前言
上篇文章 Redis闲谈(1):构建知识图谱介绍了redis的基本概念、优缺点以及它的内存淘汰机制,相信大家对redis有了初步的认识。互联网的很多应用场景都有着Redis的身影,它能做的事情远远超出了我们的想像。Redis的底层数据结构到底是什么样的呢,为什么它能做这么多的事情?本文将探秘Redis的底层数据结构以及常用的命令。
本文知识脑图如下:
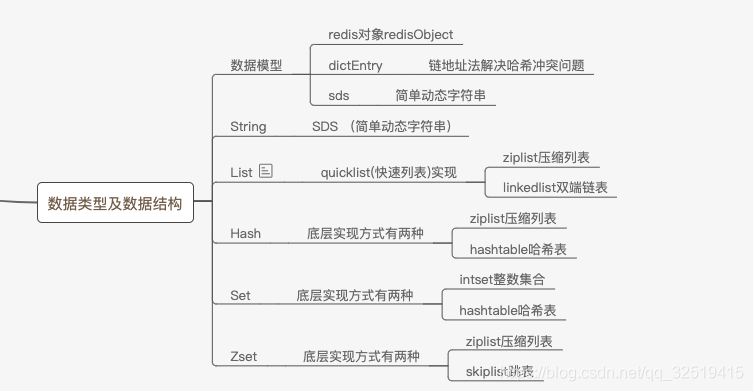
一、Redis的数据模型
用 键值对 name:"小明"来展示Redis的数据模型如下:
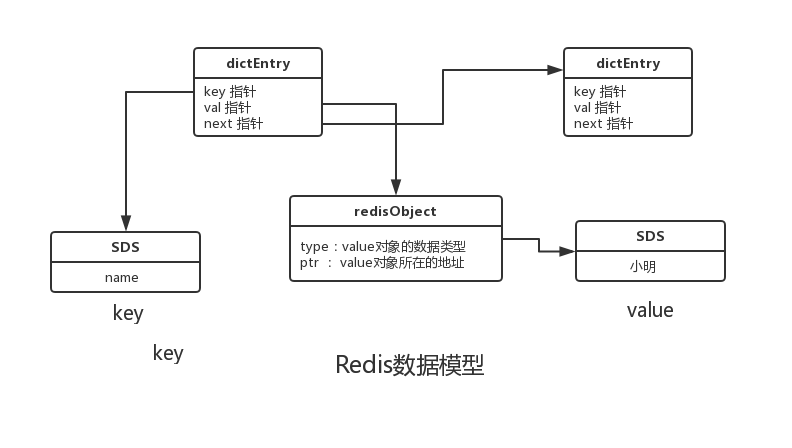
- dictEntry: 在一些编程语言中,键值对的数据结构被称为字典,而在Redis中,会给每一个key-value键值对分配一个字典实体,就是“dicEntry”。dicEntry包含三部分: key的指针、val的指针、next指针,next指针指向下一个dicteEntry形成链表,这个next指针可以将多个哈希值相同的键值对链接在一起,通过链地址法来解决哈希冲突的问题
- sds :Simple Dynamic String,简单动态字符串,存储字符串数据。
- redisObject:Redis的5种常用类型都是以RedisObject来存储的,redisObject中的type字段指明了值的数据类型(也就是5种基本类型)。ptr字段指向对象所在的地址。
RedisObject对象很重要,Redis对象的类型、内部编码、内存回收、共享对象等功能,都是基于RedisObject对象来实现的。
这样设计的好处是:可以针对不同的使用场景,对5种常用类型设置多种不同的数据结构实现,从而优化对象在不同场景下的使用效率。
Redis将jemalloc作为默认内存分配器,减小内存碎片。jemalloc在64位系统中,将内存空间划分为小、大、巨大三个范围;每个范围内又划分了许多小的内存块单位;当Redis存储数据时,会选择大小最合适的内存块进行存储。
二、Redis支持的数据结构
Redis支持的数据结构有哪些?
如果回答是String、List、Hash、Set、Zset就不对了,这5种是redis的常用基本数据类型,每一种数据类型内部还包含着多种数据结构。
用encoding指令来看一个值的数据结构。比如:
127.0.0.1:6379> set name tom OK 127.0.0.1:6379> object encoding name "embstr"
此处设置了name值是tom,它的数据结构是embstr,下文介绍字符串时会详解说明。
127.0.0.1:6379> set age 18 OK 127.0.0.1:6379> object encoding age "int"
如下表格总结Redis中所有的数据结构类型:
| 底层数据结构 | 编码常量 | object encoding指令输出 |
|---|---|---|
| 整数类型 | REDIS_ENCODING_INT | "int" |
| embstr字符串类型 | REDIS_ENCODING_EMBSTR | "embstr" |
| 简单动态字符串 | REDIS_ENCODING_RAW | "raw" |
| 字典类型 | REDIS_ENCODING_HT | "hashtable" |
| 双端链表 | REDIS_ENCODING_LINKEDLIST | "linkedlist" |
| 压缩列表 | REDIS_ENCODING_ZIPLIST | "ziplist" |
| 整数集合 | REDIS_ENCODING_INTSET | "intset" |
| 跳表和字典 | REDIS_ENCODING_SKIPLIST | "skiplist" |
补充说明
假如面试官问:redis的数据类型有哪些?
回答:String、list、hash、set、zet
一般情况下这样回答是正确的,前文也提到redis的数据类型确实是包含这5种,但细心的同学肯定发现了之前说的是“常用”的5种数据类型。其实,随着Redis的不断更新和完善,Redis的数据类型早已不止5种了。
登录redis的官方网站打开官方的数据类型介绍:
https://redis.io/topics/data-types-intro 
发现Redis支持的数据结构不止5种,而是8种,后三种类型分别是:
- 位数组(或简称位图):使用特殊命令可以处理字符串值,如位数组:您可以设置和清除各个位,将所有位设置为1,查找第一个位或未设置位,等等。
- HyperLogLogs:这是一个概率数据结构,用于估计集合的基数。不要害怕,它比看起来更简单。
- Streams:仅附加的类似于地图的条目集合,提供抽象日志数据类型。
本文主要介绍5种常用的数据类型,上述三种以后再共同探索。
2.1 string字符串
字符串类型是redis最常用的数据类型,在Redis中,字符串是可以修改的,在底层它是以字节数组的形式存在的。
Redis中的字符串被称为简单动态字符串「SDS」,这种结构很像Java中的ArrayList,其长度是动态可变的.
struct SDS<T> { T capacity; // 数组容量 T len; // 数组长度 byte[] content; // 数组内容 }
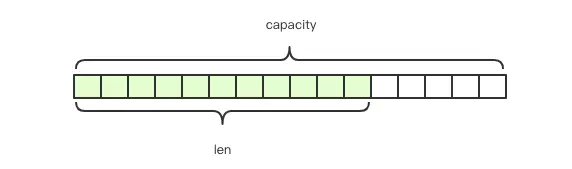
content[] 存储的是字符串的内容,capacity表示数组分配的长度,len表示字符串的实际长度。
字符串的编码类型有int、embstr和raw三种,如上表所示,那么这三种编码类型有什么不同呢?
-
int 编码:保存的是可以用 long 类型表示的整数值。
-
raw 编码:保存长度大于44字节的字符串(redis3.2版本之前是39字节,之后是44字节)。
-
embstr 编码:保存长度小于44字节的字符串(redis3.2版本之前是39字节,之后是44字节)。
设置一个值测试一下:
127.0.0.1:6379> set num 300 127.0.0.1:6379> object encoding num "int" 127.0.0.1:6379> set key1 wealwaysbyhappyhahaha OK 127.0.0.1:6379> object encoding key1 "embstr" 127.0.0.1:6379> set key2 hahahahahahahaahahahahahahahahahahahaha OK 127.0.0.1:6379> strlen key2 (integer) 39 127.0.0.1:6379> object encoding key2 "embstr" 127.0.0.1:6379> set key2 hahahahahahahaahahahahahahahahahahahahahahaha OK 127.0.0.1:6379> object encoding key2 "raw" 127.0.0.1:6379> strlen key2 (integer) 45
raw类型和embstr类型对比
embstr编码的结构:

raw编码的结构:
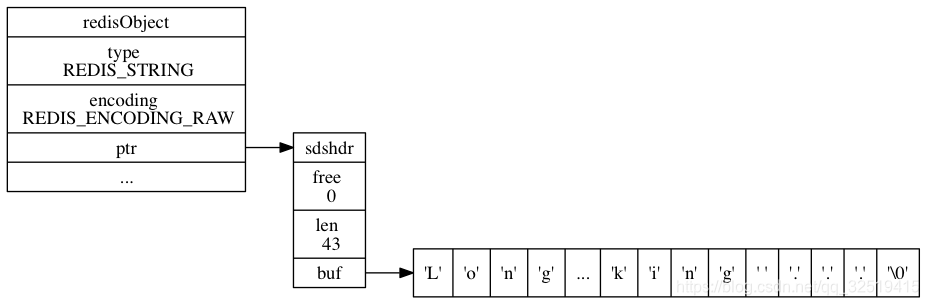
embstr和raw都是由redisObject和sds组成的。不同的是:embstr的redisObject和sds是连续的,只需要使用malloc分配一次内存;而raw需要为redisObject和sds分别分配内存,即需要分配两次内存。
所有相比较而言,embstr少分配一次内存,更方便。但embstr也有明显的缺点:如要增加长度,redisObject和sds都需要重新分配内存。
上文介绍了embstr和raw结构上的不同。重点来了~ 为什么会选择44作为两种编码的分界点?在3.2版本之前为什么是39?这两个值是怎么得出来的呢?
1) 计算RedisObject占用的字节大小
struct RedisObject { int4 type; // 4bits int4 encoding; // 4bits int24 lru; // 24bits int32 refcount; // 4bytes = 32bits void *ptr; // 8bytes,64-bit system }
- type: 不同的redis对象会有不同的数据类型(string、list、hash等),type记录类型,会用到4bits。
- encoding:存储编码形式,用4bits。
- lru:用24bits记录对象的LRU信息。
- refcount:引用计数器,用到32bits。
- *ptr:指针指向对象的具体内容,需要64bits。
计算: 4 + 4 + 24 + 32 + 64 = 128bits = 16bytes
第一步就完成了,RedisObject对象头信息会占用16字节的大小,这个大小通常是固定不变的.
2) sds占用字节大小计算
旧版本:
struct SDS { unsigned int capacity; // 4byte unsigned int len; // 4byte byte[] content; // 内联数组,长度为 capacity }
这里的unsigned int 一个4字节,加起来是8字节.
内存分配器jemalloc分配的内存如果超出了64个字节就认为是一个大字符串,就会用到raw编码。
前面提到 SDS 结构体中的 content 的字符串是以字节�结尾的字符串,之所以多出这样一个字节,是为了便于直接使用 glibc 的字符串处理函数,以及为了便于字符串的调试打印输出。所以我们还要减去1字节 64byte - 16byte - 8byte - 1byte = 39byte
新版本:
struct SDS { int8 capacity; // 1byte int8 len; // 1byte int8 flags; // 1byte byte[] content; // 内联数组,长度为 capacity }
这里unsigned int 变成了uint8_t、uint16_t.的形式,还加了一个char flags标识,总共只用了3个字节的大小。相当于优化了sds的内存使用,相应的用于存储字符串的内存就会变大。
然后进行计算:

64byte - 16byte -3byte -1byte = 44byte。
总结:
所以,redis 3.2版本之后embstr最大能容纳的字符串长度是44,之前是39。长度变化的原因是SDS中内存的优化。
2.2 List
Redis中List对象的底层是由quicklist(快速列表)实现的,快速列表支持从链表头和尾添加元素,并且可以获取指定位置的元素内容。
那么,快速列表的底层是如何实现的呢?为什么能够达到如此快的性能?
罗马不是一日建成的,quicklist也不是一日实现的,起初redis的list的底层是ziplist(压缩列表)或者是 linkedlist(双端列表)。先分别介绍这两种数据结构。
ziplist 压缩列表
当一个列表中只包含少量列表项,且是小整数值或长度比较短的字符串时,redis就使用ziplist(压缩列表)来做列表键的底层实现。
测试:
127.0.0.1:6379> rpush dotahero sf qop doom (integer) 3 127.0.0.1:6379> object encoding dotahero "ziplist"
此处使用老版本redis进行测试,向dota英雄列表中加入了qop痛苦女王、sf影魔、doom末日使者三个英雄,数据结构编码使用的是ziplist。
压缩列表顾名思义是进行了压缩,每一个节点之间没有指针的指向,而是多个元素相邻,没有缝隙。所以 ziplist是Redis为了节约内存而开发的,是由一系列特殊编码的连续内存块组成的顺序型数据结构。具体结构相对比较复杂,大家有兴趣地话可以深入了解。
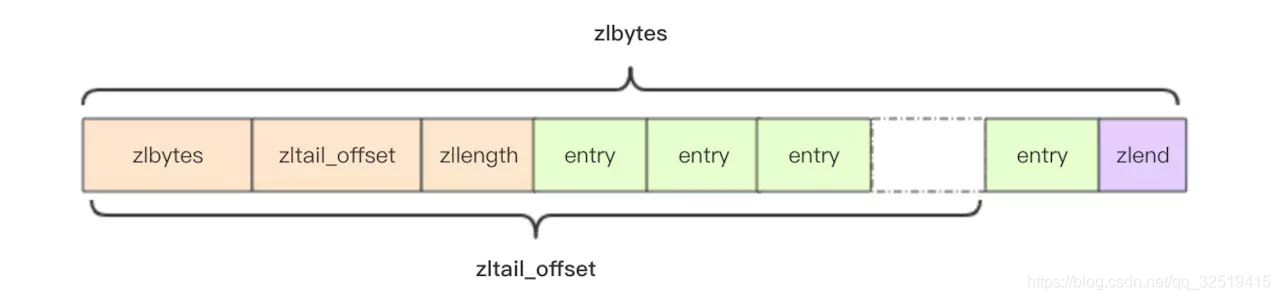
struct ziplist<T> { int32 zlbytes; // 整个压缩列表占用字节数 int32 zltail_offset; // 最后一个元素距离压缩列表起始位置的偏移量,用于快速定位到最后一个节点 int16 zllength; // 元素个数 T[] entries; // 元素内容列表,挨个挨个紧凑存储 int8 zlend; // 标志压缩列表的结束,值恒为 0xFF }
双端列表(linkedlist)
双端列表大家都很熟悉,这里的双端列表和java中的linkedlist很类似。
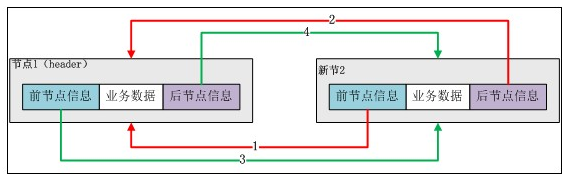
从图中可以看出Redis的linkedlist双端链表有以下特性:节点带有prev、next指针、head指针和tail指针,获取前置节点、后置节点、表头节点和表尾节点、获取长度的复杂度都是O(1)。
压缩列表占用内存少,但是是顺序型的数据结构,插入删除元素的操作比较复杂,所以压缩列表适合数据比较小的情况,当数据比较多的时候,双端列表的高效插入删除还是更好的选择
在Redis开发者的眼中,数据结构的选择,时间上、空间上都要达到极致,所以,他们将压缩列表和双端列表合二为一,创建了快速列表(quicklist)。和java中的hashmap一样,结合了数组和链表的优点。
快速列表(quicklist)
- rpush: listAddNodeHead ---O(1)
- lpush: listAddNodeTail ---O(1)
- push:listInsertNode ---O(1)
- index : listIndex ---O(N)
- pop:ListFirst/listLast ---O(1)
- llen:listLength ---O(N)
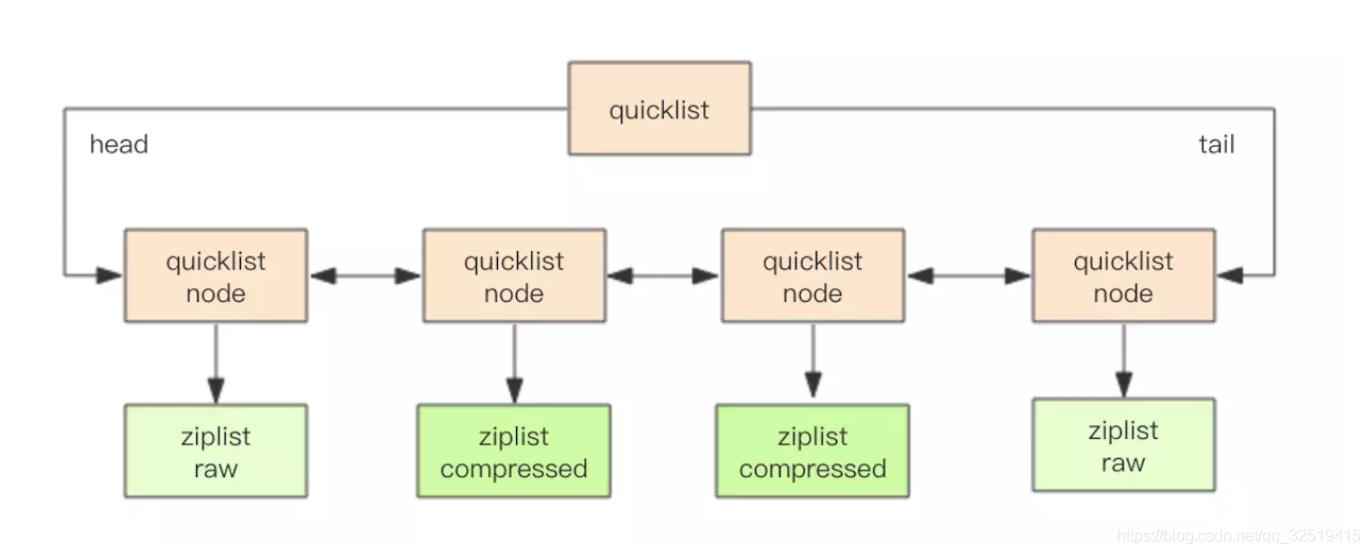
struct ziplist { ... } struct ziplist_compressed { int32 size; byte[] compressed_data; } struct quicklistNode { quicklistNode* prev; quicklistNode* next; ziplist* zl; // 指向压缩列表 int32 size; // ziplist 的字节总数 int16 count; // ziplist 中的元素数量 int2 encoding; // 存储形式 2bit,原生字节数组还是 LZF 压缩存储 ... } struct quicklist { quicklistNode* head; quicklistNode* tail; long count; // 元素总数 int nodes; // ziplist 节点的个数 int compressDepth; // LZF 算法压缩深度 ... }
quicklist 默认的压缩深度是 0,也就是不压缩。压缩的实际深度由配置参数list-compress-depth决定。为了支持快速的 push/pop 操作,quicklist 的首尾两个 ziplist 不压缩,此时深度就是 1。如果深度为 2,表示 quicklist 的首尾第一个 ziplist 以及首尾第二个 ziplist 都不压缩。
2.3 Hash
Hash数据类型的底层实现是ziplist(压缩列表)或字典(也称为hashtable或散列表)。这里压缩列表或者字典的选择,也是根据元素的数量大小决定的。

如图hset了三个键值对,每个值的字节数不超过64的时候,默认使用的数据结构是ziplist。
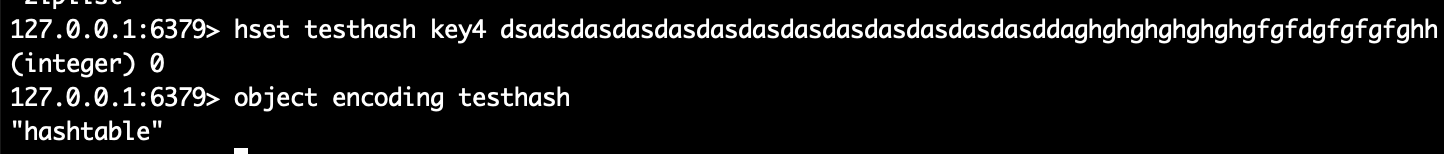
当我们加入了字节数超过64的值的数据时,默认的数据结构已经成为了hashtable。
Hash对象只有同时满足下面两个条件时,才会使用ziplist(压缩列表):
- 哈希中元素数量小于512个;
- 哈希中所有键值对的键和值字符串长度都小于64字节。
压缩列表刚才已经了解了,hashtables类似于jdk1.7以前的hashmap。hashmap采用了链地址法的方法解决了哈希冲突的问题。
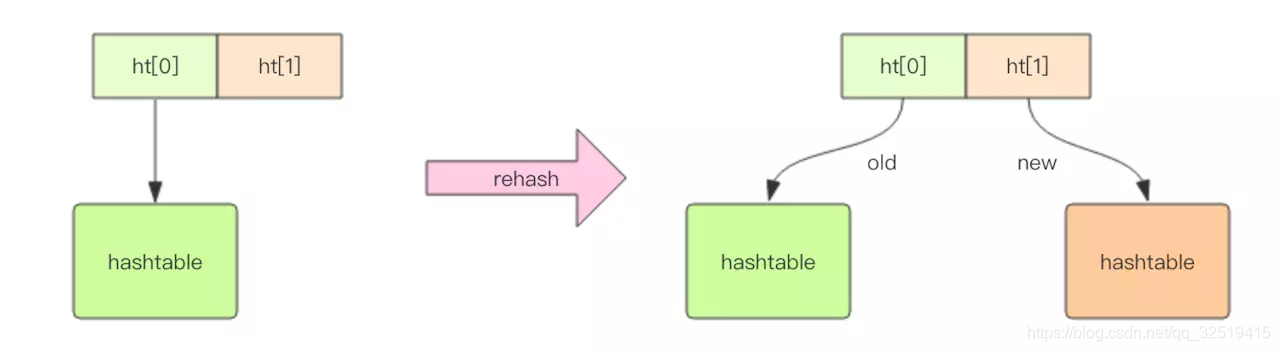
Redis中的字典
redis中的dict 结构内部包含两个 hashtable,通常情况下只有一个 hashtable 是有值的。但是在 dict 扩容缩容时,需要分配新的 hashtable,然后进行渐进式搬迁,这时两个 hashtable 存储的分别是旧的 hashtable 和新的 hashtable。待搬迁结束后,旧的 hashtable 被删除,新的 hashtable 取而代之。
2.4 Set
Set数据类型的底层可以是intset(整数集)或者是hashtable(散列表也叫哈希表)。
当数据都是整数并且数量不多时,使用intset作为底层数据结构;当有除整数以外的数据或者数据量增多时,使用hashtable作为底层数据结构。
127.0.0.1:6379> sadd myset 111 222 333 (integer) 3 127.0.0.1:6379> object encoding myset "intset" 127.0.0.1:6379> sadd myset hahaha (integer) 1 127.0.0.1:6379> object encoding myset "hashtable"
inset的数据结构为:
typedef struct intset { // 编码方式 uint32_t encoding; // 集合包含的元素数量 uint32_t length; // 保存元素的数组 int8_t contents[]; } intset;
intset底层实现为有序、无重复数的数组。 intset的整数类型可以是16位的、32位的、64位的。如果数组里所有的整数都是16位长度的,新加入一个32位的整数,那么整个16的数组将升级成一个32位的数组。升级可以提升intset的灵活性,又可以节约内存,但不可逆。
2.5 Zset
Redis中的Zset,也叫做有序集合。它的底层是ziplist(压缩列表)或 skiplist(跳跃表)。
压缩列表前文已经介绍过了,同理是在元素数量比较少的时候使用。此处主要介绍跳跃列表。
跳表
跳跃列表,顾名思义是可以跳的,跳着查询自己想要查到的元素。大家可能对这种数据结构比较陌生,虽然平时接触的少,但它确实是一个各方面性能都很好的数据结构,可以支持快速的查询、插入、删除操作,开发难度也比红黑树要容易的多。
为什么跳表有如此高的性能呢?它究竟是如何“跳”的呢?跳表利用了二分的思想,在数组中可以用二分法来快速进行查找,在链表中也是可以的。
举个例子,链表如下:

假设要找到10这个节点,需要一个一个去遍历,判断是不是要找的节点。那如何提高效率呢?mysql索引相信大家都很熟悉,可以提高效率,这里也可以使用索引。抽出一个索引层来:
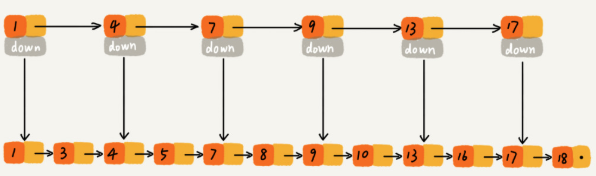
这样只需要找到9然后再找10就可以了,大大节省了查找的时间。
还可以再抽出来一层索引,可以更好地节约时间:
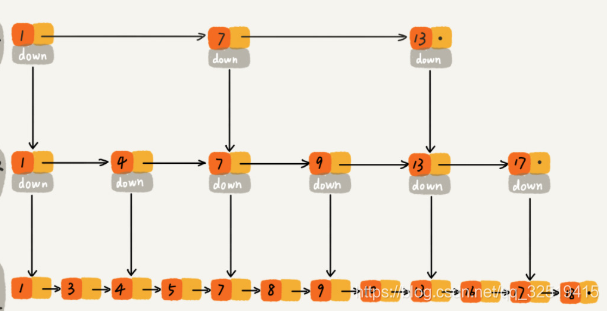
这样基于链表的“二分查找”支持快速的插入、删除,时间复杂度都是O(logn)。
由于跳表的快速查找效率,以及实现的简单、易读。所以Redis放弃了红黑树而选择了更为简单的跳表。
Redis中的跳跃表:
typedef struct zskiplist { // 表头节点和表尾节点 struct zskiplistNode *header, *tail; // 表中节点的数量 unsigned long length; // 表中层数最大的节点的层数 int level; } zskiplist; typedef struct zskiplistNode { // 成员对象 robj *obj; // 分值 double score; // 后退指针 struct zskiplistNode *backward; // 层 struct zskiplistLevel { // 前进指针 struct zskiplistNode *forward; // 跨度---前进指针所指向节点与当前节点的距离 unsigned int span; } level[]; } zskiplistNode;
zadd---zslinsert---平均O(logN), 最坏O(N)
zrem---zsldelete---平均O(logN), 最坏O(N)
zrank--zslGetRank---平均O(logN), 最坏O(N)
总结
本文大概介绍了Redis的5种常用数据类型的底层实现,希望大家结合源码和资料更深入地了解。
数据结构之美在Redis中体现得淋漓尽致,从String到压缩列表、快速列表、散列表、跳表,这些数据结构都适用在了不同的地方,各司其职。
不仅如此,Redis将这些数据结构加以升级、结合,将内存存储的效率性能达到了极致,正因为如此,Redis才能成为众多互联网公司不可缺少的高性能、秒级的key-value内存数据库。
作者:杨亨
拓展阅读:Redis闲谈(1):构建知识图谱
来源:宜信技术学院