一、背景描述
最近python的tensorflow项目要弄到线上去。网络用的Tensorflow现成的包。数据用kaggle中的数据为例子。
数据地址:
https://www.kaggle.com/johnfarrell/gpu-example-from-prepared-data-try-deepfm
二、Python代码
1、Python Code
1 # author: adrian.wu 2 from __future__ import absolute_import 3 from __future__ import division 4 from __future__ import print_function 5 6 import tensorflow as tf 7 8 tf.logging.set_verbosity(tf.logging.INFO) 9 # Set to INFO for tracking training, default is WARN 10 11 print("Using TensorFlow version %s" % (tf.__version__)) 12 13 CATEGORICAL_COLUMNS = ["workclass", "education", 14 "marital.status", "occupation", 15 "relationship", "race", 16 "sex", "native.country"] 17 18 # Columns of the input csv file 19 COLUMNS = ["age", "workclass", "fnlwgt", "education", 20 "education.num", "marital.status", 21 "occupation", "relationship", "race", 22 "sex", "capital.gain", "capital.loss", 23 "hours.per.week", "native.country", "income"] 24 25 FEATURE_COLUMNS = ["age", "workclass", "education", 26 "education.num", "marital.status", 27 "occupation", "relationship", "race", 28 "sex", "capital.gain", "capital.loss", 29 "hours.per.week", "native.country"] 30 31 import pandas as pd 32 33 df = pd.read_csv("/Users/adrian.wu/Desktop/learn/kaggle/adult-census-income/adult.csv") 34 35 from sklearn.model_selection import train_test_split 36 37 BATCH_SIZE = 40 38 39 num_epochs = 1 40 shuffle = True 41 42 y = df["income"].apply(lambda x: ">50K" in x).astype(int) 43 del df["fnlwgt"] # Unused column 44 del df["income"] # Labels column, already saved to labels variable 45 X = df 46 47 print(X.describe()) 48 49 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20) 50 51 train_input_fn = tf.estimator.inputs.pandas_input_fn( 52 x=X_train, 53 y=y_train, 54 batch_size=BATCH_SIZE, 55 num_epochs=num_epochs, 56 shuffle=shuffle) 57 58 eval_input_fn = tf.estimator.inputs.pandas_input_fn( 59 x=X_test, 60 y=y_test, 61 batch_size=BATCH_SIZE, 62 num_epochs=num_epochs, 63 shuffle=shuffle) 64 65 66 def generate_input_fn(filename, num_epochs=None, shuffle=True, batch_size=BATCH_SIZE): 67 df = pd.read_csv(filename) # , header=None, names=COLUMNS) 68 labels = df["income"].apply(lambda x: ">50K" in x).astype(int) 69 del df["fnlwgt"] # Unused column 70 del df["income"] # Labels column, already saved to labels variable 71 72 type(df['age'].iloc[3]) 73 74 return tf.estimator.inputs.pandas_input_fn( 75 x=df, 76 y=labels, 77 batch_size=batch_size, 78 num_epochs=num_epochs, 79 shuffle=shuffle) 80 81 82 sex = tf.feature_column.categorical_column_with_vocabulary_list( 83 key="sex", 84 vocabulary_list=["female", "male"]) 85 race = tf.feature_column.categorical_column_with_vocabulary_list( 86 key="race", 87 vocabulary_list=["Amer-Indian-Eskimo", 88 "Asian-Pac-Islander", 89 "Black", "Other", "White"]) 90 91 # 先对categorical的列做hash 92 education = tf.feature_column.categorical_column_with_hash_bucket( 93 "education", hash_bucket_size=1000) 94 marital_status = tf.feature_column.categorical_column_with_hash_bucket( 95 "marital.status", hash_bucket_size=100) 96 relationship = tf.feature_column.categorical_column_with_hash_bucket( 97 "relationship", hash_bucket_size=100) 98 workclass = tf.feature_column.categorical_column_with_hash_bucket( 99 "workclass", hash_bucket_size=100) 100 occupation = tf.feature_column.categorical_column_with_hash_bucket( 101 "occupation", hash_bucket_size=1000) 102 native_country = tf.feature_column.categorical_column_with_hash_bucket( 103 "native.country", hash_bucket_size=1000) 104 105 print('Categorical columns configured') 106 107 age = tf.feature_column.numeric_column("age") 108 deep_columns = [ 109 # Multi-hot indicator columns for columns with fewer possibilities 110 tf.feature_column.indicator_column(workclass), 111 tf.feature_column.indicator_column(marital_status), 112 tf.feature_column.indicator_column(sex), 113 tf.feature_column.indicator_column(relationship), 114 tf.feature_column.indicator_column(race), 115 # Embeddings for categories with more possibilities. Should have at least (possibilties)**(0.25) dims 116 tf.feature_column.embedding_column(education, dimension=8), 117 tf.feature_column.embedding_column(native_country, dimension=8), 118 tf.feature_column.embedding_column(occupation, dimension=8), 119 age 120 ] 121 122 m2 = tf.estimator.DNNClassifier( 123 model_dir="model/dir", 124 feature_columns=deep_columns, 125 hidden_units=[100, 50]) 126 127 m2.train(input_fn=train_input_fn) 128 129 start, end = 0, 5 130 data_predict = df.iloc[start:end] 131 predict_labels = y.iloc[start:end] 132 print(predict_labels) 133 print(data_predict.head(12)) # show this before deleting, so we know what the labels 134 predict_input_fn = tf.estimator.inputs.pandas_input_fn( 135 x=data_predict, 136 batch_size=1, 137 num_epochs=1, 138 shuffle=False) 139 140 predictions = m2.predict(input_fn=predict_input_fn) 141 142 for prediction in predictions: 143 print("Predictions: {} with probabilities {} ".format(prediction["classes"], prediction["probabilities"])) 144 145 146 def column_to_dtype(column): 147 if column in CATEGORICAL_COLUMNS: 148 return tf.string 149 else: 150 return tf.float32 151 152 153 # 什么数据要喂给输入 154 FEATURE_COLUMNS_FOR_SERVE = ["workclass", "education", 155 "marital.status", "occupation", 156 "relationship", "race", 157 "sex", "native.country", "age"] 158 159 serving_features = {column: tf.placeholder(shape=[1], dtype=column_to_dtype(column), name=column) for column in 160 FEATURE_COLUMNS_FOR_SERVE} 161 # serving_input_receiver_fn有很多种方式 162 export_dir = m2.export_savedmodel(export_dir_base="models/export", 163 serving_input_receiver_fn=tf.estimator.export.build_raw_serving_input_receiver_fn( 164 serving_features), as_text=True) 165 export_dir = export_dir.decode("utf8")
2、通过 export_savedmodel这个函数生成了variables变量和pbtxt文件。如图所示:
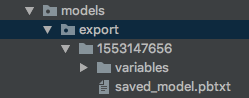
3、先打开saved_model.pbtxt文件浏览一下,会发现这是对tensorflow 的一个个描述。包含了node name, operation name,dtype等信息。在套用java时需要明确node的name。
node { name: "dnn/head/predictions/probabilities" op: "Softmax" input: "dnn/head/predictions/two_class_logits" attr { key: "T" value { type: DT_FLOAT } } attr { key: "_output_shapes" value { list { shape { dim { size: -1 } dim { size: 2 } } } }
三、Java代码
1、先将variable和pbtxt文件放到resources下面。
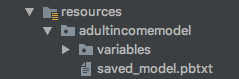
2、Java代码
1 import org.tensorflow.SavedModelBundle; 2 import org.tensorflow.Session; 3 import org.tensorflow.Tensor; 4 5 /** 6 * Created by adrian.wu on 2019/3/14. 7 */ 8 public class TestAdultIncome { 9 10 public static void main(String[] args) throws Exception { 11 12 SavedModelBundle model = SavedModelBundle.load("/Users/adrian.wu/Desktop/sc/adrian_test/src/main/resources/adultincomemodel", "serve"); 13 Session sess = model.session(); 14 15 String sex = "Female"; 16 String workclass = "?"; 17 String education = "HS-grad"; 18 String ms = "Widowed"; 19 String occupation = "?"; 20 String relationship = "Not-in-family"; 21 String race = "White"; 22 String nc = "United-States"; 23 24 //不能将string直接喂给create()接口 25 Tensor sexTensor = Tensor.create(new byte[][]{sex.getBytes()}); 26 Tensor workclassTensor = Tensor.create(new byte[][]{workclass.getBytes()}); 27 Tensor eduTensor = Tensor.create(new byte[][]{education.getBytes()}); 28 Tensor msTensor = Tensor.create(new byte[][]{ms.getBytes()}); 29 Tensor occuTensor = Tensor.create(new byte[][]{occupation.getBytes()}); 30 Tensor ralaTensor = Tensor.create(new byte[][]{relationship.getBytes()}); 31 Tensor raceTensor = Tensor.create(new byte[][]{race.getBytes()}); 32 Tensor ncTesnsor = Tensor.create(new byte[][]{nc.getBytes()}); 33 34 float[][] age = {{90f}}; 35 36 Tensor ageTensor = Tensor.create(age); 37 38 //根据pbtxt文件,查看operation name。 39 Tensor result = sess.runner() 40 .feed("workclass", workclassTensor) 41 .feed("education", eduTensor) 42 .feed("marital.status", msTensor) 43 .feed("relationship", ralaTensor) 44 .feed("race", raceTensor) 45 .feed("sex", sexTensor) 46 .feed("native.country", ncTesnsor) 47 .feed("occupation",occuTensor) 48 .feed("age", ageTensor) 49 .fetch("dnn/head/predictions/probabilities") 50 .run() 51 .get(0); 52 53 float[][] buffer = new float[1][2]; 54 result.copyTo(buffer); 55 System.out.println("" + String.valueOf(buffer[0][0])); 56 } 57 58 }
四、结果对比
python和java结果:
1 java: 0.9432887 2 python: 0.9432887