NameNode和DataNode工作原理剖析
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
一.DataNode的工作原理
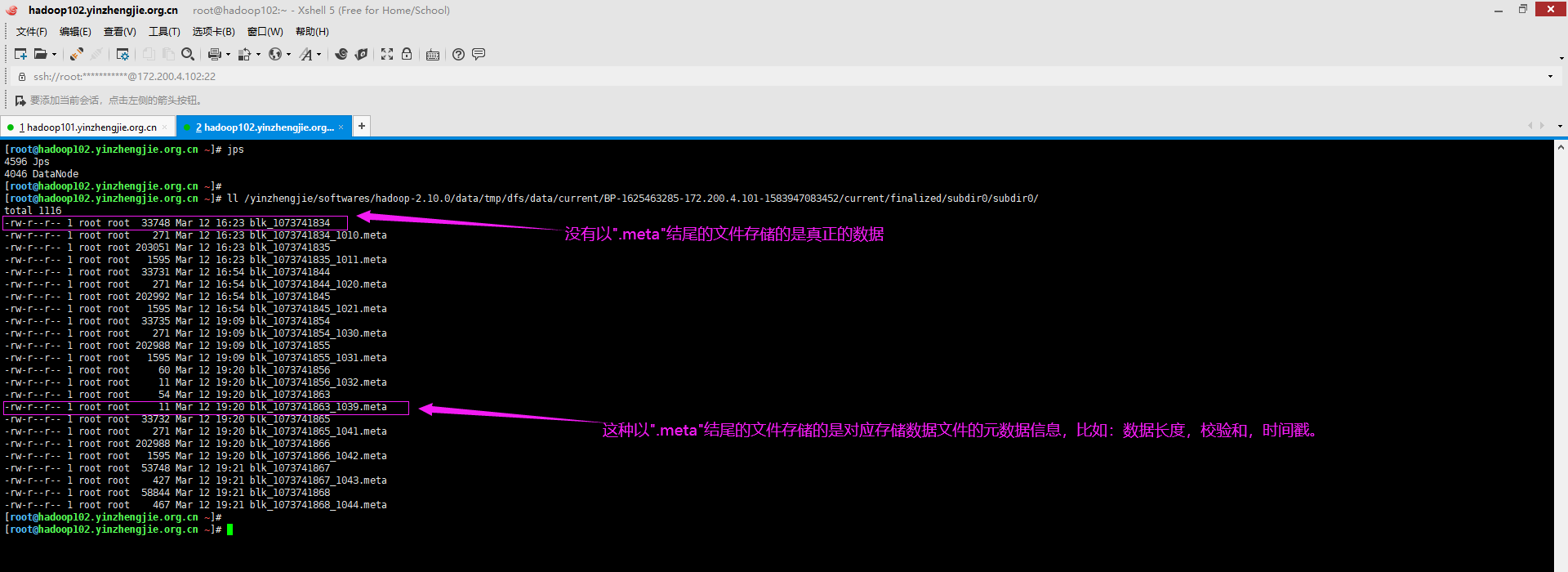
1>.查看数据节点存储数据的目录
系统中的数据块的位置并不是由NameNode维护的,而是以块列表的形式存储在DataNode中。在系统的正常操作期间,NameNode会在内存中保留所有块位置的映射信息。
在安全模式下,各个DataNode会向NameNode发送最新的块列表信息,NameNode了解到足够多的块位置信息之后,即可搞笑运行文件系统。
如下图所示,数据节点不仅仅存放了真实数据,它还保存了相应块的元数据信息哟。
一个数据块在DataNode上以文件形式存储在磁盘上,包括两个文件,一个是数据本身,一个是元数据文件,元数据包括数据块的长度,块数据的校验和,以及时间戳。
2>.数据节点的工作机制
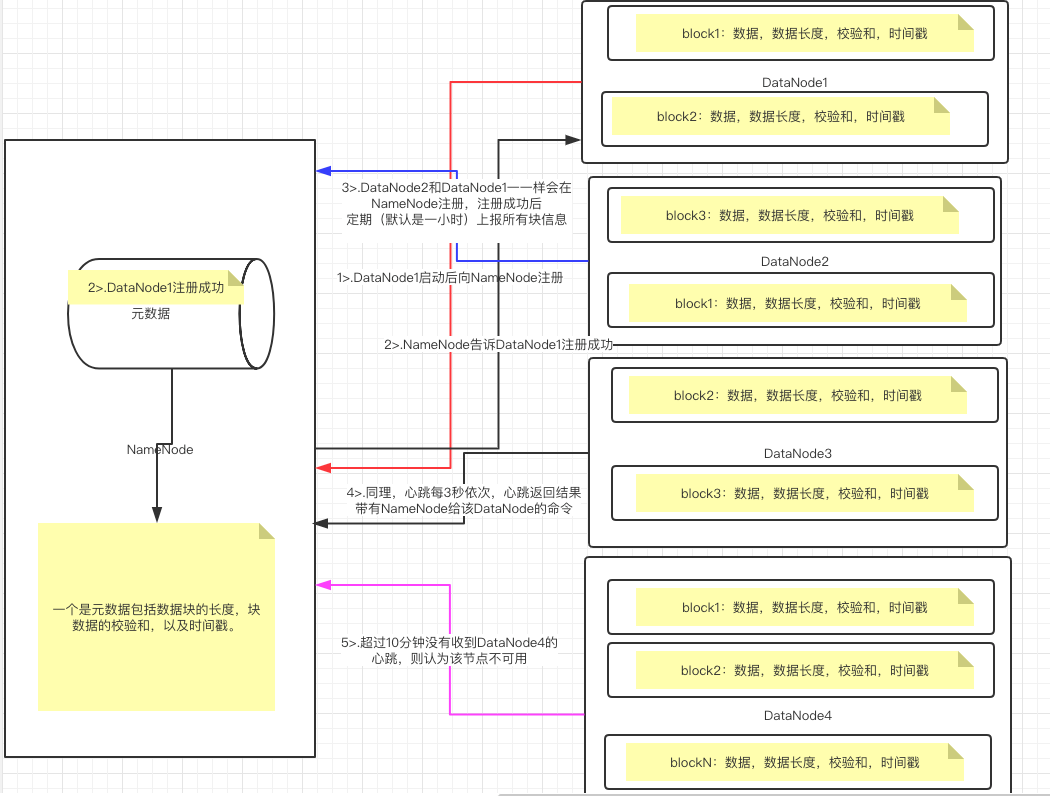
如上图所示,DataNode的工作原理大致如下: 首先我们需要启动NameNode并进入安全模式: (1)NameNode启动时,首先会将镜像文件载入内存; (2)其次会加载编辑日志以执行编辑日志中的各种操作; (3)紧接着会保存检查点; (4)而后,NameNode开始监听DataNode的请求,这个过程期间,NameNode一直运行在安全模式,即HDFS文件系统对于客户端来说是只读的。 其次我需要启动DataNode: (1)DataNode启动后会向NameNode注册; (2)NameNode接收到DataNode的注册请求,验证VERSION信息成功后,会向DataNode响应注册成功; (3)当该DataNode通过注册信息后,以后会周期性的向NameNode上报当前数据节点所有的块信息,即以一个块列表的形式上报; (4)心跳周期(可以通过"dfs.heartbeat.interval"参数设置)默认是每3秒一次,心跳返回结果带有NameNode给该DataNode的命令如复制块数据到另一台机器,或删除某个数据块。 (5)如果NameNode超过10分钟30秒没有收到某个DataNode的心跳,则认为该节点不可用。 最后集群退出安全模式: 当满足最小副本条件,NameNode会在30秒后就退出安全模式。所谓最小副本条件指的是在整个文件系统中99.9%(如果想要修改该参数的默认值可以直接修改"dfs.namenode.safemode.threshold-pct"参数)的块满足最小副本级别(默认值:dfs.namenode.replication.min=1)。 Q1:数据节点周期性上传当前节点的所有数据块列表的默认时间是多少呢? 答:我查阅了官网,并没有找到有配置该参数的值,但网上很多博客都说是1小时,我也他们是从哪看到的呢?我在官网只找到了可以设置新增快上报时间的参数,即"dfs.blockreport.incremental.intervalMsec"。
Q2:DataNode挂掉后为什么NameNode不立即判断DataNode不可用呢?
答:进程死亡还是网络故障都可以造成DataNode无法与NameNode进行通信,NameNode不会立即把该节点判断为死亡,要经过一段时间,这端时间我们称之为超时时长。如果在规定的超时市场DataNode恢复和NameNode之间的通信的话,NameNode和DataNode依旧和往常一下正常工作,这可以体现NameNode的抗容错性强。
Q3:为什么说DataNode的超时时间是10分30秒呢?
答:如果定义超时时间为TimeOut,则计算超时时间的公式为: TimeOut = 2 * dfs.namenode.heartbeat.recheck-interval(指的是一次决定检查过期数据节点的间隔。默认5分钟) + 10 * dfs.heartbeat.interval(心跳间隔,默认3秒钟),计算得到超时时间的值为"10分30秒"。因此,你可以修改这两个变量以达到修改超时时间的目的。
Q4:上面是校验和?
答:校验和的目的就是用来保证传输数据的过程中保证数据的完整性,常见的校验算法比如MD5(占用大小是128Bit),CRC(占用大小是32Bit),SHA1(占用大小是160Bit)等,
Q5:HDFS采用的是那种校验算法呢?
答:DataNode的数据传输默认使用CRC校验算法,NameNode的元数据信息采用的是MD5校验算法。但是我们要知道CRC相对MD5和SHA1校验算法的可靠性较差,因为CRC的校验算法算出的hash散列值重复性要比MD5和SHA1校验算法要高。但是校验算法越长需要付出的代价是会消耗更多的CPU资源。
二.Apache Hadoop集群扩容实战案例
博主推荐阅读: https://www.cnblogs.com/yinzhengjie2020/p/12489223.html
三.Apache Hadoop集群缩容实战案例
博主推荐阅读: https://www.cnblogs.com/yinzhengjie2020/p/12513530.html