: /soft/sqoop-1.4.7.bin__hadoop-2.6.0/bin/../../hcatalog does not exist! HCatalog jobs will fail. Please set $HCAT_HOME to the root of your HCatalog installation. Warning: /soft/sqoop-1.4.7.bin__hadoop-2.6.0/bin/../../accumulo does not exist! Accumulo imports will fail. Please set $ACCUMULO_HOME to the root of your Accumulo installation. Warning: /soft/sqoop-1.4.7.bin__hadoop-2.6.0/bin/../../zookeeper does not exist! Accumulo imports will fail. Please set $ZOOKEEPER_HOME to the root of your Zookeeper installation. 18/06/14 06:50:49 INFO sqoop.Sqoop: Running Sqoop version: 1.4.7 Enter password: 18/06/14 06:50:52 INFO manager.MySQLManager: Preparing to use a MySQL streaming resultset. 18/06/14 06:50:52 INFO tool.CodeGenTool: Beginning code generation SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/soft/hadoop-2.7.3/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/soft/hbase-1.2.6/lib/phoenix-4.10.0-HBase-1.2-client.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/soft/hbase-1.2.6/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/soft/apache-hive-2.1.1-bin/lib/log4j-slf4j-impl-2.4.1.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory] 18/06/14 06:50:53 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `word` AS t LIMIT 1 18/06/14 06:50:53 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `word` AS t LIMIT 1 18/06/14 06:50:53 INFO orm.CompilationManager: HADOOP_MAPRED_HOME is /soft/hadoop Note: /tmp/sqoop-yinzhengjie/compile/c8d9be59546846cfb07ab171c91ca0ac/word.java uses or overrides a deprecated API. Note: Recompile with -Xlint:deprecation for details. 18/06/14 06:50:55 INFO orm.CompilationManager: Writing jar file: /tmp/sqoop-yinzhengjie/compile/c8d9be59546846cfb07ab171c91ca0ac/word.jar 18/06/14 06:50:55 WARN manager.MySQLManager: It looks like you are importing from mysql. 18/06/14 06:50:55 WARN manager.MySQLManager: This transfer can be faster! Use the --direct 18/06/14 06:50:55 WARN manager.MySQLManager: option to exercise a MySQL-specific fast path. 18/06/14 06:50:55 INFO manager.MySQLManager: Setting zero DATETIME behavior to convertToNull (mysql) 18/06/14 06:50:55 INFO mapreduce.ImportJobBase: Beginning import of word 18/06/14 06:50:55 INFO Configuration.deprecation: mapred.jar is deprecated. Instead, use mapreduce.job.jar 18/06/14 06:50:56 INFO Configuration.deprecation: mapred.map.tasks is deprecated. Instead, use mapreduce.job.maps 18/06/14 06:51:01 INFO db.DBInputFormat: Using read commited transaction isolation 18/06/14 06:51:01 INFO mapreduce.JobSubmitter: number of splits:1 18/06/14 06:51:02 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1528967628934_0014 18/06/14 06:51:02 INFO impl.YarnClientImpl: Submitted application application_1528967628934_0014 18/06/14 06:51:02 INFO mapreduce.Job: The url to track the job: http://s101:8088/proxy/application_1528967628934_0014/ 18/06/14 06:51:02 INFO mapreduce.Job: Running job: job_1528967628934_0014 18/06/14 06:51:20 INFO mapreduce.Job: Job job_1528967628934_0014 running in uber mode : false 18/06/14 06:51:20 INFO mapreduce.Job: map 0% reduce 0% 18/06/14 06:51:31 INFO mapreduce.Job: map 100% reduce 0% 18/06/14 06:51:34 INFO mapreduce.Job: Job job_1528967628934_0014 completed successfully 18/06/14 06:51:35 INFO mapreduce.Job: Counters: 30 File System Counters FILE: Number of bytes read=0 FILE: Number of bytes written=140344 FILE: Number of read operations=0 FILE: Number of large read operations=0 FILE: Number of write operations=0 HDFS: Number of bytes read=87 HDFS: Number of bytes written=74 HDFS: Number of read operations=4 HDFS: Number of large read operations=0 HDFS: Number of write operations=2 Job Counters Launched map tasks=1 Other local map tasks=1 Total time spent by all maps in occupied slots (ms)=7182 Total time spent by all reduces in occupied slots (ms)=0 Total time spent by all map tasks (ms)=7182 Total vcore-milliseconds taken by all map tasks=7182 Total megabyte-milliseconds taken by all map tasks=7354368 Map-Reduce Framework Map input records=4 Map output records=4 Input split bytes=87 Spilled Records=0 Failed Shuffles=0 Merged Map outputs=0 GC time elapsed (ms)=98 CPU time spent (ms)=1060 Physical memory (bytes) snapshot=104247296 Virtual memory (bytes) snapshot=2086359040 Total committed heap usage (bytes)=18636800 File Input Format Counters Bytes Read=0 File Output Format Counters Bytes Written=74 18/06/14 06:51:35 INFO mapreduce.ImportJobBase: Transferred 74 bytes in 38.8416 seconds (1.9052 bytes/sec) 18/06/14 06:51:35 INFO mapreduce.ImportJobBase: Retrieved 4 records. 18/06/14 06:51:35 INFO mapreduce.ImportJobBase: Publishing Hive/Hcat import job data to Listeners for table word 18/06/14 06:51:35 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `word` AS t LIMIT 1 18/06/14 06:51:35 INFO hive.HiveImport: Loading uploaded data into Hive 18/06/14 06:51:35 INFO conf.HiveConf: Found configuration file file:/soft/hive/conf/hive-site.xml Logging initialized using configuration in jar:file:/soft/apache-hive-2.1.1-bin/lib/hive-common-2.1.1.jar!/hive-log4j2.properties Async: true 18/06/14 06:51:39 INFO SessionState: Logging initialized using configuration in jar:file:/soft/apache-hive-2.1.1-bin/lib/hive-common-2.1.1.jar!/hive-log4j2.properties Async: true 18/06/14 06:51:39 INFO metastore.HiveMetaStore: 0: Opening raw store with implementation class:org.apache.hadoop.hive.metastore.ObjectStore 18/06/14 06:51:46 INFO metastore.ObjectStore: ObjectStore, initialize called 18/06/14 06:51:46 INFO DataNucleus.Persistence: Property hive.metastore.integral.jdo.pushdown unknown - will be ignored 18/06/14 06:51:46 INFO DataNucleus.Persistence: Property datanucleus.cache.level2 unknown - will be ignored 18/06/14 06:51:50 INFO metastore.ObjectStore: Setting MetaStore object pin classes with hive.metastore.cache.pinobjtypes="Table,StorageDescriptor,SerDeInfo,Partition,Database,Type,FieldSchema,Order" 18/06/14 06:51:54 INFO metastore.MetaStoreDirectSql: Using direct SQL, underlying DB is MYSQL 18/06/14 06:51:54 INFO metastore.ObjectStore: Initialized ObjectStore 18/06/14 06:51:54 INFO metastore.HiveMetaStore: Added admin role in metastore 18/06/14 06:51:54 INFO metastore.HiveMetaStore: Added public role in metastore 18/06/14 06:51:54 INFO metastore.HiveMetaStore: No user is added in admin role, since config is empty 18/06/14 06:51:55 INFO metastore.HiveMetaStore: 0: get_all_functions 18/06/14 06:51:55 INFO HiveMetaStore.audit: ugi=yinzhengjie ip=unknown-ip-addr cmd=get_all_functions 18/06/14 06:51:55 INFO metadata.Hive: Registering function parsejson cn.org.yinzhengjie.udf.ParseJson 18/06/14 06:51:56 WARN metadata.Hive: Failed to register persistent function parsejson:cn.org.yinzhengjie.udf.ParseJson. Ignore and continue. 18/06/14 06:51:56 INFO metadata.Hive: Registering function parsejson cn.org.yinzhengjie.udf.MyUDTF 18/06/14 06:51:56 WARN metadata.Hive: Failed to register persistent function parsejson:cn.org.yinzhengjie.udf.MyUDTF. Ignore and continue. 18/06/14 06:51:56 INFO metadata.Hive: Registering function todate cn.org.yinzhengjie.udf.MyUDTF 18/06/14 06:51:56 WARN metadata.Hive: Failed to register persistent function todate:cn.org.yinzhengjie.udf.MyUDTF. Ignore and continue. 18/06/14 06:51:57 INFO session.SessionState: Created HDFS directory: /tmp/hive/yinzhengjie/520c334d-3342-4ac4-aa9e-32b6afc099a2 18/06/14 06:51:57 INFO session.SessionState: Created local directory: /home/yinzhengjie/yinzhengjie/520c334d-3342-4ac4-aa9e-32b6afc099a2 18/06/14 06:51:57 INFO session.SessionState: Created HDFS directory: /tmp/hive/yinzhengjie/520c334d-3342-4ac4-aa9e-32b6afc099a2/_tmp_space.db 18/06/14 06:51:57 INFO conf.HiveConf: Using the default value passed in for log id: 520c334d-3342-4ac4-aa9e-32b6afc099a2 18/06/14 06:51:57 INFO session.SessionState: Updating thread name to 520c334d-3342-4ac4-aa9e-32b6afc099a2 main 18/06/14 06:51:57 INFO conf.HiveConf: Using the default value passed in for log id: 520c334d-3342-4ac4-aa9e-32b6afc099a2 18/06/14 06:51:57 INFO ql.Driver: Compiling command(queryId=yinzhengjie_20180614065157_e829671d-1341-4858-a232-16ed5e196e1e): show databases 18/06/14 06:51:58 INFO ql.Driver: Semantic Analysis Completed 18/06/14 06:51:59 INFO ql.Driver: Returning Hive schema: Schema(fieldSchemas:[FieldSchema(name:database_name, type:string, comment:from deserializer)], properties:null) 18/06/14 06:51:59 INFO exec.ListSinkOperator: Initializing operator LIST_SINK[0] 18/06/14 06:51:59 INFO ql.Driver: Completed compiling command(queryId=yinzhengjie_20180614065157_e829671d-1341-4858-a232-16ed5e196e1e); Time taken: 1.945 seconds 18/06/14 06:51:59 INFO ql.Driver: Concurrency mode is disabled, not creating a lock manager 18/06/14 06:51:59 INFO ql.Driver: Executing command(queryId=yinzhengjie_20180614065157_e829671d-1341-4858-a232-16ed5e196e1e): show databases 18/06/14 06:51:59 INFO ql.Driver: Starting task [Stage-0:DDL] in serial mode 18/06/14 06:51:59 INFO metastore.HiveMetaStore: 0: get_all_databases 18/06/14 06:51:59 INFO HiveMetaStore.audit: ugi=yinzhengjie ip=unknown-ip-addr cmd=get_all_databases 18/06/14 06:52:00 INFO exec.DDLTask: results : 2 18/06/14 06:52:00 INFO ql.Driver: Completed executing command(queryId=yinzhengjie_20180614065157_e829671d-1341-4858-a232-16ed5e196e1e); Time taken: 0.805 seconds 18/06/14 06:52:00 INFO ql.Driver: OK 18/06/14 06:52:00 INFO Configuration.deprecation: mapred.input.dir is deprecated. Instead, use mapreduce.input.fileinputformat.inputdir 18/06/14 06:52:00 INFO mapred.FileInputFormat: Total input paths to process : 1 default yinzhengjie 18/06/14 06:52:00 INFO CliDriver: Time taken: 2.773 seconds, Fetched: 2 row(s) 18/06/14 06:52:00 INFO conf.HiveConf: Using the default value passed in for log id: 520c334d-3342-4ac4-aa9e-32b6afc099a2 18/06/14 06:52:00 INFO session.SessionState: Resetting thread name to main 18/06/14 06:52:00 INFO conf.HiveConf: Using the default value passed in for log id: 520c334d-3342-4ac4-aa9e-32b6afc099a2 18/06/14 06:52:00 INFO session.SessionState: Updating thread name to 520c334d-3342-4ac4-aa9e-32b6afc099a2 main 18/06/14 06:52:00 INFO ql.Driver: Compiling command(queryId=yinzhengjie_20180614065200_0b542503-b168-4e41-9e3d-2122d1a47de6): CREATE TABLE `yinzhengjie`.`test2` ( `id` INT, `string` STRING) COMMENT 'Imported by sqoop on 2018/06/14 06:51:35' PARTITIONED BY (province STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY '�11' LINES TERMINATED BY '�12' STORED AS TEXTFILE 18/06/14 06:52:01 INFO parse.CalcitePlanner: Starting Semantic Analysis 18/06/14 06:52:01 INFO parse.CalcitePlanner: Creating table yinzhengjie.test2 position=13 18/06/14 06:52:01 INFO metastore.HiveMetaStore: 0: get_database: yinzhengjie 18/06/14 06:52:01 INFO HiveMetaStore.audit: ugi=yinzhengjie ip=unknown-ip-addr cmd=get_database: yinzhengjie 18/06/14 06:52:01 INFO sqlstd.SQLStdHiveAccessController: Created SQLStdHiveAccessController for session context : HiveAuthzSessionContext [sessionString=520c334d-3342-4ac4-aa9e-32b6afc099a2, clientType=HIVECLI] 18/06/14 06:52:01 WARN session.SessionState: METASTORE_FILTER_HOOK will be ignored, since hive.security.authorization.manager is set to instance of HiveAuthorizerFactory. 18/06/14 06:52:01 INFO hive.metastore: Mestastore configuration hive.metastore.filter.hook changed from org.apache.hadoop.hive.metastore.DefaultMetaStoreFilterHookImpl to org.apache.hadoop.hive.ql.security.authorization.plugin.AuthorizationMetaStoreFilterHook 18/06/14 06:52:01 INFO metastore.HiveMetaStore: 0: Cleaning up thread local RawStore... 18/06/14 06:52:01 INFO HiveMetaStore.audit: ugi=yinzhengjie ip=unknown-ip-addr cmd=Cleaning up thread local RawStore... 18/06/14 06:52:01 INFO metastore.HiveMetaStore: 0: Done cleaning up thread local RawStore 18/06/14 06:52:01 INFO HiveMetaStore.audit: ugi=yinzhengjie ip=unknown-ip-addr cmd=Done cleaning up thread local RawStore 18/06/14 06:52:01 INFO ql.Driver: Semantic Analysis Completed 18/06/14 06:52:01 INFO ql.Driver: Returning Hive schema: Schema(fieldSchemas:null, properties:null) 18/06/14 06:52:01 INFO ql.Driver: Completed compiling command(queryId=yinzhengjie_20180614065200_0b542503-b168-4e41-9e3d-2122d1a47de6); Time taken: 0.828 seconds 18/06/14 06:52:01 INFO ql.Driver: Concurrency mode is disabled, not creating a lock manager 18/06/14 06:52:01 INFO ql.Driver: Executing command(queryId=yinzhengjie_20180614065200_0b542503-b168-4e41-9e3d-2122d1a47de6): CREATE TABLE `yinzhengjie`.`test2` ( `id` INT, `string` STRING) COMMENT 'Imported by sqoop on 2018/06/14 06:51:35' PARTITIONED BY (province STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY '�11' LINES TERMINATED BY '�12' STORED AS TEXTFILE 18/06/14 06:52:01 INFO ql.Driver: Starting task [Stage-0:DDL] in serial mode 18/06/14 06:52:01 INFO exec.DDLTask: creating table yinzhengjie.test2 on null 18/06/14 06:52:01 INFO metastore.HiveMetaStore: 0: create_table: Table(tableName:test2, dbName:yinzhengjie, owner:yinzhengjie, createTime:1528984321, lastAccessTime:0, retention:0, sd:StorageDescriptor(cols:[FieldSchema(name:id, type:int, comment:null), FieldSchema(name:string, type:string, comment:null)], location:null, inputFormat:org.apache.hadoop.mapred.TextInputFormat, outputFormat:org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat, compressed:false, numBuckets:-1, serdeInfo:SerDeInfo(name:null, serializationLib:org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe, parameters:{serialization.format= , line.delim= , field.delim= }), bucketCols:[], sortCols:[], parameters:{}, skewedInfo:SkewedInfo(skewedColNames:[], skewedColValues:[], skewedColValueLocationMaps:{}), storedAsSubDirectories:false), partitionKeys:[FieldSchema(name:province, type:string, comment:null)], parameters:{comment=Imported by sqoop on 2018/06/14 06:51:35}, viewOriginalText:null, viewExpandedText:null, tableType:MANAGED_TABLE, privileges:PrincipalPrivilegeSet(userPrivileges:{yinzhengjie=[PrivilegeGrantInfo(privilege:INSERT, createTime:-1, grantor:yinzhengjie, grantorType:USER, grantOption:true), PrivilegeGrantInfo(privilege:SELECT, createTime:-1, grantor:yinzhengjie, grantorType:USER, grantOption:true), PrivilegeGrantInfo(privilege:UPDATE, createTime:-1, grantor:yinzhengjie, grantorType:USER, grantOption:true), PrivilegeGrantInfo(privilege:DELETE, createTime:-1, grantor:yinzhengjie, grantorType:USER, grantOption:true)]}, groupPrivileges:null, rolePrivileges:null), temporary:false) 18/06/14 06:52:01 INFO HiveMetaStore.audit: ugi=yinzhengjie ip=unknown-ip-addr cmd=create_table: Table(tableName:test2, dbName:yinzhengjie, owner:yinzhengjie, createTime:1528984321, lastAccessTime:0, retention:0, sd:StorageDescriptor(cols:[FieldSchema(name:id, type:int, comment:null), FieldSchema(name:string, type:string, comment:null)], location:null, inputFormat:org.apache.hadoop.mapred.TextInputFormat, outputFormat:org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat, compressed:false, numBuckets:-1, serdeInfo:SerDeInfo(name:null, serializationLib:org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe, parameters:{serialization.format= , line.delim= , field.delim= }), bucketCols:[], sortCols:[], parameters:{}, skewedInfo:SkewedInfo(skewedColNames:[], skewedColValues:[], skewedColValueLocationMaps:{}), storedAsSubDirectories:false), partitionKeys:[FieldSchema(name:province, type:string, comment:null)], parameters:{comment=Imported by sqoop on 2018/06/14 06:51:35}, viewOriginalText:null, viewExpandedText:null, tableType:MANAGED_TABLE, privileges:PrincipalPrivilegeSet(userPrivileges:{yinzhengjie=[PrivilegeGrantInfo(privilege:INSERT, createTime:-1, grantor:yinzhengjie, grantorType:USER, grantOption:true), PrivilegeGrantInfo(privilege:SELECT, createTime:-1, grantor:yinzhengjie, grantorType:USER, grantOption:true), PrivilegeGrantInfo(privilege:UPDATE, createTime:-1, grantor:yinzhengjie, grantorType:USER, grantOption:true), PrivilegeGrantInfo(privilege:DELETE, createTime:-1, grantor:yinzhengjie, grantorType:USER, grantOption:true)]}, groupPrivileges:null, rolePrivileges:null), temporary:false) 18/06/14 06:52:01 INFO metastore.HiveMetaStore: 0: Opening raw store with implementation class:org.apache.hadoop.hive.metastore.ObjectStore 18/06/14 06:52:01 INFO metastore.ObjectStore: ObjectStore, initialize called 18/06/14 06:52:02 INFO metastore.MetaStoreDirectSql: Using direct SQL, underlying DB is MYSQL 18/06/14 06:52:02 INFO metastore.ObjectStore: Initialized ObjectStore 18/06/14 06:52:02 INFO common.FileUtils: Creating directory if it doesn't exist: hdfs://mycluster/user/hive/warehouse/yinzhengjie.db/test2 18/06/14 06:52:03 INFO metadata.Hive: Dumping metastore api call timing information for : execution phase 18/06/14 06:52:03 INFO metadata.Hive: Total time spent in this metastore function was greater than 1000ms : createTable_(Table, )=1406 18/06/14 06:52:03 INFO ql.Driver: Completed executing command(queryId=yinzhengjie_20180614065200_0b542503-b168-4e41-9e3d-2122d1a47de6); Time taken: 1.476 seconds OK 18/06/14 06:52:03 INFO ql.Driver: OK Time taken: 2.304 seconds 18/06/14 06:52:03 INFO CliDriver: Time taken: 2.304 seconds 18/06/14 06:52:03 INFO conf.HiveConf: Using the default value passed in for log id: 520c334d-3342-4ac4-aa9e-32b6afc099a2 18/06/14 06:52:03 INFO session.SessionState: Resetting thread name to main 18/06/14 06:52:03 INFO conf.HiveConf: Using the default value passed in for log id: 520c334d-3342-4ac4-aa9e-32b6afc099a2 18/06/14 06:52:03 INFO session.SessionState: Updating thread name to 520c334d-3342-4ac4-aa9e-32b6afc099a2 main 18/06/14 06:52:03 INFO ql.Driver: Compiling command(queryId=yinzhengjie_20180614065203_2cb29172-e5bb-43bd-abf6-4d33c3fffb48): LOAD DATA INPATH 'hdfs://mycluster/user/yinzhengjie/word' INTO TABLE `yinzhengjie`.`test2` PARTITION (province='beijing') 18/06/14 06:52:03 INFO metastore.HiveMetaStore: 0: get_table : db=yinzhengjie tbl=test2 18/06/14 06:52:03 INFO HiveMetaStore.audit: ugi=yinzhengjie ip=unknown-ip-addr cmd=get_table : db=yinzhengjie tbl=test2 18/06/14 06:52:03 INFO metastore.HiveMetaStore: 0: get_partition_with_auth : db=yinzhengjie tbl=test2[beijing] 18/06/14 06:52:03 INFO HiveMetaStore.audit: ugi=yinzhengjie ip=unknown-ip-addr cmd=get_partition_with_auth : db=yinzhengjie tbl=test2[beijing] 18/06/14 06:52:04 INFO metastore.HiveMetaStore: 0: get_partition_with_auth : db=yinzhengjie tbl=test2[beijing] 18/06/14 06:52:04 INFO HiveMetaStore.audit: ugi=yinzhengjie ip=unknown-ip-addr cmd=get_partition_with_auth : db=yinzhengjie tbl=test2[beijing] 18/06/14 06:52:04 INFO ql.Driver: Semantic Analysis Completed 18/06/14 06:52:04 INFO ql.Driver: Returning Hive schema: Schema(fieldSchemas:null, properties:null) 18/06/14 06:52:04 INFO ql.Driver: Completed compiling command(queryId=yinzhengjie_20180614065203_2cb29172-e5bb-43bd-abf6-4d33c3fffb48); Time taken: 0.931 seconds 18/06/14 06:52:04 INFO ql.Driver: Concurrency mode is disabled, not creating a lock manager 18/06/14 06:52:04 INFO ql.Driver: Executing command(queryId=yinzhengjie_20180614065203_2cb29172-e5bb-43bd-abf6-4d33c3fffb48): LOAD DATA INPATH 'hdfs://mycluster/user/yinzhengjie/word' INTO TABLE `yinzhengjie`.`test2` PARTITION (province='beijing') 18/06/14 06:52:04 INFO ql.Driver: Starting task [Stage-0:MOVE] in serial mode Loading data to table yinzhengjie.test2 partition (province=beijing) 18/06/14 06:52:04 INFO exec.Task: Loading data to table yinzhengjie.test2 partition (province=beijing) from hdfs://mycluster/user/yinzhengjie/word 18/06/14 06:52:04 INFO metastore.HiveMetaStore: 0: get_table : db=yinzhengjie tbl=test2 18/06/14 06:52:04 INFO HiveMetaStore.audit: ugi=yinzhengjie ip=unknown-ip-addr cmd=get_table : db=yinzhengjie tbl=test2 18/06/14 06:52:04 INFO metastore.HiveMetaStore: 0: get_partition_with_auth : db=yinzhengjie tbl=test2[beijing] 18/06/14 06:52:04 INFO HiveMetaStore.audit: ugi=yinzhengjie ip=unknown-ip-addr cmd=get_partition_with_auth : db=yinzhengjie tbl=test2[beijing] 18/06/14 06:52:04 INFO exec.MoveTask: Partition is: {province=beijing} 18/06/14 06:52:04 INFO metastore.HiveMetaStore: 0: partition_name_has_valid_characters 18/06/14 06:52:04 INFO HiveMetaStore.audit: ugi=yinzhengjie ip=unknown-ip-addr cmd=partition_name_has_valid_characters 18/06/14 06:52:04 INFO metastore.HiveMetaStore: 0: get_table : db=yinzhengjie tbl=test2 18/06/14 06:52:04 INFO HiveMetaStore.audit: ugi=yinzhengjie ip=unknown-ip-addr cmd=get_table : db=yinzhengjie tbl=test2 18/06/14 06:52:04 INFO metastore.HiveMetaStore: 0: get_partition_with_auth : db=yinzhengjie tbl=test2[beijing] 18/06/14 06:52:04 INFO HiveMetaStore.audit: ugi=yinzhengjie ip=unknown-ip-addr cmd=get_partition_with_auth : db=yinzhengjie tbl=test2[beijing] 18/06/14 06:52:04 INFO common.FileUtils: Creating directory if it doesn't exist: hdfs://mycluster/user/hive/warehouse/yinzhengjie.db/test2/province=beijing 18/06/14 06:52:04 ERROR hdfs.KeyProviderCache: Could not find uri with key [dfs.encryption.key.provider.uri] to create a keyProvider !! 18/06/14 06:52:04 INFO metastore.HiveMetaStore: 0: add_partition : db=yinzhengjie tbl=test2 18/06/14 06:52:04 INFO HiveMetaStore.audit: ugi=yinzhengjie ip=unknown-ip-addr cmd=add_partition : db=yinzhengjie tbl=test2 18/06/14 06:52:05 INFO metastore.HiveMetaStore: 0: get_partition_with_auth : db=yinzhengjie tbl=test2[beijing] 18/06/14 06:52:05 INFO HiveMetaStore.audit: ugi=yinzhengjie ip=unknown-ip-addr cmd=get_partition_with_auth : db=yinzhengjie tbl=test2[beijing] 18/06/14 06:52:05 INFO ql.Driver: Starting task [Stage-1:STATS] in serial mode 18/06/14 06:52:05 INFO exec.StatsTask: Executing stats task 18/06/14 06:52:05 INFO metastore.HiveMetaStore: 0: get_table : db=yinzhengjie tbl=test2 18/06/14 06:52:05 INFO HiveMetaStore.audit: ugi=yinzhengjie ip=unknown-ip-addr cmd=get_table : db=yinzhengjie tbl=test2 18/06/14 06:52:05 INFO metastore.HiveMetaStore: 0: get_table : db=yinzhengjie tbl=test2 18/06/14 06:52:05 INFO HiveMetaStore.audit: ugi=yinzhengjie ip=unknown-ip-addr cmd=get_table : db=yinzhengjie tbl=test2 18/06/14 06:52:05 INFO metastore.HiveMetaStore: 0: get_partition_with_auth : db=yinzhengjie tbl=test2[beijing] 18/06/14 06:52:05 INFO HiveMetaStore.audit: ugi=yinzhengjie ip=unknown-ip-addr cmd=get_partition_with_auth : db=yinzhengjie tbl=test2[beijing] 18/06/14 06:52:05 INFO exec.StatsTask: Partition yinzhengjie.test2{province=beijing} stats: [numFiles=1, numRows=0, totalSize=74, rawDataSize=0] 18/06/14 06:52:05 INFO metastore.HiveMetaStore: 0: alter_partitions : db=yinzhengjie tbl=test2 18/06/14 06:52:05 INFO HiveMetaStore.audit: ugi=yinzhengjie ip=unknown-ip-addr cmd=alter_partitions : db=yinzhengjie tbl=test2 18/06/14 06:52:05 INFO metastore.HiveMetaStore: New partition values:[beijing] 18/06/14 06:52:05 INFO ql.Driver: Completed executing command(queryId=yinzhengjie_20180614065203_2cb29172-e5bb-43bd-abf6-4d33c3fffb48); Time taken: 1.324 seconds OK 18/06/14 06:52:05 INFO ql.Driver: OK Time taken: 2.255 seconds 18/06/14 06:52:05 INFO CliDriver: Time taken: 2.255 seconds 18/06/14 06:52:05 INFO conf.HiveConf: Using the default value passed in for log id: 520c334d-3342-4ac4-aa9e-32b6afc099a2 18/06/14 06:52:05 INFO session.SessionState: Resetting thread name to main 18/06/14 06:52:05 INFO conf.HiveConf: Using the default value passed in for log id: 520c334d-3342-4ac4-aa9e-32b6afc099a2 18/06/14 06:52:05 INFO session.SessionState: Deleted directory: /tmp/hive/yinzhengjie/520c334d-3342-4ac4-aa9e-32b6afc099a2 on fs with scheme hdfs 18/06/14 06:52:05 INFO session.SessionState: Deleted directory: /home/yinzhengjie/yinzhengjie/520c334d-3342-4ac4-aa9e-32b6afc099a2 on fs with scheme file 18/06/14 06:52:05 INFO metastore.HiveMetaStore: 0: Cleaning up thread local RawStore... 18/06/14 06:52:05 INFO HiveMetaStore.audit: ugi=yinzhengjie ip=unknown-ip-addr cmd=Cleaning up thread local RawStore... 18/06/14 06:52:05 INFO metastore.HiveMetaStore: 0: Done cleaning up thread local RawStore 18/06/14 06:52:05 INFO HiveMetaStore.audit: ugi=yinzhengjie ip=unknown-ip-addr cmd=Done cleaning up thread local RawStore 18/06/14 06:52:05 INFO hive.HiveImport: Hive import complete. [yinzhengjie@s101 ~]$ echo $? 0 [yinzhengjie@s101 ~]$
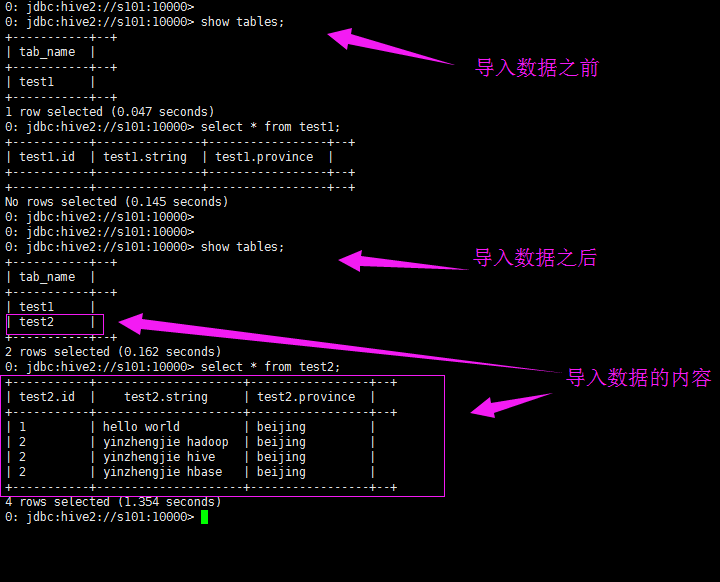
9>.sqoop增量导入
[yinzhengjie@s101 ~]$ sqoop import --connect jdbc:mysql://s101/yinzhengjie --username root -P --table user --fields-terminated-by ' ' --hive-import --create-hive-table --hive-database yinzhengjie --hive-table test3 --hive-partition-key province --hive-partition-value beijing -m 1 Warning: /soft/sqoop-1.4.7.bin__hadoop-2.6.0/bin/../../hcatalog does not exist! HCatalog jobs will fail. Please set $HCAT_HOME to the root of your HCatalog installation. Warning: /soft/sqoop-1.4.7.bin__hadoop-2.6.0/bin/../../accumulo does not exist! Accumulo imports will fail. Please set $ACCUMULO_HOME to the root of your Accumulo installation. Warning: /soft/sqoop-1.4.7.bin__hadoop-2.6.0/bin/../../zookeeper does not exist! Accumulo imports will fail. Please set $ZOOKEEPER_HOME to the root of your Zookeeper installation. 18/06/14 07:25:15 INFO sqoop.Sqoop: Running Sqoop version: 1.4.7 Enter password: 18/06/14 07:25:18 INFO manager.MySQLManager: Preparing to use a MySQL streaming resultset. 18/06/14 07:25:18 INFO tool.CodeGenTool: Beginning code generation SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/soft/hadoop-2.7.3/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/soft/hbase-1.2.6/lib/phoenix-4.10.0-HBase-1.2-client.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/soft/hbase-1.2.6/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/soft/apache-hive-2.1.1-bin/lib/log4j-slf4j-impl-2.4.1.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory] 18/06/14 07:25:19 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `user` AS t LIMIT 1 18/06/14 07:25:19 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `user` AS t LIMIT 1 18/06/14 07:25:19 INFO orm.CompilationManager: HADOOP_MAPRED_HOME is /soft/hadoop Note: /tmp/sqoop-yinzhengjie/compile/094e32eb529484850a3218f3ce12dff2/user.java uses or overrides a deprecated API. Note: Recompile with -Xlint:deprecation for details. 18/06/14 07:25:22 INFO orm.CompilationManager: Writing jar file: /tmp/sqoop-yinzhengjie/compile/094e32eb529484850a3218f3ce12dff2/user.jar 18/06/14 07:25:22 WARN manager.MySQLManager: It looks like you are importing from mysql. 18/06/14 07:25:22 WARN manager.MySQLManager: This transfer can be faster! Use the --direct 18/06/14 07:25:22 WARN manager.MySQLManager: option to exercise a MySQL-specific fast path. 18/06/14 07:25:22 INFO manager.MySQLManager: Setting zero DATETIME behavior to convertToNull (mysql) 18/06/14 07:25:22 INFO mapreduce.ImportJobBase: Beginning import of user 18/06/14 07:25:23 INFO Configuration.deprecation: mapred.jar is deprecated. Instead, use mapreduce.job.jar 18/06/14 07:25:24 INFO Configuration.deprecation: mapred.map.tasks is deprecated. Instead, use mapreduce.job.maps 18/06/14 07:25:39 INFO db.DBInputFormat: Using read commited transaction isolation 18/06/14 07:25:39 INFO mapreduce.JobSubmitter: number of splits:1 18/06/14 07:25:41 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1528967628934_0016 18/06/14 07:25:41 INFO impl.YarnClientImpl: Submitted application application_1528967628934_0016 18/06/14 07:25:41 INFO mapreduce.Job: The url to track the job: http://s101:8088/proxy/application_1528967628934_0016/ 18/06/14 07:25:41 INFO mapreduce.Job: Running job: job_1528967628934_0016 18/06/14 07:25:55 INFO mapreduce.Job: Job job_1528967628934_0016 running in uber mode : false 18/06/14 07:25:55 INFO mapreduce.Job: map 0% reduce 0% 18/06/14 07:26:07 INFO mapreduce.Job: map 100% reduce 0% 18/06/14 07:26:07 INFO mapreduce.Job: Job job_1528967628934_0016 completed successfully 18/06/14 07:26:07 INFO mapreduce.Job: Counters: 30 File System Counters FILE: Number of bytes read=0 FILE: Number of bytes written=140490 FILE: Number of read operations=0 FILE: Number of large read operations=0 FILE: Number of write operations=0 HDFS: Number of bytes read=87 HDFS: Number of bytes written=58 HDFS: Number of read operations=4 HDFS: Number of large read operations=0 HDFS: Number of write operations=2 Job Counters Launched map tasks=1 Other local map tasks=1 Total time spent by all maps in occupied slots (ms)=9299 Total time spent by all reduces in occupied slots (ms)=0 Total time spent by all map tasks (ms)=9299 Total vcore-milliseconds taken by all map tasks=9299 Total megabyte-milliseconds taken by all map tasks=9522176 Map-Reduce Framework Map input records=5 Map output records=5 Input split bytes=87 Spilled Records=0 Failed Shuffles=0 Merged Map outputs=0 GC time elapsed (ms)=88 CPU time spent (ms)=1070 Physical memory (bytes) snapshot=103718912 Virtual memory (bytes) snapshot=2086359040 Total committed heap usage (bytes)=18776064 File Input Format Counters Bytes Read=0 File Output Format Counters Bytes Written=58 18/06/14 07:26:07 INFO mapreduce.ImportJobBase: Transferred 58 bytes in 43.2821 seconds (1.34 bytes/sec) 18/06/14 07:26:07 INFO mapreduce.ImportJobBase: Retrieved 5 records. 18/06/14 07:26:07 INFO mapreduce.ImportJobBase: Publishing Hive/Hcat import job data to Listeners for table user 18/06/14 07:26:07 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `user` AS t LIMIT 1 18/06/14 07:26:07 INFO hive.HiveImport: Loading uploaded data into Hive 18/06/14 07:26:07 INFO conf.HiveConf: Found configuration file file:/soft/hive/conf/hive-site.xml Logging initialized using configuration in jar:file:/soft/apache-hive-2.1.1-bin/lib/hive-common-2.1.1.jar!/hive-log4j2.properties Async: true 18/06/14 07:26:10 INFO SessionState: Logging initialized using configuration in jar:file:/soft/apache-hive-2.1.1-bin/lib/hive-common-2.1.1.jar!/hive-log4j2.properties Async: true 18/06/14 07:26:10 INFO metastore.HiveMetaStore: 0: Opening raw store with implementation class:org.apache.hadoop.hive.metastore.ObjectStore 18/06/14 07:26:16 INFO metastore.ObjectStore: ObjectStore, initialize called 18/06/14 07:26:16 INFO DataNucleus.Persistence: Property hive.metastore.integral.jdo.pushdown unknown - will be ignored 18/06/14 07:26:16 INFO DataNucleus.Persistence: Property datanucleus.cache.level2 unknown - will be ignored 18/06/14 07:26:17 INFO metastore.ObjectStore: Setting MetaStore object pin classes with hive.metastore.cache.pinobjtypes="Table,StorageDescriptor,SerDeInfo,Partition,Database,Type,FieldSchema,Order" 18/06/14 07:26:20 INFO metastore.MetaStoreDirectSql: Using direct SQL, underlying DB is MYSQL 18/06/14 07:26:20 INFO metastore.ObjectStore: Initialized ObjectStore 18/06/14 07:26:20 INFO metastore.HiveMetaStore: Added admin role in metastore 18/06/14 07:26:20 INFO metastore.HiveMetaStore: Added public role in metastore 18/06/14 07:26:20 INFO metastore.HiveMetaStore: No user is added in admin role, since config is empty 18/06/14 07:26:21 INFO metastore.HiveMetaStore: 0: get_all_functions 18/06/14 07:26:21 INFO HiveMetaStore.audit: ugi=yinzhengjie ip=unknown-ip-addr cmd=get_all_functions 18/06/14 07:26:21 INFO metadata.Hive: Registering function parsejson cn.org.yinzhengjie.udf.ParseJson 18/06/14 07:26:22 WARN metadata.Hive: Failed to register persistent function parsejson:cn.org.yinzhengjie.udf.ParseJson. Ignore and continue. 18/06/14 07:26:22 INFO metadata.Hive: Registering function parsejson cn.org.yinzhengjie.udf.MyUDTF 18/06/14 07:26:22 WARN metadata.Hive: Failed to register persistent function parsejson:cn.org.yinzhengjie.udf.MyUDTF. Ignore and continue. 18/06/14 07:26:22 INFO metadata.Hive: Registering function todate cn.org.yinzhengjie.udf.MyUDTF 18/06/14 07:26:22 WARN metadata.Hive: Failed to register persistent function todate:cn.org.yinzhengjie.udf.MyUDTF. Ignore and continue. 18/06/14 07:26:22 INFO session.SessionState: Created HDFS directory: /tmp/hive/yinzhengjie/b32fc742-42a1-4fe0-b9be-2892ba183f7f 18/06/14 07:26:22 INFO session.SessionState: Created local directory: /home/yinzhengjie/yinzhengjie/b32fc742-42a1-4fe0-b9be-2892ba183f7f 18/06/14 07:26:22 INFO session.SessionState: Created HDFS directory: /tmp/hive/yinzhengjie/b32fc742-42a1-4fe0-b9be-2892ba183f7f/_tmp_space.db 18/06/14 07:26:22 INFO conf.HiveConf: Using the default value passed in for log id: b32fc742-42a1-4fe0-b9be-2892ba183f7f 18/06/14 07:26:22 INFO session.SessionState: Updating thread name to b32fc742-42a1-4fe0-b9be-2892ba183f7f main 18/06/14 07:26:22 INFO conf.HiveConf: Using the default value passed in for log id: b32fc742-42a1-4fe0-b9be-2892ba183f7f 18/06/14 07:26:22 INFO ql.Driver: Compiling command(queryId=yinzhengjie_20180614072622_4c4ae3f2-b869-4650-a4dd-d4e8956b508c): show databases 18/06/14 07:26:23 INFO ql.Driver: Semantic Analysis Completed 18/06/14 07:26:23 INFO ql.Driver: Returning Hive schema: Schema(fieldSchemas:[FieldSchema(name:database_name, type:string, comment:from deserializer)], properties:null) 18/06/14 07:26:24 INFO exec.ListSinkOperator: Initializing operator LIST_SINK[0] 18/06/14 07:26:24 INFO ql.Driver: Completed compiling command(queryId=yinzhengjie_20180614072622_4c4ae3f2-b869-4650-a4dd-d4e8956b508c); Time taken: 1.844 seconds 18/06/14 07:26:24 INFO ql.Driver: Concurrency mode is disabled, not creating a lock manager 18/06/14 07:26:24 INFO ql.Driver: Executing command(queryId=yinzhengjie_20180614072622_4c4ae3f2-b869-4650-a4dd-d4e8956b508c): show databases 18/06/14 07:26:24 INFO ql.Driver: Starting task [Stage-0:DDL] in serial mode 18/06/14 07:26:24 INFO metastore.HiveMetaStore: 0: get_all_databases 18/06/14 07:26:24 INFO HiveMetaStore.audit: ugi=yinzhengjie ip=unknown-ip-addr cmd=get_all_databases 18/06/14 07:26:24 INFO exec.DDLTask: results : 2 18/06/14 07:26:24 INFO ql.Driver: Completed executing command(queryId=yinzhengjie_20180614072622_4c4ae3f2-b869-4650-a4dd-d4e8956b508c); Time taken: 0.148 seconds 18/06/14 07:26:24 INFO ql.Driver: OK 18/06/14 07:26:24 INFO Configuration.deprecation: mapred.input.dir is deprecated. Instead, use mapreduce.input.fileinputformat.inputdir 18/06/14 07:26:24 INFO mapred.FileInputFormat: Total input paths to process : 1 default yinzhengjie 18/06/14 07:26:24 INFO CliDriver: Time taken: 2.028 seconds, Fetched: 2 row(s) 18/06/14 07:26:24 INFO conf.HiveConf: Using the default value passed in for log id: b32fc742-42a1-4fe0-b9be-2892ba183f7f 18/06/14 07:26:24 INFO session.SessionState: Resetting thread name to main 18/06/14 07:26:24 INFO conf.HiveConf: Using the default value passed in for log id: b32fc742-42a1-4fe0-b9be-2892ba183f7f 18/06/14 07:26:24 INFO session.SessionState: Updating thread name to b32fc742-42a1-4fe0-b9be-2892ba183f7f main 18/06/14 07:26:24 INFO ql.Driver: Compiling command(queryId=yinzhengjie_20180614072624_7058afb1-ac99-4741-923a-5c47a4671cf1): CREATE TABLE `yinzhengjie`.`test3` ( `id` INT, `name` STRING, `age` INT) COMMENT 'Imported by sqoop on 2018/06/14 07:26:07' PARTITIONED BY (province STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY '�11' LINES TERMINATED BY '�12' STORED AS TEXTFILE 18/06/14 07:26:24 INFO parse.CalcitePlanner: Starting Semantic Analysis 18/06/14 07:26:24 INFO parse.CalcitePlanner: Creating table yinzhengjie.test3 position=13 18/06/14 07:26:24 INFO metastore.HiveMetaStore: 0: get_database: yinzhengjie 18/06/14 07:26:24 INFO HiveMetaStore.audit: ugi=yinzhengjie ip=unknown-ip-addr cmd=get_database: yinzhengjie 18/06/14 07:26:25 INFO sqlstd.SQLStdHiveAccessController: Created SQLStdHiveAccessController for session context : HiveAuthzSessionContext [sessionString=b32fc742-42a1-4fe0-b9be-2892ba183f7f, clientType=HIVECLI] 18/06/14 07:26:25 WARN session.SessionState: METASTORE_FILTER_HOOK will be ignored, since hive.security.authorization.manager is set to instance of HiveAuthorizerFactory. 18/06/14 07:26:25 INFO hive.metastore: Mestastore configuration hive.metastore.filter.hook changed from org.apache.hadoop.hive.metastore.DefaultMetaStoreFilterHookImpl to org.apache.hadoop.hive.ql.security.authorization.plugin.AuthorizationMetaStoreFilterHook 18/06/14 07:26:25 INFO metastore.HiveMetaStore: 0: Cleaning up thread local RawStore... 18/06/14 07:26:25 INFO HiveMetaStore.audit: ugi=yinzhengjie ip=unknown-ip-addr cmd=Cleaning up thread local RawStore... 18/06/14 07:26:25 INFO metastore.HiveMetaStore: 0: Done cleaning up thread local RawStore 18/06/14 07:26:25 INFO HiveMetaStore.audit: ugi=yinzhengjie ip=unknown-ip-addr cmd=Done cleaning up thread local RawStore 18/06/14 07:26:25 INFO ql.Driver: Semantic Analysis Completed 18/06/14 07:26:25 INFO ql.Driver: Returning Hive schema: Schema(fieldSchemas:null, properties:null) 18/06/14 07:26:25 INFO ql.Driver: Completed compiling command(queryId=yinzhengjie_20180614072624_7058afb1-ac99-4741-923a-5c47a4671cf1); Time taken: 0.731 seconds 18/06/14 07:26:25 INFO ql.Driver: Concurrency mode is disabled, not creating a lock manager 18/06/14 07:26:25 INFO ql.Driver: Executing command(queryId=yinzhengjie_20180614072624_7058afb1-ac99-4741-923a-5c47a4671cf1): CREATE TABLE `yinzhengjie`.`test3` ( `id` INT, `name` STRING, `age` INT) COMMENT 'Imported by sqoop on 2018/06/14 07:26:07' PARTITIONED BY (province STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY '�11' LINES TERMINATED BY '�12' STORED AS TEXTFILE 18/06/14 07:26:25 INFO ql.Driver: Starting task [Stage-0:DDL] in serial mode 18/06/14 07:26:25 INFO exec.DDLTask: creating table yinzhengjie.test3 on null 18/06/14 07:26:25 INFO metastore.HiveMetaStore: 0: create_table: Table(tableName:test3, dbName:yinzhengjie, owner:yinzhengjie, createTime:1528986385, lastAccessTime:0, retention:0, sd:StorageDescriptor(cols:[FieldSchema(name:id, type:int, comment:null), FieldSchema(name:name, type:string, comment:null), FieldSchema(name:age, type:int, comment:null)], location:null, inputFormat:org.apache.hadoop.mapred.TextInputFormat, outputFormat:org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat, compressed:false, numBuckets:-1, serdeInfo:SerDeInfo(name:null, serializationLib:org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe, parameters:{serialization.format= , line.delim= , field.delim= }), bucketCols:[], sortCols:[], parameters:{}, skewedInfo:SkewedInfo(skewedColNames:[], skewedColValues:[], skewedColValueLocationMaps:{}), storedAsSubDirectories:false), partitionKeys:[FieldSchema(name:province, type:string, comment:null)], parameters:{comment=Imported by sqoop on 2018/06/14 07:26:07}, viewOriginalText:null, viewExpandedText:null, tableType:MANAGED_TABLE, privileges:PrincipalPrivilegeSet(userPrivileges:{yinzhengjie=[PrivilegeGrantInfo(privilege:INSERT, createTime:-1, grantor:yinzhengjie, grantorType:USER, grantOption:true), PrivilegeGrantInfo(privilege:SELECT, createTime:-1, grantor:yinzhengjie, grantorType:USER, grantOption:true), PrivilegeGrantInfo(privilege:UPDATE, createTime:-1, grantor:yinzhengjie, grantorType:USER, grantOption:true), PrivilegeGrantInfo(privilege:DELETE, createTime:-1, grantor:yinzhengjie, grantorType:USER, grantOption:true)]}, groupPrivileges:null, rolePrivileges:null), temporary:false) 18/06/14 07:26:25 INFO HiveMetaStore.audit: ugi=yinzhengjie ip=unknown-ip-addr cmd=create_table: Table(tableName:test3, dbName:yinzhengjie, owner:yinzhengjie, createTime:1528986385, lastAccessTime:0, retention:0, sd:StorageDescriptor(cols:[FieldSchema(name:id, type:int, comment:null), FieldSchema(name:name, type:string, comment:null), FieldSchema(name:age, type:int, comment:null)], location:null, inputFormat:org.apache.hadoop.mapred.TextInputFormat, outputFormat:org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat, compressed:false, numBuckets:-1, serdeInfo:SerDeInfo(name:null, serializationLib:org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe, parameters:{serialization.format= , line.delim= , field.delim= }), bucketCols:[], sortCols:[], parameters:{}, skewedInfo:SkewedInfo(skewedColNames:[], skewedColValues:[], skewedColValueLocationMaps:{}), storedAsSubDirectories:false), partitionKeys:[FieldSchema(name:province, type:string, comment:null)], parameters:{comment=Imported by sqoop on 2018/06/14 07:26:07}, viewOriginalText:null, viewExpandedText:null, tableType:MANAGED_TABLE, privileges:PrincipalPrivilegeSet(userPrivileges:{yinzhengjie=[PrivilegeGrantInfo(privilege:INSERT, createTime:-1, grantor:yinzhengjie, grantorType:USER, grantOption:true), PrivilegeGrantInfo(privilege:SELECT, createTime:-1, grantor:yinzhengjie, grantorType:USER, grantOption:true), PrivilegeGrantInfo(privilege:UPDATE, createTime:-1, grantor:yinzhengjie, grantorType:USER, grantOption:true), PrivilegeGrantInfo(privilege:DELETE, createTime:-1, grantor:yinzhengjie, grantorType:USER, grantOption:true)]}, groupPrivileges:null, rolePrivileges:null), temporary:false) 18/06/14 07:26:25 INFO metastore.HiveMetaStore: 0: Opening raw store with implementation class:org.apache.hadoop.hive.metastore.ObjectStore 18/06/14 07:26:25 INFO metastore.ObjectStore: ObjectStore, initialize called 18/06/14 07:26:25 INFO metastore.MetaStoreDirectSql: Using direct SQL, underlying DB is MYSQL 18/06/14 07:26:25 INFO metastore.ObjectStore: Initialized ObjectStore 18/06/14 07:26:25 INFO common.FileUtils: Creating directory if it doesn't exist: hdfs://mycluster/user/hive/warehouse/yinzhengjie.db/test3 18/06/14 07:26:26 INFO ql.Driver: Completed executing command(queryId=yinzhengjie_20180614072624_7058afb1-ac99-4741-923a-5c47a4671cf1); Time taken: 0.922 seconds OK 18/06/14 07:26:26 INFO ql.Driver: OK Time taken: 1.653 seconds 18/06/14 07:26:26 INFO CliDriver: Time taken: 1.653 seconds 18/06/14 07:26:26 INFO conf.HiveConf: Using the default value passed in for log id: b32fc742-42a1-4fe0-b9be-2892ba183f7f 18/06/14 07:26:26 INFO session.SessionState: Resetting thread name to main 18/06/14 07:26:26 INFO conf.HiveConf: Using the default value passed in for log id: b32fc742-42a1-4fe0-b9be-2892ba183f7f 18/06/14 07:26:26 INFO session.SessionState: Updating thread name to b32fc742-42a1-4fe0-b9be-2892ba183f7f main 18/06/14 07:26:26 INFO ql.Driver: Compiling command(queryId=yinzhengjie_20180614072626_ed96bdc2-701f-456e-9c4b-d0ce261fed96): LOAD DATA INPATH 'hdfs://mycluster/user/yinzhengjie/user' INTO TABLE `yinzhengjie`.`test3` PARTITION (province='beijing') 18/06/14 07:26:26 INFO metastore.HiveMetaStore: 0: get_table : db=yinzhengjie tbl=test3 18/06/14 07:26:26 INFO HiveMetaStore.audit: ugi=yinzhengjie ip=unknown-ip-addr cmd=get_table : db=yinzhengjie tbl=test3 18/06/14 07:26:26 INFO metastore.HiveMetaStore: 0: get_partition_with_auth : db=yinzhengjie tbl=test3[beijing] 18/06/14 07:26:26 INFO HiveMetaStore.audit: ugi=yinzhengjie ip=unknown-ip-addr cmd=get_partition_with_auth : db=yinzhengjie tbl=test3[beijing] 18/06/14 07:26:27 INFO metastore.HiveMetaStore: 0: get_partition_with_auth : db=yinzhengjie tbl=test3[beijing] 18/06/14 07:26:27 INFO HiveMetaStore.audit: ugi=yinzhengjie ip=unknown-ip-addr cmd=get_partition_with_auth : db=yinzhengjie tbl=test3[beijing] 18/06/14 07:26:27 INFO ql.Driver: Semantic Analysis Completed 18/06/14 07:26:27 INFO ql.Driver: Returning Hive schema: Schema(fieldSchemas:null, properties:null) 18/06/14 07:26:27 INFO ql.Driver: Completed compiling command(queryId=yinzhengjie_20180614072626_ed96bdc2-701f-456e-9c4b-d0ce261fed96); Time taken: 1.265 seconds 18/06/14 07:26:27 INFO ql.Driver: Concurrency mode is disabled, not creating a lock manager 18/06/14 07:26:27 INFO ql.Driver: Executing command(queryId=yinzhengjie_20180614072626_ed96bdc2-701f-456e-9c4b-d0ce261fed96): LOAD DATA INPATH 'hdfs://mycluster/user/yinzhengjie/user' INTO TABLE `yinzhengjie`.`test3` PARTITION (province='beijing') 18/06/14 07:26:27 INFO ql.Driver: Starting task [Stage-0:MOVE] in serial mode Loading data to table yinzhengjie.test3 partition (province=beijing) 18/06/14 07:26:27 INFO exec.Task: Loading data to table yinzhengjie.test3 partition (province=beijing) from hdfs://mycluster/user/yinzhengjie/user 18/06/14 07:26:27 INFO metastore.HiveMetaStore: 0: get_table : db=yinzhengjie tbl=test3 18/06/14 07:26:27 INFO HiveMetaStore.audit: ugi=yinzhengjie ip=unknown-ip-addr cmd=get_table : db=yinzhengjie tbl=test3 18/06/14 07:26:27 INFO metastore.HiveMetaStore: 0: get_partition_with_auth : db=yinzhengjie tbl=test3[beijing] 18/06/14 07:26:27 INFO HiveMetaStore.audit: ugi=yinzhengjie ip=unknown-ip-addr cmd=get_partition_with_auth : db=yinzhengjie tbl=test3[beijing] 18/06/14 07:26:27 INFO exec.MoveTask: Partition is: {province=beijing} 18/06/14 07:26:27 INFO metastore.HiveMetaStore: 0: partition_name_has_valid_characters 18/06/14 07:26:27 INFO HiveMetaStore.audit: ugi=yinzhengjie ip=unknown-ip-addr cmd=partition_name_has_valid_characters 18/06/14 07:26:27 INFO metastore.HiveMetaStore: 0: get_table : db=yinzhengjie tbl=test3 18/06/14 07:26:27 INFO HiveMetaStore.audit: ugi=yinzhengjie ip=unknown-ip-addr cmd=get_table : db=yinzhengjie tbl=test3 18/06/14 07:26:27 INFO metastore.HiveMetaStore: 0: get_partition_with_auth : db=yinzhengjie tbl=test3[beijing] 18/06/14 07:26:27 INFO HiveMetaStore.audit: ugi=yinzhengjie ip=unknown-ip-addr cmd=get_partition_with_auth : db=yinzhengjie tbl=test3[beijing] 18/06/14 07:26:27 INFO common.FileUtils: Creating directory if it doesn't exist: hdfs://mycluster/user/hive/warehouse/yinzhengjie.db/test3/province=beijing 18/06/14 07:26:27 ERROR hdfs.KeyProviderCache: Could not find uri with key [dfs.encryption.key.provider.uri] to create a keyProvider !! 18/06/14 07:26:27 INFO metastore.HiveMetaStore: 0: add_partition : db=yinzhengjie tbl=test3 18/06/14 07:26:27 INFO HiveMetaStore.audit: ugi=yinzhengjie ip=unknown-ip-addr cmd=add_partition : db=yinzhengjie tbl=test3 18/06/14 07:26:28 INFO metastore.HiveMetaStore: 0: get_partition_with_auth : db=yinzhengjie tbl=test3[beijing] 18/06/14 07:26:28 INFO HiveMetaStore.audit: ugi=yinzhengjie ip=unknown-ip-addr cmd=get_partition_with_auth : db=yinzhengjie tbl=test3[beijing] 18/06/14 07:26:28 INFO ql.Driver: Starting task [Stage-1:STATS] in serial mode 18/06/14 07:26:28 INFO exec.StatsTask: Executing stats task 18/06/14 07:26:28 INFO metastore.HiveMetaStore: 0: get_table : db=yinzhengjie tbl=test3 18/06/14 07:26:28 INFO HiveMetaStore.audit: ugi=yinzhengjie ip=unknown-ip-addr cmd=get_table : db=yinzhengjie tbl=test3 18/06/14 07:26:28 INFO metastore.HiveMetaStore: 0: get_table : db=yinzhengjie tbl=test3 18/06/14 07:26:28 INFO HiveMetaStore.audit: ugi=yinzhengjie ip=unknown-ip-addr cmd=get_table : db=yinzhengjie tbl=test3 18/06/14 07:26:28 INFO metastore.HiveMetaStore: 0: get_partition_with_auth : db=yinzhengjie tbl=test3[beijing] 18/06/14 07:26:28 INFO HiveMetaStore.audit: ugi=yinzhengjie ip=unknown-ip-addr cmd=get_partition_with_auth : db=yinzhengjie tbl=test3[beijing] 18/06/14 07:26:28 INFO exec.StatsTask: Partition yinzhengjie.test3{province=beijing} stats: [numFiles=1, numRows=0, totalSize=58, rawDataSize=0] 18/06/14 07:26:28 INFO metastore.HiveMetaStore: 0: alter_partitions : db=yinzhengjie tbl=test3 18/06/14 07:26:28 INFO HiveMetaStore.audit: ugi=yinzhengjie ip=unknown-ip-addr cmd=alter_partitions : db=yinzhengjie tbl=test3 18/06/14 07:26:28 INFO metastore.HiveMetaStore: New partition values:[beijing] 18/06/14 07:26:28 INFO ql.Driver: Completed executing command(queryId=yinzhengjie_20180614072626_ed96bdc2-701f-456e-9c4b-d0ce261fed96); Time taken: 0.926 seconds OK 18/06/14 07:26:28 INFO ql.Driver: OK Time taken: 2.192 seconds 18/06/14 07:26:28 INFO CliDriver: Time taken: 2.192 seconds 18/06/14 07:26:28 INFO conf.HiveConf: Using the default value passed in for log id: b32fc742-42a1-4fe0-b9be-2892ba183f7f 18/06/14 07:26:28 INFO session.SessionState: Resetting thread name to main 18/06/14 07:26:28 INFO conf.HiveConf: Using the default value passed in for log id: b32fc742-42a1-4fe0-b9be-2892ba183f7f 18/06/14 07:26:28 INFO session.SessionState: Deleted directory: /tmp/hive/yinzhengjie/b32fc742-42a1-4fe0-b9be-2892ba183f7f on fs with scheme hdfs 18/06/14 07:26:28 INFO session.SessionState: Deleted directory: /home/yinzhengjie/yinzhengjie/b32fc742-42a1-4fe0-b9be-2892ba183f7f on fs with scheme file 18/06/14 07:26:28 INFO metastore.HiveMetaStore: 0: Cleaning up thread local RawStore... 18/06/14 07:26:28 INFO HiveMetaStore.audit: ugi=yinzhengjie ip=unknown-ip-addr cmd=Cleaning up thread local RawStore... 18/06/14 07:26:28 INFO metastore.HiveMetaStore: 0: Done cleaning up thread local RawStore 18/06/14 07:26:28 INFO HiveMetaStore.audit: ugi=yinzhengjie ip=unknown-ip-addr cmd=Done cleaning up thread local RawStore 18/06/14 07:26:28 INFO hive.HiveImport: Hive import complete. [yinzhengjie@s101 ~]$

[yinzhengjie@s101 ~]$ sqoop import --connect jdbc:mysql://s101/yinzhengjie --username root -P --table user --fields-terminated-by ' ' --hive-import --hive-database yinzhengjie --hive-table test3 --hive-partition-key province --hive-partition-value beijing --check-column id --last-value 3 --incremental append -m 1 Warning: /soft/sqoop-1.4.7.bin__hadoop-2.6.0/bin/../../hcatalog does not exist! HCatalog jobs will fail. Please set $HCAT_HOME to the root of your HCatalog installation. Warning: /soft/sqoop-1.4.7.bin__hadoop-2.6.0/bin/../../accumulo does not exist! Accumulo imports will fail. Please set $ACCUMULO_HOME to the root of your Accumulo installation. Warning: /soft/sqoop-1.4.7.bin__hadoop-2.6.0/bin/../../zookeeper does not exist! Accumulo imports will fail. Please set $ZOOKEEPER_HOME to the root of your Zookeeper installation. 18/06/14 07:40:03 INFO sqoop.Sqoop: Running Sqoop version: 1.4.7 Enter password: 18/06/14 07:40:06 INFO manager.MySQLManager: Preparing to use a MySQL streaming resultset. 18/06/14 07:40:06 INFO tool.CodeGenTool: Beginning code generation SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/soft/hadoop-2.7.3/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/soft/hbase-1.2.6/lib/phoenix-4.10.0-HBase-1.2-client.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/soft/hbase-1.2.6/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/soft/apache-hive-2.1.1-bin/lib/log4j-slf4j-impl-2.4.1.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory] 18/06/14 07:40:07 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `user` AS t LIMIT 1 18/06/14 07:40:07 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `user` AS t LIMIT 1 18/06/14 07:40:07 INFO orm.CompilationManager: HADOOP_MAPRED_HOME is /soft/hadoop Note: /tmp/sqoop-yinzhengjie/compile/18863b9e7c77cfbebe522577912fcd65/user.java uses or overrides a deprecated API. Note: Recompile with -Xlint:deprecation for details. 18/06/14 07:40:10 INFO orm.CompilationManager: Writing jar file: /tmp/sqoop-yinzhengjie/compile/18863b9e7c77cfbebe522577912fcd65/user.jar 18/06/14 07:40:10 INFO tool.ImportTool: Maximal id query for free form incremental import: SELECT MAX(`id`) FROM `user` 18/06/14 07:40:10 INFO tool.ImportTool: Incremental import based on column `id` 18/06/14 07:40:10 INFO tool.ImportTool: Lower bound value: 3 18/06/14 07:40:10 INFO tool.ImportTool: Upper bound value: 5 18/06/14 07:40:10 WARN manager.MySQLManager: It looks like you are importing from mysql. 18/06/14 07:40:10 WARN manager.MySQLManager: This transfer can be faster! Use the --direct 18/06/14 07:40:10 WARN manager.MySQLManager: option to exercise a MySQL-specific fast path. 18/06/14 07:40:10 INFO manager.MySQLManager: Setting zero DATETIME behavior to convertToNull (mysql) 18/06/14 07:40:10 INFO mapreduce.ImportJobBase: Beginning import of user 18/06/14 07:40:10 INFO Configuration.deprecation: mapred.jar is deprecated. Instead, use mapreduce.job.jar 18/06/14 07:40:11 INFO Configuration.deprecation: mapred.map.tasks is deprecated. Instead, use mapreduce.job.maps 18/06/14 07:40:17 INFO db.DBInputFormat: Using read commited transaction isolation 18/06/14 07:40:17 INFO mapreduce.JobSubmitter: number of splits:1 18/06/14 07:40:17 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1528967628934_0017 18/06/14 07:40:18 INFO impl.YarnClientImpl: Submitted application application_1528967628934_0017 18/06/14 07:40:19 INFO mapreduce.Job: The url to track the job: http://s101:8088/proxy/application_1528967628934_0017/ 18/06/14 07:40:19 INFO mapreduce.Job: Running job: job_1528967628934_0017 18/06/14 07:40:28 INFO mapreduce.Job: Job job_1528967628934_0017 running in uber mode : false 18/06/14 07:40:28 INFO mapreduce.Job: map 0% reduce 0% 18/06/14 07:40:37 INFO mapreduce.Job: map 100% reduce 0% 18/06/14 07:40:38 INFO mapreduce.Job: Job job_1528967628934_0017 completed successfully 18/06/14 07:40:38 INFO mapreduce.Job: Counters: 30 File System Counters FILE: Number of bytes read=0 FILE: Number of bytes written=140695 FILE: Number of read operations=0 FILE: Number of large read operations=0 FILE: Number of write operations=0 HDFS: Number of bytes read=87 HDFS: Number of bytes written=21 HDFS: Number of read operations=4 HDFS: Number of large read operations=0 HDFS: Number of write operations=2 Job Counters Launched map tasks=1 Other local map tasks=1 Total time spent by all maps in occupied slots (ms)=6858 Total time spent by all reduces in occupied slots (ms)=0 Total time spent by all map tasks (ms)=6858 Total vcore-milliseconds taken by all map tasks=6858 Total megabyte-milliseconds taken by all map tasks=7022592 Map-Reduce Framework Map input records=2 Map output records=2 Input split bytes=87 Spilled Records=0 Failed Shuffles=0 Merged Map outputs=0 GC time elapsed (ms)=82 CPU time spent (ms)=1080 Physical memory (bytes) snapshot=102739968 Virtual memory (bytes) snapshot=2086359040 Total committed heap usage (bytes)=19517440 File Input Format Counters Bytes Read=0 File Output Format Counters Bytes Written=21 18/06/14 07:40:38 INFO mapreduce.ImportJobBase: Transferred 21 bytes in 27.3862 seconds (0.7668 bytes/sec) 18/06/14 07:40:38 INFO mapreduce.ImportJobBase: Retrieved 2 records. 18/06/14 07:40:38 INFO mapreduce.ImportJobBase: Publishing Hive/Hcat import job data to Listeners for table user 18/06/14 07:40:38 INFO util.AppendUtils: Creating missing output directory - user 18/06/14 07:40:39 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `user` AS t LIMIT 1 18/06/14 07:40:39 INFO hive.HiveImport: Loading uploaded data into Hive 18/06/14 07:40:39 INFO conf.HiveConf: Found configuration file file:/soft/hive/conf/hive-site.xml Logging initialized using configuration in jar:file:/soft/apache-hive-2.1.1-bin/lib/hive-common-2.1.1.jar!/hive-log4j2.properties Async: true 18/06/14 07:40:41 INFO SessionState: Logging initialized using configuration in jar:file:/soft/apache-hive-2.1.1-bin/lib/hive-common-2.1.1.jar!/hive-log4j2.properties Async: true 18/06/14 07:40:42 INFO metastore.HiveMetaStore: 0: Opening raw store with implementation class:org.apache.hadoop.hive.metastore.ObjectStore 18/06/14 07:40:46 INFO metastore.ObjectStore: ObjectStore, initialize called 18/06/14 07:40:46 INFO DataNucleus.Persistence: Property hive.metastore.integral.jdo.pushdown unknown - will be ignored 18/06/14 07:40:46 INFO DataNucleus.Persistence: Property datanucleus.cache.level2 unknown - will be ignored 18/06/14 07:40:47 INFO metastore.ObjectStore: Setting MetaStore object pin classes with hive.metastore.cache.pinobjtypes="Table,StorageDescriptor,SerDeInfo,Partition,Database,Type,FieldSchema,Order" 18/06/14 07:40:50 INFO metastore.MetaStoreDirectSql: Using direct SQL, underlying DB is MYSQL 18/06/14 07:40:50 INFO metastore.ObjectStore: Initialized ObjectStore 18/06/14 07:40:50 INFO metastore.HiveMetaStore: Added admin role in metastore 18/06/14 07:40:50 INFO metastore.HiveMetaStore: Added public role in metastore 18/06/14 07:40:50 INFO metastore.HiveMetaStore: No user is added in admin role, since config is empty 18/06/14 07:40:51 INFO metastore.HiveMetaStore: 0: get_all_functions 18/06/14 07:40:51 INFO HiveMetaStore.audit: ugi=yinzhengjie ip=unknown-ip-addr cmd=get_all_functions 18/06/14 07:40:51 INFO metadata.Hive: Registering function parsejson cn.org.yinzhengjie.udf.ParseJson 18/06/14 07:40:51 WARN metadata.Hive: Failed to register persistent function parsejson:cn.org.yinzhengjie.udf.ParseJson. Ignore and continue. 18/06/14 07:40:51 INFO metadata.Hive: Registering function parsejson cn.org.yinzhengjie.udf.MyUDTF 18/06/14 07:40:51 WARN metadata.Hive: Failed to register persistent function parsejson:cn.org.yinzhengjie.udf.MyUDTF. Ignore and continue. 18/06/14 07:40:51 INFO metadata.Hive: Registering function todate cn.org.yinzhengjie.udf.MyUDTF 18/06/14 07:40:51 WARN metadata.Hive: Failed to register persistent function todate:cn.org.yinzhengjie.udf.MyUDTF. Ignore and continue. 18/06/14 07:40:51 INFO session.SessionState: Created HDFS directory: /tmp/hive/yinzhengjie/8c8d3572-c995-4504-8ab4-8e57b757b141 18/06/14 07:40:51 INFO session.SessionState: Created local directory: /home/yinzhengjie/yinzhengjie/8c8d3572-c995-4504-8ab4-8e57b757b141 18/06/14 07:40:51 INFO session.SessionState: Created HDFS directory: /tmp/hive/yinzhengjie/8c8d3572-c995-4504-8ab4-8e57b757b141/_tmp_space.db 18/06/14 07:40:51 INFO conf.HiveConf: Using the default value passed in for log id: 8c8d3572-c995-4504-8ab4-8e57b757b141 18/06/14 07:40:51 INFO session.SessionState: Updating thread name to 8c8d3572-c995-4504-8ab4-8e57b757b141 main 18/06/14 07:40:51 INFO conf.HiveConf: Using the default value passed in for log id: 8c8d3572-c995-4504-8ab4-8e57b757b141 18/06/14 07:40:52 INFO ql.Driver: Compiling command(queryId=yinzhengjie_20180614074052_f0cd040e-63ce-4bbf-a10b-6abc6610e295): show databases 18/06/14 07:40:53 INFO ql.Driver: Semantic Analysis Completed 18/06/14 07:40:53 INFO ql.Driver: Returning Hive schema: Schema(fieldSchemas:[FieldSchema(name:database_name, type:string, comment:from deserializer)], properties:null) 18/06/14 07:40:53 INFO exec.ListSinkOperator: Initializing operator LIST_SINK[0] 18/06/14 07:40:53 INFO ql.Driver: Completed compiling command(queryId=yinzhengjie_20180614074052_f0cd040e-63ce-4bbf-a10b-6abc6610e295); Time taken: 1.493 seconds 18/06/14 07:40:53 INFO ql.Driver: Concurrency mode is disabled, not creating a lock manager 18/06/14 07:40:53 INFO ql.Driver: Executing command(queryId=yinzhengjie_20180614074052_f0cd040e-63ce-4bbf-a10b-6abc6610e295): show databases 18/06/14 07:40:53 INFO ql.Driver: Starting task [Stage-0:DDL] in serial mode 18/06/14 07:40:53 INFO metastore.HiveMetaStore: 0: get_all_databases 18/06/14 07:40:53 INFO HiveMetaStore.audit: ugi=yinzhengjie ip=unknown-ip-addr cmd=get_all_databases 18/06/14 07:40:53 INFO exec.DDLTask: results : 2 18/06/14 07:40:53 INFO ql.Driver: Completed executing command(queryId=yinzhengjie_20180614074052_f0cd040e-63ce-4bbf-a10b-6abc6610e295); Time taken: 0.074 seconds 18/06/14 07:40:53 INFO ql.Driver: OK 18/06/14 07:40:53 INFO Configuration.deprecation: mapred.input.dir is deprecated. Instead, use mapreduce.input.fileinputformat.inputdir 18/06/14 07:40:53 INFO mapred.FileInputFormat: Total input paths to process : 1 default yinzhengjie 18/06/14 07:40:53 INFO CliDriver: Time taken: 1.574 seconds, Fetched: 2 row(s) 18/06/14 07:40:53 INFO conf.HiveConf: Using the default value passed in for log id: 8c8d3572-c995-4504-8ab4-8e57b757b141 18/06/14 07:40:53 INFO session.SessionState: Resetting thread name to main 18/06/14 07:40:53 INFO conf.HiveConf: Using the default value passed in for log id: 8c8d3572-c995-4504-8ab4-8e57b757b141 18/06/14 07:40:53 INFO session.SessionState: Updating thread name to 8c8d3572-c995-4504-8ab4-8e57b757b141 main 18/06/14 07:40:53 INFO ql.Driver: Compiling command(queryId=yinzhengjie_20180614074053_92c70cb8-1936-4bd0-b61b-81e7935456de): CREATE TABLE IF NOT EXISTS `yinzhengjie`.`test3` ( `id` INT, `name` STRING, `age` INT) COMMENT 'Imported by sqoop on 2018/06/14 07:40:39' PARTITIONED BY (province STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY '�11' LINES TERMINATED BY '�12' STORED AS TEXTFILE 18/06/14 07:40:53 INFO parse.CalcitePlanner: Starting Semantic Analysis 18/06/14 07:40:53 INFO parse.CalcitePlanner: Creating table yinzhengjie.test3 position=27 18/06/14 07:40:53 INFO metastore.HiveMetaStore: 0: get_table : db=yinzhengjie tbl=test3 18/06/14 07:40:53 INFO HiveMetaStore.audit: ugi=yinzhengjie ip=unknown-ip-addr cmd=get_table : db=yinzhengjie tbl=test3 18/06/14 07:40:54 INFO ql.Driver: Semantic Analysis Completed 18/06/14 07:40:54 INFO ql.Driver: Returning Hive schema: Schema(fieldSchemas:null, properties:null) 18/06/14 07:40:54 INFO ql.Driver: Completed compiling command(queryId=yinzhengjie_20180614074053_92c70cb8-1936-4bd0-b61b-81e7935456de); Time taken: 0.276 seconds 18/06/14 07:40:54 INFO ql.Driver: Concurrency mode is disabled, not creating a lock manager 18/06/14 07:40:54 INFO ql.Driver: Executing command(queryId=yinzhengjie_20180614074053_92c70cb8-1936-4bd0-b61b-81e7935456de): CREATE TABLE IF NOT EXISTS `yinzhengjie`.`test3` ( `id` INT, `name` STRING, `age` INT) COMMENT 'Imported by sqoop on 2018/06/14 07:40:39' PARTITIONED BY (province STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY '�11' LINES TERMINATED BY '�12' STORED AS TEXTFILE 18/06/14 07:40:54 INFO ql.Driver: Completed executing command(queryId=yinzhengjie_20180614074053_92c70cb8-1936-4bd0-b61b-81e7935456de); Time taken: 0.014 seconds OK 18/06/14 07:40:54 INFO ql.Driver: OK Time taken: 0.292 seconds 18/06/14 07:40:54 INFO CliDriver: Time taken: 0.292 seconds 18/06/14 07:40:54 INFO conf.HiveConf: Using the default value passed in for log id: 8c8d3572-c995-4504-8ab4-8e57b757b141 18/06/14 07:40:54 INFO session.SessionState: Resetting thread name to main 18/06/14 07:40:54 INFO conf.HiveConf: Using the default value passed in for log id: 8c8d3572-c995-4504-8ab4-8e57b757b141 18/06/14 07:40:54 INFO session.SessionState: Updating thread name to 8c8d3572-c995-4504-8ab4-8e57b757b141 main 18/06/14 07:40:54 INFO ql.Driver: Compiling command(queryId=yinzhengjie_20180614074054_841a2915-844f-45ae-9ad9-431c5179ee48): LOAD DATA INPATH 'hdfs://mycluster/user/yinzhengjie/user' INTO TABLE `yinzhengjie`.`test3` PARTITION (province='beijing') 18/06/14 07:40:54 INFO metastore.HiveMetaStore: 0: get_table : db=yinzhengjie tbl=test3 18/06/14 07:40:54 INFO HiveMetaStore.audit: ugi=yinzhengjie ip=unknown-ip-addr cmd=get_table : db=yinzhengjie tbl=test3 18/06/14 07:40:54 INFO sqlstd.SQLStdHiveAccessController: Created SQLStdHiveAccessController for session context : HiveAuthzSessionContext [sessionString=8c8d3572-c995-4504-8ab4-8e57b757b141, clientType=HIVECLI] 18/06/14 07:40:54 WARN session.SessionState: METASTORE_FILTER_HOOK will be ignored, since hive.security.authorization.manager is set to instance of HiveAuthorizerFactory. 18/06/14 07:40:54 INFO hive.metastore: Mestastore configuration hive.metastore.filter.hook changed from org.apache.hadoop.hive.metastore.DefaultMetaStoreFilterHookImpl to org.apache.hadoop.hive.ql.security.authorization.plugin.AuthorizationMetaStoreFilterHook 18/06/14 07:40:54 INFO metastore.HiveMetaStore: 0: Cleaning up thread local RawStore... 18/06/14 07:40:54 INFO HiveMetaStore.audit: ugi=yinzhengjie ip=unknown-ip-addr cmd=Cleaning up thread local RawStore... 18/06/14 07:40:54 INFO metastore.HiveMetaStore: 0: Done cleaning up thread local RawStore 18/06/14 07:40:54 INFO HiveMetaStore.audit: ugi=yinzhengjie ip=unknown-ip-addr cmd=Done cleaning up thread local RawStore 18/06/14 07:40:54 INFO metastore.HiveMetaStore: 0: get_partition_with_auth : db=yinzhengjie tbl=test3[beijing] 18/06/14 07:40:54 INFO HiveMetaStore.audit: ugi=yinzhengjie ip=unknown-ip-addr cmd=get_partition_with_auth : db=yinzhengjie tbl=test3[beijing] 18/06/14 07:40:54 INFO metastore.HiveMetaStore: 0: Opening raw store with implementation class:org.apache.hadoop.hive.metastore.ObjectStore 18/06/14 07:40:54 INFO metastore.ObjectStore: ObjectStore, initialize called 18/06/14 07:40:54 INFO metastore.MetaStoreDirectSql: Using direct SQL, underlying DB is MYSQL 18/06/14 07:40:54 INFO metastore.ObjectStore: Initialized ObjectStore 18/06/14 07:40:54 INFO metastore.HiveMetaStore: 0: get_partition_with_auth : db=yinzhengjie tbl=test3[beijing] 18/06/14 07:40:54 INFO HiveMetaStore.audit: ugi=yinzhengjie ip=unknown-ip-addr cmd=get_partition_with_auth : db=yinzhengjie tbl=test3[beijing] 18/06/14 07:40:54 INFO ql.Driver: Semantic Analysis Completed 18/06/14 07:40:54 INFO ql.Driver: Returning Hive schema: Schema(fieldSchemas:null, properties:null) 18/06/14 07:40:54 INFO ql.Driver: Completed compiling command(queryId=yinzhengjie_20180614074054_841a2915-844f-45ae-9ad9-431c5179ee48); Time taken: 0.601 seconds 18/06/14 07:40:54 INFO ql.Driver: Concurrency mode is disabled, not creating a lock manager 18/06/14 07:40:54 INFO ql.Driver: Executing command(queryId=yinzhengjie_20180614074054_841a2915-844f-45ae-9ad9-431c5179ee48): LOAD DATA INPATH 'hdfs://mycluster/user/yinzhengjie/user' INTO TABLE `yinzhengjie`.`test3` PARTITION (province='beijing') 18/06/14 07:40:54 INFO ql.Driver: Starting task [Stage-0:MOVE] in serial mode Loading data to table yinzhengjie.test3 partition (province=beijing) 18/06/14 07:40:54 INFO exec.Task: Loading data to table yinzhengjie.test3 partition (province=beijing) from hdfs://mycluster/user/yinzhengjie/user 18/06/14 07:40:54 INFO metastore.HiveMetaStore: 0: get_table : db=yinzhengjie tbl=test3 18/06/14 07:40:54 INFO HiveMetaStore.audit: ugi=yinzhengjie ip=unknown-ip-addr cmd=get_table : db=yinzhengjie tbl=test3 18/06/14 07:40:54 INFO metastore.HiveMetaStore: 0: get_partition_with_auth : db=yinzhengjie tbl=test3[beijing] 18/06/14 07:40:54 INFO HiveMetaStore.audit: ugi=yinzhengjie ip=unknown-ip-addr cmd=get_partition_with_auth : db=yinzhengjie tbl=test3[beijing] 18/06/14 07:40:54 INFO exec.MoveTask: Partition is: {province=beijing} 18/06/14 07:40:54 INFO metastore.HiveMetaStore: 0: partition_name_has_valid_characters 18/06/14 07:40:54 INFO HiveMetaStore.audit: ugi=yinzhengjie ip=unknown-ip-addr cmd=partition_name_has_valid_characters 18/06/14 07:40:54 INFO metastore.HiveMetaStore: 0: get_table : db=yinzhengjie tbl=test3 18/06/14 07:40:54 INFO HiveMetaStore.audit: ugi=yinzhengjie ip=unknown-ip-addr cmd=get_table : db=yinzhengjie tbl=test3 18/06/14 07:40:54 INFO metastore.HiveMetaStore: 0: get_partition_with_auth : db=yinzhengjie tbl=test3[beijing] 18/06/14 07:40:54 INFO HiveMetaStore.audit: ugi=yinzhengjie ip=unknown-ip-addr cmd=get_partition_with_auth : db=yinzhengjie tbl=test3[beijing] 18/06/14 07:40:54 ERROR hdfs.KeyProviderCache: Could not find uri with key [dfs.encryption.key.provider.uri] to create a keyProvider !! 18/06/14 07:40:54 INFO metastore.HiveMetaStore: 0: alter_partition : db=yinzhengjie tbl=test3 18/06/14 07:40:54 INFO HiveMetaStore.audit: ugi=yinzhengjie ip=unknown-ip-addr cmd=alter_partition : db=yinzhengjie tbl=test3 18/06/14 07:40:54 INFO metastore.HiveMetaStore: New partition values:[beijing] 18/06/14 07:40:55 INFO metastore.HiveMetaStore: 0: get_partition_with_auth : db=yinzhengjie tbl=test3[beijing] 18/06/14 07:40:55 INFO HiveMetaStore.audit: ugi=yinzhengjie ip=unknown-ip-addr cmd=get_partition_with_auth : db=yinzhengjie tbl=test3[beijing] 18/06/14 07:40:55 INFO ql.Driver: Starting task [Stage-1:STATS] in serial mode 18/06/14 07:40:55 INFO exec.StatsTask: Executing stats task 18/06/14 07:40:55 INFO metastore.HiveMetaStore: 0: get_table : db=yinzhengjie tbl=test3 18/06/14 07:40:55 INFO HiveMetaStore.audit: ugi=yinzhengjie ip=unknown-ip-addr cmd=get_table : db=yinzhengjie tbl=test3 18/06/14 07:40:55 INFO metastore.HiveMetaStore: 0: get_table : db=yinzhengjie tbl=test3 18/06/14 07:40:55 INFO HiveMetaStore.audit: ugi=yinzhengjie ip=unknown-ip-addr cmd=get_table : db=yinzhengjie tbl=test3 18/06/14 07:40:55 INFO metastore.HiveMetaStore: 0: get_partition_with_auth : db=yinzhengjie tbl=test3[beijing] 18/06/14 07:40:55 INFO HiveMetaStore.audit: ugi=yinzhengjie ip=unknown-ip-addr cmd=get_partition_with_auth : db=yinzhengjie tbl=test3[beijing] 18/06/14 07:40:55 INFO exec.StatsTask: Partition yinzhengjie.test3{province=beijing} stats: [numFiles=2, numRows=0, totalSize=79, rawDataSize=0] 18/06/14 07:40:55 INFO metastore.HiveMetaStore: 0: alter_partitions : db=yinzhengjie tbl=test3 18/06/14 07:40:55 INFO HiveMetaStore.audit: ugi=yinzhengjie ip=unknown-ip-addr cmd=alter_partitions : db=yinzhengjie tbl=test3 18/06/14 07:40:55 INFO metastore.HiveMetaStore: New partition values:[beijing] 18/06/14 07:40:55 WARN hive.log: Updating partition stats fast for: test3 18/06/14 07:40:55 WARN hive.log: Updated size to 79 18/06/14 07:40:55 INFO ql.Driver: Completed executing command(queryId=yinzhengjie_20180614074054_841a2915-844f-45ae-9ad9-431c5179ee48); Time taken: 0.847 seconds OK 18/06/14 07:40:55 INFO ql.Driver: OK Time taken: 1.463 seconds 18/06/14 07:40:55 INFO CliDriver: Time taken: 1.463 seconds 18/06/14 07:40:55 INFO conf.HiveConf: Using the default value passed in for log id: 8c8d3572-c995-4504-8ab4-8e57b757b141 18/06/14 07:40:55 INFO session.SessionState: Resetting thread name to main 18/06/14 07:40:55 INFO conf.HiveConf: Using the default value passed in for log id: 8c8d3572-c995-4504-8ab4-8e57b757b141 18/06/14 07:40:55 INFO session.SessionState: Deleted directory: /tmp/hive/yinzhengjie/8c8d3572-c995-4504-8ab4-8e57b757b141 on fs with scheme hdfs 18/06/14 07:40:55 INFO session.SessionState: Deleted directory: /home/yinzhengjie/yinzhengjie/8c8d3572-c995-4504-8ab4-8e57b757b141 on fs with scheme file 18/06/14 07:40:55 INFO metastore.HiveMetaStore: 0: Cleaning up thread local RawStore... 18/06/14 07:40:55 INFO HiveMetaStore.audit: ugi=yinzhengjie ip=unknown-ip-addr cmd=Cleaning up thread local RawStore... 18/06/14 07:40:55 INFO metastore.HiveMetaStore: 0: Done cleaning up thread local RawStore 18/06/14 07:40:55 INFO HiveMetaStore.audit: ugi=yinzhengjie ip=unknown-ip-addr cmd=Done cleaning up thread local RawStore 18/06/14 07:40:55 INFO hive.HiveImport: Hive import complete. 18/06/14 07:40:55 INFO hive.HiveImport: Export directory is empty, removing it. 18/06/14 07:40:55 INFO tool.ImportTool: Incremental import complete! To run another incremental import of all data following this import, supply the following arguments: 18/06/14 07:40:55 INFO tool.ImportTool: --incremental append 18/06/14 07:40:55 INFO tool.ImportTool: --check-column id 18/06/14 07:40:55 INFO tool.ImportTool: --last-value 5 18/06/14 07:40:55 INFO tool.ImportTool: (Consider saving this with 'sqoop job --create') [yinzhengjie@s101 ~]$ echo $? 0 [yinzhengjie@s101 ~]$
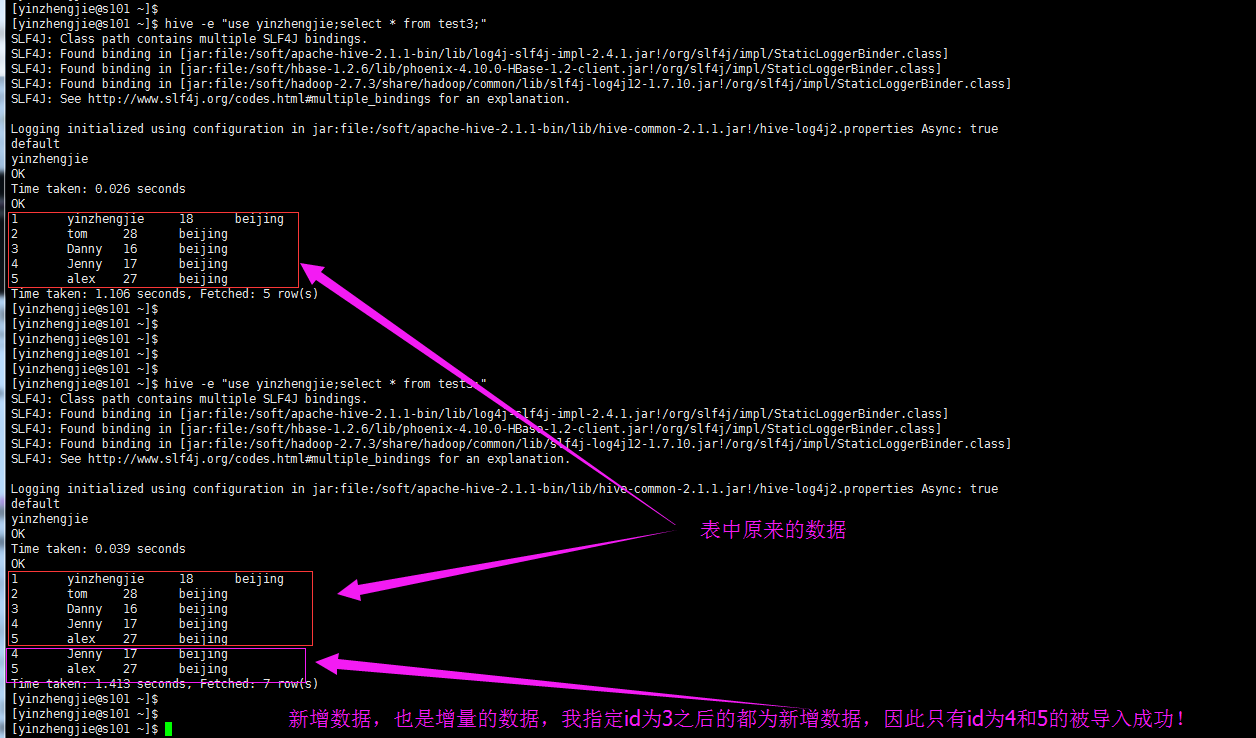
关键参数说明: --incremental append //增量模式,追加(append) --check-column id //检查需要增量导入的指定列,一般采取主键检查,建议将其设置为主键,让其具有唯一性! --last-value 3 //检查增量导入的最终值,以便增量导入,这个3只是一个判断值,如果id是主键,那么3表示id在3之后的都是新增数据
10>.sqoop指定query导入
[yinzhengjie@s101 ~]$ sqoop import --connect jdbc:mysql://s101/yinzhengjie --username root -P --query 'select a.id, a.name, a.age from user a where a.id=1 and $CONDITIONS' --fields-terminated-by ' ' --hive-import --create-hive-table --hive-database yinzhengjie --hive-table test4 --hive-partition-key province --hive-partition-value beijing --target-dir /test4 -m 1 Warning: /soft/sqoop-1.4.7.bin__hadoop-2.6.0/bin/../../hcatalog does not exist! HCatalog jobs will fail. Please set $HCAT_HOME to the root of your HCatalog installation. Warning: /soft/sqoop-1.4.7.bin__hadoop-2.6.0/bin/../../accumulo does not exist! Accumulo imports will fail. Please set $ACCUMULO_HOME to the root of your Accumulo installation. Warning: /soft/sqoop-1.4.7.bin__hadoop-2.6.0/bin/../../zookeeper does not exist! Accumulo imports will fail. Please set $ZOOKEEPER_HOME to the root of your Zookeeper installation. 18/06/14 08:01:12 INFO sqoop.Sqoop: Running Sqoop version: 1.4.7 Enter password: 18/06/14 08:01:16 INFO manager.MySQLManager: Preparing to use a MySQL streaming resultset. 18/06/14 08:01:16 INFO tool.CodeGenTool: Beginning code generation SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/soft/hadoop-2.7.3/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/soft/hbase-1.2.6/lib/phoenix-4.10.0-HBase-1.2-client.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/soft/hbase-1.2.6/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/soft/apache-hive-2.1.1-bin/lib/log4j-slf4j-impl-2.4.1.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory] 18/06/14 08:01:16 INFO manager.SqlManager: Executing SQL statement: select a.id, a.name, a.age from user a where a.id=1 and (1 = 0) 18/06/14 08:01:16 INFO manager.SqlManager: Executing SQL statement: select a.id, a.name, a.age from user a where a.id=1 and (1 = 0) 18/06/14 08:01:16 INFO manager.SqlManager: Executing SQL statement: select a.id, a.name, a.age from user a where a.id=1 and (1 = 0) 18/06/14 08:01:16 INFO orm.CompilationManager: HADOOP_MAPRED_HOME is /soft/hadoop Note: /tmp/sqoop-yinzhengjie/compile/a8130a005528b8613c8aebcdf5f8109f/QueryResult.java uses or overrides a deprecated API. Note: Recompile with -Xlint:deprecation for details. 18/06/14 08:01:19 INFO orm.CompilationManager: Writing jar file: /tmp/sqoop-yinzhengjie/compile/a8130a005528b8613c8aebcdf5f8109f/QueryResult.jar 18/06/14 08:01:19 INFO mapreduce.ImportJobBase: Beginning query import. 18/06/14 08:01:19 INFO Configuration.deprecation: mapred.jar is deprecated. Instead, use mapreduce.job.jar 18/06/14 08:01:20 INFO Configuration.deprecation: mapred.map.tasks is deprecated. Instead, use mapreduce.job.maps 18/06/14 08:01:30 INFO db.DBInputFormat: Using read commited transaction isolation 18/06/14 08:01:31 INFO mapreduce.JobSubmitter: number of splits:1 18/06/14 08:01:32 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1528967628934_0018 18/06/14 08:01:33 INFO impl.YarnClientImpl: Submitted application application_1528967628934_0018 18/06/14 08:01:33 INFO mapreduce.Job: The url to track the job: http://s101:8088/proxy/application_1528967628934_0018/ 18/06/14 08:01:33 INFO mapreduce.Job: Running job: job_1528967628934_0018 18/06/14 08:01:46 INFO mapreduce.Job: Job job_1528967628934_0018 running in uber mode : false 18/06/14 08:01:46 INFO mapreduce.Job: map 0% reduce 0% 18/06/14 08:02:10 INFO mapreduce.Job: map 100% reduce 0% 18/06/14 08:02:11 INFO mapreduce.Job: Job job_1528967628934_0018 completed successfully 18/06/14 08:02:11 INFO mapreduce.Job: Counters: 30 File System Counters FILE: Number of bytes read=0 FILE: Number of bytes written=140213 FILE: Number of read operations=0 FILE: Number of large read operations=0 FILE: Number of write operations=0 HDFS: Number of bytes read=87 HDFS: Number of bytes written=17 HDFS: Number of read operations=4 HDFS: Number of large read operations=0 HDFS: Number of write operations=2 Job Counters Launched map tasks=1 Other local map tasks=1 Total time spent by all maps in occupied slots (ms)=21074 Total time spent by all reduces in occupied slots (ms)=0 Total time spent by all map tasks (ms)=21074 Total vcore-milliseconds taken by all map tasks=21074 Total megabyte-milliseconds taken by all map tasks=21579776 Map-Reduce Framework Map input records=1 Map output records=1 Input split bytes=87 Spilled Records=0 Failed Shuffles=0 Merged Map outputs=0 GC time elapsed (ms)=131 CPU time spent (ms)=1240 Physical memory (bytes) snapshot=91738112 Virtual memory (bytes) snapshot=2086756352 Total committed heap usage (bytes)=18800640 File Input Format Counters Bytes Read=0 File Output Format Counters Bytes Written=17 18/06/14 08:02:11 INFO mapreduce.ImportJobBase: Transferred 17 bytes in 50.7953 seconds (0.3347 bytes/sec) 18/06/14 08:02:11 INFO mapreduce.ImportJobBase: Retrieved 1 records. 18/06/14 08:02:11 INFO mapreduce.ImportJobBase: Publishing Hive/Hcat import job data to Listeners for table null 18/06/14 08:02:11 INFO manager.SqlManager: Executing SQL statement: select a.id, a.name, a.age from user a where a.id=1 and (1 = 0) 18/06/14 08:02:11 INFO manager.SqlManager: Executing SQL statement: select a.id, a.name, a.age from user a where a.id=1 and (1 = 0) 18/06/14 08:02:11 INFO hive.HiveImport: Loading uploaded data into Hive 18/06/14 08:02:11 INFO conf.HiveConf: Found configuration file file:/soft/hive/conf/hive-site.xml Logging initialized using configuration in jar:file:/soft/apache-hive-2.1.1-bin/lib/hive-common-2.1.1.jar!/hive-log4j2.properties Async: true 18/06/14 08:02:14 INFO SessionState: Logging initialized using configuration in jar:file:/soft/apache-hive-2.1.1-bin/lib/hive-common-2.1.1.jar!/hive-log4j2.properties Async: true 18/06/14 08:02:14 INFO metastore.HiveMetaStore: 0: Opening raw store with implementation class:org.apache.hadoop.hive.metastore.ObjectStore 18/06/14 08:02:19 INFO metastore.ObjectStore: ObjectStore, initialize called 18/06/14 08:02:20 INFO DataNucleus.Persistence: Property hive.metastore.integral.jdo.pushdown unknown - will be ignored 18/06/14 08:02:20 INFO DataNucleus.Persistence: Property datanucleus.cache.level2 unknown - will be ignored 18/06/14 08:02:21 INFO metastore.ObjectStore: Setting MetaStore object pin classes with hive.metastore.cache.pinobjtypes="Table,StorageDescriptor,SerDeInfo,Partition,Database,Type,FieldSchema,Order" 18/06/14 08:02:24 INFO metastore.MetaStoreDirectSql: Using direct SQL, underlying DB is MYSQL 18/06/14 08:02:24 INFO metastore.ObjectStore: Initialized ObjectStore 18/06/14 08:02:25 INFO metastore.HiveMetaStore: Added admin role in metastore 18/06/14 08:02:25 INFO metastore.HiveMetaStore: Added public role in metastore 18/06/14 08:02:25 INFO metastore.HiveMetaStore: No user is added in admin role, since config is empty 18/06/14 08:02:25 INFO metastore.HiveMetaStore: 0: get_all_functions 18/06/14 08:02:25 INFO HiveMetaStore.audit: ugi=yinzhengjie ip=unknown-ip-addr cmd=get_all_functions 18/06/14 08:02:25 INFO metadata.Hive: Registering function parsejson cn.org.yinzhengjie.udf.ParseJson 18/06/14 08:02:26 WARN metadata.Hive: Failed to register persistent function parsejson:cn.org.yinzhengjie.udf.ParseJson. Ignore and continue. 18/06/14 08:02:26 INFO metadata.Hive: Registering function parsejson cn.org.yinzhengjie.udf.MyUDTF 18/06/14 08:02:26 WARN metadata.Hive: Failed to register persistent function parsejson:cn.org.yinzhengjie.udf.MyUDTF. Ignore and continue. 18/06/14 08:02:26 INFO metadata.Hive: Registering function todate cn.org.yinzhengjie.udf.MyUDTF 18/06/14 08:02:26 WARN metadata.Hive: Failed to register persistent function todate:cn.org.yinzhengjie.udf.MyUDTF. Ignore and continue. 18/06/14 08:02:26 INFO session.SessionState: Created HDFS directory: /tmp/hive/yinzhengjie/8c662785-93ad-4dec-af7d-43310f284ec4 18/06/14 08:02:26 INFO session.SessionState: Created local directory: /home/yinzhengjie/yinzhengjie/8c662785-93ad-4dec-af7d-43310f284ec4 18/06/14 08:02:26 INFO session.SessionState: Created HDFS directory: /tmp/hive/yinzhengjie/8c662785-93ad-4dec-af7d-43310f284ec4/_tmp_space.db 18/06/14 08:02:26 INFO conf.HiveConf: Using the default value passed in for log id: 8c662785-93ad-4dec-af7d-43310f284ec4 18/06/14 08:02:26 INFO session.SessionState: Updating thread name to 8c662785-93ad-4dec-af7d-43310f284ec4 main 18/06/14 08:02:26 INFO conf.HiveConf: Using the default value passed in for log id: 8c662785-93ad-4dec-af7d-43310f284ec4 18/06/14 08:02:27 INFO ql.Driver: Compiling command(queryId=yinzhengjie_20180614080227_5fcf7963-a968-4249-9976-629da87bb749): show databases 18/06/14 08:02:28 INFO ql.Driver: Semantic Analysis Completed 18/06/14 08:02:28 INFO ql.Driver: Returning Hive schema: Schema(fieldSchemas:[FieldSchema(name:database_name, type:string, comment:from deserializer)], properties:null) 18/06/14 08:02:28 INFO exec.ListSinkOperator: Initializing operator LIST_SINK[0] 18/06/14 08:02:29 INFO ql.Driver: Completed compiling command(queryId=yinzhengjie_20180614080227_5fcf7963-a968-4249-9976-629da87bb749); Time taken: 1.925 seconds 18/06/14 08:02:29 INFO ql.Driver: Concurrency mode is disabled, not creating a lock manager 18/06/14 08:02:29 INFO ql.Driver: Executing command(queryId=yinzhengjie_20180614080227_5fcf7963-a968-4249-9976-629da87bb749): show databases 18/06/14 08:02:29 INFO ql.Driver: Starting task [Stage-0:DDL] in serial mode 18/06/14 08:02:29 INFO metastore.HiveMetaStore: 0: get_all_databases 18/06/14 08:02:29 INFO HiveMetaStore.audit: ugi=yinzhengjie ip=unknown-ip-addr cmd=get_all_databases 18/06/14 08:02:29 INFO exec.DDLTask: results : 2 18/06/14 08:02:29 INFO ql.Driver: Completed executing command(queryId=yinzhengjie_20180614080227_5fcf7963-a968-4249-9976-629da87bb749); Time taken: 0.419 seconds 18/06/14 08:02:29 INFO ql.Driver: OK 18/06/14 08:02:29 INFO Configuration.deprecation: mapred.input.dir is deprecated. Instead, use mapreduce.input.fileinputformat.inputdir 18/06/14 08:02:29 INFO mapred.FileInputFormat: Total input paths to process : 1 default yinzhengjie 18/06/14 08:02:29 INFO CliDriver: Time taken: 2.398 seconds, Fetched: 2 row(s) 18/06/14 08:02:29 INFO conf.HiveConf: Using the default value passed in for log id: 8c662785-93ad-4dec-af7d-43310f284ec4 18/06/14 08:02:29 INFO session.SessionState: Resetting thread name to main 18/06/14 08:02:29 INFO conf.HiveConf: Using the default value passed in for log id: 8c662785-93ad-4dec-af7d-43310f284ec4 18/06/14 08:02:29 INFO session.SessionState: Updating thread name to 8c662785-93ad-4dec-af7d-43310f284ec4 main 18/06/14 08:02:29 INFO ql.Driver: Compiling command(queryId=yinzhengjie_20180614080229_34715c5f-cb4d-414c-a173-594b4dd88248): CREATE TABLE `yinzhengjie`.`test4` ( `id` INT, `name` STRING, `age` INT) COMMENT 'Imported by sqoop on 2018/06/14 08:02:11' PARTITIONED BY (province STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY '�11' LINES TERMINATED BY '�12' STORED AS TEXTFILE 18/06/14 08:02:29 INFO parse.CalcitePlanner: Starting Semantic Analysis 18/06/14 08:02:30 INFO parse.CalcitePlanner: Creating table yinzhengjie.test4 position=13 18/06/14 08:02:30 INFO metastore.HiveMetaStore: 0: get_database: yinzhengjie 18/06/14 08:02:30 INFO HiveMetaStore.audit: ugi=yinzhengjie ip=unknown-ip-addr cmd=get_database: yinzhengjie 18/06/14 08:02:30 INFO sqlstd.SQLStdHiveAccessController: Created SQLStdHiveAccessController for session context : HiveAuthzSessionContext [sessionString=8c662785-93ad-4dec-af7d-43310f284ec4, clientType=HIVECLI] 18/06/14 08:02:30 WARN session.SessionState: METASTORE_FILTER_HOOK will be ignored, since hive.security.authorization.manager is set to instance of HiveAuthorizerFactory. 18/06/14 08:02:30 INFO hive.metastore: Mestastore configuration hive.metastore.filter.hook changed from org.apache.hadoop.hive.metastore.DefaultMetaStoreFilterHookImpl to org.apache.hadoop.hive.ql.security.authorization.plugin.AuthorizationMetaStoreFilterHook 18/06/14 08:02:30 INFO metastore.HiveMetaStore: 0: Cleaning up thread local RawStore... 18/06/14 08:02:30 INFO HiveMetaStore.audit: ugi=yinzhengjie ip=unknown-ip-addr cmd=Cleaning up thread local RawStore... 18/06/14 08:02:30 INFO metastore.HiveMetaStore: 0: Done cleaning up thread local RawStore 18/06/14 08:02:30 INFO HiveMetaStore.audit: ugi=yinzhengjie ip=unknown-ip-addr cmd=Done cleaning up thread local RawStore 18/06/14 08:02:30 INFO ql.Driver: Semantic Analysis Completed 18/06/14 08:02:30 INFO ql.Driver: Returning Hive schema: Schema(fieldSchemas:null, properties:null) 18/06/14 08:02:30 INFO ql.Driver: Completed compiling command(queryId=yinzhengjie_20180614080229_34715c5f-cb4d-414c-a173-594b4dd88248); Time taken: 0.774 seconds 18/06/14 08:02:30 INFO ql.Driver: Concurrency mode is disabled, not creating a lock manager 18/06/14 08:02:30 INFO ql.Driver: Executing command(queryId=yinzhengjie_20180614080229_34715c5f-cb4d-414c-a173-594b4dd88248): CREATE TABLE `yinzhengjie`.`test4` ( `id` INT, `name` STRING, `age` INT) COMMENT 'Imported by sqoop on 2018/06/14 08:02:11' PARTITIONED BY (province STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY '�11' LINES TERMINATED BY '�12' STORED AS TEXTFILE 18/06/14 08:02:30 INFO ql.Driver: Starting task [Stage-0:DDL] in serial mode 18/06/14 08:02:30 INFO exec.DDLTask: creating table yinzhengjie.test4 on null 18/06/14 08:02:30 INFO metastore.HiveMetaStore: 0: create_table: Table(tableName:test4, dbName:yinzhengjie, owner:yinzhengjie, createTime:1528988550, lastAccessTime:0, retention:0, sd:StorageDescriptor(cols:[FieldSchema(name:id, type:int, comment:null), FieldSchema(name:name, type:string, comment:null), FieldSchema(name:age, type:int, comment:null)], location:null, inputFormat:org.apache.hadoop.mapred.TextInputFormat, outputFormat:org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat, compressed:false, numBuckets:-1, serdeInfo:SerDeInfo(name:null, serializationLib:org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe, parameters:{serialization.format= , line.delim= , field.delim= }), bucketCols:[], sortCols:[], parameters:{}, skewedInfo:SkewedInfo(skewedColNames:[], skewedColValues:[], skewedColValueLocationMaps:{}), storedAsSubDirectories:false), partitionKeys:[FieldSchema(name:province, type:string, comment:null)], parameters:{comment=Imported by sqoop on 2018/06/14 08:02:11}, viewOriginalText:null, viewExpandedText:null, tableType:MANAGED_TABLE, privileges:PrincipalPrivilegeSet(userPrivileges:{yinzhengjie=[PrivilegeGrantInfo(privilege:INSERT, createTime:-1, grantor:yinzhengjie, grantorType:USER, grantOption:true), PrivilegeGrantInfo(privilege:SELECT, createTime:-1, grantor:yinzhengjie, grantorType:USER, grantOption:true), PrivilegeGrantInfo(privilege:UPDATE, createTime:-1, grantor:yinzhengjie, grantorType:USER, grantOption:true), PrivilegeGrantInfo(privilege:DELETE, createTime:-1, grantor:yinzhengjie, grantorType:USER, grantOption:true)]}, groupPrivileges:null, rolePrivileges:null), temporary:false) 18/06/14 08:02:30 INFO HiveMetaStore.audit: ugi=yinzhengjie ip=unknown-ip-addr cmd=create_table: Table(tableName:test4, dbName:yinzhengjie, owner:yinzhengjie, createTime:1528988550, lastAccessTime:0, retention:0, sd:StorageDescriptor(cols:[FieldSchema(name:id, type:int, comment:null), FieldSchema(name:name, type:string, comment:null), FieldSchema(name:age, type:int, comment:null)], location:null, inputFormat:org.apache.hadoop.mapred.TextInputFormat, outputFormat:org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat, compressed:false, numBuckets:-1, serdeInfo:SerDeInfo(name:null, serializationLib:org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe, parameters:{serialization.format= , line.delim= , field.delim= }), bucketCols:[], sortCols:[], parameters:{}, skewedInfo:SkewedInfo(skewedColNames:[], skewedColValues:[], skewedColValueLocationMaps:{}), storedAsSubDirectories:false), partitionKeys:[FieldSchema(name:province, type:string, comment:null)], parameters:{comment=Imported by sqoop on 2018/06/14 08:02:11}, viewOriginalText:null, viewExpandedText:null, tableType:MANAGED_TABLE, privileges:PrincipalPrivilegeSet(userPrivileges:{yinzhengjie=[PrivilegeGrantInfo(privilege:INSERT, createTime:-1, grantor:yinzhengjie, grantorType:USER, grantOption:true), PrivilegeGrantInfo(privilege:SELECT, createTime:-1, grantor:yinzhengjie, grantorType:USER, grantOption:true), PrivilegeGrantInfo(privilege:UPDATE, createTime:-1, grantor:yinzhengjie, grantorType:USER, grantOption:true), PrivilegeGrantInfo(privilege:DELETE, createTime:-1, grantor:yinzhengjie, grantorType:USER, grantOption:true)]}, groupPrivileges:null, rolePrivileges:null), temporary:false) 18/06/14 08:02:30 INFO metastore.HiveMetaStore: 0: Opening raw store with implementation class:org.apache.hadoop.hive.metastore.ObjectStore 18/06/14 08:02:30 INFO metastore.ObjectStore: ObjectStore, initialize called 18/06/14 08:02:30 INFO metastore.MetaStoreDirectSql: Using direct SQL, underlying DB is MYSQL 18/06/14 08:02:30 INFO metastore.ObjectStore: Initialized ObjectStore 18/06/14 08:02:30 INFO common.FileUtils: Creating directory if it doesn't exist: hdfs://mycluster/user/hive/warehouse/yinzhengjie.db/test4 18/06/14 08:02:32 INFO metadata.Hive: Dumping metastore api call timing information for : execution phase 18/06/14 08:02:32 INFO metadata.Hive: Total time spent in this metastore function was greater than 1000ms : createTable_(Table, )=1374 18/06/14 08:02:32 INFO ql.Driver: Completed executing command(queryId=yinzhengjie_20180614080229_34715c5f-cb4d-414c-a173-594b4dd88248); Time taken: 1.427 seconds OK 18/06/14 08:02:32 INFO ql.Driver: OK Time taken: 2.202 seconds 18/06/14 08:02:32 INFO CliDriver: Time taken: 2.202 seconds 18/06/14 08:02:32 INFO conf.HiveConf: Using the default value passed in for log id: 8c662785-93ad-4dec-af7d-43310f284ec4 18/06/14 08:02:32 INFO session.SessionState: Resetting thread name to main 18/06/14 08:02:32 INFO conf.HiveConf: Using the default value passed in for log id: 8c662785-93ad-4dec-af7d-43310f284ec4 18/06/14 08:02:32 INFO session.SessionState: Updating thread name to 8c662785-93ad-4dec-af7d-43310f284ec4 main 18/06/14 08:02:32 INFO ql.Driver: Compiling command(queryId=yinzhengjie_20180614080232_c7148c60-e51c-4a5d-85e0-11727ef0e8bc): LOAD DATA INPATH 'hdfs://mycluster/test4' INTO TABLE `yinzhengjie`.`test4` PARTITION (province='beijing') 18/06/14 08:02:32 INFO metastore.HiveMetaStore: 0: get_table : db=yinzhengjie tbl=test4 18/06/14 08:02:32 INFO HiveMetaStore.audit: ugi=yinzhengjie ip=unknown-ip-addr cmd=get_table : db=yinzhengjie tbl=test4 18/06/14 08:02:32 INFO metastore.HiveMetaStore: 0: get_partition_with_auth : db=yinzhengjie tbl=test4[beijing] 18/06/14 08:02:32 INFO HiveMetaStore.audit: ugi=yinzhengjie ip=unknown-ip-addr cmd=get_partition_with_auth : db=yinzhengjie tbl=test4[beijing] 18/06/14 08:02:32 INFO metastore.HiveMetaStore: 0: get_partition_with_auth : db=yinzhengjie tbl=test4[beijing] 18/06/14 08:02:32 INFO HiveMetaStore.audit: ugi=yinzhengjie ip=unknown-ip-addr cmd=get_partition_with_auth : db=yinzhengjie tbl=test4[beijing] 18/06/14 08:02:32 INFO ql.Driver: Semantic Analysis Completed 18/06/14 08:02:32 INFO ql.Driver: Returning Hive schema: Schema(fieldSchemas:null, properties:null) 18/06/14 08:02:32 INFO ql.Driver: Completed compiling command(queryId=yinzhengjie_20180614080232_c7148c60-e51c-4a5d-85e0-11727ef0e8bc); Time taken: 0.813 seconds 18/06/14 08:02:32 INFO ql.Driver: Concurrency mode is disabled, not creating a lock manager 18/06/14 08:02:32 INFO ql.Driver: Executing command(queryId=yinzhengjie_20180614080232_c7148c60-e51c-4a5d-85e0-11727ef0e8bc): LOAD DATA INPATH 'hdfs://mycluster/test4' INTO TABLE `yinzhengjie`.`test4` PARTITION (province='beijing') 18/06/14 08:02:32 INFO ql.Driver: Starting task [Stage-0:MOVE] in serial mode Loading data to table yinzhengjie.test4 partition (province=beijing) 18/06/14 08:02:32 INFO exec.Task: Loading data to table yinzhengjie.test4 partition (province=beijing) from hdfs://mycluster/test4 18/06/14 08:02:32 INFO metastore.HiveMetaStore: 0: get_table : db=yinzhengjie tbl=test4 18/06/14 08:02:32 INFO HiveMetaStore.audit: ugi=yinzhengjie ip=unknown-ip-addr cmd=get_table : db=yinzhengjie tbl=test4 18/06/14 08:02:32 INFO metastore.HiveMetaStore: 0: get_partition_with_auth : db=yinzhengjie tbl=test4[beijing] 18/06/14 08:02:32 INFO HiveMetaStore.audit: ugi=yinzhengjie ip=unknown-ip-addr cmd=get_partition_with_auth : db=yinzhengjie tbl=test4[beijing] 18/06/14 08:02:32 INFO exec.MoveTask: Partition is: {province=beijing} 18/06/14 08:02:32 INFO metastore.HiveMetaStore: 0: partition_name_has_valid_characters 18/06/14 08:02:32 INFO HiveMetaStore.audit: ugi=yinzhengjie ip=unknown-ip-addr cmd=partition_name_has_valid_characters 18/06/14 08:02:32 INFO metastore.HiveMetaStore: 0: get_table : db=yinzhengjie tbl=test4 18/06/14 08:02:32 INFO HiveMetaStore.audit: ugi=yinzhengjie ip=unknown-ip-addr cmd=get_table : db=yinzhengjie tbl=test4 18/06/14 08:02:32 INFO metastore.HiveMetaStore: 0: get_partition_with_auth : db=yinzhengjie tbl=test4[beijing] 18/06/14 08:02:32 INFO HiveMetaStore.audit: ugi=yinzhengjie ip=unknown-ip-addr cmd=get_partition_with_auth : db=yinzhengjie tbl=test4[beijing] 18/06/14 08:02:32 INFO common.FileUtils: Creating directory if it doesn't exist: hdfs://mycluster/user/hive/warehouse/yinzhengjie.db/test4/province=beijing 18/06/14 08:02:33 ERROR hdfs.KeyProviderCache: Could not find uri with key [dfs.encryption.key.provider.uri] to create a keyProvider !! 18/06/14 08:02:33 INFO metastore.HiveMetaStore: 0: add_partition : db=yinzhengjie tbl=test4 18/06/14 08:02:33 INFO HiveMetaStore.audit: ugi=yinzhengjie ip=unknown-ip-addr cmd=add_partition : db=yinzhengjie tbl=test4 18/06/14 08:02:33 INFO metastore.HiveMetaStore: 0: get_partition_with_auth : db=yinzhengjie tbl=test4[beijing] 18/06/14 08:02:33 INFO HiveMetaStore.audit: ugi=yinzhengjie ip=unknown-ip-addr cmd=get_partition_with_auth : db=yinzhengjie tbl=test4[beijing] 18/06/14 08:02:33 INFO ql.Driver: Starting task [Stage-1:STATS] in serial mode 18/06/14 08:02:33 INFO exec.StatsTask: Executing stats task 18/06/14 08:02:33 INFO metastore.HiveMetaStore: 0: get_table : db=yinzhengjie tbl=test4 18/06/14 08:02:33 INFO HiveMetaStore.audit: ugi=yinzhengjie ip=unknown-ip-addr cmd=get_table : db=yinzhengjie tbl=test4 18/06/14 08:02:33 INFO metastore.HiveMetaStore: 0: get_table : db=yinzhengjie tbl=test4 18/06/14 08:02:33 INFO HiveMetaStore.audit: ugi=yinzhengjie ip=unknown-ip-addr cmd=get_table : db=yinzhengjie tbl=test4 18/06/14 08:02:33 INFO metastore.HiveMetaStore: 0: get_partition_with_auth : db=yinzhengjie tbl=test4[beijing] 18/06/14 08:02:33 INFO HiveMetaStore.audit: ugi=yinzhengjie ip=unknown-ip-addr cmd=get_partition_with_auth : db=yinzhengjie tbl=test4[beijing] 18/06/14 08:02:33 INFO exec.StatsTask: Partition yinzhengjie.test4{province=beijing} stats: [numFiles=1, numRows=0, totalSize=17, rawDataSize=0] 18/06/14 08:02:33 INFO metastore.HiveMetaStore: 0: alter_partitions : db=yinzhengjie tbl=test4 18/06/14 08:02:33 INFO HiveMetaStore.audit: ugi=yinzhengjie ip=unknown-ip-addr cmd=alter_partitions : db=yinzhengjie tbl=test4 18/06/14 08:02:33 INFO metastore.HiveMetaStore: New partition values:[beijing] 18/06/14 08:02:33 INFO ql.Driver: Completed executing command(queryId=yinzhengjie_20180614080232_c7148c60-e51c-4a5d-85e0-11727ef0e8bc); Time taken: 0.886 seconds OK 18/06/14 08:02:33 INFO ql.Driver: OK Time taken: 1.701 seconds 18/06/14 08:02:33 INFO CliDriver: Time taken: 1.701 seconds 18/06/14 08:02:33 INFO conf.HiveConf: Using the default value passed in for log id: 8c662785-93ad-4dec-af7d-43310f284ec4 18/06/14 08:02:33 INFO session.SessionState: Resetting thread name to main 18/06/14 08:02:33 INFO conf.HiveConf: Using the default value passed in for log id: 8c662785-93ad-4dec-af7d-43310f284ec4 18/06/14 08:02:33 INFO session.SessionState: Deleted directory: /tmp/hive/yinzhengjie/8c662785-93ad-4dec-af7d-43310f284ec4 on fs with scheme hdfs 18/06/14 08:02:33 INFO session.SessionState: Deleted directory: /home/yinzhengjie/yinzhengjie/8c662785-93ad-4dec-af7d-43310f284ec4 on fs with scheme file 18/06/14 08:02:33 INFO metastore.HiveMetaStore: 0: Cleaning up thread local RawStore... 18/06/14 08:02:33 INFO HiveMetaStore.audit: ugi=yinzhengjie ip=unknown-ip-addr cmd=Cleaning up thread local RawStore... 18/06/14 08:02:33 INFO metastore.HiveMetaStore: 0: Done cleaning up thread local RawStore 18/06/14 08:02:33 INFO HiveMetaStore.audit: ugi=yinzhengjie ip=unknown-ip-addr cmd=Done cleaning up thread local RawStore 18/06/14 08:02:33 INFO hive.HiveImport: Hive import complete. [yinzhengjie@s101 ~]$ echo $? 0 [yinzhengjie@s101 ~]$
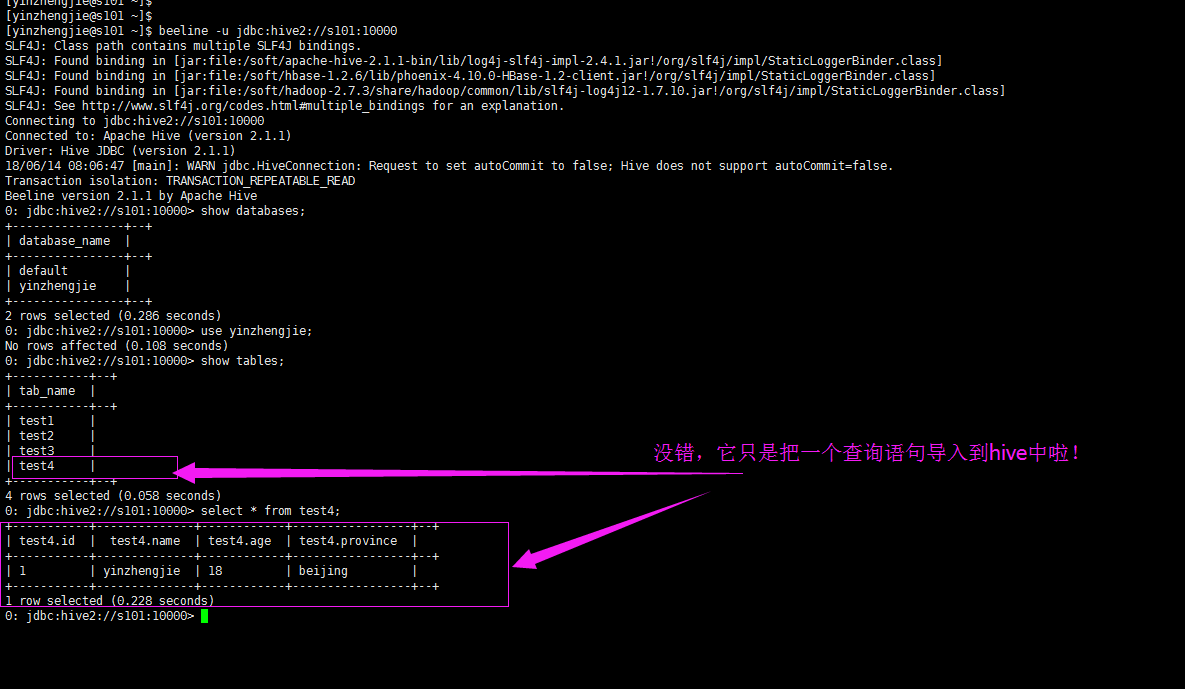
注意: 1>.在查询语句中需要使用单引号'', 查询语句末尾添加 where $CONDITIONS 2>.--targrt-dir //指定mr中产生的中间数据,此数据会被load到hive表中
五.sqoop导入mysql数据到hbase(需要启动hdfs,yarn,MySQL,HBase等相关服务)
1>.导入数据到HBase
[yinzhengjie@s101 ~]$ hbase shell SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/soft/hbase-1.2.6/lib/phoenix-4.10.0-HBase-1.2-client.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/soft/hbase-1.2.6/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/soft/hadoop-2.7.3/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/soft/apache-hive-2.1.1-bin/lib/log4j-slf4j-impl-2.4.1.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. HBase Shell; enter 'help<RETURN>' for list of supported commands. Type "exit<RETURN>" to leave the HBase Shell Version 1.2.6, rUnknown, Mon May 29 02:25:32 CDT 2017 hbase(main):001:0> list TABLE SYSTEM.CATALOG SYSTEM.FUNCTION SYSTEM.MUTEX SYSTEM.SEQUENCE SYSTEM.STATS YINZHENGJIE.T1 ns1:calllog ns1:observer ns1:t1 yinzhengjie:WordCount yinzhengjie:WordCount2 yinzhengjie:WordCount3 yinzhengjie:t1 yinzhengjie:test 14 row(s) in 0.3720 seconds => ["SYSTEM.CATALOG", "SYSTEM.FUNCTION", "SYSTEM.MUTEX", "SYSTEM.SEQUENCE", "SYSTEM.STATS", "YINZHENGJIE.T1", "ns1:calllog", "ns1:observer", "ns1:t1", "yinzhengjie:WordCount", "yinzhengjie:WordCount2", "yinzhengjie:WordCount3", "yinzhengjie:t1", "yinzhengjie:test"] hbase(main):002:0>
[yinzhengjie@s101 ~]$ sqoop import --connect jdbc:mysql://s101/yinzhengjie --username root -P --table word --hbase-create-table --hbase-table yinzhengjie:wc --hbase-row-key id --column-family f1 -m 1 Warning: /soft/sqoop-1.4.7.bin__hadoop-2.6.0/bin/../../hcatalog does not exist! HCatalog jobs will fail. Please set $HCAT_HOME to the root of your HCatalog installation. Warning: /soft/sqoop-1.4.7.bin__hadoop-2.6.0/bin/../../accumulo does not exist! Accumulo imports will fail. Please set $ACCUMULO_HOME to the root of your Accumulo installation. Warning: /soft/sqoop-1.4.7.bin__hadoop-2.6.0/bin/../../zookeeper does not exist! Accumulo imports will fail. Please set $ZOOKEEPER_HOME to the root of your Zookeeper installation. 18/06/14 03:49:06 INFO sqoop.Sqoop: Running Sqoop version: 1.4.7 Enter password: 18/06/14 03:49:09 INFO manager.MySQLManager: Preparing to use a MySQL streaming resultset. 18/06/14 03:49:09 INFO tool.CodeGenTool: Beginning code generation SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/soft/hadoop-2.7.3/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/soft/hbase-1.2.6/lib/phoenix-4.10.0-HBase-1.2-client.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/soft/hbase-1.2.6/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/soft/apache-hive-2.1.1-bin/lib/log4j-slf4j-impl-2.4.1.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory] 18/06/14 03:49:10 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `word` AS t LIMIT 1 18/06/14 03:49:10 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `word` AS t LIMIT 1 18/06/14 03:49:10 INFO orm.CompilationManager: HADOOP_MAPRED_HOME is /soft/hadoop Note: /tmp/sqoop-yinzhengjie/compile/b502c5c084cf744b05c1dfec13590b2c/word.java uses or overrides a deprecated API. Note: Recompile with -Xlint:deprecation for details. 18/06/14 03:49:11 INFO orm.CompilationManager: Writing jar file: /tmp/sqoop-yinzhengjie/compile/b502c5c084cf744b05c1dfec13590b2c/word.jar 18/06/14 03:49:11 WARN manager.MySQLManager: It looks like you are importing from mysql. 18/06/14 03:49:11 WARN manager.MySQLManager: This transfer can be faster! Use the --direct 18/06/14 03:49:11 WARN manager.MySQLManager: option to exercise a MySQL-specific fast path. 18/06/14 03:49:11 INFO manager.MySQLManager: Setting zero DATETIME behavior to convertToNull (mysql) 18/06/14 03:49:11 INFO mapreduce.ImportJobBase: Beginning import of word 18/06/14 03:49:12 INFO Configuration.deprecation: mapred.jar is deprecated. Instead, use mapreduce.job.jar 18/06/14 03:49:12 INFO Configuration.deprecation: mapred.map.tasks is deprecated. Instead, use mapreduce.job.maps 18/06/14 03:49:12 INFO zookeeper.RecoverableZooKeeper: Process identifier=hconnection-0x3c782d8e connecting to ZooKeeper ensemble=s102:2181,s103:2181,s104:2181 18/06/14 03:49:12 INFO zookeeper.ZooKeeper: Client environment:zookeeper.version=3.4.6-1569965, built on 02/20/2014 09:09 GMT 18/06/14 03:49:12 INFO zookeeper.ZooKeeper: Client environment:host.name=s101 18/06/14 03:49:12 INFO zookeeper.ZooKeeper: Client environment:java.version=1.8.0_131 18/06/14 03:49:12 INFO zookeeper.ZooKeeper: Client environment:java.vendor=Oracle Corporation 18/06/14 03:49:12 INFO zookeeper.ZooKeeper: Client environment:java.home=/soft/jdk1.8.0_131/jre 18/06/14 03:49:12 INFO zookeeper.ZooKeeper: Client environment:java.class.path=/soft/hadoop-2.7.3/etc/hadoop:/soft/hadoop/share/hadoop/common/lib/jaxb-impl-2.2.3-1.jar:/soft/hadoop/share/hadoop/common/lib/jaxb-api-2.2.2.jar:/soft/hadoop/share/hadoop/common/lib/stax-api-1.0-2.jar:/soft/hadoop/share/hadoop/common/lib/activation-1.1.jar:/soft/hadoop/share/hadoop/common/lib/jackson-core-asl-1.9.13.jar:/soft/hadoop/share/hadoop/common/lib/jackson-mapper-asl-1.9.13.jar:/soft/hadoop/share/hadoop/common/lib/jackson-jaxrs-1.9.13.jar:/soft/hadoop/share/hadoop/common/lib/jackson-xc-1.9.13.jar:/soft/hadoop/share/hadoop/common/lib/jersey-server-1.9.jar:/soft/hadoop/share/hadoop/common/lib/asm-3.2.jar:/soft/hadoop/share/hadoop/common/lib/log4j-1.2.17.jar:/soft/hadoop/share/hadoop/common/lib/jets3t-0.9.0.jar:/soft/hadoop/share/hadoop/common/lib/httpclient-4.2.5.jar:/soft/hadoop/share/hadoop/common/lib/httpcore-4.2.5.jar:/soft/hadoop/share/hadoop/common/lib/java-xmlbuilder-0.4.jar:/soft/hadoop/share/hadoop/common/lib/commons-lang-2.6.jar:/soft/hadoop/share/hadoop/common/lib/commons-configuration-1.6.jar:/soft/hadoop/share/hadoop/common/lib/commons-digester-1.8.jar:/soft/hadoop/share/hadoop/common/lib/commons-beanutils-1.7.0.jar:/soft/hadoop/share/hadoop/common/lib/commons-beanutils-core-1.8.0.jar:/soft/hadoop/share/hadoop/common/lib/slf4j-api-1.7.10.jar:/soft/hadoop/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar:/soft/hadoop/share/hadoop/common/lib/avro-1.7.4.jar:/soft/hadoop/share/hadoop/common/lib/paranamer-2.3.jar:/soft/hadoop/share/hadoop/common/lib/snappy-java-1.0.4.1.jar:/soft/hadoop/share/hadoop/common/lib/commons-compress-1.4.1.jar:/soft/hadoop/share/hadoop/common/lib/xz-1.0.jar:/soft/hadoop/share/hadoop/common/lib/protobuf-java-2.5.0.jar:/soft/hadoop/share/hadoop/common/lib/gson-2.2.4.jar:/soft/hadoop/share/hadoop/common/lib/hadoop-auth-2.7.3.jar:/soft/hadoop/share/hadoop/common/lib/apacheds-kerberos-codec-2.0.0-M15.jar:/soft/hadoop/share/hadoop/common/lib/apacheds-i18n-2.0.0-M15.jar:/soft/hadoop/share/hadoop/common/lib/api-asn1-api-1.0.0-M20.jar:/soft/hadoop/share/hadoop/common/lib/api-util-1.0.0-M20.jar:/soft/hadoop/share/hadoop/common/lib/zookeeper-3.4.6.jar:/soft/hadoop/share/hadoop/common/lib/netty-3.6.2.Final.jar:/soft/hadoop/share/hadoop/common/lib/curator-framework-2.7.1.jar:/soft/hadoop/share/hadoop/common/lib/curator-client-2.7.1.jar:/soft/hadoop/share/hadoop/common/lib/jsch-0.1.42.jar:/soft/hadoop/share/hadoop/common/lib/curator-recipes-2.7.1.jar:/soft/hadoop/share/hadoop/common/lib/htrace-core-3.1.0-incubating.jar:/soft/hadoop/share/hadoop/common/lib/junit-4.11.jar:/soft/hadoop/share/hadoop/common/lib/hamcrest-core-1.3.jar:/soft/hadoop/share/hadoop/common/lib/mockito-all-1.8.5.jar:/soft/hadoop/share/hadoop/common/lib/hadoop-annotations-2.7.3.jar:/soft/hadoop/share/hadoop/common/lib/guava-11.0.2.jar:/soft/hadoop/share/hadoop/common/lib/jsr305-3.0.0.jar:/soft/hadoop/share/hadoop/common/lib/commons-cli-1.2.jar:/soft/hadoop/share/hadoop/common/lib/commons-math3-3.1.1.jar:/soft/hadoop/share/hadoop/common/lib/xmlenc-0.52.jar:/soft/hadoop/share/hadoop/common/lib/commons-httpclient-3.1.jar:/soft/hadoop/share/hadoop/common/lib/commons-logging-1.1.3.jar:/soft/hadoop/share/hadoop/common/lib/commons-codec-1.4.jar:/soft/hadoop/share/hadoop/common/lib/commons-io-2.4.jar:/soft/hadoop/share/hadoop/common/lib/commons-net-3.1.jar:/soft/hadoop/share/hadoop/common/lib/commons-collections-3.2.2.jar:/soft/hadoop/share/hadoop/common/lib/servlet-api-2.5.jar:/soft/hadoop/share/hadoop/common/lib/jetty-6.1.26.jar:/soft/hadoop/share/hadoop/common/lib/jetty-util-6.1.26.jar:/soft/hadoop/share/hadoop/common/lib/jsp-api-2.1.jar:/soft/hadoop/share/hadoop/common/lib/jersey-core-1.9.jar:/soft/hadoop/share/hadoop/common/lib/jersey-json-1.9.jar:/soft/hadoop/share/hadoop/common/lib/jettison-1.1.jar:/soft/hadoop/share/hadoop/common/lib/lzo-core-1.0.0.jar:/soft/hadoop/share/hadoop/common/lib/lzo-hadoop-1.0.0.jar:/soft/hadoop/share/hadoop/common/lib/fastjson-1.2.47.jar:/soft/hadoop/share/hadoop/common/lib/MyHbase-1.0-SNAPSHOT.jar:/soft/hadoop/share/hadoop/common/hadoop-common-2.7.3.jar:/soft/hadoop/share/hadoop/common/hadoop-common-2.7.3-tests.jar:/soft/hadoop/share/hadoop/common/hadoop-nfs-2.7.3.jar:/soft/hadoop-2.7.3/share/hadoop/hdfs:/soft/hadoop-2.7.3/share/hadoop/hdfs/lib/commons-codec-1.4.jar:/soft/hadoop-2.7.3/share/hadoop/hdfs/lib/log4j-1.2.17.jar:/soft/hadoop-2.7.3/share/hadoop/hdfs/lib/commons-logging-1.1.3.jar:/soft/hadoop-2.7.3/share/hadoop/hdfs/lib/netty-3.6.2.Final.jar:/soft/hadoop-2.7.3/share/hadoop/hdfs/lib/guava-11.0.2.jar:/soft/hadoop-2.7.3/share/hadoop/hdfs/lib/jsr305-3.0.0.jar:/soft/hadoop-2.7.3/share/hadoop/hdfs/lib/commons-cli-1.2.jar:/soft/hadoop-2.7.3/share/hadoop/hdfs/lib/xmlenc-0.52.jar:/soft/hadoop-2.7.3/share/hadoop/hdfs/lib/commons-io-2.4.jar:/soft/hadoop-2.7.3/share/hadoop/hdfs/lib/servlet-api-2.5.jar:/soft/hadoop-2.7.3/share/hadoop/hdfs/lib/jetty-6.1.26.jar:/soft/hadoop-2.7.3/share/hadoop/hdfs/lib/jetty-util-6.1.26.jar:/soft/hadoop-2.7.3/share/hadoop/hdfs/lib/jersey-core-1.9.jar:/soft/hadoop-2.7.3/share/hadoop/hdfs/lib/jackson-core-asl-1.9.13.jar:/soft/hadoop-2.7.3/share/hadoop/hdfs/lib/jackson-mapper-asl-1.9.13.jar:/soft/hadoop-2.7.3/share/hadoop/hdfs/lib/jersey-server-1.9.jar:/soft/hadoop-2.7.3/share/hadoop/hdfs/lib/asm-3.2.jar:/soft/hadoop-2.7.3/share/hadoop/hdfs/lib/commons-lang-2.6.jar:/soft/hadoop-2.7.3/share/hadoop/hdfs/lib/protobuf-java-2.5.0.jar:/soft/hadoop-2.7.3/share/hadoop/hdfs/lib/htrace-core-3.1.0-incubating.jar:/soft/hadoop-2.7.3/share/hadoop/hdfs/lib/commons-daemon-1.0.13.jar:/soft/hadoop-2.7.3/share/hadoop/hdfs/lib/netty-all-4.0.23.Final.jar:/soft/hadoop-2.7.3/share/hadoop/hdfs/lib/xercesImpl-2.9.1.jar:/soft/hadoop-2.7.3/share/hadoop/hdfs/lib/xml-apis-1.3.04.jar:/soft/hadoop-2.7.3/share/hadoop/hdfs/lib/leveldbjni-all-1.8.jar:/soft/hadoop-2.7.3/share/hadoop/hdfs/hadoop-hdfs-2.7.3.jar:/soft/hadoop-2.7.3/share/hadoop/hdfs/hadoop-hdfs-2.7.3-tests.jar:/soft/hadoop-2.7.3/share/hadoop/hdfs/hadoop-hdfs-nfs-2.7.3.jar:/soft/hadoop-2.7.3/share/hadoop/yarn/lib/zookeeper-3.4.6-tests.jar:/soft/hadoop-2.7.3/share/hadoop/yarn/lib/commons-lang-2.6.jar:/soft/hadoop-2.7.3/share/hadoop/yarn/lib/guava-11.0.2.jar:/soft/hadoop-2.7.3/share/hadoop/yarn/lib/jsr305-3.0.0.jar:/soft/hadoop-2.7.3/share/hadoop/yarn/lib/commons-logging-1.1.3.jar:/soft/hadoop-2.7.3/share/hadoop/yarn/lib/protobuf-java-2.5.0.jar:/soft/hadoop-2.7.3/share/hadoop/yarn/lib/commons-cli-1.2.jar:/soft/hadoop-2.7.3/share/hadoop/yarn/lib/log4j-1.2.17.jar:/soft/hadoop-2.7.3/share/hadoop/yarn/lib/jaxb-api-2.2.2.jar:/soft/hadoop-2.7.3/share/hadoop/yarn/lib/stax-api-1.0-2.jar:/soft/hadoop-2.7.3/share/hadoop/yarn/lib/activation-1.1.jar:/soft/hadoop-2.7.3/share/hadoop/yarn/lib/commons-compress-1.4.1.jar:/soft/hadoop-2.7.3/share/hadoop/yarn/lib/xz-1.0.jar:/soft/hadoop-2.7.3/share/hadoop/yarn/lib/servlet-api-2.5.jar:/soft/hadoop-2.7.3/share/hadoop/yarn/lib/commons-codec-1.4.jar:/soft/hadoop-2.7.3/share/hadoop/yarn/lib/jetty-util-6.1.26.jar:/soft/hadoop-2.7.3/share/hadoop/yarn/lib/jersey-core-1.9.jar:/soft/hadoop-2.7.3/share/hadoop/yarn/lib/jersey-client-1.9.jar:/soft/hadoop-2.7.3/share/hadoop/yarn/lib/jackson-core-asl-1.9.13.jar:/soft/hadoop-2.7.3/share/hadoop/yarn/lib/jackson-mapper-asl-1.9.13.jar:/soft/hadoop-2.7.3/share/hadoop/yarn/lib/jackson-jaxrs-1.9.13.jar:/soft/hadoop-2.7.3/share/hadoop/yarn/lib/jackson-xc-1.9.13.jar:/soft/hadoop-2.7.3/share/hadoop/yarn/lib/guice-servlet-3.0.jar:/soft/hadoop-2.7.3/share/hadoop/yarn/lib/guice-3.0.jar:/soft/hadoop-2.7.3/share/hadoop/yarn/lib/javax.inject-1.jar:/soft/hadoop-2.7.3/share/hadoop/yarn/lib/aopalliance-1.0.jar:/soft/hadoop-2.7.3/share/hadoop/yarn/lib/commons-io-2.4.jar:/soft/hadoop-2.7.3/share/hadoop/yarn/lib/jersey-server-1.9.jar:/soft/hadoop-2.7.3/share/hadoop/yarn/lib/asm-3.2.jar:/soft/hadoop-2.7.3/share/hadoop/yarn/lib/jersey-json-1.9.jar:/soft/hadoop-2.7.3/share/hadoop/yarn/lib/jettison-1.1.jar:/soft/hadoop-2.7.3/share/hadoop/yarn/lib/jaxb-impl-2.2.3-1.jar:/soft/hadoop-2.7.3/share/hadoop/yarn/lib/jersey-guice-1.9.jar:/soft/hadoop-2.7.3/share/hadoop/yarn/lib/zookeeper-3.4.6.jar:/soft/hadoop-2.7.3/share/hadoop/yarn/lib/netty-3.6.2.Final.jar:/soft/hadoop-2.7.3/share/hadoop/yarn/lib/leveldbjni-all-1.8.jar:/soft/hadoop-2.7.3/share/hadoop/yarn/lib/commons-collections-3.2.2.jar:/soft/hadoop-2.7.3/share/hadoop/yarn/lib/jetty-6.1.26.jar:/soft/hadoop-2.7.3/share/hadoop/yarn/hadoop-yarn-api-2.7.3.jar:/soft/hadoop-2.7.3/share/hadoop/yarn/hadoop-yarn-common-2.7.3.jar:/soft/hadoop-2.7.3/share/hadoop/yarn/hadoop-yarn-server-common-2.7.3.jar:/soft/hadoop-2.7.3/share/hadoop/yarn/hadoop-yarn-server-nodemanager-2.7.3.jar:/soft/hadoop-2.7.3/share/hadoop/yarn/hadoop-yarn-server-web-proxy-2.7.3.jar:/soft/hadoop-2.7.3/share/hadoop/yarn/hadoop-yarn-server-applicationhistoryservice-2.7.3.jar:/soft/hadoop-2.7.3/share/hadoop/yarn/hadoop-yarn-server-resourcemanager-2.7.3.jar:/soft/hadoop-2.7.3/share/hadoop/yarn/hadoop-yarn-server-tests-2.7.3.jar:/soft/hadoop-2.7.3/share/hadoop/yarn/hadoop-yarn-client-2.7.3.jar:/soft/hadoop-2.7.3/share/hadoop/yarn/hadoop-yarn-server-sharedcachemanager-2.7.3.jar:/soft/hadoop-2.7.3/share/hadoop/yarn/hadoop-yarn-applications-distributedshell-2.7.3.jar:/soft/hadoop-2.7.3/share/hadoop/yarn/hadoop-yarn-applications-unmanaged-am-launcher-2.7.3.jar:/soft/hadoop-2.7.3/share/hadoop/yarn/hadoop-yarn-registry-2.7.3.jar:/soft/hadoop/share/hadoop/mapreduce/lib/protobuf-java-2.5.0.jar:/soft/hadoop/share/hadoop/mapreduce/lib/avro-1.7.4.jar:/soft/hadoop/share/hadoop/mapreduce/lib/jackson-core-asl-1.9.13.jar:/soft/hadoop/share/hadoop/mapreduce/lib/jackson-mapper-asl-1.9.13.jar:/soft/hadoop/share/hadoop/mapreduce/lib/paranamer-2.3.jar:/soft/hadoop/share/hadoop/mapreduce/lib/snappy-java-1.0.4.1.jar:/soft/hadoop/share/hadoop/mapreduce/lib/commons-compress-1.4.1.jar:/soft/hadoop/share/hadoop/mapreduce/lib/xz-1.0.jar:/soft/hadoop/share/hadoop/mapreduce/lib/hadoop-annotations-2.7.3.jar:/soft/hadoop/share/hadoop/mapreduce/lib/commons-io-2.4.jar:/soft/hadoop/share/hadoop/mapreduce/lib/jersey-core-1.9.jar:/soft/hadoop/share/hadoop/mapreduce/lib/jersey-server-1.9.jar:/soft/hadoop/share/hadoop/mapreduce/lib/asm-3.2.jar:/soft/hadoop/share/hadoop/mapreduce/lib/log4j-1.2.17.jar:/soft/hadoop/share/hadoop/mapreduce/lib/netty-3.6.2.Final.jar:/soft/hadoop/share/hadoop/mapreduce/lib/leveldbjni-all-1.8.jar:/soft/hadoop/share/hadoop/mapreduce/lib/guice-3.0.jar:/soft/hadoop/share/hadoop/mapreduce/lib/javax.inject-1.jar:/soft/hadoop/share/hadoop/mapreduce/lib/aopalliance-1.0.jar:/soft/hadoop/share/hadoop/mapreduce/lib/jersey-guice-1.9.jar:/soft/hadoop/share/hadoop/mapreduce/lib/guice-servlet-3.0.jar:/soft/hadoop/share/hadoop/mapreduce/lib/junit-4.11.jar:/soft/hadoop/share/hadoop/mapreduce/lib/hamcrest-core-1.3.jar:/soft/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-client-core-2.7.3.jar:/soft/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-client-common-2.7.3.jar:/soft/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-client-shuffle-2.7.3.jar:/soft/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-client-app-2.7.3.jar:/soft/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-client-hs-2.7.3.jar:/soft/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-2.7.3.jar:/soft/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-client-hs-plugins-2.7.3.jar:/soft/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar:/soft/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-2.7.3-tests.jar:/soft/sqoop-1.4.7.bin__hadoop-2.6.0/bin/../conf:/soft/zk/conf::/soft/sqoop-1.4.7.bin__hadoop-2.6.0/bin/../lib/ant-contrib-1.0b3.jar:/soft/sqoop-1.4.7.bin__hadoop-2.6.0/bin/../lib/ant-eclipse-1.0-jvm1.2.jar:/soft/sqoop-1.4.7.bin__hadoop-2.6.0/bin/../lib/avro-1.8.1.jar:/soft/sqoop-1.4.7.bin__hadoop-2.6.0/bin/../lib/avro-mapred-1.8.1-hadoop2.jar:/soft/sqoop-1.4.7.bin__hadoop-2.6.0/bin/../lib/commons-codec-1.4.jar:/soft/sqoop-1.4.7.bin__hadoop-2.6.0/bin/../lib/commons-compress-1.8.1.jar:/soft/sqoop-1.4.7.bin__hadoop-2.6.0/bin/../lib/commons-io-1.4.jar:/soft/sqoop-1.4.7.bin__hadoop-2.6.0/bin/../lib/commons-jexl-2.1.1.jar:/soft/sqoop-1.4.7.bin__hadoop-2.6.0/bin/../lib/commons-lang3-3.4.jar:/soft/sqoop-1.4.7.bin__hadoop-2.6.0/bin/../lib/commons-logging-1.1.1.jar:/soft/sqoop-1.4.7.bin__hadoop-2.6.0/bin/../lib/hsqldb-1.8.0.10.jar:/soft/sqoop-1.4.7.bin__hadoop-2.6.0/bin/../lib/jackson-annotations-2.3.1.jar:/soft/sqoop-1.4.7.bin__hadoop-2.6.0/bin/../lib/jackson-core-2.3.1.jar:/soft/sqoop-1.4.7.bin__hadoop-2.6.0/bin/../lib/jackson-core-asl-1.9.13.jar:/soft/sqoop-1.4.7.bin__hadoop-2.6.0/bin/../lib/jackson-databind-2.3.1.jar:/soft/sqoop-1.4.7.bin__hadoop-2.6.0/bin/../lib/jackson-mapper-asl-1.9.13.jar:/soft/sqoop-1.4.7.bin__hadoop-2.6.0/bin/../lib/kite-data-core-1.1.0.jar:/soft/sqoop-1.4.7.bin__hadoop-2.6.0/bin/../lib/kite-data-hive-1.1.0.jar:/soft/sqoop-1.4.7.bin__hadoop-2.6.0/bin/../lib/kite-data-mapreduce-1.1.0.jar:/soft/sqoop-1.4.7.bin__hadoop-2.6.0/bin/../lib/kite-hadoop-compatibility-1.1.0.jar:/soft/sqoop-1.4.7.bin__hadoop-2.6.0/bin/../lib/mysql-connector-java-5.1.41.jar:/soft/sqoop-1.4.7.bin__hadoop-2.6.0/bin/../lib/opencsv-2.3.jar:/soft/sqoop-1.4.7.bin__hadoop-2.6.0/bin/../lib/paranamer-2.7.jar:/soft/sqoop-1.4.7.bin__hadoop-2.6.0/bin/../lib/parquet-avro-1.6.0.jar:/soft/sqoop-1.4.7.bin__hadoop-2.6.0/bin/../lib/parquet-column-1.6.0.jar:/soft/sqoop-1.4.7.bin__hadoop-2.6.0/bin/../lib/parquet-common-1.6.0.jar:/soft/sqoop-1.4.7.bin__hadoop-2.6.0/bin/../lib/parquet-encoding-1.6.0.jar:/soft/sqoop-1.4.7.bin__hadoop-2.6.0/bin/../lib/parquet-format-2.2.0-rc1.jar:/soft/sqoop-1.4.7.bin__hadoop-2.6.0/bin/../lib/parquet-generator-1.6.0.jar:/soft/sqoop-1.4.7.bin__hadoop-2.6.0/bin/../lib/parquet-hadoop-1.6.0.jar:/soft/sqoop-1.4.7.bin__hadoop-2.6.0/bin/../lib/parquet-jackson-1.6.0.jar:/soft/sqoop-1.4.7.bin__hadoop-2.6.0/bin/../lib/slf4j-api-1.6.1.jar:/soft/sqoop-1.4.7.bin__hadoop-2.6.0/bin/../lib/snappy-java-1.1.1.6.jar:/soft/sqoop-1.4.7.bin__hadoop-2.6.0/bin/../lib/xz-1.5.jar:/soft/hbase/conf:/soft/jdk//lib/tools.jar:/soft/hbase:/soft/hbase/lib/activation-1.1.jar:/soft/hbase/lib/aopalliance-1.0.jar:/soft/hbase/lib/apacheds-i18n-2.0.0-M15.jar:/soft/hbase/lib/apacheds-kerberos-codec-2.0.0-M15.jar:/soft/hbase/lib/api-asn1-api-1.0.0-M20.jar:/soft/hbase/lib/api-util-1.0.0-M20.jar:/soft/hbase/lib/asm-3.1.jar:/soft/hbase/lib/avro-1.7.4.jar:/soft/hbase/lib/commons-beanutils-1.7.0.jar:/soft/hbase/lib/commons-beanutils-core-1.8.0.jar:/soft/hbase/lib/commons-cli-1.2.jar:/soft/hbase/lib/commons-codec-1.9.jar:/soft/hbase/lib/commons-collections-3.2.2.jar:/soft/hbase/lib/commons-compress-1.4.1.jar:/soft/hbase/lib/commons-configuration-1.6.jar:/soft/hbase/lib/commons-daemon-1.0.13.jar:/soft/hbase/lib/commons-digester-1.8.jar:/soft/hbase/lib/commons-el-1.0.jar:/soft/hbase/lib/commons-httpclient-3.1.jar:/soft/hbase/lib/commons-io-2.4.jar:/soft/hbase/lib/commons-lang-2.6.jar:/soft/hbase/lib/commons-logging-1.2.jar:/soft/hbase/lib/commons-math-2.2.jar:/soft/hbase/lib/commons-math3-3.1.1.jar:/soft/hbase/lib/commons-net-3.1.jar:/soft/hbase/lib/disruptor-3.3.0.jar:/soft/hbase/lib/findbugs-annotations-1.3.9-1.jar:/soft/hbase/lib/guava-12.0.1.jar:/soft/hbase/lib/guice-3.0.jar:/soft/hbase/lib/guice-servlet-3.0.jar:/soft/hbase/lib/hadoop-annotations-2.5.1.jar:/soft/hbase/lib/hadoop-auth-2.5.1.jar:/soft/hbase/lib/hadoop-client-2.5.1.jar:/soft/hbase/lib/hadoop-common-2.5.1.jar:/soft/hbase/lib/hadoop-hdfs-2.5.1.jar:/soft/hbase/lib/hadoop-mapreduce-client-app-2.5.1.jar:/soft/hbase/lib/hadoop-mapreduce-client-common-2.5.1.jar:/soft/hbase/lib/hadoop-mapreduce-client-core-2.5.1.jar:/soft/hbase/lib/hadoop-mapreduce-client-jobclient-2.5.1.jar:/soft/hbase/lib/hadoop-mapreduce-client-shuffle-2.5.1.jar:/soft/hbase/lib/hadoop-yarn-api-2.5.1.jar:/soft/hbase/lib/hadoop-yarn-client-2.5.1.jar:/soft/hbase/lib/hadoop-yarn-common-2.5.1.jar:/soft/hbase/lib/hadoop-yarn-server-common-2.5.1.jar:/soft/hbase/lib/hbase-annotations-1.2.6.jar:/soft/hbase/lib/hbase-annotations-1.2.6-tests.jar:/soft/hbase/lib/hbase-client-1.2.6.jar:/soft/hbase/lib/hbase-common-1.2.6.jar:/soft/hbase/lib/hbase-common-1.2.6-tests.jar:/soft/hbase/lib/hbase-examples-1.2.6.jar:/soft/hbase/lib/hbase-external-blockcache-1.2.6.jar:/soft/hbase/lib/hbase-hadoop2-compat-1.2.6.jar:/soft/hbase/lib/hbase-hadoop-compat-1.2.6.jar:/soft/hbase/lib/hbase-it-1.2.6.jar:/soft/hbase/lib/hbase-it-1.2.6-tests.jar:/soft/hbase/lib/hbase-prefix-tree-1.2.6.jar:/soft/hbase/lib/hbase-procedure-1.2.6.jar:/soft/hbase/lib/hbase-protocol-1.2.6.jar:/soft/hbase/lib/hbase-resource-bundle-1.2.6.jar:/soft/hbase/lib/hbase-rest-1.2.6.jar:/soft/hbase/lib/hbase-server-1.2.6.jar:/soft/hbase/lib/hbase-server-1.2.6-tests.jar:/soft/hbase/lib/hbase-shell-1.2.6.jar:/soft/hbase/lib/hbase-thrift-1.2.6.jar:/soft/hbase/lib/htrace-core-3.1.0-incubating.jar:/soft/hbase/lib/httpclient-4.2.5.jar:/soft/hbase/lib/httpcore-4.4.1.jar:/soft/hbase/lib/jackson-core-asl-1.9.13.jar:/soft/hbase/lib/jackson-jaxrs-1.9.13.jar:/soft/hbase/lib/jackson-mapper-asl-1.9.13.jar:/soft/hbase/lib/jackson-xc-1.9.13.jar:/soft/hbase/lib/jamon-runtime-2.4.1.jar:/soft/hbase/lib/jasper-compiler-5.5.23.jar:/soft/hbase/lib/jasper-runtime-5.5.23.jar:/soft/hbase/lib/javax.inject-1.jar:/soft/hbase/lib/java-xmlbuilder-0.4.jar:/soft/hbase/lib/jaxb-api-2.2.2.jar:/soft/hbase/lib/jaxb-impl-2.2.3-1.jar:/soft/hbase/lib/jcodings-1.0.8.jar:/soft/hbase/lib/jersey-client-1.9.jar:/soft/hbase/lib/jersey-core-1.9.jar:/soft/hbase/lib/jersey-guice-1.9.jar:/soft/hbase/lib/jersey-json-1.9.jar:/soft/hbase/lib/jersey-server-1.9.jar:/soft/hbase/lib/jets3t-0.9.0.jar:/soft/hbase/lib/jettison-1.3.3.jar:/soft/hbase/lib/jetty-6.1.26.jar:/soft/hbase/lib/jetty-sslengine-6.1.26.jar:/soft/hbase/lib/jetty-util-6.1.26.jar:/soft/hbase/lib/joni-2.1.2.jar:/soft/hbase/lib/jruby-complete-1.6.8.jar:/soft/hbase/lib/jsch-0.1.42.jar:/soft/hbase/lib/jsp-2.1-6.1.14.jar:/soft/hbase/lib/jsp-api-2.1-6.1.14.jar:/soft/hbase/lib/junit-4.12.jar:/soft/hbase/lib/leveldbjni-all-1.8.jar:/soft/hbase/lib/libthrift-0.9.3.jar:/soft/hbase/lib/log4j-1.2.17.jar:/soft/hbase/lib/metrics-core-2.2.0.jar:/soft/hbase/lib/MyHbase-1.0-SNAPSHOT.jar:/soft/hbase/lib/netty-all-4.0.23.Final.jar:/soft/hbase/lib/paranamer-2.3.jar:/soft/hbase/lib/phoenix-4.10.0-HBase-1.2-client.jar:/soft/hbase/lib/protobuf-java-2.5.0.jar:/soft/hbase/lib/servlet-api-2.5-6.1.14.jar:/soft/hbase/lib/servlet-api-2.5.jar:/soft/hbase/lib/slf4j-api-1.7.7.jar:/soft/hbase/lib/slf4j-log4j12-1.7.5.jar:/soft/hbase/lib/snappy-java-1.0.4.1.jar:/soft/hbase/lib/spymemcached-2.11.6.jar:/soft/hbase/lib/xmlenc-0.52.jar:/soft/hbase/lib/xz-1.0.jar:/soft/hbase/lib/zookeeper-3.4.6.jar:/soft/hadoop-2.7.3/etc/hadoop:/soft/hadoop/share/hadoop/common/lib/jaxb-impl-2.2.3-1.jar:/soft/hadoop/share/hadoop/common/lib/jaxb-api-2.2.2.jar:/soft/hadoop/share/hadoop/common/lib/stax-api-1.0-2.jar:/soft/hadoop/share/hadoop/common/lib/activation-1.1.jar:/soft/hadoop/share/hadoop/common/lib/jackson-core-asl-1.9.13.jar:/soft/hadoop/share/hadoop/common/lib/jackson-mapper-asl-1.9.13.jar:/soft/hadoop/share/hadoop/common/lib/jackson-jaxrs-1.9.13.jar:/soft/hadoop/share/hadoop/common/lib/jackson-xc-1.9.13.jar:/soft/hadoop/share/hadoop/common/lib/jersey-server-1.9.jar:/soft/hadoop/share/hadoop/common/lib/asm-3.2.jar:/soft/hadoop/share/hadoop/common/lib/log4j-1.2.17.jar:/soft/hadoop/share/hadoop/common/lib/jets3t-0.9.0.jar:/soft/hadoop/share/hadoop/common/lib/httpclient-4.2.5.jar:/soft/hadoop/share/hadoop/common/lib/httpcore-4.2.5.jar:/soft/hadoop/share/hadoop/common/lib/java-xmlbuilder-0.4.jar:/soft/hadoop/share/hadoop/common/lib/commons-lang-2.6.jar:/soft/hadoop/share/hadoop/common/lib/commons-configuration-1.6.jar:/soft/hadoop/share/hadoop/common/lib/commons-digester-1.8.jar:/soft/hadoop/share/hadoop/common/lib/commons-beanutils-1.7.0.jar:/soft/hadoop/share/hadoop/common/lib/commons-beanutils-core-1.8.0.jar:/soft/hadoop/share/hadoop/common/lib/slf4j-api-1.7.10.jar:/soft/hadoop/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar:/soft/hadoop/share/hadoop/common/lib/avro-1.7.4.jar:/soft/hadoop/share/hadoop/common/lib/paranamer-2.3.jar:/soft/hadoop/share/hadoop/common/lib/snappy-java-1.0.4.1.jar:/soft/hadoop/share/hadoop/common/lib/commons-compress-1.4.1.jar:/soft/hadoop/share/hadoop/common/lib/xz-1.0.jar:/soft/hadoop/share/hadoop/common/lib/protobuf-java-2.5.0.jar:/soft/hadoop/share/hadoop/common/lib/gson-2.2.4.jar:/soft/hadoop/share/hadoop/common/lib/hadoop-auth-2.7.3.jar:/soft/hadoop/share/hadoop/common/lib/apacheds-kerberos-codec-2.0.0-M15.jar:/soft/hadoop/share/hadoop/common/lib/apacheds-i18n-2.0.0-M15.jar:/soft/hadoop/share/hadoop/common/lib/api-asn1-api-1.0.0-M20.jar:/soft/hadoop/share/hadoop/common/lib/api-util-1.0.0-M20.jar:/soft/hadoop/share/hadoop/common/lib/zookeeper-3.4.6.jar:/soft/hadoop/share/hadoop/common/lib/netty-3.6.2.Final.jar:/soft/hadoop/share/hadoop/common/lib/curator-framework-2.7.1.jar:/soft/hadoop/share/hadoop/common/lib/curator-client-2.7.1.jar:/soft/hadoop/share/hadoop/common/lib/jsch-0.1.42.jar:/soft/hadoop/share/hadoop/common/lib/curator-recipes-2.7.1.jar:/soft/hadoop/share/hadoop/common/lib/htrace-core-3.1.0-incubating.jar:/soft/hadoop/share/hadoop/common/lib/junit-4.11.jar:/soft/hadoop/share/hadoop/common/lib/hamcrest-core-1.3.jar:/soft/hadoop/share/hadoop/common/lib/mockito-all-1.8.5.jar:/soft/hadoop/share/hadoop/common/lib/hadoop-annotations-2.7.3.jar:/soft/hadoop/share/hadoop/common/lib/guava-11.0.2.jar:/soft/hadoop/share/hadoop/common/lib/jsr305-3.0.0.jar:/soft/hadoop/share/hadoop/common/lib/commons-cli-1.2.jar:/soft/hadoop/share/hadoop/common/lib/commons-math3-3.1.1.jar:/soft/hadoop/share/hadoop/common/lib/xmlenc-0.52.jar:/soft/hadoop/share/hadoop/common/lib/commons-httpclient-3.1.jar:/soft/hadoop/share/hadoop/common/lib/commons-logging-1.1.3.jar:/soft/hadoop/share/hadoop/common/lib/commons-codec-1.4.jar:/soft/hadoop/share/hadoop/common/lib/commons-io-2.4.jar:/soft/hadoop/share/hadoop/common/lib/commons-net-3.1.jar:/soft/hadoop/share/hadoop/common/lib/commons-collections-3.2.2.jar:/soft/hadoop/share/hadoop/common/lib/servlet-api-2.5.jar:/soft/hadoop/share/hadoop/common/lib/jetty-6.1.26.jar:/soft/hadoop/share/hadoop/common/lib/jetty-util-6.1.26.jar:/soft/hadoop/share/hadoop/common/lib/jsp-api-2.1.jar:/soft/hadoop/share/hadoop/common/lib/jersey-core-1.9.jar:/soft/hadoop/share/hadoop/common/lib/jersey-json-1.9.jar:/soft/hadoop/share/hadoop/common/lib/jettison-1.1.jar:/soft/hadoop/share/hadoop/common/lib/lzo-core-1.0.0.jar:/soft/hadoop/share/hadoop/common/lib/lzo-hadoop-1.0.0.jar:/soft/hadoop/share/hadoop/common/lib/fastjson-1.2.47.jar:/soft/hadoop/share/hadoop/common/lib/MyHbase-1.0-SNAPSHOT.jar:/soft/hadoop/share/hadoop/common/hadoop-common-2.7.3.jar:/soft/hadoop/share/hadoop/common/hadoop-common-2.7.3-tests.jar:/soft/hadoop/share/hadoop/common/hadoop-nfs-2.7.3.jar:/soft/hadoop-2.7.3/share/hadoop/hdfs:/soft/hadoop-2.7.3/share/hadoop/hdfs/lib/commons-codec-1.4.jar:/soft/hadoop-2.7.3/share/hadoop/hdfs/lib/log4j-1.2.17.jar:/soft/hadoop-2.7.3/share/hadoop/hdfs/lib/commons-logging-1.1.3.jar:/soft/hadoop-2.7.3/share/hadoop/hdfs/lib/netty-3.6.2.Final.jar:/soft/hadoop-2.7.3/share/hadoop/hdfs/lib/guava-11.0.2.jar:/soft/hadoop-2.7.3/share/hadoop/hdfs/lib/jsr305-3.0.0.jar:/soft/hadoop-2.7.3/share/hadoop/hdfs/lib/commons-cli-1.2.jar:/soft/hadoop-2.7.3/share/hadoop/hdfs/lib/xmlenc-0.52.jar:/soft/hadoop-2.7.3/share/hadoop/hdfs/lib/commons-io-2.4.jar:/soft/hadoop-2.7.3/share/hadoop/hdfs/lib/servlet-api-2.5.jar:/soft/hadoop-2.7.3/share/hadoop/hdfs/lib/jetty-6.1.26.jar:/soft/hadoop-2.7.3/share/hadoop/hdfs/lib/jetty-util-6.1.26.jar:/soft/hadoop-2.7.3/share/hadoop/hdfs/lib/jersey-core-1.9.jar:/soft/hadoop-2.7.3/share/hadoop/hdfs/lib/jackson-core-asl-1.9.13.jar:/soft/hadoop-2.7.3/share/hadoop/hdfs/lib/jackson-mapper-asl-1.9.13.jar:/soft/hadoop-2.7.3/share/hadoop/hdfs/lib/jersey-server-1.9.jar:/soft/hadoop-2.7.3/share/hadoop/hdfs/lib/asm-3.2.jar:/soft/hadoop-2.7.3/share/hadoop/hdfs/lib/commons-lang-2.6.jar:/soft/hadoop-2.7.3/share/hadoop/hdfs/lib/protobuf-java-2.5.0.jar:/soft/hadoop-2.7.3/share/hadoop/hdfs/lib/htrace-core-3.1.0-incubating.jar:/soft/hadoop-2.7.3/share/hadoop/hdfs/lib/commons-daemon-1.0.13.jar:/soft/hadoop-2.7.3/share/hadoop/hdfs/lib/netty-all-4.0.23.Final.jar:/soft/hadoop-2.7.3/share/hadoop/hdfs/lib/xercesImpl-2.9.1.jar:/soft/hadoop-2.7.3/share/hadoop/hdfs/lib/xml-apis-1.3.04.jar:/soft/hadoop-2.7.3/share/hadoop/hdfs/lib/leveldbjni-all-1.8.jar:/soft/hadoop-2.7.3/share/hadoop/hdfs/hadoop-hdfs-2.7.3.jar:/soft/hadoop-2.7.3/share/hadoop/hdfs/hadoop-hdfs-2.7.3-tests.jar:/soft/hadoop-2.7.3/share/hadoop/hdfs/hadoop-hdfs-nfs-2.7.3.jar:/soft/hadoop-2.7.3/share/hadoop/yarn/lib/zookeeper-3.4.6-tests.jar:/soft/hadoop-2.7.3/share/hadoop/yarn/lib/commons-lang-2.6.jar:/soft/hadoop-2.7.3/share/hadoop/yarn/lib/guava-11.0.2.jar:/soft/hadoop-2.7.3/share/hadoop/yarn/lib/jsr305-3.0.0.jar:/soft/hadoop-2.7.3/share/hadoop/yarn/lib/commons-logging-1.1.3.jar:/soft/hadoop-2.7.3/share/hadoop/yarn/lib/protobuf-java-2.5.0.jar:/soft/hadoop-2.7.3/share/hadoop/yarn/lib/commons-cli-1.2.jar:/soft/hadoop-2.7.3/share/hadoop/yarn/lib/log4j-1.2.17.jar:/soft/hadoop-2.7.3/share/hadoop/yarn/lib/jaxb-api-2.2.2.jar:/soft/hadoop-2.7.3/share/hadoop/yarn/lib/stax-api-1.0-2.jar:/soft/hadoop-2.7.3/share/hadoop/yarn/lib/activation-1.1.jar:/soft/hadoop-2.7.3/share/hadoop/yarn/lib/commons-compress-1.4.1.jar:/soft/hadoop-2.7.3/share/hadoop/yarn/lib/xz-1.0.jar:/soft/hadoop-2.7.3/share/hadoop/yarn/lib/servlet-api-2.5.jar:/soft/hadoop-2.7.3/share/hadoop/yarn/lib/commons-codec-1.4.jar:/soft/hadoop-2.7.3/share/hadoop/yarn/lib/jetty-util-6.1.26.jar:/soft/hadoop-2.7.3/share/hadoop/yarn/lib/jersey-core-1.9.jar:/soft/hadoop-2.7.3/share/hadoop/yarn/lib/jersey-client-1.9.jar:/soft/hadoop-2.7.3/share/hadoop/yarn/lib/jackson-core-asl-1.9.13.jar:/soft/hadoop-2.7.3/share/hadoop/yarn/lib/jackson-mapper-asl-1.9.13.jar:/soft/hadoop-2.7.3/share/hadoop/yarn/lib/jackson-jaxrs-1.9.13.jar:/soft/hadoop-2.7.3/share/hadoop/yarn/lib/jackson-xc-1.9.13.jar:/soft/hadoop-2.7.3/share/hadoop/yarn/lib/guice-servlet-3.0.jar:/soft/hadoop-2.7.3/share/hadoop/yarn/lib/guice-3.0.jar:/soft/hadoop-2.7.3/share/hadoop/yarn/lib/javax.inject-1.jar:/soft/hadoop-2.7.3/share/hadoop/yarn/lib/aopalliance-1.0.jar:/soft/hadoop-2.7.3/share/hadoop/yarn/lib/commons-io-2.4.jar:/soft/hadoop-2.7.3/share/hadoop/yarn/lib/jersey-server-1.9.jar:/soft/hadoop-2.7.3/share/hadoop/yarn/lib/asm-3.2.jar:/soft/hadoop-2.7.3/share/hadoop/yarn/lib/jersey-json-1.9.jar:/soft/hadoop-2.7.3/share/hadoop/yarn/lib/jettison-1.1.jar:/soft/hadoop-2.7.3/share/hadoop/yarn/lib/jaxb-impl-2.2.3-1.jar:/soft/hadoop-2.7.3/share/hadoop/yarn/lib/jersey-guice-1.9.jar:/soft/hadoop-2.7.3/share/hadoop/yarn/lib/zookeeper-3.4.6.jar:/soft/hadoop-2.7.3/share/hadoop/yarn/lib/netty-3.6.2.Final.jar:/soft/hadoop-2.7.3/share/hadoop/yarn/lib/leveldbjni-all-1.8.jar:/soft/hadoop-2.7.3/share/hadoop/yarn/lib/commons-collections-3.2.2.jar:/soft/hadoop-2.7.3/share/hadoop/yarn/lib/jetty-6.1.26.jar:/soft/hadoop-2.7.3/share/hadoop/yarn/hadoop-yarn-api-2.7.3.jar:/soft/hadoop-2.7.3/share/hadoop/yarn/hadoop-yarn-common-2.7.3.jar:/soft/hadoop-2.7.3/share/hadoop/yarn/hadoop-yarn-server-common-2.7.3.jar:/soft/hadoop-2.7.3/share/hadoop/yarn/hadoop-yarn-server-nodemanager-2.7.3.jar:/soft/hadoop-2.7.3/share/hadoop/yarn/hadoop-yarn-server-web-proxy-2.7.3.jar:/soft/hadoop-2.7.3/share/hadoop/yarn/hadoop-yarn-server-applicationhistoryservice-2.7.3.jar:/soft/hadoop-2.7.3/share/hadoop/yarn/hadoop-yarn-server-resourcemanager-2.7.3.jar:/soft/hadoop-2.7.3/share/hadoop/yarn/hadoop-yarn-server-tests-2.7.3.jar:/soft/hadoop-2.7.3/share/hadoop/yarn/hadoop-yarn-client-2.7.3.jar:/soft/hadoop-2.7.3/share/hadoop/yarn/hadoop-yarn-server-sharedcachemanager-2.7.3.jar:/soft/hadoop-2.7.3/share/hadoop/yarn/hadoop-yarn-applications-distributedshell-2.7.3.jar:/soft/hadoop-2.7.3/share/hadoop/yarn/hadoop-yarn-applications-unmanaged-am-launcher-2.7.3.jar:/soft/hadoop-2.7.3/share/hadoop/yarn/hadoop-yarn-registry-2.7.3.jar:/soft/hadoop/share/hadoop/mapreduce/lib/protobuf-java-2.5.0.jar:/soft/hadoop/share/hadoop/mapreduce/lib/avro-1.7.4.jar:/soft/hadoop/share/hadoop/mapreduce/lib/jackson-core-asl-1.9.13.jar:/soft/hadoop/share/hadoop/mapreduce/lib/jackson-mapper-asl-1.9.13.jar:/soft/hadoop/share/hadoop/mapreduce/lib/paranamer-2.3.jar:/soft/hadoop/share/hadoop/mapreduce/lib/snappy-java-1.0.4.1.jar:/soft/hadoop/share/hadoop/mapreduce/lib/commons-compress-1.4.1.jar:/soft/hadoop/share/hadoop/mapreduce/lib/xz-1.0.jar:/soft/hadoop/share/hadoop/mapreduce/lib/hadoop-annotations-2.7.3.jar:/soft/hadoop/share/hadoop/mapreduce/lib/commons-io-2.4.jar:/soft/hadoop/share/hadoop/mapreduce/lib/jersey-core-1.9.jar:/soft/hadoop/share/hadoop/mapreduce/lib/jersey-server-1.9.jar:/soft/hadoop/share/hadoop/mapreduce/lib/asm-3.2.jar:/soft/hadoop/share/hadoop/mapreduce/lib/log4j-1.2.17.jar:/soft/hadoop/share/hadoop/mapreduce/lib/netty-3.6.2.Final.jar:/soft/hadoop/share/hadoop/mapreduce/lib/leveldbjni-all-1.8.jar:/soft/hadoop/share/hadoop/mapreduce/lib/guice-3.0.jar:/soft/hadoop/share/hadoop/mapreduce/lib/javax.inject-1.jar:/soft/hadoop/share/hadoop/mapreduce/lib/aopalliance-1.0.jar:/soft/hadoop/share/hadoop/mapreduce/lib/jersey-guice-1.9.jar:/soft/hadoop/share/hadoop/mapreduce/lib/guice-servlet-3.0.jar:/soft/hadoop/share/hadoop/mapreduce/lib/junit-4.11.jar:/soft/hadoop/share/hadoop/mapreduce/lib/hamcrest-core-1.3.jar:/soft/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-client-core-2.7.3.jar:/soft/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-client-common-2.7.3.jar:/soft/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-client-shuffle-2.7.3.jar:/soft/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-client-app-2.7.3.jar:/soft/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-client-hs-2.7.3.jar:/soft/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-2.7.3.jar:/soft/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-client-hs-plugins-2.7.3.jar:/soft/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar:/soft/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-2.7.3-tests.jar::/soft/hive/lib/hive-common-2.1.1.jar:/soft/hive/lib/hive-shims-2.1.1.jar:/soft/hive/lib/hive-shims-common-2.1.1.jar:/soft/hive/lib/log4j-slf4j-impl-2.4.1.jar:/soft/hive/lib/log4j-api-2.4.1.jar:/soft/hive/lib/guava-14.0.1.jar:/soft/hive/lib/commons-lang-2.6.jar:/soft/hive/lib/libthrift-0.9.3.jar:/soft/hive/lib/httpclient-4.4.jar:/soft/hive/lib/httpcore-4.4.jar:/soft/hive/lib/commons-logging-1.2.jar:/soft/hive/lib/commons-codec-1.4.jar:/soft/hive/lib/curator-framework-2.6.0.jar:/soft/hive/lib/curator-client-2.6.0.jar:/soft/hive/lib/zookeeper-3.4.6.jar:/soft/hive/lib/jline-2.12.jar:/soft/hive/lib/netty-3.7.0.Final.jar:/soft/hive/lib/hive-shims-0.23-2.1.1.jar:/soft/hive/lib/guice-servlet-3.0.jar:/soft/hive/lib/guice-3.0.jar:/soft/hive/lib/javax.inject-1.jar:/soft/hive/lib/aopalliance-1.0.jar:/soft/hive/lib/protobuf-java-2.5.0.jar:/soft/hive/lib/commons-io-2.4.jar:/soft/hive/lib/activation-1.1.jar:/soft/hive/lib/jackson-jaxrs-1.9.2.jar:/soft/hive/lib/jackson-xc-1.9.2.jar:/soft/hive/lib/jersey-server-1.14.jar:/soft/hive/lib/asm-3.1.jar:/soft/hive/lib/commons-compress-1.9.jar:/soft/hive/lib/jetty-util-6.1.26.jar:/soft/hive/lib/jersey-client-1.9.jar:/soft/hive/lib/commons-cli-1.2.jar:/soft/hive/lib/commons-collections-3.2.2.jar:/soft/hive/lib/commons-httpclient-3.0.1.jar:/soft/hive/lib/junit-4.11.jar:/soft/hive/lib/hamcrest-core-1.3.jar:/soft/hive/lib/jetty-6.1.26.jar:/soft/hive/lib/hive-shims-scheduler-2.1.1.jar:/soft/hive/lib/hive-storage-api-2.1.1.jar:/soft/hive/lib/hive-orc-2.1.1.jar:/soft/hive/lib/jasper-compiler-5.5.23.jar:/soft/hive/lib/jasper-runtime-5.5.23.jar:/soft/hive/lib/commons-el-1.0.jar:/soft/hive/lib/gson-2.2.4.jar:/soft/hive/lib/curator-recipes-2.6.0.jar:/soft/hive/lib/jsr305-3.0.0.jar:/soft/hive/lib/snappy-0.2.jar:/soft/hive/lib/jetty-all-7.6.0.v20120127.jar:/soft/hive/lib/geronimo-jta_1.1_spec-1.1.1.jar:/soft/hive/lib/mail-1.4.1.jar:/soft/hive/lib/geronimo-jaspic_1.0_spec-1.0.jar:/soft/hive/lib/geronimo-annotation_1.0_spec-1.1.1.jar:/soft/hive/lib/asm-commons-3.1.jar:/soft/hive/lib/asm-tree-3.1.jar:/soft/hive/lib/javax.servlet-3.0.0.v201112011016.jar:/soft/hive/lib/joda-time-2.5.jar:/soft/hive/lib/log4j-1.2-api-2.4.1.jar:/soft/hive/lib/log4j-core-2.4.1.jar:/soft/hive/lib/log4j-web-2.4.1.jar:/soft/hive/lib/ant-1.9.1.jar:/soft/hive/lib/ant-launcher-1.9.1.jar:/soft/hive/lib/json-20090211.jar:/soft/hive/lib/metrics-core-3.1.0.jar:/soft/hive/lib/metrics-jvm-3.1.0.jar:/soft/hive/lib/metrics-json-3.1.0.jar:/soft/hive/lib/jackson-databind-2.4.2.jar:/soft/hive/lib/jackson-annotations-2.4.0.jar:/soft/hive/lib/jackson-core-2.4.2.jar:/soft/hive/lib/dropwizard-metrics-hadoop-metrics2-reporter-0.1.2.jar:/soft/hive/lib/hive-serde-2.1.1.jar:/soft/hive/lib/hive-service-rpc-2.1.1.jar:/soft/hive/lib/jsp-api-2.0.jar:/soft/hive/lib/servlet-api-2.4.jar:/soft/hive/lib/ant-1.6.5.jar:/soft/hive/lib/libfb303-0.9.3.jar:/soft/hive/lib/avro-1.7.7.jar:/soft/hive/lib/paranamer-2.3.jar:/soft/hive/lib/snappy-java-1.0.5.jar:/soft/hive/lib/opencsv-2.3.jar:/soft/hive/lib/parquet-hadoop-bundle-1.8.1.jar:/soft/hive/lib/hive-metastore-2.1.1.jar:/soft/hive/lib/javolution-5.5.1.jar:/soft/hive/lib/hbase-client-1.1.1.jar:/soft/hive/lib/hbase-annotations-1.1.1.jar:/soft/hive/lib/findbugs-annotations-1.3.9-1.jar:/soft/hive/lib/hbase-common-1.1.1.jar:/soft/hive/lib/hbase-protocol-1.1.1.jar:/soft/hive/lib/htrace-core-3.1.0-incubating.jar:/soft/hive/lib/netty-all-4.0.23.Final.jar:/soft/hive/lib/jcodings-1.0.8.jar:/soft/hive/lib/joni-2.1.2.jar:/soft/hive/lib/bonecp-0.8.0.RELEASE.jar:/soft/hive/lib/derby-10.10.2.0.jar:/soft/hive/lib/datanucleus-api-jdo-4.2.1.jar:/soft/hive/lib/datanucleus-core-4.1.6.jar:/soft/hive/lib/datanucleus-rdbms-4.1.7.jar:/soft/hive/lib/commons-pool-1.5.4.jar:/soft/hive/lib/commons-dbcp-1.4.jar:/soft/hive/lib/jdo-api-3.0.1.jar:/soft/hive/lib/jta-1.1.jar:/soft/hive/lib/javax.jdo-3.2.0-m3.jar:/soft/hive/lib/transaction-api-1.1.jar:/soft/hive/lib/antlr-runtime-3.4.jar:/soft/hive/lib/stringtemplate-3.2.1.jar:/soft/hive/lib/antlr-2.7.7.jar:/soft/hive/lib/tephra-api-0.6.0.jar:/soft/hive/lib/tephra-core-0.6.0.jar:/soft/hive/lib/guice-assistedinject-3.0.jar:/soft/hive/lib/fastutil-6.5.6.jar:/soft/hive/lib/twill-common-0.6.0-incubating.jar:/soft/hive/lib/twill-core-0.6.0-incubating.jar:/soft/hive/lib/twill-api-0.6.0-incubating.jar:/soft/hive/lib/twill-discovery-api-0.6.0-incubating.jar:/soft/hive/lib/twill-zookeeper-0.6.0-incubating.jar:/soft/hive/lib/twill-discovery-core-0.6.0-incubating.jar:/soft/hive/lib/tephra-hbase-compat-1.0-0.6.0.jar:/soft/hive/lib/hive-testutils-2.1.1.jar:/soft/hive/lib/tempus-fugit-1.1.jar:/soft/hive/lib/hive-exec-2.1.1.jar:/soft/hive/lib/hive-ant-2.1.1.jar:/soft/hive/lib/velocity-1.5.jar:/soft/hive/lib/hive-llap-tez-2.1.1.jar:/soft/hive/lib/hive-llap-client-2.1.1.jar:/soft/hive/lib/hive-llap-common-2.1.1.jar:/soft/hive/lib/commons-lang3-3.1.jar:/soft/hive/lib/ST4-4.0.4.jar:/soft/hive/lib/ivy-2.4.0.jar:/soft/hive/lib/groovy-all-2.4.4.jar:/soft/hive/lib/calcite-core-1.6.0.jar:/soft/hive/lib/calcite-avatica-1.6.0.jar:/soft/hive/lib/calcite-linq4j-1.6.0.jar:/soft/hive/lib/eigenbase-properties-1.1.5.jar:/soft/hive/lib/janino-2.7.6.jar:/soft/hive/lib/commons-compiler-2.7.6.jar:/soft/hive/lib/pentaho-aggdesigner-algorithm-5.1.5-jhyde.jar:/soft/hive/lib/stax-api-1.0.1.jar:/soft/hive/lib/hive-service-2.1.1.jar:/soft/hive/lib/hive-llap-server-2.1.1.jar:/soft/hive/lib/slider-core-0.90.2-incubating.jar:/soft/hive/lib/jcommander-1.32.jar:/soft/hive/lib/jsp-api-2.1.jar:/soft/hive/lib/hbase-hadoop2-compat-1.1.1.jar:/soft/hive/lib/hbase-hadoop-compat-1.1.1.jar:/soft/hive/lib/commons-math-2.2.jar:/soft/hive/lib/metrics-core-2.2.0.jar:/soft/hive/lib/hbase-server-1.1.1.jar:/soft/hive/lib/hbase-procedure-1.1.1.jar:/soft/hive/lib/hbase-common-1.1.1-tests.jar:/soft/hive/lib/hbase-prefix-tree-1.1.1.jar:/soft/hive/lib/jetty-sslengine-6.1.26.jar:/soft/hive/lib/jsp-2.1-6.1.14.jar:/soft/hive/lib/jsp-api-2.1-6.1.14.jar:/soft/hive/lib/servlet-api-2.5-6.1.14.jar:/soft/hive/lib/jamon-runtime-2.3.1.jar:/soft/hive/lib/disruptor-3.3.0.jar:/soft/hive/lib/jpam-1.1.jar:/soft/hive/lib/hive-jdbc-2.1.1.jar:/soft/hive/lib/hive-beeline-2.1.1.jar:/soft/hive/lib/super-csv-2.2.0.jar:/soft/hive/lib/hive-cli-2.1.1.jar:/soft/hive/lib/hive-contrib-2.1.1.jar:/soft/hive/lib/hive-hbase-handler-2.1.1.jar:/soft/hive/lib/hbase-hadoop2-compat-1.1.1-tests.jar:/soft/hive/lib/hive-hwi-2.1.1.jar:/soft/hive/lib/jetty-all-server-7.6.0.v20120127.jar:/soft/hive/lib/hive-accumulo-handler-2.1.1.jar:/soft/hive/lib/accumulo-core-1.6.0.jar:/soft/hive/lib/accumulo-fate-1.6.0.jar:/soft/hive/lib/accumulo-start-1.6.0.jar:/soft/hive/lib/commons-vfs2-2.0.jar:/soft/hive/lib/maven-scm-api-1.4.jar:/soft/hive/lib/plexus-utils-1.5.6.jar:/soft/hive/lib/maven-scm-provider-svnexe-1.4.jar:/soft/hive/lib/maven-scm-provider-svn-commons-1.4.jar:/soft/hive/lib/regexp-1.3.jar:/soft/hive/lib/accumulo-trace-1.6.0.jar:/soft/hive/lib/hive-llap-ext-client-2.1.1.jar:/soft/hive/lib/hive-hplsql-2.1.1.jar:/soft/hive/lib/antlr4-runtime-4.5.jar:/soft/hive/lib/org.abego.treelayout.core-1.0.1.jar:/soft/hive/lib/mysql-connector-java-5.1.41.jar:/soft/hadoop/contrib/capacity-scheduler/*.jar:/soft/sqoop-1.4.7.bin__hadoop-2.6.0/bin/../sqoop-1.4.7.jar:/soft/sqoop-1.4.7.bin__hadoop-2.6.0/bin/../sqoop-test-1.4.7.jar::/soft/hive/lib/hive-common-2.1.1.jar:/soft/hive/lib/hive-shims-2.1.1.jar:/soft/hive/lib/hive-shims-common-2.1.1.jar:/soft/hive/lib/log4j-slf4j-impl-2.4.1.jar:/soft/hive/lib/log4j-api-2.4.1.jar:/soft/hive/lib/guava-14.0.1.jar:/soft/hive/lib/commons-lang-2.6.jar:/soft/hive/lib/libthrift-0.9.3.jar:/soft/hive/lib/httpclient-4.4.jar:/soft/hive/lib/httpcore-4.4.jar:/soft/hive/lib/commons-logging-1.2.jar:/soft/hive/lib/commons-codec-1.4.jar:/soft/hive/lib/curator-framework-2.6.0.jar:/soft/hive/lib/curator-client-2.6.0.jar:/soft/hive/lib/zookeeper-3.4.6.jar:/soft/hive/lib/jline-2.12.jar:/soft/hive/lib/netty-3.7.0.Final.jar:/soft/hive/lib/hive-shims-0.23-2.1.1.jar:/soft/hive/lib/guice-servlet-3.0.jar:/soft/hive/lib/guice-3.0.jar:/soft/hive/lib/javax.inject-1.jar:/soft/hive/lib/aopalliance-1.0.jar:/soft/hive/lib/protobuf-java-2.5.0.jar:/soft/hive/lib/commons-io-2.4.jar:/soft/hive/lib/activation-1.1.jar:/soft/hive/lib/jackson-jaxrs-1.9.2.jar:/soft/hive/lib/jackson-xc-1.9.2.jar:/soft/hive/lib/jersey-server-1.14.jar:/soft/hive/lib/asm-3.1.jar:/soft/hive/lib/commons-compress-1.9.jar:/soft/hive/lib/jetty-util-6.1.26.jar:/soft/hive/lib/jersey-client-1.9.jar:/soft/hive/lib/commons-cli-1.2.jar:/soft/hive/lib/commons-collections-3.2.2.jar:/soft/hive/lib/commons-httpclient-3.0.1.jar:/soft/hive/lib/junit-4.11.jar:/soft/hive/lib/hamcrest-core-1.3.jar:/soft/hive/lib/jetty-6.1.26.jar:/soft/hive/lib/hive-shims-scheduler-2.1.1.jar:/soft/hive/lib/hive-storage-api-2.1.1.jar:/soft/hive/lib/hive-orc-2.1.1.jar:/soft/hive/lib/jasper-compiler-5.5.23.jar:/soft/hive/lib/jasper-runtime-5.5.23.jar:/soft/hive/lib/commons-el-1.0.jar:/soft/hive/lib/gson-2.2.4.jar:/soft/hive/lib/curator-recipes-2.6.0.jar:/soft/hive/lib/jsr305-3.0.0.jar:/soft/hive/lib/snappy-0.2.jar:/soft/hive/lib/jetty-all-7.6.0.v20120127.jar:/soft/hive/lib/geronimo-jta_1.1_spec-1.1.1.jar:/soft/hive/lib/mail-1.4.1.jar:/soft/hive/lib/geronimo-jaspic_1.0_spec-1.0.jar:/soft/hive/lib/geronimo-annotation_1.0_spec-1.1.1.jar:/soft/hive/lib/asm-commons-3.1.jar:/soft/hive/lib/asm-tree-3.1.jar:/soft/hive/lib/javax.servlet-3.0.0.v201112011016.jar:/soft/hive/lib/joda-time-2.5.jar:/soft/hive/lib/log4j-1.2-api-2.4.1.jar:/soft/hive/lib/log4j-core-2.4.1.jar:/soft/hive/lib/log4j-web-2.4.1.jar:/soft/hive/lib/ant-1.9.1.jar:/soft/hive/lib/ant-launcher-1.9.1.jar:/soft/hive/lib/json-20090211.jar:/soft/hive/lib/metrics-core-3.1.0.jar:/soft/hive/lib/metrics-jvm-3.1.0.jar:/soft/hive/lib/metrics-json-3.1.0.jar:/soft/hive/lib/jackson-databind-2.4.2.jar:/soft/hive/lib/jackson-annotations-2.4.0.jar:/soft/hive/lib/jackson-core-2.4.2.jar:/soft/hive/lib/dropwizard-metrics-hadoop-metrics2-reporter-0.1.2.jar:/soft/hive/lib/hive-serde-2.1.1.jar:/soft/hive/lib/hive-service-rpc-2.1.1.jar:/soft/hive/lib/jsp-api-2.0.jar:/soft/hive/lib/servlet-api-2.4.jar:/soft/hive/lib/ant-1.6.5.jar:/soft/hive/lib/libfb303-0.9.3.jar:/soft/hive/lib/avro-1.7.7.jar:/soft/hive/lib/paranamer-2.3.jar:/soft/hive/lib/snappy-java-1.0.5.jar:/soft/hive/lib/opencsv-2.3.jar:/soft/hive/lib/parquet-hadoop-bundle-1.8.1.jar:/soft/hive/lib/hive-metastore-2.1.1.jar:/soft/hive/lib/javolution-5.5.1.jar:/soft/hive/lib/hbase-client-1.1.1.jar:/soft/hive/lib/hbase-annotations-1.1.1.jar:/soft/hive/lib/findbugs-annotations-1.3.9-1.jar:/soft/hive/lib/hbase-common-1.1.1.jar:/soft/hive/lib/hbase-protocol-1.1.1.jar:/soft/hive/lib/htrace-core-3.1.0-incubating.jar:/soft/hive/lib/netty-all-4.0.23.Final.jar:/soft/hive/lib/jcodings-1.0.8.jar:/soft/hive/lib/joni-2.1.2.jar:/soft/hive/lib/bonecp-0.8.0.RELEASE.jar:/soft/hive/lib/derby-10.10.2.0.jar:/soft/hive/lib/datanucleus-api-jdo-4.2.1.jar:/soft/hive/lib/datanucleus-core-4.1.6.jar:/soft/hive/lib/datanucleus-rdbms-4.1.7.jar:/soft/hive/lib/commons-pool-1.5.4.jar:/soft/hive/lib/commons-dbcp-1.4.jar:/soft/hive/lib/jdo-api-3.0.1.jar:/soft/hive/lib/jta-1.1.jar:/soft/hive/lib/javax.jdo-3.2.0-m3.jar:/soft/hive/lib/transaction-api-1.1.jar:/soft/hive/lib/antlr-runtime-3.4.jar:/soft/hive/lib/stringtemplate-3.2.1.jar:/soft/hive/lib/antlr-2.7.7.jar:/soft/hive/lib/tephra-api-0.6.0.jar:/soft/hive/lib/tephra-core-0.6.0.jar:/soft/hive/lib/guice-assistedinject-3.0.jar:/soft/hive/lib/fastutil-6.5.6.jar:/soft/hive/lib/twill-common-0.6.0-incubating.jar:/soft/hive/lib/twill-core-0.6.0-incubating.jar:/soft/hive/lib/twill-api-0.6.0-incubating.jar:/soft/hive/lib/twill-discovery-api-0.6.0-incubating.jar:/soft/hive/lib/twill-zookeeper-0.6.0-incubating.jar:/soft/hive/lib/twill-discovery-core-0.6.0-incubating.jar:/soft/hive/lib/tephra-hbase-compat-1.0-0.6.0.jar:/soft/hive/lib/hive-testutils-2.1.1.jar:/soft/hive/lib/tempus-fugit-1.1.jar:/soft/hive/lib/hive-exec-2.1.1.jar:/soft/hive/lib/hive-ant-2.1.1.jar:/soft/hive/lib/velocity-1.5.jar:/soft/hive/lib/hive-llap-tez-2.1.1.jar:/soft/hive/lib/hive-llap-client-2.1.1.jar:/soft/hive/lib/hive-llap-common-2.1.1.jar:/soft/hive/lib/commons-lang3-3.1.jar:/soft/hive/lib/ST4-4.0.4.jar:/soft/hive/lib/ivy-2.4.0.jar:/soft/hive/lib/groovy-all-2.4.4.jar:/soft/hive/lib/calcite-core-1.6.0.jar:/soft/hive/lib/calcite-avatica-1.6.0.jar:/soft/hive/lib/calcite-linq4j-1.6.0.jar:/soft/hive/lib/eigenbase-properties-1.1.5.jar:/soft/hive/lib/janino-2.7.6.jar:/soft/hive/lib/commons-compiler-2.7.6.jar:/soft/hive/lib/pentaho-aggdesigner-algorithm-5.1.5-jhyde.jar:/soft/hive/lib/stax-api-1.0.1.jar:/soft/hive/lib/hive-service-2.1.1.jar:/soft/hive/lib/hive-llap-server-2.1.1.jar:/soft/hive/lib/slider-core-0.90.2-incubating.jar:/soft/hive/lib/jcommander-1.32.jar:/soft/hive/lib/jsp-api-2.1.jar:/soft/hive/lib/hbase-hadoop2-compat-1.1.1.jar:/soft/hive/lib/hbase-hadoop-compat-1.1.1.jar:/soft/hive/lib/commons-math-2.2.jar:/soft/hive/lib/metrics-core-2.2.0.jar:/soft/hive/lib/hbase-server-1.1.1.jar:/soft/hive/lib/hbase-procedure-1.1.1.jar:/soft/hive/lib/hbase-common-1.1.1-tests.jar:/soft/hive/lib/hbase-prefix-tree-1.1.1.jar:/soft/hive/lib/jetty-sslengine-6.1.26.jar:/soft/hive/lib/jsp-2.1-6.1.14.jar:/soft/hive/lib/jsp-api-2.1-6.1.14.jar:/soft/hive/lib/servlet-api-2.5-6.1.14.jar:/soft/hive/lib/jamon-runtime-2.3.1.jar:/soft/hive/lib/disruptor-3.3.0.jar:/soft/hive/lib/jpam-1.1.jar:/soft/hive/lib/hive-jdbc-2.1.1.jar:/soft/hive/lib/hive-beeline-2.1.1.jar:/soft/hive/lib/super-csv-2.2.0.jar:/soft/hive/lib/hive-cli-2.1.1.jar:/soft/hive/lib/hive-contrib-2.1.1.jar:/soft/hive/lib/hive-hbase-handler-2.1.1.jar:/soft/hive/lib/hbase-hadoop2-compat-1.1.1-tests.jar:/soft/hive/lib/hive-hwi-2.1.1.jar:/soft/hive/lib/jetty-all-server-7.6.0.v20120127.jar:/soft/hive/lib/hive-accumulo-handler-2.1.1.jar:/soft/hive/lib/accumulo-core-1.6.0.jar:/soft/hive/lib/accumulo-fate-1.6.0.jar:/soft/hive/lib/accumulo-start-1.6.0.jar:/soft/hive/lib/commons-vfs2-2.0.jar:/soft/hive/lib/maven-scm-api-1.4.jar:/soft/hive/lib/plexus-utils-1.5.6.jar:/soft/hive/lib/maven-scm-provider-svnexe-1.4.jar:/soft/hive/lib/maven-scm-provider-svn-commons-1.4.jar:/soft/hive/lib/regexp-1.3.jar:/soft/hive/lib/accumulo-trace-1.6.0.jar:/soft/hive/lib/hive-llap-ext-client-2.1.1.jar:/soft/hive/lib/hive-hplsql-2.1.1.jar:/soft/hive/lib/antlr4-runtime-4.5.jar:/soft/hive/lib/org.abego.treelayout.core-1.0.1.jar:/soft/hive/lib/mysql-connector-java-5.1.41.jar:/soft/hadoop/contrib/capacity-scheduler/*.jar 18/06/14 03:49:12 INFO zookeeper.ZooKeeper: Client environment:java.library.path=/soft/hadoop-2.7.3/lib/native 18/06/14 03:49:12 INFO zookeeper.ZooKeeper: Client environment:java.io.tmpdir=/tmp 18/06/14 03:49:12 INFO zookeeper.ZooKeeper: Client environment:java.compiler=<NA> 18/06/14 03:49:12 INFO zookeeper.ZooKeeper: Client environment:os.name=Linux 18/06/14 03:49:12 INFO zookeeper.ZooKeeper: Client environment:os.arch=amd64 18/06/14 03:49:12 INFO zookeeper.ZooKeeper: Client environment:os.version=3.10.0-327.el7.x86_64 18/06/14 03:49:12 INFO zookeeper.ZooKeeper: Client environment:user.name=yinzhengjie 18/06/14 03:49:12 INFO zookeeper.ZooKeeper: Client environment:user.home=/home/yinzhengjie 18/06/14 03:49:12 INFO zookeeper.ZooKeeper: Client environment:user.dir=/home/yinzhengjie 18/06/14 03:49:12 INFO zookeeper.ZooKeeper: Initiating client connection, connectString=s102:2181,s103:2181,s104:2181 sessionTimeout=90000 watcher=hconnection-0x3c782d8e0x0, quorum=s102:2181,s103:2181,s104:2181, baseZNode=/hbase 18/06/14 03:49:12 INFO zookeeper.ClientCnxn: Opening socket connection to server s102/172.30.100.102:2181. Will not attempt to authenticate using SASL (unknown error) 18/06/14 03:49:12 INFO zookeeper.ClientCnxn: Socket connection established to s102/172.30.100.102:2181, initiating session 18/06/14 03:49:12 INFO zookeeper.ClientCnxn: Session establishment complete on server s102/172.30.100.102:2181, sessionid = 0x6600000ebb860010, negotiated timeout = 40000 18/06/14 03:49:13 INFO mapreduce.HBaseImportJob: Creating missing HBase table yinzhengjie:wc 18/06/14 03:49:15 INFO client.HBaseAdmin: Created yinzhengjie:wc 18/06/14 03:49:15 INFO client.ConnectionManager$HConnectionImplementation: Closing master protocol: MasterService 18/06/14 03:49:15 INFO client.ConnectionManager$HConnectionImplementation: Closing zookeeper sessionid=0x6600000ebb860010 18/06/14 03:49:15 INFO zookeeper.ZooKeeper: Session: 0x6600000ebb860010 closed 18/06/14 03:49:15 INFO zookeeper.ClientCnxn: EventThread shut down 18/06/14 03:49:21 INFO db.DBInputFormat: Using read commited transaction isolation 18/06/14 03:49:22 INFO mapreduce.JobSubmitter: number of splits:1 18/06/14 03:49:22 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1528967628934_0012 18/06/14 03:49:23 INFO impl.YarnClientImpl: Submitted application application_1528967628934_0012 18/06/14 03:49:23 INFO mapreduce.Job: The url to track the job: http://s101:8088/proxy/application_1528967628934_0012/ 18/06/14 03:49:23 INFO mapreduce.Job: Running job: job_1528967628934_0012 18/06/14 03:49:33 INFO mapreduce.Job: Job job_1528967628934_0012 running in uber mode : false 18/06/14 03:49:33 INFO mapreduce.Job: map 0% reduce 0% 18/06/14 03:49:41 INFO mapreduce.Job: map 100% reduce 0% 18/06/14 03:49:41 INFO mapreduce.Job: Job job_1528967628934_0012 completed successfully 18/06/14 03:49:41 INFO mapreduce.Job: Counters: 30 File System Counters FILE: Number of bytes read=0 FILE: Number of bytes written=170441 FILE: Number of read operations=0 FILE: Number of large read operations=0 FILE: Number of write operations=0 HDFS: Number of bytes read=87 HDFS: Number of bytes written=0 HDFS: Number of read operations=1 HDFS: Number of large read operations=0 HDFS: Number of write operations=0 Job Counters Launched map tasks=1 Other local map tasks=1 Total time spent by all maps in occupied slots (ms)=5649 Total time spent by all reduces in occupied slots (ms)=0 Total time spent by all map tasks (ms)=5649 Total vcore-milliseconds taken by all map tasks=5649 Total megabyte-milliseconds taken by all map tasks=5784576 Map-Reduce Framework Map input records=4 Map output records=4 Input split bytes=87 Spilled Records=0 Failed Shuffles=0 Merged Map outputs=0 GC time elapsed (ms)=103 CPU time spent (ms)=2080 Physical memory (bytes) snapshot=148975616 Virtual memory (bytes) snapshot=2099900416 Total committed heap usage (bytes)=19546112 File Input Format Counters Bytes Read=0 File Output Format Counters Bytes Written=0 18/06/14 03:49:41 INFO mapreduce.ImportJobBase: Transferred 0 bytes in 26.3319 seconds (0 bytes/sec) 18/06/14 03:49:41 INFO mapreduce.ImportJobBase: Retrieved 4 records. [yinzhengjie@s101 ~]$
[yinzhengjie@s101 ~]$ hbase shell SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/soft/hbase-1.2.6/lib/phoenix-4.10.0-HBase-1.2-client.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/soft/hbase-1.2.6/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/soft/hadoop-2.7.3/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/soft/apache-hive-2.1.1-bin/lib/log4j-slf4j-impl-2.4.1.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. HBase Shell; enter 'help<RETURN>' for list of supported commands. Type "exit<RETURN>" to leave the HBase Shell Version 1.2.6, rUnknown, Mon May 29 02:25:32 CDT 2017 hbase(main):001:0> list TABLE SYSTEM.CATALOG SYSTEM.FUNCTION SYSTEM.MUTEX SYSTEM.SEQUENCE SYSTEM.STATS YINZHENGJIE.T1 ns1:calllog ns1:observer ns1:t1 yinzhengjie:WordCount yinzhengjie:WordCount2 yinzhengjie:WordCount3 yinzhengjie:t1 yinzhengjie:test yinzhengjie:wc 15 row(s) in 0.1960 seconds => ["SYSTEM.CATALOG", "SYSTEM.FUNCTION", "SYSTEM.MUTEX", "SYSTEM.SEQUENCE", "SYSTEM.STATS", "YINZHENGJIE.T1", "ns1:calllog", "ns1:observer", "ns1:t1", "yinzhengjie:WordCount", "yinzhengjie:WordCount2", "yinzhengjie:WordCount3", "yinzhengjie:t1", "yinzhengjie:test", "yinzhengjie:wc"] hbase(main):002:0> scan 'yinzhengjie:wc' ROW COLUMN+CELL 1 column=f1:string, timestamp=1528973379630, value=hello world 2 column=f1:string, timestamp=1528973379630, value=yinzhengjie hbase 2 row(s) in 0.1190 seconds hbase(main):003:0>
2>.其他常用参数介绍
--column-family <family> //指定列族 --hbase-bulkload //指定批量加载 --hbase-create-table //改参数表示如果表不存在就创建,若存在就忽略该参数 --hbase-row-key <col> //指定hbase的rowkey --hbase-table <table> //指定hbase的表
六.sqoop的导出
1>.关键参数说明
--columns <col,col,col...> //指定mysql列 --direct //使用直接导入,速度较快 --export-dir <dir> //导出源数据 -m //mapper数量 --table <table-name> //指定mysql表 --input-fields-terminated-by <char> //输入字段分割符
2>.建立mysql表,指明字段
[yinzhengjie@s101 ~]$ mysql -uroot -pyinzhengjie Warning: Using a password on the command line interface can be insecure. Welcome to the MySQL monitor. Commands end with ; or g. Your MySQL connection id is 291 Server version: 5.6.38 MySQL Community Server (GPL) Copyright (c) 2000, 2017, Oracle and/or its affiliates. All rights reserved. Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners. Type 'help;' or 'h' for help. Type 'c' to clear the current input statement. mysql> use yinzhengjie Reading table information for completion of table and column names You can turn off this feature to get a quicker startup with -A Database changed mysql> create table yinzhengjie_export(id int primary key AUTO_INCREMENT, name varchar(20), age int); Query OK, 0 rows affected (0.14 sec) mysql> desc yinzhengjie_export; +-------+-------------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +-------+-------------+------+-----+---------+----------------+ | id | int(11) | NO | PRI | NULL | auto_increment | | name | varchar(20) | YES | | NULL | | | age | int(11) | YES | | NULL | | +-------+-------------+------+-----+---------+----------------+ 3 rows in set (0.04 sec) mysql>
3>.开始导出
[yinzhengjie@s101 ~]$ sqoop export --connect jdbc:mysql://s101/yinzhengjie --username root -P --table yinzhengjie_export --export-dir /user/hive/warehouse/yinzhengjie.db/test4/province=beijing/part-m-00000 --columns id,name,age --input-fields-terminated-by " " -m 1 Warning: /soft/sqoop-1.4.7.bin__hadoop-2.6.0/bin/../../hcatalog does not exist! HCatalog jobs will fail. Please set $HCAT_HOME to the root of your HCatalog installation. Warning: /soft/sqoop-1.4.7.bin__hadoop-2.6.0/bin/../../accumulo does not exist! Accumulo imports will fail. Please set $ACCUMULO_HOME to the root of your Accumulo installation. Warning: /soft/sqoop-1.4.7.bin__hadoop-2.6.0/bin/../../zookeeper does not exist! Accumulo imports will fail. Please set $ZOOKEEPER_HOME to the root of your Zookeeper installation. 18/06/14 08:27:53 INFO sqoop.Sqoop: Running Sqoop version: 1.4.7 Enter password: 18/06/14 08:27:56 INFO manager.MySQLManager: Preparing to use a MySQL streaming resultset. 18/06/14 08:27:56 INFO tool.CodeGenTool: Beginning code generation SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/soft/hadoop-2.7.3/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/soft/hbase-1.2.6/lib/phoenix-4.10.0-HBase-1.2-client.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/soft/hbase-1.2.6/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/soft/apache-hive-2.1.1-bin/lib/log4j-slf4j-impl-2.4.1.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory] 18/06/14 08:27:56 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `yinzhengjie_export` AS t LIMIT 1 18/06/14 08:27:56 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `yinzhengjie_export` AS t LIMIT 1 18/06/14 08:27:56 INFO orm.CompilationManager: HADOOP_MAPRED_HOME is /soft/hadoop Note: /tmp/sqoop-yinzhengjie/compile/6b92104c3d95bb8deacbe1af30022e16/yinzhengjie_export.java uses or overrides a deprecated API. Note: Recompile with -Xlint:deprecation for details. 18/06/14 08:27:59 INFO orm.CompilationManager: Writing jar file: /tmp/sqoop-yinzhengjie/compile/6b92104c3d95bb8deacbe1af30022e16/yinzhengjie_export.jar 18/06/14 08:27:59 INFO mapreduce.ExportJobBase: Beginning export of yinzhengjie_export 18/06/14 08:27:59 INFO Configuration.deprecation: mapred.jar is deprecated. Instead, use mapreduce.job.jar 18/06/14 08:28:01 INFO Configuration.deprecation: mapred.reduce.tasks.speculative.execution is deprecated. Instead, use mapreduce.reduce.speculative 18/06/14 08:28:01 INFO Configuration.deprecation: mapred.map.tasks.speculative.execution is deprecated. Instead, use mapreduce.map.speculative 18/06/14 08:28:01 INFO Configuration.deprecation: mapred.map.tasks is deprecated. Instead, use mapreduce.job.maps 18/06/14 08:28:06 INFO input.FileInputFormat: Total input paths to process : 1 18/06/14 08:28:06 INFO input.FileInputFormat: Total input paths to process : 1 18/06/14 08:28:06 INFO mapreduce.JobSubmitter: number of splits:1 18/06/14 08:28:06 INFO Configuration.deprecation: mapred.map.tasks.speculative.execution is deprecated. Instead, use mapreduce.map.speculative 18/06/14 08:28:07 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1528967628934_0020 18/06/14 08:28:07 INFO impl.YarnClientImpl: Submitted application application_1528967628934_0020 18/06/14 08:28:07 INFO mapreduce.Job: The url to track the job: http://s101:8088/proxy/application_1528967628934_0020/ 18/06/14 08:28:07 INFO mapreduce.Job: Running job: job_1528967628934_0020 18/06/14 08:28:14 INFO mapreduce.Job: Job job_1528967628934_0020 running in uber mode : false 18/06/14 08:28:14 INFO mapreduce.Job: map 0% reduce 0% 18/06/14 08:28:21 INFO mapreduce.Job: map 100% reduce 0% 18/06/14 08:28:22 INFO mapreduce.Job: Job job_1528967628934_0020 completed successfully 18/06/14 08:28:22 INFO mapreduce.Job: Counters: 30 File System Counters FILE: Number of bytes read=0 FILE: Number of bytes written=140269 FILE: Number of read operations=0 FILE: Number of large read operations=0 FILE: Number of write operations=0 HDFS: Number of bytes read=188 HDFS: Number of bytes written=0 HDFS: Number of read operations=4 HDFS: Number of large read operations=0 HDFS: Number of write operations=0 Job Counters Launched map tasks=1 Other local map tasks=1 Total time spent by all maps in occupied slots (ms)=3822 Total time spent by all reduces in occupied slots (ms)=0 Total time spent by all map tasks (ms)=3822 Total vcore-milliseconds taken by all map tasks=3822 Total megabyte-milliseconds taken by all map tasks=3913728 Map-Reduce Framework Map input records=1 Map output records=1 Input split bytes=168 Spilled Records=0 Failed Shuffles=0 Merged Map outputs=0 GC time elapsed (ms)=56 CPU time spent (ms)=830 Physical memory (bytes) snapshot=165449728 Virtual memory (bytes) snapshot=2108575744 Total committed heap usage (bytes)=86507520 File Input Format Counters Bytes Read=0 File Output Format Counters Bytes Written=0 18/06/14 08:28:22 INFO mapreduce.ExportJobBase: Transferred 188 bytes in 20.9128 seconds (8.9897 bytes/sec) 18/06/14 08:28:22 INFO mapreduce.ExportJobBase: Exported 1 records. [yinzhengjie@s101 ~]$ echo $? 0 [yinzhengjie@s101 ~]$