一、Solr是什么,能解决什么问题?
Solr是一个高性能,采用Java开发,基于Lucene的全文搜索服务器。同时对其进行了扩展,提供了比Lucene更为丰富的查询语言,同时实现了可配置、可扩展并对查询性能进行了优化,并且提供了一个完善的功能管理界面,是一款非常优秀的全文搜索引擎。
简而言之就是在项目中可以作为搜索引擎,提供资源的高效查询。
Q:数据库不是能提供查询的接口吗?为什么要用额外的框架来做?
A:因为模糊查询不能使用数据库的索引,所以数据库提供的模糊查询效率很低。而Solr本身也可以看做是数据库(no sql)类似于MongoDB存文档数据的菲关系型数据库。许多大型网站的搜索引擎绝不是通过查询数据库来做的,而是由Solr、Elasticsearch 这样的全文检索框架来负责。
二、同类型产品比较
全文检索框架还有ElasticSearch,它们两者之间的区别如下:
- Solr 利用 Zookeeper 进行分布式管理,而 Elasticsearch 自身带有分布式协调管理功能;
- Solr 支持更多格式的数据,而 Elasticsearch 仅支持json文件格式;
- Solr 官方提供的功能更多,而 Elasticsearch 本身更注重于核心功能,高级功能多有第三方插件提供;
- Solr 在传统的搜索应用中表现好于 Elasticsearch,但在处理实时搜索应用时效率明显低于 Elasticsearch。
- Solr 是传统搜索应用的有力解决方案,但 Elasticsearch 更适用于新兴的实时搜索应用。
三、搭建服务
本例中Solr版本为7.7.2
1.下载Solr
官方下载网站: https://lucene.apache.org/solr/downloads.html
2.版本变更记录
参考博文: https://blog.csdn.net/jiangchao858/article/details/52443745
说明:Solr从5.0.0开始内嵌jetty服务器,可直接启动,之前版本需依赖外部容器(tomcat、jetty...)中启动。
3.安装与启动
免安装,下载解压即用。
常用命令:
- 启动:solr start
- 停止:solr stop -p 8983
- 重启:solr restart
启动方式:找到bin目录,在地址栏输入cmd,打开命令界面
![]()
输入solr start,使用默认端口启用jetty服务。
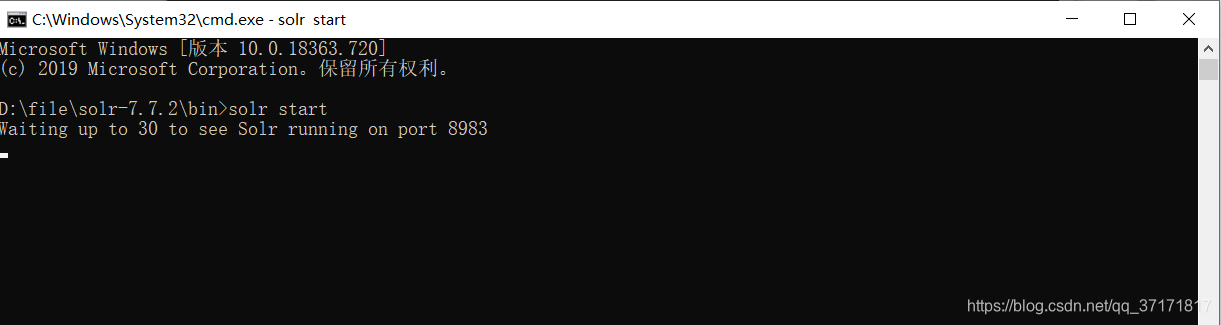
![]()
在浏览器输入localhost:8983/solr查看效果
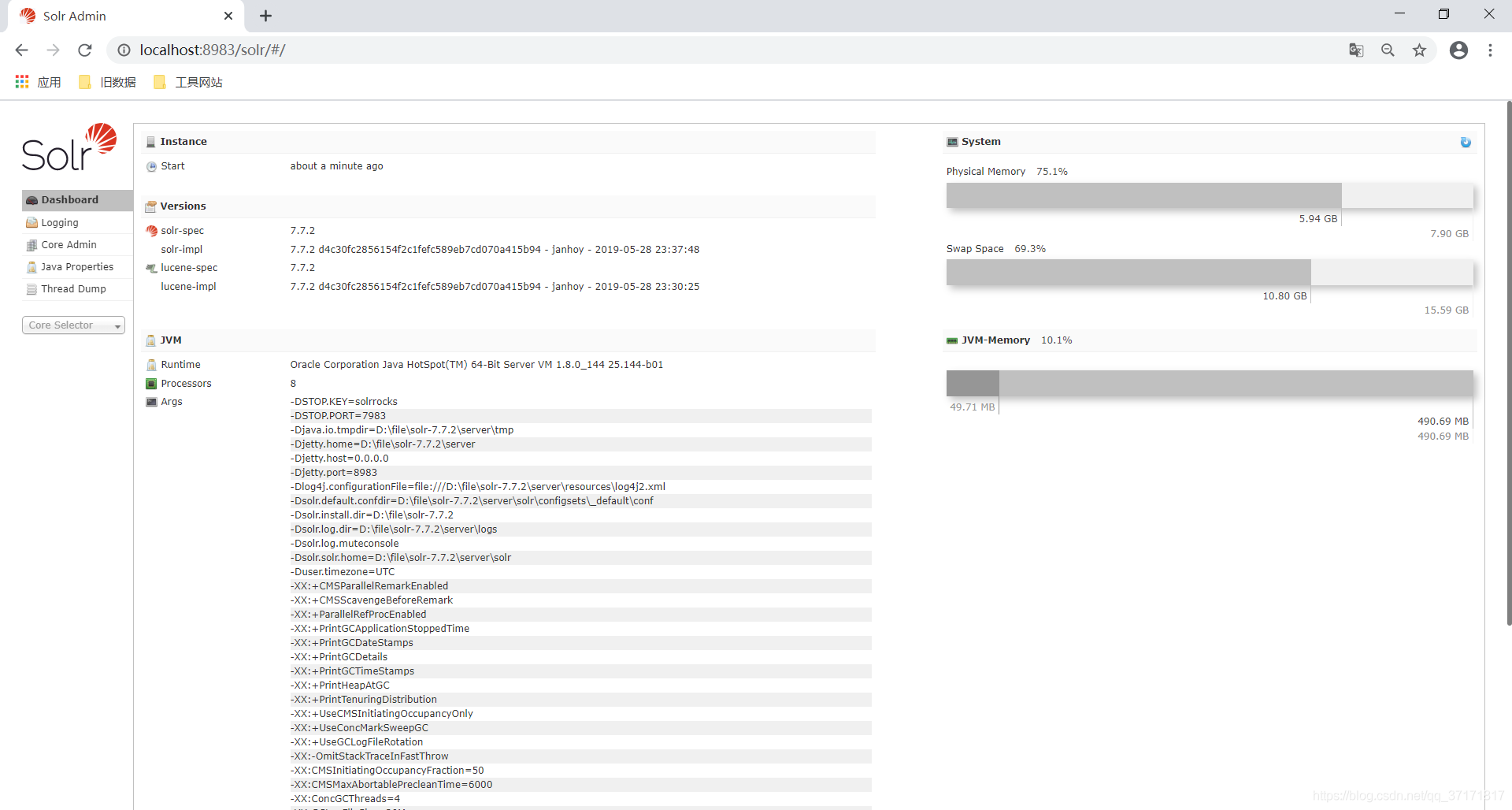
![]()
4、建立core
core就相当于数据库中的表,用来存放数据。
在/server/solr下新建一个文件夹,文件夹的名称就是core的名称,再将/server/solr/configsets/sample_techproducts_configs中的conf文件夹复制到新建的文件夹下。
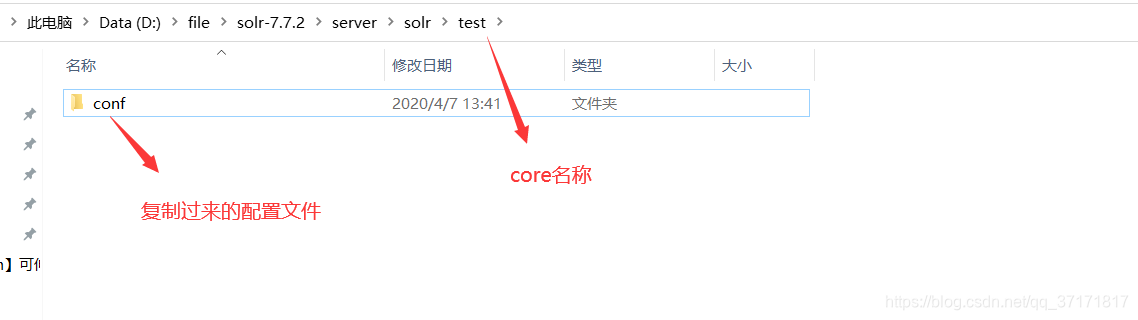
![]()
完成后重启solr服务,再进入solr的admin界面进行添加Core
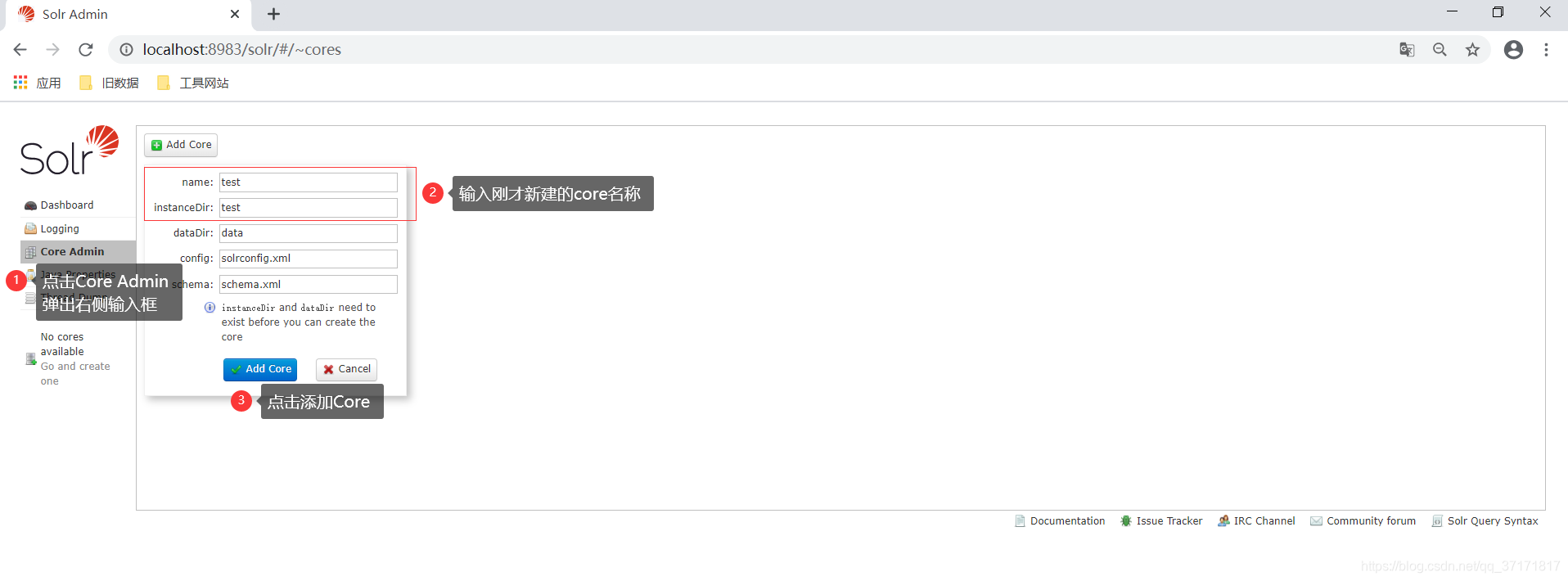
![]()
![]()
添加成功后,文件夹里会多出两个文件(data、core.properties)
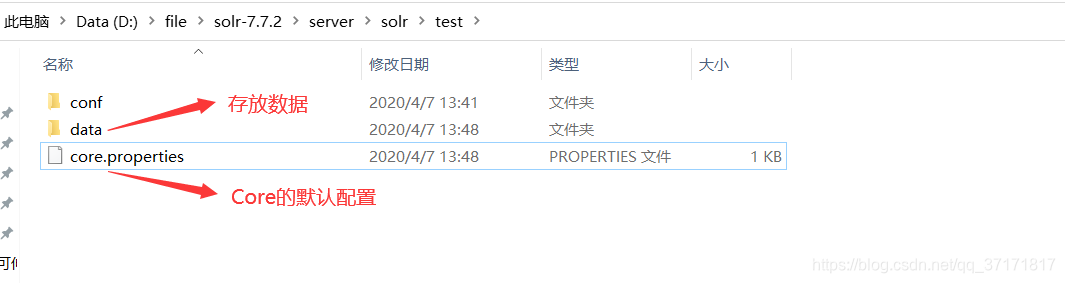
![]()
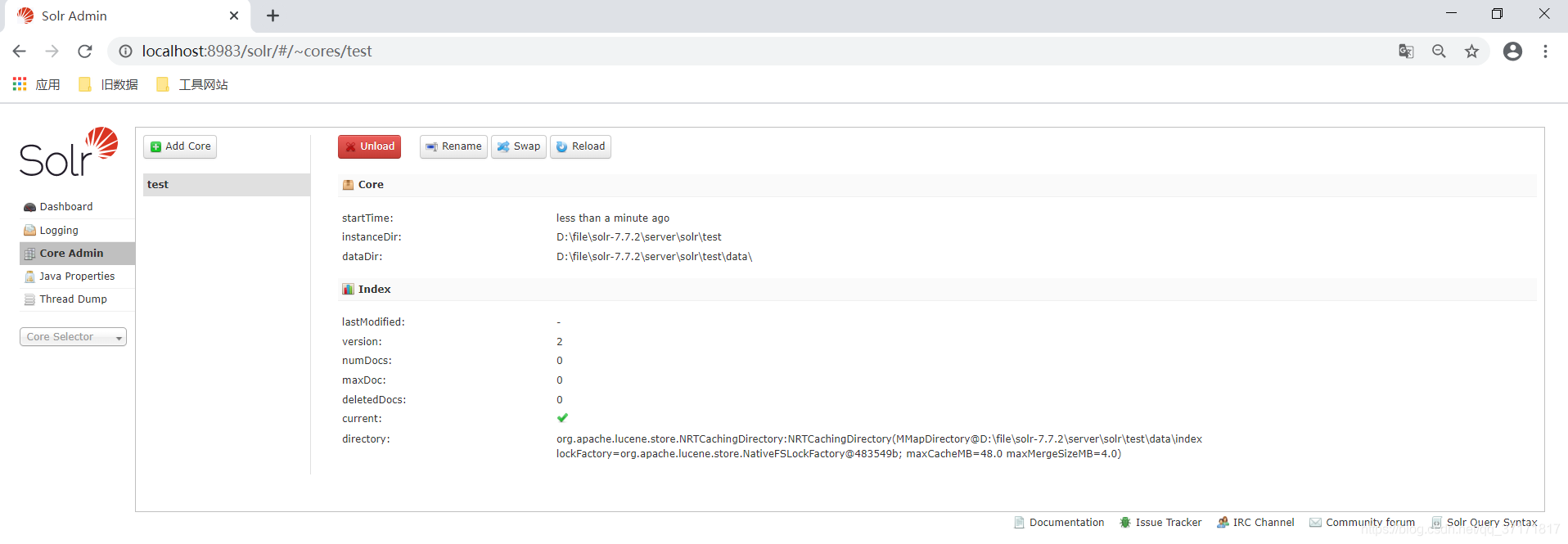
进入自己建立的core进行管理:
![]()
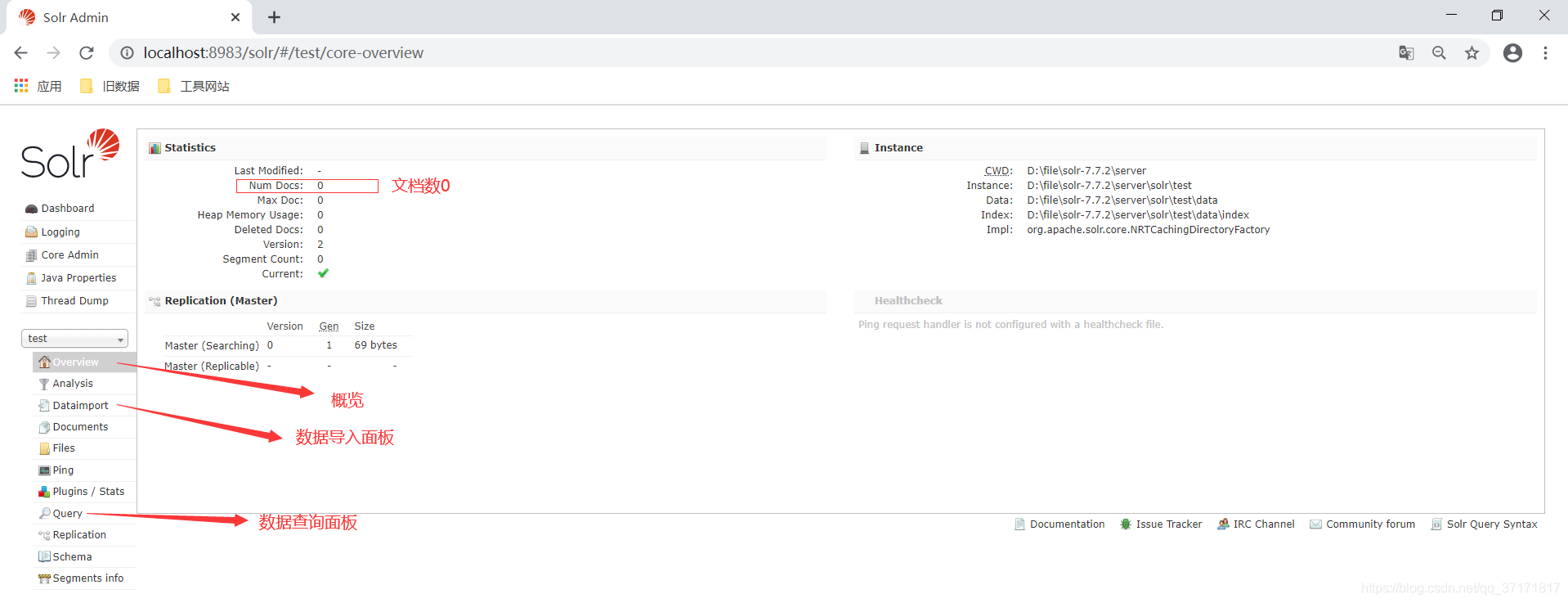
![]()
至此,Solr服务的搭建已经成功了,接下来是运用教程。
5、导入数据
是指将数据库里面的数据导入到Solr中。
首先导入需要的jar包,将dist下的两个jar包复制到/server/solr-webapp/webapp/WEB-INF/lib文件夹下
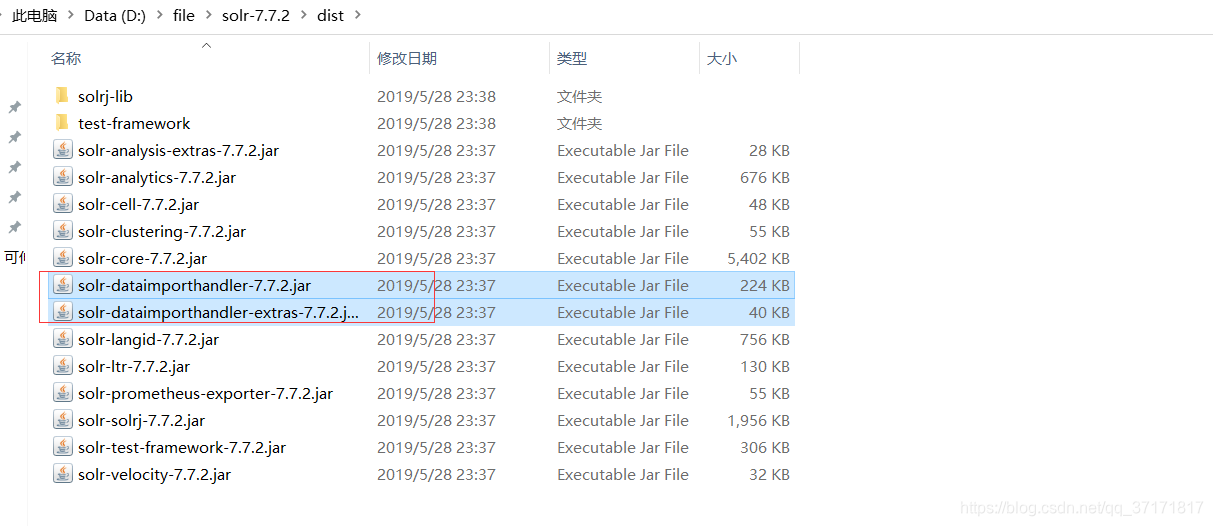
![]()
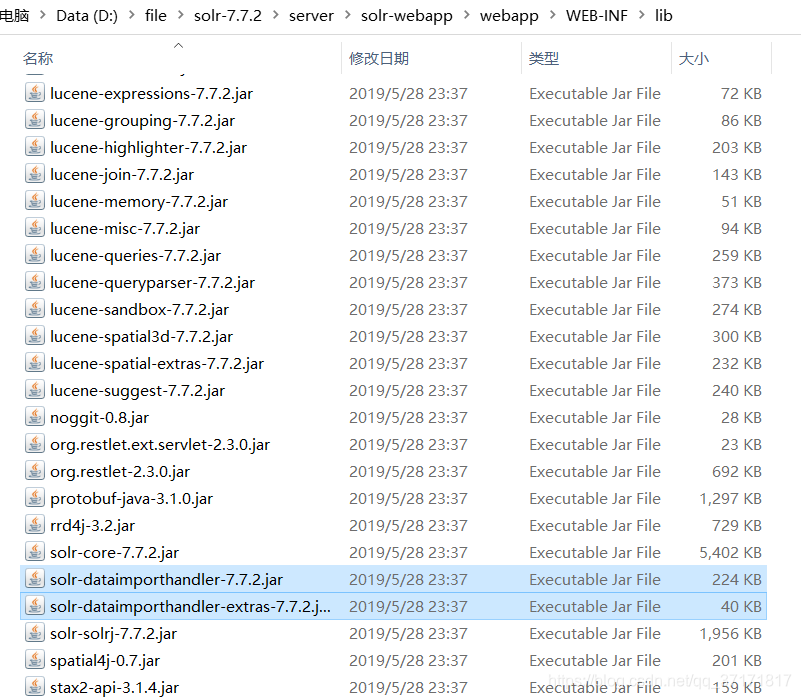
![]()
在你自己的core里的conf下新建一个data-config.xml的配置文件。
- dataSource表示连接数据库的配置
- document表示文档信息
- entity表示实体信息
- --query表示全量导入时调用的sql语句
- --deltaImportQuery表示增量导入时调用的sql语句
- --deltaQuery表示增量导入时查出来的数据
- --field表示字段
- --column表示数据库中字段名称
- --name表示存在solr的core中的名称
- ${dataimporter.last_index_time}表示最后一次导入数据的时间
具体流程:选择全量导入(全部数据导入)时调用query查询数据并导入到Solr中。选择增量导入时,先执行deltaQuery语句获得需要导入数据的id,再根据deltaImportQuery查出数据并导入到Solr中。
编辑你Core下的conf/managed-schema文件:
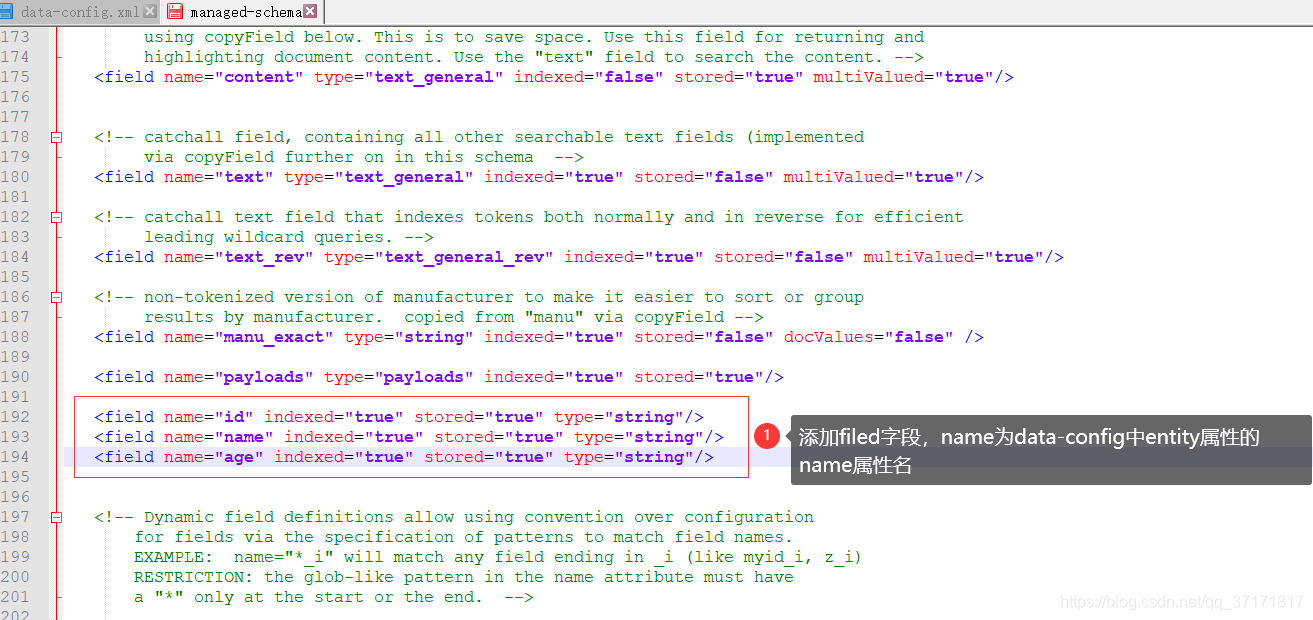
![]()
- indexed表示是否被索引,即是否被查询使用。
- stored表示是否存到Solr库。
- type表示搜索类型,当前为string类型的搜索,还可以自己配置,如IK中文分词器。
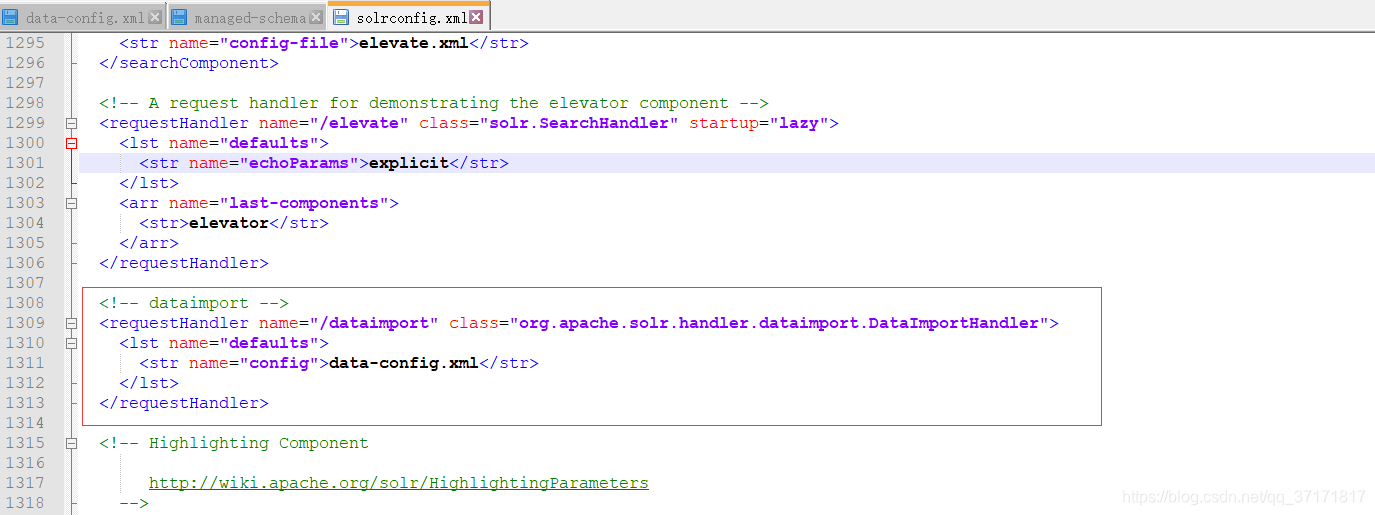
编辑core下conf/solrconfig.xml
新增以下内容
![]()
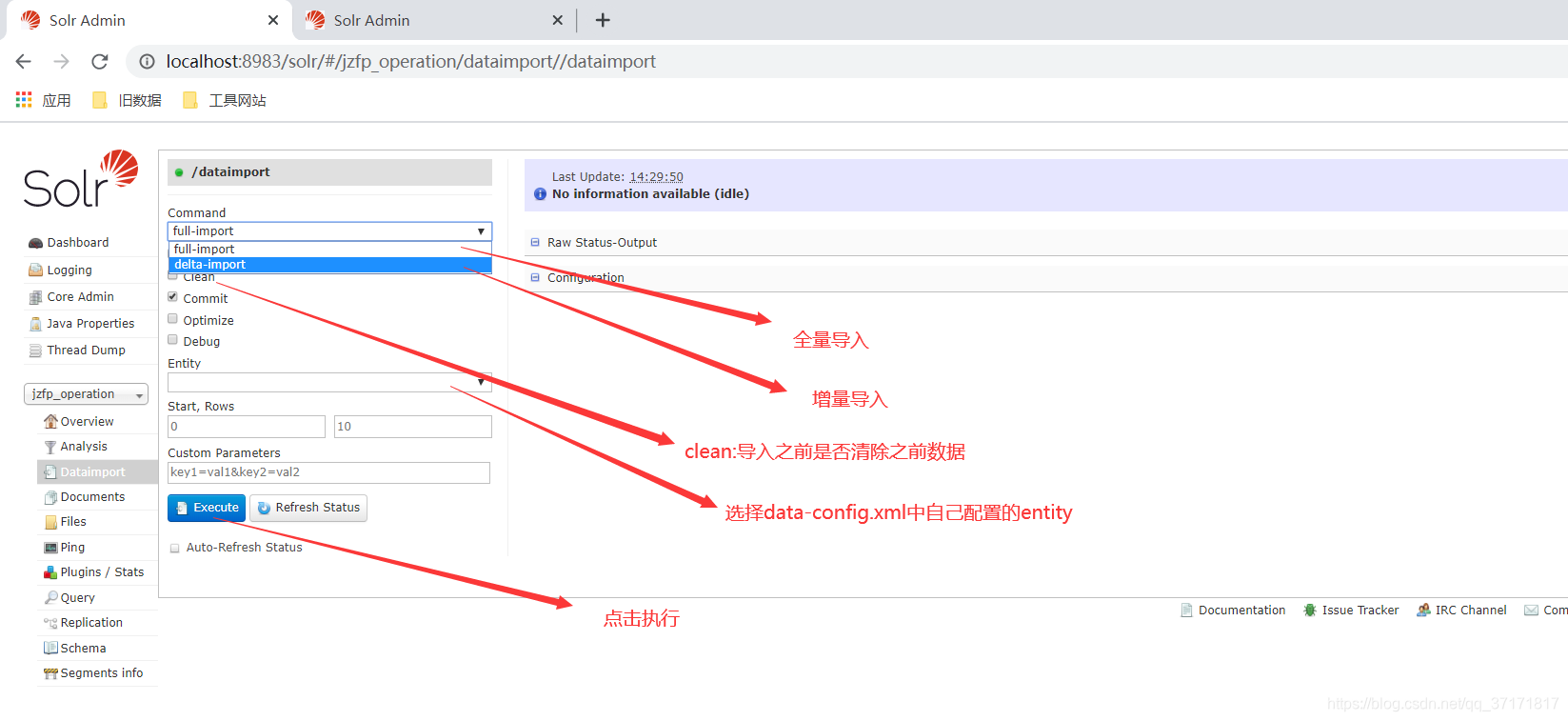
配好之后重启solr服务,并进入admin界面
![]()
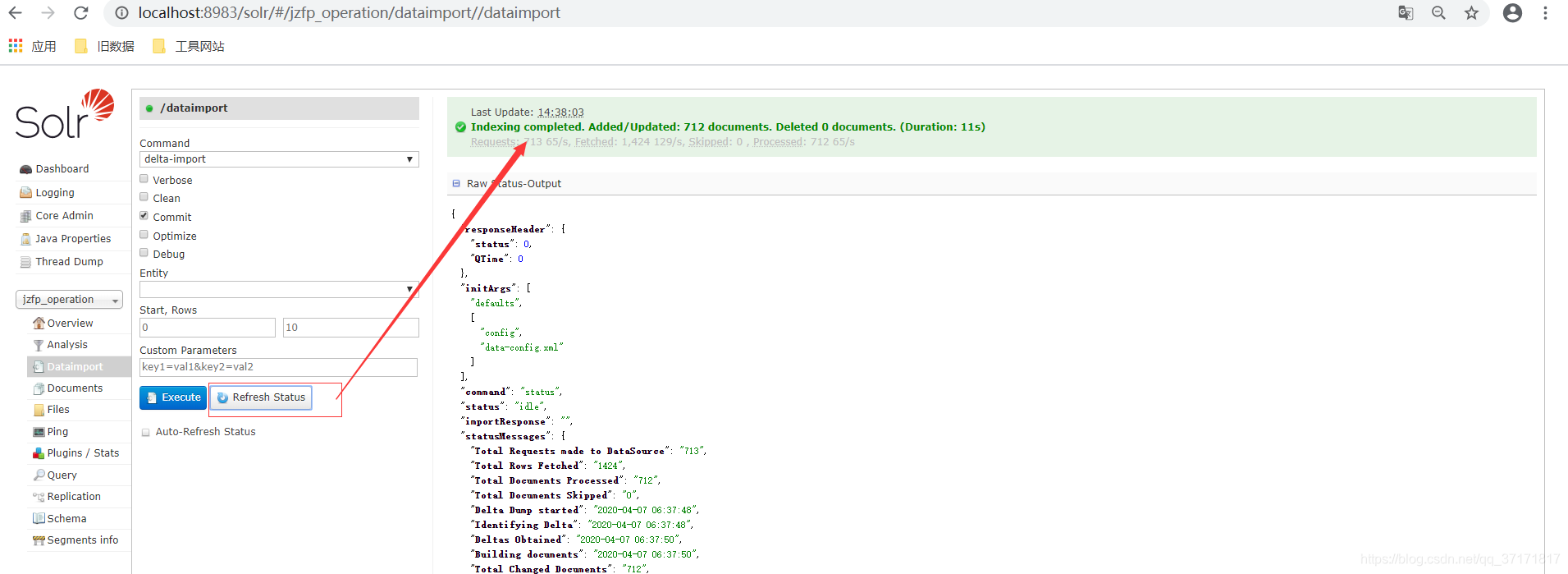
只有点击刷新状态按钮,才回刷新显示状态,出现Indexing completed则为导入完成。
![]()
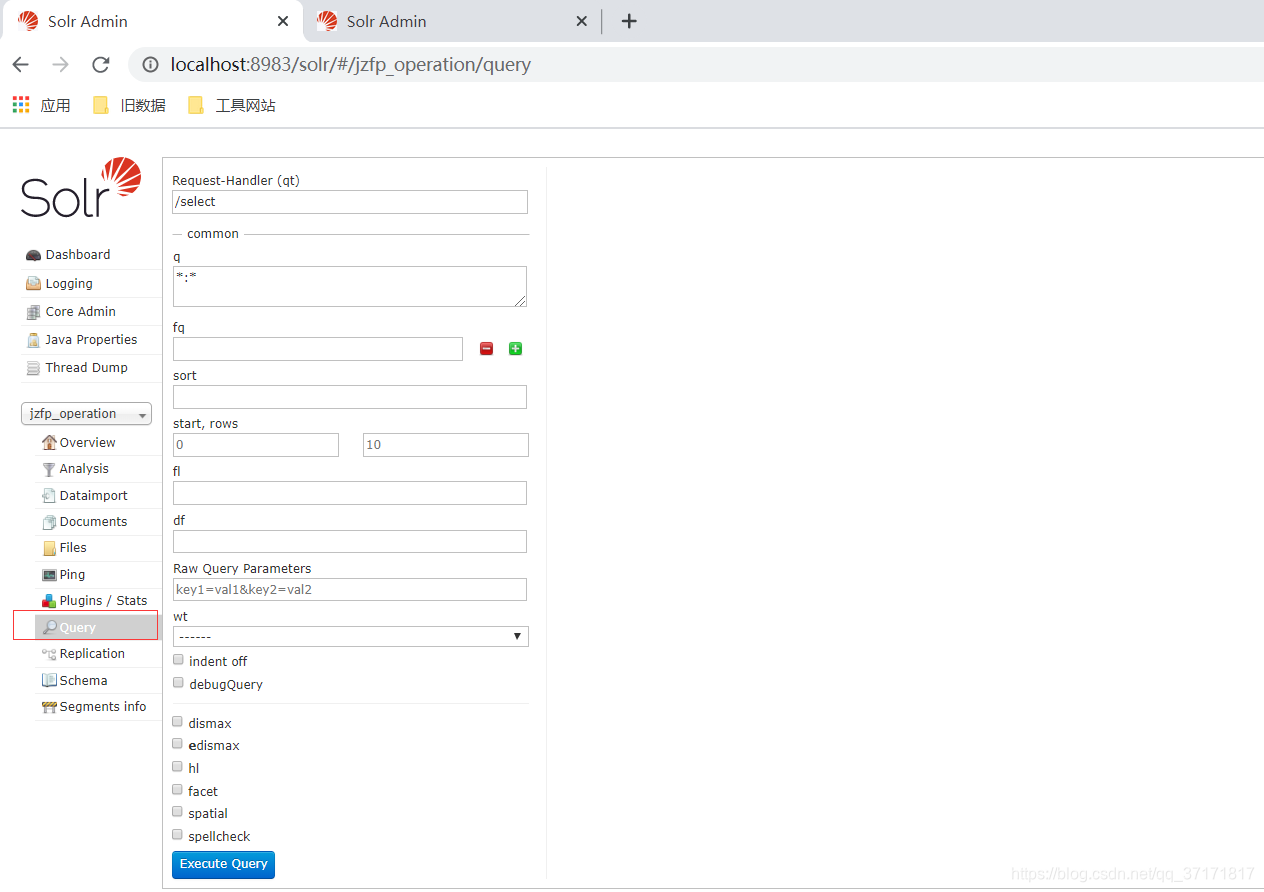
6、查询数据
![]()
输入查询条件,点击执行查询,即可感受到全文检索的魅力。
下一节将会对Solr Query进行一个详细的讲解。