Spark的Standalone运行模式部署实战案例
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
一.准备工作
1>.角色分配
hadoop101.yinzhengjie.org.cn:
worker节点,ansible节点
hadoop102.yinzhengjie.org.cn:
worker节点
hadoop103.yinzhengjie.org.cn:
worker节点
hadoop104.yinzhengjie.org.cn:
worker节点
hadoop105.yinzhengjie.org.cn:
master节点
hadoop106.yinzhengjie.org.cn:
woker节点
2>.配置master节点与其它worker节点免密登录


[root@hadoop105.yinzhengjie.org.cn ~]# ssh-keygen -t rsa -f ~/.ssh/id_rsa -P '' Generating public/private rsa key pair. Your identification has been saved in /root/.ssh/id_rsa. Your public key has been saved in /root/.ssh/id_rsa.pub. The key fingerprint is: SHA256:Bb4nYkfJI45ODlSFmeh9CZOdcxys7a44MABjFsVNFY0 root@hadoop105.yinzhengjie.org.cn The key's randomart image is: +---[RSA 2048]----+ | .+o+Oo**. | |oo.oB.+E++ | |+o.. o.** . | |... .o+o.+ | | .. o.+.S . | | o= . o.o | | oo . | | .. . | | .... | +----[SHA256]-----+ [root@hadoop105.yinzhengjie.org.cn ~]#
[root@hadoop105.yinzhengjie.org.cn ~]# ssh-copy-id hadoop101.yinzhengjie.org.cn /usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/root/.ssh/id_rsa.pub" /usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed /usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys root@hadoop101.yinzhengjie.org.cn's password: Number of key(s) added: 1 Now try logging into the machine, with: "ssh 'hadoop101.yinzhengjie.org.cn'" and check to make sure that only the key(s) you wanted were added. [root@hadoop105.yinzhengjie.org.cn ~]# [root@hadoop105.yinzhengjie.org.cn ~]# who root pts/0 2020-06-30 03:38 (172.200.0.1) [root@hadoop105.yinzhengjie.org.cn ~]# [root@hadoop105.yinzhengjie.org.cn ~]# ssh hadoop101.yinzhengjie.org.cn Last failed login: Tue Jun 30 03:49:58 CST 2020 from 172.200.4.105 on ssh:notty There were 2 failed login attempts since the last successful login. Last login: Tue Jun 30 03:47:46 2020 from 172.200.4.101 [root@hadoop101.yinzhengjie.org.cn ~]# [root@hadoop101.yinzhengjie.org.cn ~]# who root pts/0 2020-06-30 03:36 (172.200.0.1) root pts/1 2020-06-30 03:55 (172.200.4.105) [root@hadoop101.yinzhengjie.org.cn ~]# [root@hadoop101.yinzhengjie.org.cn ~]# exit logout Connection to hadoop101.yinzhengjie.org.cn closed. [root@hadoop105.yinzhengjie.org.cn ~]# [root@hadoop105.yinzhengjie.org.cn ~]# who root pts/0 2020-06-30 03:38 (172.200.0.1) [root@hadoop105.yinzhengjie.org.cn ~]# [root@hadoop105.yinzhengjie.org.cn ~]#
[root@hadoop105.yinzhengjie.org.cn ~]# ssh-copy-id hadoop102.yinzhengjie.org.cn /usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/root/.ssh/id_rsa.pub" /usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed /usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys root@hadoop102.yinzhengjie.org.cn's password: Number of key(s) added: 1 Now try logging into the machine, with: "ssh 'hadoop102.yinzhengjie.org.cn'" and check to make sure that only the key(s) you wanted were added. [root@hadoop105.yinzhengjie.org.cn ~]# [root@hadoop105.yinzhengjie.org.cn ~]# ssh hadoop102.yinzhengjie.org.cn Last failed login: Tue Jun 30 03:49:58 CST 2020 from 172.200.4.105 on ssh:notty There were 2 failed login attempts since the last successful login. Last login: Tue Jun 30 03:47:46 2020 from 172.200.4.101 [root@hadoop102.yinzhengjie.org.cn ~]# [root@hadoop102.yinzhengjie.org.cn ~]# who root pts/0 2020-06-30 03:56 (172.200.4.105) [root@hadoop102.yinzhengjie.org.cn ~]# [root@hadoop102.yinzhengjie.org.cn ~]# exit logout Connection to hadoop102.yinzhengjie.org.cn closed. [root@hadoop105.yinzhengjie.org.cn ~]# [root@hadoop105.yinzhengjie.org.cn ~]# who root pts/0 2020-06-30 03:38 (172.200.0.1) [root@hadoop105.yinzhengjie.org.cn ~]# [root@hadoop105.yinzhengjie.org.cn ~]#
[root@hadoop105.yinzhengjie.org.cn ~]# ssh-copy-id hadoop103.yinzhengjie.org.cn /usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/root/.ssh/id_rsa.pub" /usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed /usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys root@hadoop103.yinzhengjie.org.cn's password: Number of key(s) added: 1 Now try logging into the machine, with: "ssh 'hadoop103.yinzhengjie.org.cn'" and check to make sure that only the key(s) you wanted were added. [root@hadoop105.yinzhengjie.org.cn ~]# [root@hadoop105.yinzhengjie.org.cn ~]# who root pts/0 2020-06-30 03:38 (172.200.0.1) [root@hadoop105.yinzhengjie.org.cn ~]# [root@hadoop105.yinzhengjie.org.cn ~]# ssh hadoop103.yinzhengjie.org.cn Last failed login: Tue Jun 30 03:49:58 CST 2020 from 172.200.4.105 on ssh:notty There were 2 failed login attempts since the last successful login. Last login: Tue Jun 30 03:47:46 2020 from 172.200.4.101 [root@hadoop103.yinzhengjie.org.cn ~]# [root@hadoop103.yinzhengjie.org.cn ~]# who root pts/0 2020-06-30 03:56 (172.200.4.105) [root@hadoop103.yinzhengjie.org.cn ~]# [root@hadoop103.yinzhengjie.org.cn ~]# exit logout Connection to hadoop103.yinzhengjie.org.cn closed. [root@hadoop105.yinzhengjie.org.cn ~]# [root@hadoop105.yinzhengjie.org.cn ~]# who root pts/0 2020-06-30 03:38 (172.200.0.1) [root@hadoop105.yinzhengjie.org.cn ~]# [root@hadoop105.yinzhengjie.org.cn ~]#
[root@hadoop105.yinzhengjie.org.cn ~]# ssh-copy-id hadoop104.yinzhengjie.org.cn /usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/root/.ssh/id_rsa.pub" /usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed /usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys root@hadoop104.yinzhengjie.org.cn's password: Number of key(s) added: 1 Now try logging into the machine, with: "ssh 'hadoop104.yinzhengjie.org.cn'" and check to make sure that only the key(s) you wanted were added. [root@hadoop105.yinzhengjie.org.cn ~]# [root@hadoop105.yinzhengjie.org.cn ~]# who root pts/0 2020-06-30 03:38 (172.200.0.1) [root@hadoop105.yinzhengjie.org.cn ~]# [root@hadoop105.yinzhengjie.org.cn ~]# ssh hadoop104.yinzhengjie.org.cn Last login: Tue Jun 30 03:57:23 2020 from 172.200.4.105 [root@hadoop104.yinzhengjie.org.cn ~]# [root@hadoop104.yinzhengjie.org.cn ~]# who root pts/0 2020-06-30 03:58 (172.200.4.105) [root@hadoop104.yinzhengjie.org.cn ~]# [root@hadoop104.yinzhengjie.org.cn ~]# exit logout Connection to hadoop104.yinzhengjie.org.cn closed. [root@hadoop105.yinzhengjie.org.cn ~]# [root@hadoop105.yinzhengjie.org.cn ~]# who root pts/0 2020-06-30 03:38 (172.200.0.1) [root@hadoop105.yinzhengjie.org.cn ~]#
[root@hadoop105.yinzhengjie.org.cn ~]# ssh-copy-id hadoop105.yinzhengjie.org.cn /usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/root/.ssh/id_rsa.pub" The authenticity of host 'hadoop105.yinzhengjie.org.cn (172.200.4.105)' can't be established. ECDSA key fingerprint is SHA256:y6iS5ipSyWSGRmgcjivbWhd78pKfrcuQHeBPd5H9/U8. ECDSA key fingerprint is MD5:da:0f:2a:93:c0:d4:6e:7e:13:16:61:f1:93:a7:38:01. Are you sure you want to continue connecting (yes/no)? yes /usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed /usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys root@hadoop105.yinzhengjie.org.cn's password: Number of key(s) added: 1 Now try logging into the machine, with: "ssh 'hadoop105.yinzhengjie.org.cn'" and check to make sure that only the key(s) you wanted were added. [root@hadoop105.yinzhengjie.org.cn ~]# [root@hadoop105.yinzhengjie.org.cn ~]# ssh hadoop105.yinzhengjie.org.cn Last login: Tue Jun 30 03:47:46 2020 from 172.200.4.101 [root@hadoop105.yinzhengjie.org.cn ~]# [root@hadoop105.yinzhengjie.org.cn ~]# who root pts/0 2020-06-30 03:38 (172.200.0.1) root pts/1 2020-06-30 03:58 (172.200.4.105) [root@hadoop105.yinzhengjie.org.cn ~]# [root@hadoop105.yinzhengjie.org.cn ~]# exit logout Connection to hadoop105.yinzhengjie.org.cn closed. [root@hadoop105.yinzhengjie.org.cn ~]# [root@hadoop105.yinzhengjie.org.cn ~]# who root pts/0 2020-06-30 03:38 (172.200.0.1) [root@hadoop105.yinzhengjie.org.cn ~]# [root@hadoop105.yinzhengjie.org.cn ~]#
[root@hadoop105.yinzhengjie.org.cn ~]# ssh-copy-id hadoop106.yinzhengjie.org.cn /usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/root/.ssh/id_rsa.pub" /usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed /usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys root@hadoop106.yinzhengjie.org.cn's password: Number of key(s) added: 1 Now try logging into the machine, with: "ssh 'hadoop106.yinzhengjie.org.cn'" and check to make sure that only the key(s) you wanted were added. [root@hadoop105.yinzhengjie.org.cn ~]# [root@hadoop105.yinzhengjie.org.cn ~]# who root pts/0 2020-06-30 03:38 (172.200.0.1) [root@hadoop105.yinzhengjie.org.cn ~]# [root@hadoop105.yinzhengjie.org.cn ~]# ssh hadoop106.yinzhengjie.org.cn Last failed login: Tue Jun 30 03:49:58 CST 2020 from 172.200.4.105 on ssh:notty There were 2 failed login attempts since the last successful login. Last login: Tue Jun 30 03:47:47 2020 from 172.200.4.101 [root@hadoop106.yinzhengjie.org.cn ~]# [root@hadoop106.yinzhengjie.org.cn ~]# who root pts/0 2020-06-30 03:59 (172.200.4.105) [root@hadoop106.yinzhengjie.org.cn ~]# [root@hadoop106.yinzhengjie.org.cn ~]# exit logout Connection to hadoop106.yinzhengjie.org.cn closed. [root@hadoop105.yinzhengjie.org.cn ~]# [root@hadoop105.yinzhengjie.org.cn ~]# who root pts/0 2020-06-30 03:38 (172.200.0.1) [root@hadoop105.yinzhengjie.org.cn ~]# [root@hadoop105.yinzhengjie.org.cn ~]#
3>.温馨提示
本篇博客部署的节点和部署Hadoop机器复用了,因为后期是想部署spark On YARN运行模式,但在部署standalone时可以先关闭Hadoop相关服务哟~ Apache Hadoop HDFS高可用部署实战案例: https://www.cnblogs.com/yinzhengjie2020/p/12508145.html
二.部署spark
1>.下载spark二进制安装包
下载Spark地址: http://spark.apache.org/downloads.html
2>.解压spark到指定路径
[root@hadoop101.yinzhengjie.org.cn ~]# ll total 227752 -rw-r--r-- 1 root root 233215067 Jun 27 23:33 spark-2.4.6-bin-hadoop2.7.tgz [root@hadoop101.yinzhengjie.org.cn ~]# [root@hadoop101.yinzhengjie.org.cn ~]# tar -zxf spark-2.4.6-bin-hadoop2.7.tgz -C /yinzhengjie/softwares/ [root@hadoop101.yinzhengjie.org.cn ~]# [root@hadoop101.yinzhengjie.org.cn ~]# ll /yinzhengjie/softwares/spark-2.4.6-bin-hadoop2.7/ total 104 drwxr-xr-x 2 yinzhengjie yinzhengjie 4096 May 30 08:02 bin drwxr-xr-x 2 yinzhengjie yinzhengjie 230 May 30 08:02 conf drwxr-xr-x 5 yinzhengjie yinzhengjie 50 May 30 08:02 data drwxr-xr-x 4 yinzhengjie yinzhengjie 29 May 30 08:02 examples drwxr-xr-x 2 yinzhengjie yinzhengjie 12288 May 30 08:02 jars drwxr-xr-x 4 yinzhengjie yinzhengjie 38 May 30 08:02 kubernetes -rw-r--r-- 1 yinzhengjie yinzhengjie 21371 May 30 08:02 LICENSE drwxr-xr-x 2 yinzhengjie yinzhengjie 4096 May 30 08:02 licenses -rw-r--r-- 1 yinzhengjie yinzhengjie 42919 May 30 08:02 NOTICE drwxr-xr-x 9 yinzhengjie yinzhengjie 311 May 30 08:02 python drwxr-xr-x 3 yinzhengjie yinzhengjie 17 May 30 08:02 R -rw-r--r-- 1 yinzhengjie yinzhengjie 3756 May 30 08:02 README.md -rw-r--r-- 1 yinzhengjie yinzhengjie 187 May 30 08:02 RELEASE drwxr-xr-x 2 yinzhengjie yinzhengjie 4096 May 30 08:02 sbin drwxr-xr-x 2 yinzhengjie yinzhengjie 42 May 30 08:02 yarn [root@hadoop101.yinzhengjie.org.cn ~]#
3>.创建符号链接
[root@hadoop101.yinzhengjie.org.cn ~]# ll /yinzhengjie/softwares/spark-2.4.6-bin-hadoop2.7/ total 104 drwxr-xr-x 2 yinzhengjie yinzhengjie 4096 May 30 08:02 bin drwxr-xr-x 2 yinzhengjie yinzhengjie 230 May 30 08:02 conf drwxr-xr-x 5 yinzhengjie yinzhengjie 50 May 30 08:02 data drwxr-xr-x 4 yinzhengjie yinzhengjie 29 May 30 08:02 examples drwxr-xr-x 2 yinzhengjie yinzhengjie 12288 May 30 08:02 jars drwxr-xr-x 4 yinzhengjie yinzhengjie 38 May 30 08:02 kubernetes -rw-r--r-- 1 yinzhengjie yinzhengjie 21371 May 30 08:02 LICENSE drwxr-xr-x 2 yinzhengjie yinzhengjie 4096 May 30 08:02 licenses -rw-r--r-- 1 yinzhengjie yinzhengjie 42919 May 30 08:02 NOTICE drwxr-xr-x 9 yinzhengjie yinzhengjie 311 May 30 08:02 python drwxr-xr-x 3 yinzhengjie yinzhengjie 17 May 30 08:02 R -rw-r--r-- 1 yinzhengjie yinzhengjie 3756 May 30 08:02 README.md -rw-r--r-- 1 yinzhengjie yinzhengjie 187 May 30 08:02 RELEASE drwxr-xr-x 2 yinzhengjie yinzhengjie 4096 May 30 08:02 sbin drwxr-xr-x 2 yinzhengjie yinzhengjie 42 May 30 08:02 yarn [root@hadoop101.yinzhengjie.org.cn ~]# [root@hadoop101.yinzhengjie.org.cn ~]# ln -sv /yinzhengjie/softwares/spark-2.4.6-bin-hadoop2.7/ /yinzhengjie/softwares/spark ‘/yinzhengjie/softwares/spark’ -> ‘/yinzhengjie/softwares/spark-2.4.6-bin-hadoop2.7/’ [root@hadoop101.yinzhengjie.org.cn ~]# [root@hadoop101.yinzhengjie.org.cn ~]# ll /yinzhengjie/softwares/spark lrwxrwxrwx 1 root root 49 Jun 28 02:24 /yinzhengjie/softwares/spark -> /yinzhengjie/softwares/spark-2.4.6-bin-hadoop2.7/ [root@hadoop101.yinzhengjie.org.cn ~]# [root@hadoop101.yinzhengjie.org.cn ~]# [root@hadoop101.yinzhengjie.org.cn ~]# ll /yinzhengjie/softwares/spark/ total 104 drwxr-xr-x 2 yinzhengjie yinzhengjie 4096 May 30 08:02 bin drwxr-xr-x 2 yinzhengjie yinzhengjie 230 May 30 08:02 conf drwxr-xr-x 5 yinzhengjie yinzhengjie 50 May 30 08:02 data drwxr-xr-x 4 yinzhengjie yinzhengjie 29 May 30 08:02 examples drwxr-xr-x 2 yinzhengjie yinzhengjie 12288 May 30 08:02 jars drwxr-xr-x 4 yinzhengjie yinzhengjie 38 May 30 08:02 kubernetes -rw-r--r-- 1 yinzhengjie yinzhengjie 21371 May 30 08:02 LICENSE drwxr-xr-x 2 yinzhengjie yinzhengjie 4096 May 30 08:02 licenses -rw-r--r-- 1 yinzhengjie yinzhengjie 42919 May 30 08:02 NOTICE drwxr-xr-x 9 yinzhengjie yinzhengjie 311 May 30 08:02 python drwxr-xr-x 3 yinzhengjie yinzhengjie 17 May 30 08:02 R -rw-r--r-- 1 yinzhengjie yinzhengjie 3756 May 30 08:02 README.md -rw-r--r-- 1 yinzhengjie yinzhengjie 187 May 30 08:02 RELEASE drwxr-xr-x 2 yinzhengjie yinzhengjie 4096 May 30 08:02 sbin drwxr-xr-x 2 yinzhengjie yinzhengjie 42 May 30 08:02 yarn [root@hadoop101.yinzhengjie.org.cn ~]# [root@hadoop101.yinzhengjie.org.cn ~]#
4>.配置spark环境变量
[root@hadoop101.yinzhengjie.org.cn ~]# vim /etc/profile.d/spark.sh [root@hadoop101.yinzhengjie.org.cn ~]# [root@hadoop101.yinzhengjie.org.cn ~]# cat /etc/profile.d/spark.sh #Add ${SPARK_HOME} by yinzhengjie SPARK_HOME=/yinzhengjie/softwares/spark PATH=$PATH:${SPARK_HOME}/bin:${SPARK_HOME}/sbin [root@hadoop101.yinzhengjie.org.cn ~]#
[root@hadoop101.yinzhengjie.org.cn ~]# source /etc/profile.d/spark.sh #使用"source"命令使咱们自定义的环境变量生效 [root@hadoop101.yinzhengjie.org.cn ~]# [root@hadoop101.yinzhengjie.org.cn ~]# spark #输入spark后连续按两下"tab"键如果有自动补齐功能说明环境变量配置生效啦~ spark-class spark-config.sh spark-daemon.sh spark-daemons.sh sparkR spark-shell spark-sql spark-submit [root@hadoop101.yinzhengjie.org.cn ~]# spark
5>.修改spark-env.sh文件,添加配置
[root@hadoop101.yinzhengjie.org.cn ~]# cp /yinzhengjie/softwares/spark/conf/spark-env.sh.template /yinzhengjie/softwares/spark/conf/spark-env.sh #通过模板文件创建spark的配置文件 [root@hadoop101.yinzhengjie.org.cn ~]# [root@hadoop101.yinzhengjie.org.cn ~]# vim /yinzhengjie/softwares/spark/conf/spark-env.sh [root@hadoop101.yinzhengjie.org.cn ~]# [root@hadoop101.yinzhengjie.org.cn ~]# egrep -v "^*#|^$" /yinzhengjie/softwares/spark/conf/spark-env.sh SPARK_MASTER_HOST=hadoop105.yinzhengjie.org.cn SPARK_MASTER_PORT=6000 [root@hadoop101.yinzhengjie.org.cn ~]#
6>.修改slave文件,添加work节点
[root@hadoop101.yinzhengjie.org.cn ~]# cp /yinzhengjie/softwares/spark/conf/slaves.template /yinzhengjie/softwares/spark/conf/slaves [root@hadoop101.yinzhengjie.org.cn ~]# [root@hadoop101.yinzhengjie.org.cn ~]# vim /yinzhengjie/softwares/spark/conf/slaves [root@hadoop101.yinzhengjie.org.cn ~]# [root@hadoop101.yinzhengjie.org.cn ~]# egrep -v "^*#|^$" /yinzhengjie/softwares/spark/conf/slaves hadoop101.yinzhengjie.org.cn hadoop102.yinzhengjie.org.cn hadoop103.yinzhengjie.org.cn hadoop104.yinzhengjie.org.cn hadoop106.yinzhengjie.org.cn [root@hadoop101.yinzhengjie.org.cn ~]#
7>.分发spark软件包
[root@hadoop101.yinzhengjie.org.cn ~]# more `which rsync-hadoop.sh` #!/bin/bash #@author :yinzhengjie #blog:http://www.cnblogs.com/yinzhengjie #EMAIL:y1053419035@qq.com #判断用户是否传参 if [ $# -lt 1 ];then echo "请输入参数"; exit fi #获取文件路径 file=$@ #获取子路径 filename=`basename $file` #获取父路径 dirpath=`dirname $file` #获取完整路径 cd $dirpath fullpath=`pwd -P` #同步文件到DataNode for (( hostId=102;hostId<=106;hostId++ )) do #使终端变绿色 tput setaf 2 echo "******* [hadoop${hostId}.yinzhengjie.org.cn] node starts synchronizing [${file}] *******" #使终端变回原来的颜色,即白灰色 tput setaf 7 #远程执行命令 rsync -lr $filename `whoami`@hadoop${hostId}.yinzhengjie.org.cn:${fullpath} & #判断命令是否执行成功 if [ $? == 0 ];then echo "命令执行成功" fi done [root@hadoop101.yinzhengjie.org.cn ~]#
[root@hadoop101.yinzhengjie.org.cn ~]# rsync-hadoop.sh /yinzhengjie/softwares/spark ******* [hadoop102.yinzhengjie.org.cn] node starts synchronizing [/yinzhengjie/softwares/spark] ******* 命令执行成功 ******* [hadoop103.yinzhengjie.org.cn] node starts synchronizing [/yinzhengjie/softwares/spark] ******* 命令执行成功 ******* [hadoop104.yinzhengjie.org.cn] node starts synchronizing [/yinzhengjie/softwares/spark] ******* 命令执行成功 ******* [hadoop105.yinzhengjie.org.cn] node starts synchronizing [/yinzhengjie/softwares/spark] ******* 命令执行成功 ******* [hadoop106.yinzhengjie.org.cn] node starts synchronizing [/yinzhengjie/softwares/spark] ******* 命令执行成功 [root@hadoop101.yinzhengjie.org.cn ~]#
[root@hadoop101.yinzhengjie.org.cn ~]# rsync-hadoop.sh /yinzhengjie/softwares/spark-2.4.6-bin-hadoop2.7/ ******* [hadoop102.yinzhengjie.org.cn] node starts synchronizing [/yinzhengjie/softwares/spark-2.4.6-bin-hadoop2.7/] ******* 命令执行成功 ******* [hadoop103.yinzhengjie.org.cn] node starts synchronizing [/yinzhengjie/softwares/spark-2.4.6-bin-hadoop2.7/] ******* 命令执行成功 ******* [hadoop104.yinzhengjie.org.cn] node starts synchronizing [/yinzhengjie/softwares/spark-2.4.6-bin-hadoop2.7/] ******* 命令执行成功 ******* [hadoop105.yinzhengjie.org.cn] node starts synchronizing [/yinzhengjie/softwares/spark-2.4.6-bin-hadoop2.7/] ******* 命令执行成功 ******* [hadoop106.yinzhengjie.org.cn] node starts synchronizing [/yinzhengjie/softwares/spark-2.4.6-bin-hadoop2.7/] ******* 命令执行成功 [root@hadoop101.yinzhengjie.org.cn ~]#
[root@hadoop101.yinzhengjie.org.cn ~]# rsync-hadoop.sh /etc/profile.d/spark.sh ******* [hadoop102.yinzhengjie.org.cn] node starts synchronizing [/etc/profile.d/spark.sh] ******* 命令执行成功 ******* [hadoop103.yinzhengjie.org.cn] node starts synchronizing [/etc/profile.d/spark.sh] ******* 命令执行成功 ******* [hadoop104.yinzhengjie.org.cn] node starts synchronizing [/etc/profile.d/spark.sh] ******* 命令执行成功 ******* [hadoop105.yinzhengjie.org.cn] node starts synchronizing [/etc/profile.d/spark.sh] ******* 命令执行成功 ******* [hadoop106.yinzhengjie.org.cn] node starts synchronizing [/etc/profile.d/spark.sh] ******* 命令执行成功 [root@hadoop101.yinzhengjie.org.cn ~]#
[root@hadoop101.yinzhengjie.org.cn ~]# ansible all -m shell -a 'du -sh /yinzhengjie/softwares/spark/' hadoop101.yinzhengjie.org.cn | SUCCESS | rc=0 >> 254M /yinzhengjie/softwares/spark/ hadoop105.yinzhengjie.org.cn | SUCCESS | rc=0 >> 254M /yinzhengjie/softwares/spark/ hadoop102.yinzhengjie.org.cn | SUCCESS | rc=0 >> 254M /yinzhengjie/softwares/spark/ hadoop103.yinzhengjie.org.cn | SUCCESS | rc=0 >> 254M /yinzhengjie/softwares/spark/ hadoop104.yinzhengjie.org.cn | SUCCESS | rc=0 >> 254M /yinzhengjie/softwares/spark/ hadoop106.yinzhengjie.org.cn | SUCCESS | rc=0 >> 254M /yinzhengjie/softwares/spark/ [root@hadoop101.yinzhengjie.org.cn ~]#
8>.在master节点启动spark集群
[root@hadoop101.yinzhengjie.org.cn ~]# ansible all -m shell -a 'jps' hadoop101.yinzhengjie.org.cn | SUCCESS | rc=0 >> 6231 Jps hadoop105.yinzhengjie.org.cn | SUCCESS | rc=0 >> 6018 Jps hadoop104.yinzhengjie.org.cn | SUCCESS | rc=0 >> 5670 Jps hadoop102.yinzhengjie.org.cn | SUCCESS | rc=0 >> 5661 Jps hadoop103.yinzhengjie.org.cn | SUCCESS | rc=0 >> 5741 Jps hadoop106.yinzhengjie.org.cn | SUCCESS | rc=0 >> 5676 Jps [root@hadoop101.yinzhengjie.org.cn ~]#
[root@hadoop105.yinzhengjie.org.cn ~]# jps 6034 Jps [root@hadoop105.yinzhengjie.org.cn ~]# [root@hadoop105.yinzhengjie.org.cn ~]# /yinzhengjie/softwares/spark/sbin/start-all.sh starting org.apache.spark.deploy.master.Master, logging to /yinzhengjie/softwares/spark/logs/spark-root-org.apache.spark.deploy.master.Master-1-hadoop105.yinzhengjie.org.cn.out hadoop101.yinzhengjie.org.cn: starting org.apache.spark.deploy.worker.Worker, logging to /yinzhengjie/softwares/spark/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-hadoop101.yinzhengjie.org.cn.out hadoop102.yinzhengjie.org.cn: starting org.apache.spark.deploy.worker.Worker, logging to /yinzhengjie/softwares/spark/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-hadoop102.yinzhengjie.org.cn.out hadoop104.yinzhengjie.org.cn: starting org.apache.spark.deploy.worker.Worker, logging to /yinzhengjie/softwares/spark/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-hadoop104.yinzhengjie.org.cn.out hadoop103.yinzhengjie.org.cn: starting org.apache.spark.deploy.worker.Worker, logging to /yinzhengjie/softwares/spark/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-hadoop103.yinzhengjie.org.cn.out hadoop106.yinzhengjie.org.cn: starting org.apache.spark.deploy.worker.Worker, logging to /yinzhengjie/softwares/spark/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-hadoop106.yinzhengjie.org.cn.out [root@hadoop105.yinzhengjie.org.cn ~]# [root@hadoop105.yinzhengjie.org.cn ~]# jps 6066 Master 6132 Jps [root@hadoop105.yinzhengjie.org.cn ~]# [root@hadoop105.yinzhengjie.org.cn ~]#
[root@hadoop101.yinzhengjie.org.cn ~]# ansible all -m shell -a 'jps' hadoop102.yinzhengjie.org.cn | SUCCESS | rc=0 >> 5793 Jps 5700 Worker hadoop104.yinzhengjie.org.cn | SUCCESS | rc=0 >> 5801 Jps 5708 Worker hadoop103.yinzhengjie.org.cn | SUCCESS | rc=0 >> 5875 Jps 5781 Worker hadoop105.yinzhengjie.org.cn | SUCCESS | rc=0 >> 6066 Master 6188 Jps hadoop101.yinzhengjie.org.cn | SUCCESS | rc=0 >> 6442 Jps 6286 Worker hadoop106.yinzhengjie.org.cn | SUCCESS | rc=0 >> 5809 Jps 5715 Worker [root@hadoop101.yinzhengjie.org.cn ~]#
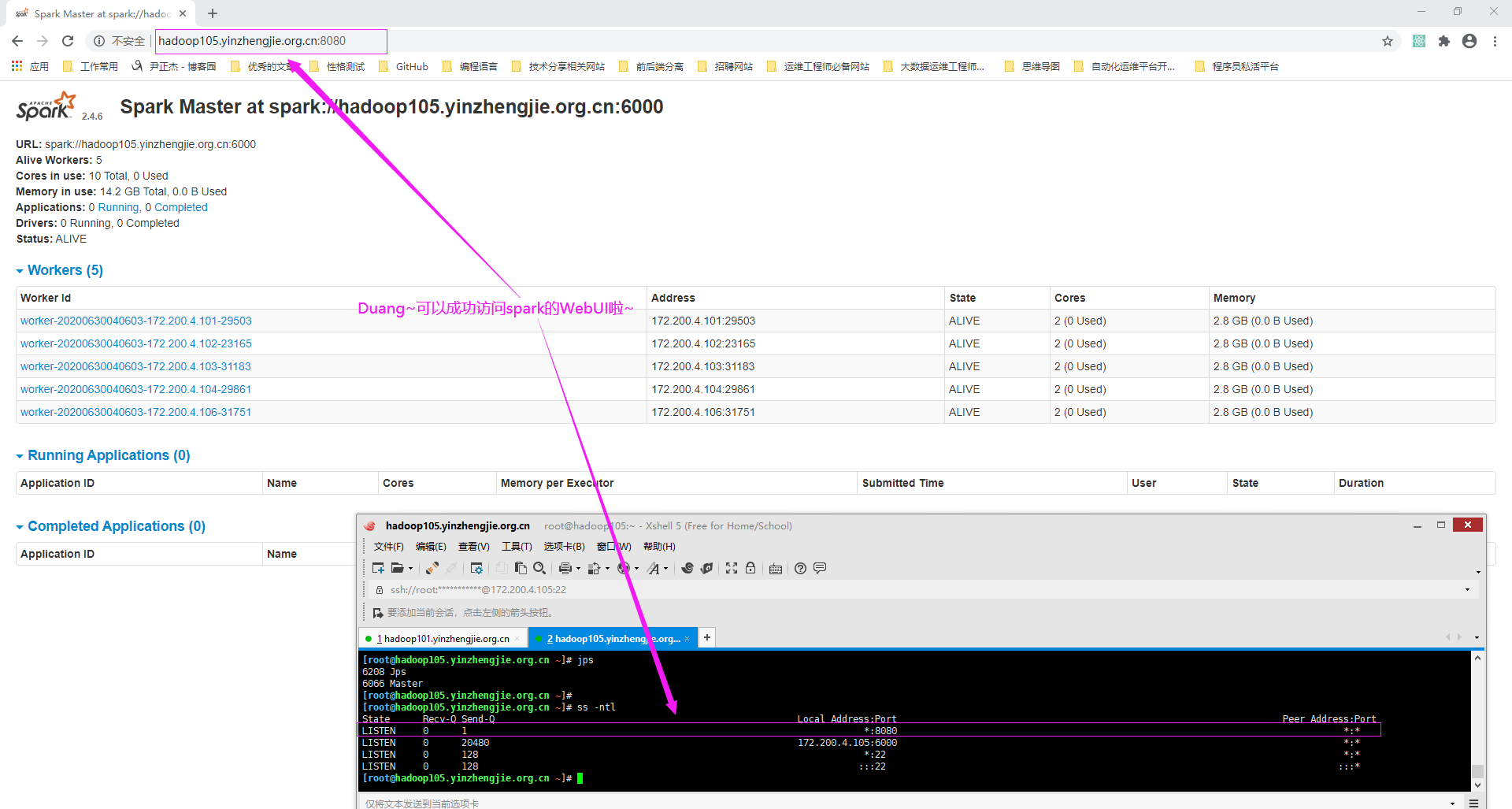
9>.访问spark的WebUI
如下图所示,浏览器访问Master的8080端口: http://hadoop105.yinzhengjie.org.cn:8080/
三.使用spark案例
1>.官方求圆周率案例
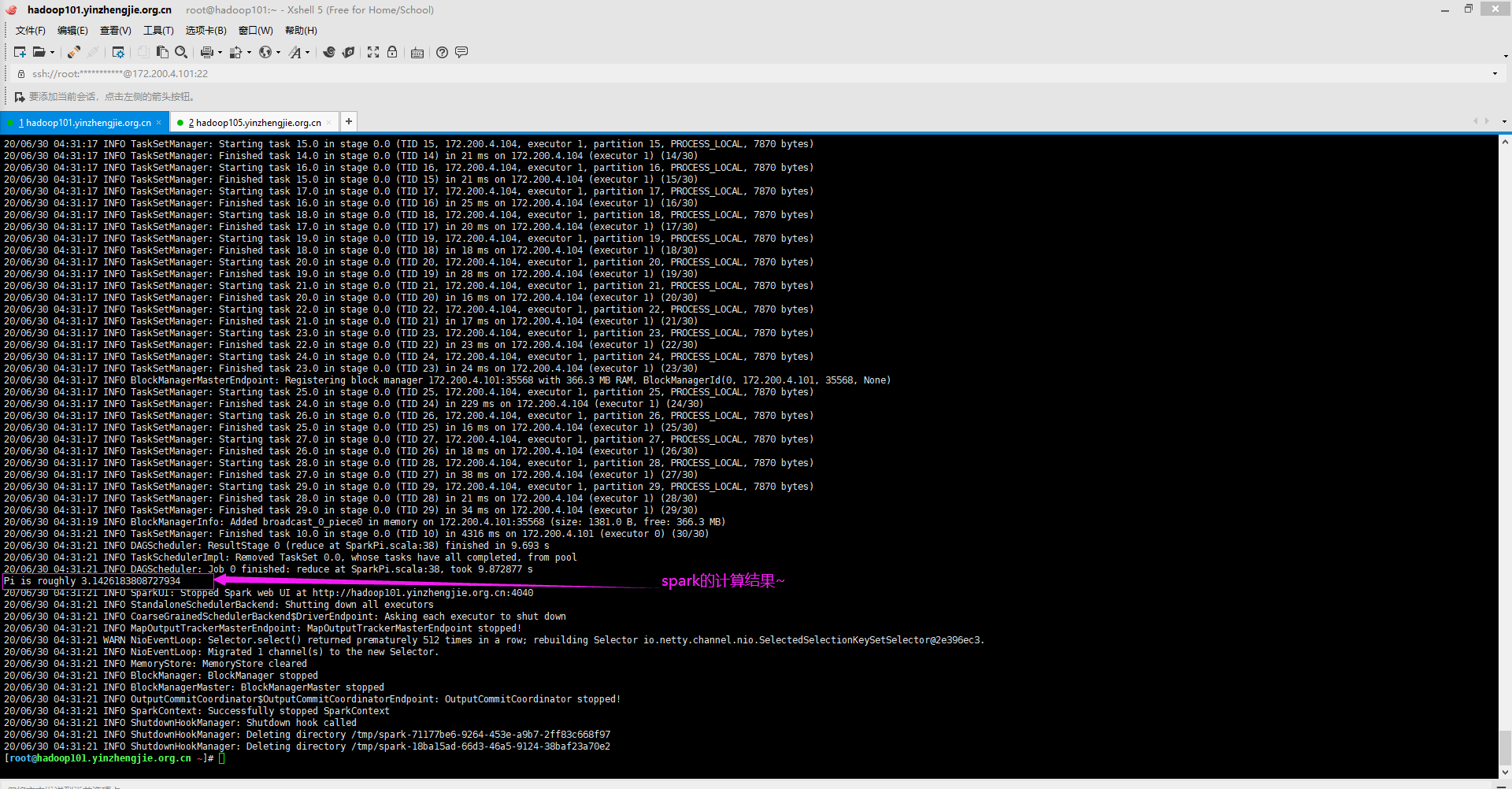
[root@hadoop101.yinzhengjie.org.cn ~]# spark-submit > --class org.apache.spark.examples.SparkPi > --master spark://hadoop105.yinzhengjie.org.cn:6000 > --executor-memory 1G > --total-executor-cores 2 > /yinzhengjie/softwares/spark/examples/jars/spark-examples_2.11-2.4.6.jar > 30 20/06/30 04:31:05 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties 20/06/30 04:31:06 INFO SparkContext: Running Spark version 2.4.6 20/06/30 04:31:06 INFO SparkContext: Submitted application: Spark Pi 20/06/30 04:31:06 INFO SecurityManager: Changing view acls to: root 20/06/30 04:31:06 INFO SecurityManager: Changing modify acls to: root 20/06/30 04:31:06 INFO SecurityManager: Changing view acls groups to: 20/06/30 04:31:06 INFO SecurityManager: Changing modify acls groups to: 20/06/30 04:31:06 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(root); groups with view permissions: Set(); users with modify permissions: Set(root); groups with modify permissions: Set() 20/06/30 04:31:06 INFO Utils: Successfully started service 'sparkDriver' on port 27414. 20/06/30 04:31:06 INFO SparkEnv: Registering MapOutputTracker 20/06/30 04:31:06 INFO SparkEnv: Registering BlockManagerMaster 20/06/30 04:31:06 INFO BlockManagerMasterEndpoint: Using org.apache.spark.storage.DefaultTopologyMapper for getting topology information 20/06/30 04:31:06 INFO BlockManagerMasterEndpoint: BlockManagerMasterEndpoint up 20/06/30 04:31:06 INFO DiskBlockManager: Created local directory at /tmp/blockmgr-7e648acd-ac27-46f8-a9e9-854a33f5aefa 20/06/30 04:31:06 INFO MemoryStore: MemoryStore started with capacity 366.3 MB 20/06/30 04:31:06 INFO SparkEnv: Registering OutputCommitCoordinator 20/06/30 04:31:06 INFO Utils: Successfully started service 'SparkUI' on port 4040. 20/06/30 04:31:06 INFO SparkUI: Bound SparkUI to 0.0.0.0, and started at http://hadoop101.yinzhengjie.org.cn:4040 20/06/30 04:31:07 INFO SparkContext: Added JAR file:/yinzhengjie/softwares/spark/examples/jars/spark-examples_2.11-2.4.6.jar at spark://hadoop101.yinzhengjie.org.cn:27414/jars/spark-examples_2.11-2.4.6.jar with timestamp 1593462667087 20/06/30 04:31:07 INFO StandaloneAppClient$ClientEndpoint: Connecting to master spark://hadoop105.yinzhengjie.org.cn:6000... 20/06/30 04:31:07 INFO TransportClientFactory: Successfully created connection to hadoop105.yinzhengjie.org.cn/172.200.4.105:6000 after 103 ms (0 ms spent in bootstraps) 20/06/30 04:31:07 INFO StandaloneSchedulerBackend: Connected to Spark cluster with app ID app-20200630043107-0000 20/06/30 04:31:07 INFO Utils: Successfully started service 'org.apache.spark.network.netty.NettyBlockTransferService' on port 32180. 20/06/30 04:31:07 INFO NettyBlockTransferService: Server created on hadoop101.yinzhengjie.org.cn:32180 20/06/30 04:31:07 INFO BlockManager: Using org.apache.spark.storage.RandomBlockReplicationPolicy for block replication policy 20/06/30 04:31:07 INFO StandaloneAppClient$ClientEndpoint: Executor added: app-20200630043107-0000/0 on worker-20200630040603-172.200.4.101-29503 (172.200.4.101:29503) with 1 core(s) 20/06/30 04:31:07 INFO StandaloneSchedulerBackend: Granted executor ID app-20200630043107-0000/0 on hostPort 172.200.4.101:29503 with 1 core(s), 1024.0 MB RAM 20/06/30 04:31:07 INFO StandaloneAppClient$ClientEndpoint: Executor added: app-20200630043107-0000/1 on worker-20200630040603-172.200.4.104-29861 (172.200.4.104:29861) with 1 core(s) 20/06/30 04:31:07 INFO StandaloneSchedulerBackend: Granted executor ID app-20200630043107-0000/1 on hostPort 172.200.4.104:29861 with 1 core(s), 1024.0 MB RAM 20/06/30 04:31:07 INFO BlockManagerMaster: Registering BlockManager BlockManagerId(driver, hadoop101.yinzhengjie.org.cn, 32180, None) 20/06/30 04:31:07 INFO BlockManagerMasterEndpoint: Registering block manager hadoop101.yinzhengjie.org.cn:32180 with 366.3 MB RAM, BlockManagerId(driver, hadoop101.yinzhengjie.org.cn, 32180, None) 20/06/30 04:31:07 INFO StandaloneAppClient$ClientEndpoint: Executor updated: app-20200630043107-0000/1 is now RUNNING 20/06/30 04:31:08 INFO BlockManagerMaster: Registered BlockManager BlockManagerId(driver, hadoop101.yinzhengjie.org.cn, 32180, None) 20/06/30 04:31:08 INFO BlockManager: Initialized BlockManager: BlockManagerId(driver, hadoop101.yinzhengjie.org.cn, 32180, None) 20/06/30 04:31:08 INFO StandaloneAppClient$ClientEndpoint: Executor updated: app-20200630043107-0000/0 is now RUNNING 20/06/30 04:31:08 INFO StandaloneSchedulerBackend: SchedulerBackend is ready for scheduling beginning after reached minRegisteredResourcesRatio: 0.0 20/06/30 04:31:11 INFO SparkContext: Starting job: reduce at SparkPi.scala:38 20/06/30 04:31:11 INFO DAGScheduler: Got job 0 (reduce at SparkPi.scala:38) with 30 output partitions 20/06/30 04:31:11 INFO DAGScheduler: Final stage: ResultStage 0 (reduce at SparkPi.scala:38) 20/06/30 04:31:11 INFO DAGScheduler: Parents of final stage: List() 20/06/30 04:31:11 INFO DAGScheduler: Missing parents: List() 20/06/30 04:31:11 INFO DAGScheduler: Submitting ResultStage 0 (MapPartitionsRDD[1] at map at SparkPi.scala:34), which has no missing parents 20/06/30 04:31:12 INFO CoarseGrainedSchedulerBackend$DriverEndpoint: Registered executor NettyRpcEndpointRef(spark-client://Executor) (172.200.4.104:43415) with ID 1 20/06/30 04:31:12 INFO MemoryStore: Block broadcast_0 stored as values in memory (estimated size 2.0 KB, free 366.3 MB) 20/06/30 04:31:12 INFO MemoryStore: Block broadcast_0_piece0 stored as bytes in memory (estimated size 1381.0 B, free 366.3 MB) 20/06/30 04:31:12 INFO BlockManagerInfo: Added broadcast_0_piece0 in memory on hadoop101.yinzhengjie.org.cn:32180 (size: 1381.0 B, free: 366.3 MB) 20/06/30 04:31:12 INFO SparkContext: Created broadcast 0 from broadcast at DAGScheduler.scala:1163 20/06/30 04:31:12 INFO DAGScheduler: Submitting 30 missing tasks from ResultStage 0 (MapPartitionsRDD[1] at map at SparkPi.scala:34) (first 15 tasks are for partitions Vector(0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14)) 20/06/30 04:31:12 INFO TaskSchedulerImpl: Adding task set 0.0 with 30 tasks 20/06/30 04:31:12 INFO BlockManagerMasterEndpoint: Registering block manager 172.200.4.104:31581 with 366.3 MB RAM, BlockManagerId(1, 172.200.4.104, 31581, None) 20/06/30 04:31:12 INFO TaskSetManager: Starting task 0.0 in stage 0.0 (TID 0, 172.200.4.104, executor 1, partition 0, PROCESS_LOCAL, 7870 bytes) 20/06/30 04:31:15 INFO BlockManagerInfo: Added broadcast_0_piece0 in memory on 172.200.4.104:31581 (size: 1381.0 B, free: 366.3 MB) 20/06/30 04:31:15 INFO TaskSetManager: Starting task 1.0 in stage 0.0 (TID 1, 172.200.4.104, executor 1, partition 1, PROCESS_LOCAL, 7870 bytes) 20/06/30 04:31:15 INFO TaskSetManager: Finished task 0.0 in stage 0.0 (TID 0) in 2925 ms on 172.200.4.104 (executor 1) (1/30) 20/06/30 04:31:15 INFO TaskSetManager: Starting task 2.0 in stage 0.0 (TID 2, 172.200.4.104, executor 1, partition 2, PROCESS_LOCAL, 7870 bytes) 20/06/30 04:31:15 INFO TaskSetManager: Finished task 1.0 in stage 0.0 (TID 1) in 95 ms on 172.200.4.104 (executor 1) (2/30) 20/06/30 04:31:15 INFO TaskSetManager: Starting task 3.0 in stage 0.0 (TID 3, 172.200.4.104, executor 1, partition 3, PROCESS_LOCAL, 7870 bytes) 20/06/30 04:31:15 INFO TaskSetManager: Finished task 2.0 in stage 0.0 (TID 2) in 160 ms on 172.200.4.104 (executor 1) (3/30) 20/06/30 04:31:15 INFO TaskSetManager: Starting task 4.0 in stage 0.0 (TID 4, 172.200.4.104, executor 1, partition 4, PROCESS_LOCAL, 7870 bytes) 20/06/30 04:31:15 INFO TaskSetManager: Finished task 3.0 in stage 0.0 (TID 3) in 34 ms on 172.200.4.104 (executor 1) (4/30) 20/06/30 04:31:15 INFO TaskSetManager: Starting task 5.0 in stage 0.0 (TID 5, 172.200.4.104, executor 1, partition 5, PROCESS_LOCAL, 7870 bytes) 20/06/30 04:31:15 INFO TaskSetManager: Finished task 4.0 in stage 0.0 (TID 4) in 31 ms on 172.200.4.104 (executor 1) (5/30) 20/06/30 04:31:15 INFO TaskSetManager: Starting task 6.0 in stage 0.0 (TID 6, 172.200.4.104, executor 1, partition 6, PROCESS_LOCAL, 7870 bytes) 20/06/30 04:31:15 INFO TaskSetManager: Finished task 5.0 in stage 0.0 (TID 5) in 23 ms on 172.200.4.104 (executor 1) (6/30) 20/06/30 04:31:16 INFO TaskSetManager: Starting task 7.0 in stage 0.0 (TID 7, 172.200.4.104, executor 1, partition 7, PROCESS_LOCAL, 7870 bytes) 20/06/30 04:31:16 INFO TaskSetManager: Finished task 6.0 in stage 0.0 (TID 6) in 20 ms on 172.200.4.104 (executor 1) (7/30) 20/06/30 04:31:16 INFO TaskSetManager: Starting task 8.0 in stage 0.0 (TID 8, 172.200.4.104, executor 1, partition 8, PROCESS_LOCAL, 7870 bytes) 20/06/30 04:31:16 INFO TaskSetManager: Finished task 7.0 in stage 0.0 (TID 7) in 33 ms on 172.200.4.104 (executor 1) (8/30) 20/06/30 04:31:16 INFO TaskSetManager: Starting task 9.0 in stage 0.0 (TID 9, 172.200.4.104, executor 1, partition 9, PROCESS_LOCAL, 7870 bytes) 20/06/30 04:31:17 INFO TaskSetManager: Finished task 8.0 in stage 0.0 (TID 8) in 1209 ms on 172.200.4.104 (executor 1) (9/30) 20/06/30 04:31:17 INFO CoarseGrainedSchedulerBackend$DriverEndpoint: Registered executor NettyRpcEndpointRef(spark-client://Executor) (172.200.4.101:10051) with ID 0 20/06/30 04:31:17 INFO TaskSetManager: Starting task 10.0 in stage 0.0 (TID 10, 172.200.4.101, executor 0, partition 10, PROCESS_LOCAL, 7870 bytes) 20/06/30 04:31:17 INFO TaskSetManager: Starting task 11.0 in stage 0.0 (TID 11, 172.200.4.104, executor 1, partition 11, PROCESS_LOCAL, 7870 bytes) 20/06/30 04:31:17 INFO TaskSetManager: Finished task 9.0 in stage 0.0 (TID 9) in 1218 ms on 172.200.4.104 (executor 1) (10/30) 20/06/30 04:31:17 INFO TaskSetManager: Starting task 12.0 in stage 0.0 (TID 12, 172.200.4.104, executor 1, partition 12, PROCESS_LOCAL, 7870 bytes) 20/06/30 04:31:17 INFO TaskSetManager: Finished task 11.0 in stage 0.0 (TID 11) in 20 ms on 172.200.4.104 (executor 1) (11/30) 20/06/30 04:31:17 INFO TaskSetManager: Starting task 13.0 in stage 0.0 (TID 13, 172.200.4.104, executor 1, partition 13, PROCESS_LOCAL, 7870 bytes) 20/06/30 04:31:17 INFO TaskSetManager: Finished task 12.0 in stage 0.0 (TID 12) in 27 ms on 172.200.4.104 (executor 1) (12/30) 20/06/30 04:31:17 INFO TaskSetManager: Starting task 14.0 in stage 0.0 (TID 14, 172.200.4.104, executor 1, partition 14, PROCESS_LOCAL, 7870 bytes) 20/06/30 04:31:17 INFO TaskSetManager: Finished task 13.0 in stage 0.0 (TID 13) in 28 ms on 172.200.4.104 (executor 1) (13/30) 20/06/30 04:31:17 INFO TaskSetManager: Starting task 15.0 in stage 0.0 (TID 15, 172.200.4.104, executor 1, partition 15, PROCESS_LOCAL, 7870 bytes) 20/06/30 04:31:17 INFO TaskSetManager: Finished task 14.0 in stage 0.0 (TID 14) in 21 ms on 172.200.4.104 (executor 1) (14/30) 20/06/30 04:31:17 INFO TaskSetManager: Starting task 16.0 in stage 0.0 (TID 16, 172.200.4.104, executor 1, partition 16, PROCESS_LOCAL, 7870 bytes) 20/06/30 04:31:17 INFO TaskSetManager: Finished task 15.0 in stage 0.0 (TID 15) in 21 ms on 172.200.4.104 (executor 1) (15/30) 20/06/30 04:31:17 INFO TaskSetManager: Starting task 17.0 in stage 0.0 (TID 17, 172.200.4.104, executor 1, partition 17, PROCESS_LOCAL, 7870 bytes) 20/06/30 04:31:17 INFO TaskSetManager: Finished task 16.0 in stage 0.0 (TID 16) in 25 ms on 172.200.4.104 (executor 1) (16/30) 20/06/30 04:31:17 INFO TaskSetManager: Starting task 18.0 in stage 0.0 (TID 18, 172.200.4.104, executor 1, partition 18, PROCESS_LOCAL, 7870 bytes) 20/06/30 04:31:17 INFO TaskSetManager: Finished task 17.0 in stage 0.0 (TID 17) in 20 ms on 172.200.4.104 (executor 1) (17/30) 20/06/30 04:31:17 INFO TaskSetManager: Starting task 19.0 in stage 0.0 (TID 19, 172.200.4.104, executor 1, partition 19, PROCESS_LOCAL, 7870 bytes) 20/06/30 04:31:17 INFO TaskSetManager: Finished task 18.0 in stage 0.0 (TID 18) in 18 ms on 172.200.4.104 (executor 1) (18/30) 20/06/30 04:31:17 INFO TaskSetManager: Starting task 20.0 in stage 0.0 (TID 20, 172.200.4.104, executor 1, partition 20, PROCESS_LOCAL, 7870 bytes) 20/06/30 04:31:17 INFO TaskSetManager: Finished task 19.0 in stage 0.0 (TID 19) in 28 ms on 172.200.4.104 (executor 1) (19/30) 20/06/30 04:31:17 INFO TaskSetManager: Starting task 21.0 in stage 0.0 (TID 21, 172.200.4.104, executor 1, partition 21, PROCESS_LOCAL, 7870 bytes) 20/06/30 04:31:17 INFO TaskSetManager: Finished task 20.0 in stage 0.0 (TID 20) in 16 ms on 172.200.4.104 (executor 1) (20/30) 20/06/30 04:31:17 INFO TaskSetManager: Starting task 22.0 in stage 0.0 (TID 22, 172.200.4.104, executor 1, partition 22, PROCESS_LOCAL, 7870 bytes) 20/06/30 04:31:17 INFO TaskSetManager: Finished task 21.0 in stage 0.0 (TID 21) in 17 ms on 172.200.4.104 (executor 1) (21/30) 20/06/30 04:31:17 INFO TaskSetManager: Starting task 23.0 in stage 0.0 (TID 23, 172.200.4.104, executor 1, partition 23, PROCESS_LOCAL, 7870 bytes) 20/06/30 04:31:17 INFO TaskSetManager: Finished task 22.0 in stage 0.0 (TID 22) in 23 ms on 172.200.4.104 (executor 1) (22/30) 20/06/30 04:31:17 INFO TaskSetManager: Starting task 24.0 in stage 0.0 (TID 24, 172.200.4.104, executor 1, partition 24, PROCESS_LOCAL, 7870 bytes) 20/06/30 04:31:17 INFO TaskSetManager: Finished task 23.0 in stage 0.0 (TID 23) in 24 ms on 172.200.4.104 (executor 1) (23/30) 20/06/30 04:31:17 INFO BlockManagerMasterEndpoint: Registering block manager 172.200.4.101:35568 with 366.3 MB RAM, BlockManagerId(0, 172.200.4.101, 35568, None) 20/06/30 04:31:17 INFO TaskSetManager: Starting task 25.0 in stage 0.0 (TID 25, 172.200.4.104, executor 1, partition 25, PROCESS_LOCAL, 7870 bytes) 20/06/30 04:31:17 INFO TaskSetManager: Finished task 24.0 in stage 0.0 (TID 24) in 229 ms on 172.200.4.104 (executor 1) (24/30) 20/06/30 04:31:17 INFO TaskSetManager: Starting task 26.0 in stage 0.0 (TID 26, 172.200.4.104, executor 1, partition 26, PROCESS_LOCAL, 7870 bytes) 20/06/30 04:31:17 INFO TaskSetManager: Finished task 25.0 in stage 0.0 (TID 25) in 16 ms on 172.200.4.104 (executor 1) (25/30) 20/06/30 04:31:17 INFO TaskSetManager: Starting task 27.0 in stage 0.0 (TID 27, 172.200.4.104, executor 1, partition 27, PROCESS_LOCAL, 7870 bytes) 20/06/30 04:31:17 INFO TaskSetManager: Finished task 26.0 in stage 0.0 (TID 26) in 18 ms on 172.200.4.104 (executor 1) (26/30) 20/06/30 04:31:17 INFO TaskSetManager: Starting task 28.0 in stage 0.0 (TID 28, 172.200.4.104, executor 1, partition 28, PROCESS_LOCAL, 7870 bytes) 20/06/30 04:31:17 INFO TaskSetManager: Finished task 27.0 in stage 0.0 (TID 27) in 38 ms on 172.200.4.104 (executor 1) (27/30) 20/06/30 04:31:17 INFO TaskSetManager: Starting task 29.0 in stage 0.0 (TID 29, 172.200.4.104, executor 1, partition 29, PROCESS_LOCAL, 7870 bytes) 20/06/30 04:31:17 INFO TaskSetManager: Finished task 28.0 in stage 0.0 (TID 28) in 21 ms on 172.200.4.104 (executor 1) (28/30) 20/06/30 04:31:17 INFO TaskSetManager: Finished task 29.0 in stage 0.0 (TID 29) in 34 ms on 172.200.4.104 (executor 1) (29/30) 20/06/30 04:31:19 INFO BlockManagerInfo: Added broadcast_0_piece0 in memory on 172.200.4.101:35568 (size: 1381.0 B, free: 366.3 MB) 20/06/30 04:31:21 INFO TaskSetManager: Finished task 10.0 in stage 0.0 (TID 10) in 4316 ms on 172.200.4.101 (executor 0) (30/30) 20/06/30 04:31:21 INFO DAGScheduler: ResultStage 0 (reduce at SparkPi.scala:38) finished in 9.693 s 20/06/30 04:31:21 INFO TaskSchedulerImpl: Removed TaskSet 0.0, whose tasks have all completed, from pool 20/06/30 04:31:21 INFO DAGScheduler: Job 0 finished: reduce at SparkPi.scala:38, took 9.872877 s Pi is roughly 3.1426183808727934 20/06/30 04:31:21 INFO SparkUI: Stopped Spark web UI at http://hadoop101.yinzhengjie.org.cn:4040 20/06/30 04:31:21 INFO StandaloneSchedulerBackend: Shutting down all executors 20/06/30 04:31:21 INFO CoarseGrainedSchedulerBackend$DriverEndpoint: Asking each executor to shut down 20/06/30 04:31:21 INFO MapOutputTrackerMasterEndpoint: MapOutputTrackerMasterEndpoint stopped! 20/06/30 04:31:21 WARN NioEventLoop: Selector.select() returned prematurely 512 times in a row; rebuilding Selector io.netty.channel.nio.SelectedSelectionKeySetSelector@2e396ec3. 20/06/30 04:31:21 INFO NioEventLoop: Migrated 1 channel(s) to the new Selector. 20/06/30 04:31:21 INFO MemoryStore: MemoryStore cleared 20/06/30 04:31:21 INFO BlockManager: BlockManager stopped 20/06/30 04:31:21 INFO BlockManagerMaster: BlockManagerMaster stopped 20/06/30 04:31:21 INFO OutputCommitCoordinator$OutputCommitCoordinatorEndpoint: OutputCommitCoordinator stopped! 20/06/30 04:31:21 INFO SparkContext: Successfully stopped SparkContext 20/06/30 04:31:21 INFO ShutdownHookManager: Shutdown hook called 20/06/30 04:31:21 INFO ShutdownHookManager: Deleting directory /tmp/spark-71177be6-9264-453e-a9b7-2ff83c668f97 20/06/30 04:31:21 INFO ShutdownHookManager: Deleting directory /tmp/spark-18ba15ad-66d3-46a5-9124-38baf23a70e2 [root@hadoop101.yinzhengjie.org.cn ~]#
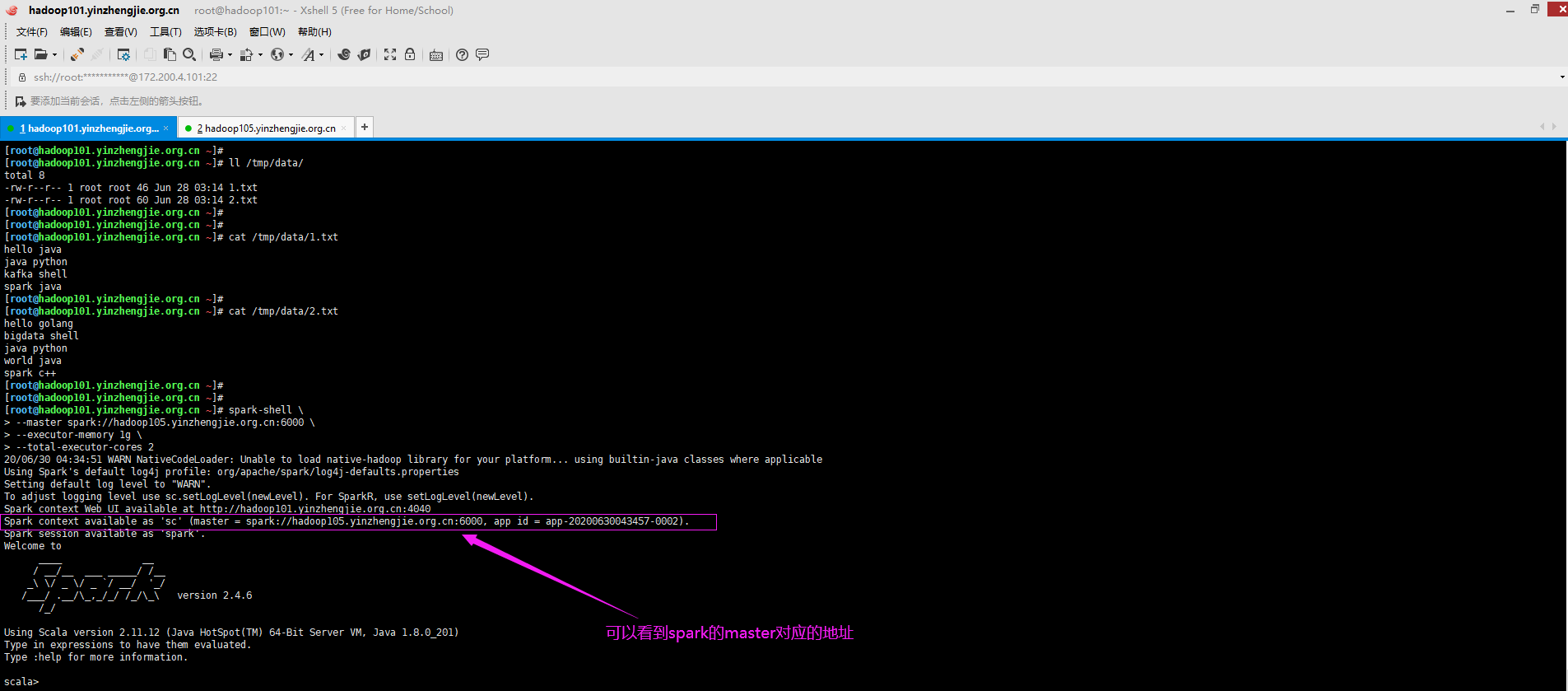
2>.启动spark shell
[root@hadoop101.yinzhengjie.org.cn ~]# spark-shell > --master spark://hadoop105.yinzhengjie.org.cn:6000 > --executor-memory 1g > --total-executor-cores 2 20/06/30 04:34:51 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties Setting default log level to "WARN". To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). Spark context Web UI available at http://hadoop101.yinzhengjie.org.cn:4040 Spark context available as 'sc' (master = spark://hadoop105.yinzhengjie.org.cn:6000, app id = app-20200630043457-0002). Spark session available as 'spark'. Welcome to ____ __ / __/__ ___ _____/ /__ _ / _ / _ `/ __/ '_/ /___/ .__/\_,_/_/ /_/\_ version 2.4.6 /_/ Using Scala version 2.11.12 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_201) Type in expressions to have them evaluated. Type :help for more information. scala>