一、shutil模块--高级的文件、文件夹、压缩包处理模块
1、通过句柄复制内容
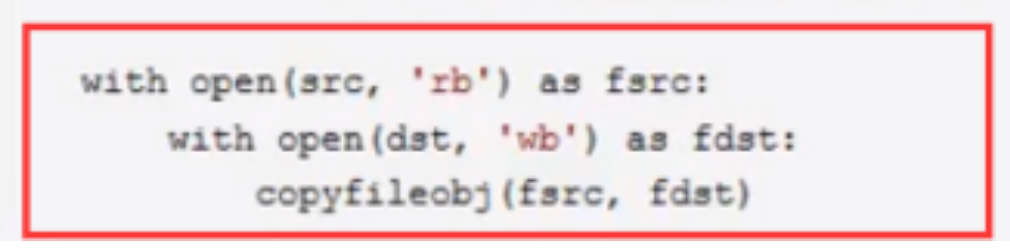
shutil.copyfileobj(f1,f2)对文件的复制(通过句柄fdst/fsrc复制文件内容)
源码: Length=16*1024 While 1: Buf=Fsrc.read(length) If not buf: Break Fdst.write(bug)
2、通过文件名复制文件(不复制权限及文件属性)
shutil.copyfile('oldfile','newfile')
输入文件名即可完成复制 复制文件内容
看源码中 with open部分 调用copyfileobj来实现
shutil.copyfile('/root/myfile/Python-3.6.3.tgz','/root/myfile/python.tgz') -rw-r--r-- 1 yomi yomi 22673115 11月 14 15:22 Python-3.6.3.tgz -rw-r--r-- 1 root root 22673115 3月 10 20:39 python.tgz 文件:"Python-3.6.3.tgz" 大小:22673115 块:44344 IO 块:4096 普通文件 设备:fd01h/64769d Inode:131086 硬链接:1 权限:(0644/-rw-r--r--) Uid:( 1000/ yomi) Gid:( 1000/ yomi) 最近访问:2017-11-14 15:43:32.000000000 +0800 最近更改:2017-11-14 15:22:32.000000000 +0800 最近改动:2018-03-10 20:37:34.248820941 +0800 文件:"python.tgz" 大小:22673115 块:44344 IO 块:4096 普通文件 设备:fd01h/64769d Inode:134184 硬链接:1 权限:(0644/-rw-r--r--) Uid:( 0/ root) Gid:( 0/ root) 最近访问:2018-03-10 20:39:53.069979344 +0800 最近更改:2018-03-10 20:39:53.106979648 +0800 最近改动:2018-03-10 20:39:53.106979648 +0800
3、shutil.copymode() 复制权限(不复制所有者及所属组,两个文件都需要存在的前提,才能进行复制mode)
shutil.copymode('/root/myfile/Python-3.6.3.tgz','/root/myfile/python.tgz')
------------------------------------------------------- -rw-r--r-- 1 yomi yomi 22673115 11月 14 15:22 Python-3.6.3.tgz ---x--x--x 1 root root 22673115 3月 10 20:39 python.tgz [root@VM_61_212_centos myfile]# ll -rw-r--r-- 1 yomi yomi 22673115 11月 14 15:22 Python-3.6.3.tgz -rw-r--r-- 1 root root 22673115 3月 10 20:39 python.tgz [root@VM_61_212_centos myfile]#
4、shutil.copystat() 复制状态(前提两个文件必须存在)
shutil.copystat('/root/myfile/Python-3.6.3.tgz','/root/myfile/python.tgz') 文件:"Python-3.6.3.tgz" 大小:22673115 块:44344 IO 块:4096 普通文件 设备:fd01h/64769d Inode:131086 硬链接:1 权限:(0644/-rw-r--r--) Uid:( 1000/ yomi) Gid:( 1000/ yomi) 最近访问:2017-11-14 15:43:32.000000000 +0800 最近更改:2017-11-14 15:22:32.000000000 +0800 最近改动:2018-03-10 20:37:34.248820941 +0800 文件:"python.tgz" 大小:22673115 块:44344 IO 块:4096 普通文件 设备:fd01h/64769d Inode:134184 硬链接:1 权限:(0644/-rw-r--r--) Uid:( 0/ root) Gid:( 0/ root) 最近访问:2017-11-14 15:43:32.000000000 +0800 最近更改:2017-11-14 15:22:32.000000000 +0800 最近改动:2018-03-10 20:51:04.450228946 +0800
5、shutil.copy() -》 不复制状态stat
Copy=copyfile+copymode
shutil.copy('/root/myfile/Python-3.6.3.tgz','/root/myfile/pythonnew.tgz')
6、 shutil.copy2()复制文件,包括内容权限及属性
包含3个部分file/mode/stat
copy2=copyfile+copymode+copystat
shutil.copy2('/root/myfile/Python-3.6.3.tgz','/root/myfile/python2.tgz')
7、copytree
递归复制文件 copyfile+copymode+copystat
>>> import shutil >>> shutil.copytree('/root/myfile','/root/test') ----------------------------- [root@VM_61_212_centos ~]# cd /root/myfile/ [root@VM_61_212_centos myfile]# ll 总用量 88704 drwxr-xr-x 2 root root 4096 12月 15 21:07 conf drwxr-xr-x 8 root root 4096 1月 27 17:31 my_python_file -rw-r--r-- 1 root root 22673115 3月 10 20:55 python1.tgz -rw-r--r-- 1 root root 22673115 11月 14 15:22 python2.tgz drwxr-xr-x 16 501 501 4096 10月 3 15:47 Python-3.6.3 -rw-r--r-- 1 yomi yomi 22673115 11月 14 15:22 Python-3.6.3.tgz -rw-r--r-- 1 root root 22673115 11月 14 15:22 python.tgz drwxr-xr-x 2 root root 4096 11月 27 02:45 test_directory --------------------------------- [root@VM_61_212_centos ~]# cd /root/test/ [root@VM_61_212_centos test]# ll 总用量 88704 drwxr-xr-x 2 root root 4096 12月 15 21:07 conf drwxr-xr-x 8 root root 4096 1月 27 17:31 my_python_file -rw-r--r-- 1 root root 22673115 3月 10 20:55 python1.tgz -rw-r--r-- 1 root root 22673115 11月 14 15:22 python2.tgz drwxr-xr-x 16 root root 4096 10月 3 15:47 Python-3.6.3 -rw-r--r-- 1 root root 22673115 11月 14 15:22 Python-3.6.3.tgz -rw-r--r-- 1 root root 22673115 11月 14 15:22 python.tgz drwxr-xr-x 2 root root 4096 11月 27 02:45 test_directory
8、shutil.rmtree()删除一个目录
这个目录不管是否为空
9、shutil.move()递归移动文件,包括文件夹内的内容
shutil.move(r'c:\a',r'd:\a')
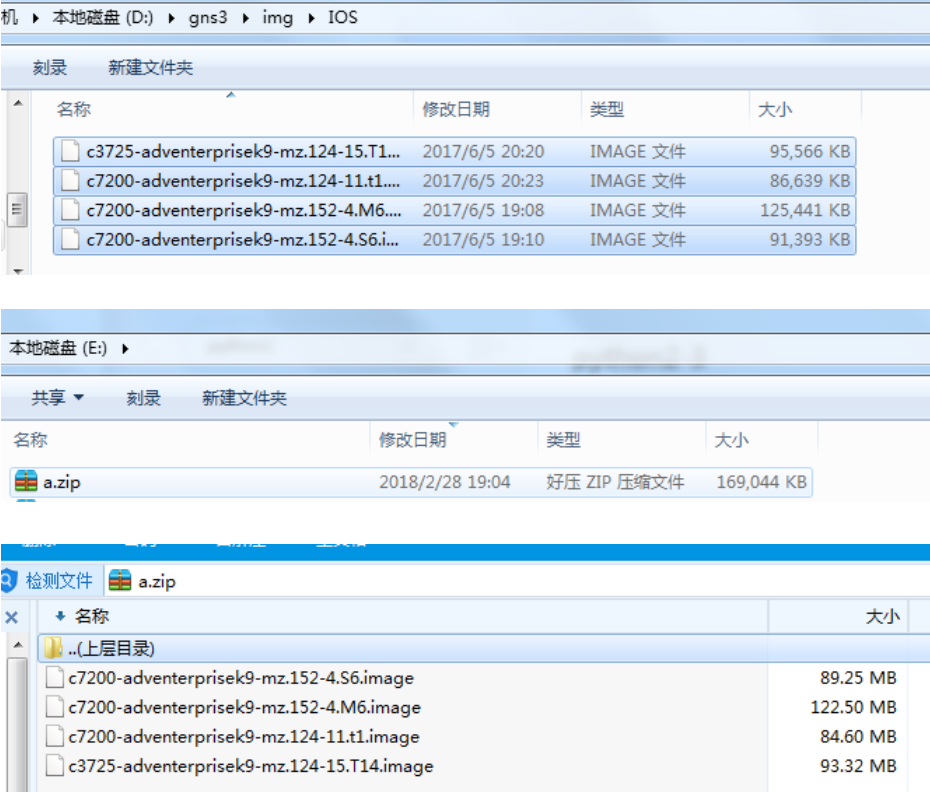
10、shutil.make_archive('指定要压缩到的位置及文件名','指定压缩格式,可以有zip、tar、gztar、bztar','需要被处理的文件')
注意要分清顺序,新文件在前面,要压缩的内容在后面
>>> shutil.make_archive(r'e:a','zip','D:gns3imgIOS') 'e:\a.zip'
了解一下:实际是通过调用zipfile和tarfile 两个模块来处理
>>> shutil.make_archive(r'e:a.zip','zip',r'D:a') 'e:\a.zip.zip'#自己会加后缀名
11、shutil.unpack_archive(原文件,加压位置) 解压文件
>>> shutil.unpack_archive(r'e:a.zip.zip',r'c:\')
二、json与pickle模块--序列化
1、json.dumps与json.loads
思路:
通过dumps一个变量,生成一个可以写入文本的变量来写入文件。
tmpwrite=json.dumps(dict1)
f.write(tmpwrite)
通过loads来解析read的句柄赋值给变量,来完成加载
tmpjson=json.loads(f.read()) print(tmpjson)
2、pickle.dumps与pickle.dumps
Pickle和json的思路一致
3、json和pickle的对比
3.1 文件的读取方式r rb w wb
json.dumps、pickle.dumps -> 需要注意的是 dumps时 json文件可以直接用w打开 pickle文件需要用wb来写
都是用来将内存数据保存到硬盘文件内
loads 时 pickle文件需要用rb打开
3.2 明文与密文
json保存的文件为明文 不同的语言之间可以使用json文件来互相传递信息
pickle的文件为python自己的格式 只能python自己使用 从表面上看为'乱码'实际也是明文
3.3 其他语言的内容交互
Json所有语言都支持
pickle能支持python所有的数据类型,但只有python有这种格式
import json import pickle dict1={ 1:'111', 2:'222', 3:'333' } dict2={ 11:'a111', 22:'b222', 33:'c333' } with open ('jsonfile','w') as f: tmpwrite=json.dumps(dict1) f.write(tmpwrite) f.close() with open('picklefile','wb') as f1: tmpwrite=pickle.dumps(dict2) f1.write(tmpwrite) f1.close() with open ('jsonfile') as f: tmpjson=json.loads(f.read()) print(tmpjson) f .close() with open('picklefile','rb') as f1: tmppickle=pickle.loads(f1.read()) print(tmppickle) f1.close()
4、 json与pickle的使用说明
需要注意不要在一个文件中多次使用dump,一个变量dump一个文件
5、json.dump与json.load
6、pickle.dump与pickle.load
注意pickle的wb rb情况。
pickle和json的使用方式一样
dump和load就是dumps及loads的缩写
with open('xxx1','w') as f: json.dump(dict1,f) f.close() with open('xxx1','r') as f: data=json.load(f) print(data) f.close()
三、Shelve模块 比pickle更牛逼的一种工具 可以dump、load多次
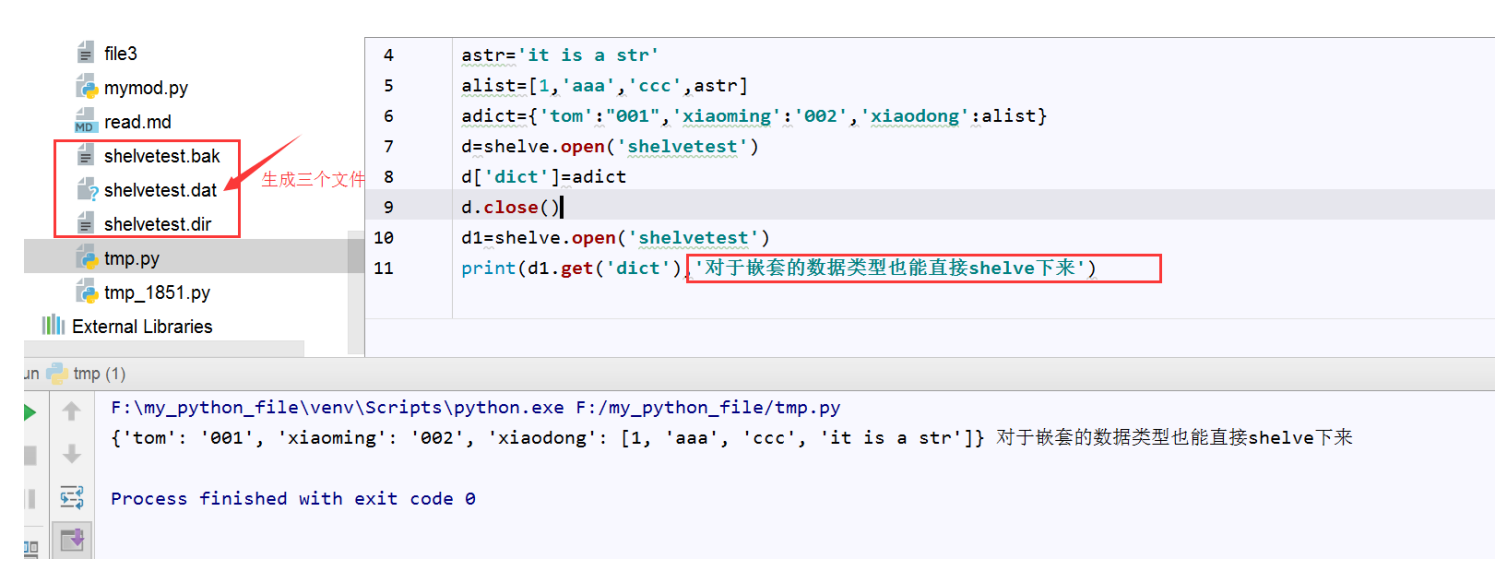
shelve 可以在一个文件内放入多个数据类型
import shelve astr='it is a str' alist=[1,'aaa','ccc',astr] adict={'tom':"001",'xiaoming':'002','xiaodong':alist} #创建过程直接下标赋值 d=shelve.open('shelvetest') d['dict']=adict d['list']=alist d['str']=astr d.close() #读取过程get动作 d1=shelve.open('shelvetest') print(d1.get('dict'),'对于嵌套的数据类型也能直接shelve下来') print(d1.get('str')) print(d1.get('list'))
四、xml.etree.ElementTree --xml文件处理
1、知道如何写一个xml文件
<?xml version"1.0"?> 写版本 <data item=“str”>item2</data> <data item=“str” item2=“str” />自结束形式
2、如何全遍历(parse读文件、getroot获取根)
import xml.etree.ElementTree as ET #获取模块 FileTree=ET.parse('360.xml')#打开文件 FileRoot=FileTree.getroot()#获取根节点
2.1 print(root.tag)
2.2 循环输出 需要知道tag attrib text分别输出的内容
import xml.etree.ElementTree as ET #获取模块 FileTree=ET.parse('360.xml')#打开文件 FileRoot=FileTree.getroot()#获取根节点 print(FileTree) print(FileRoot) print(FileRoot.tag) for child in FileRoot: print(child.tag,child.attrib)#分别输出tag attrib text的方法 for i in child: print(i.tag,i.attrib,i.text)
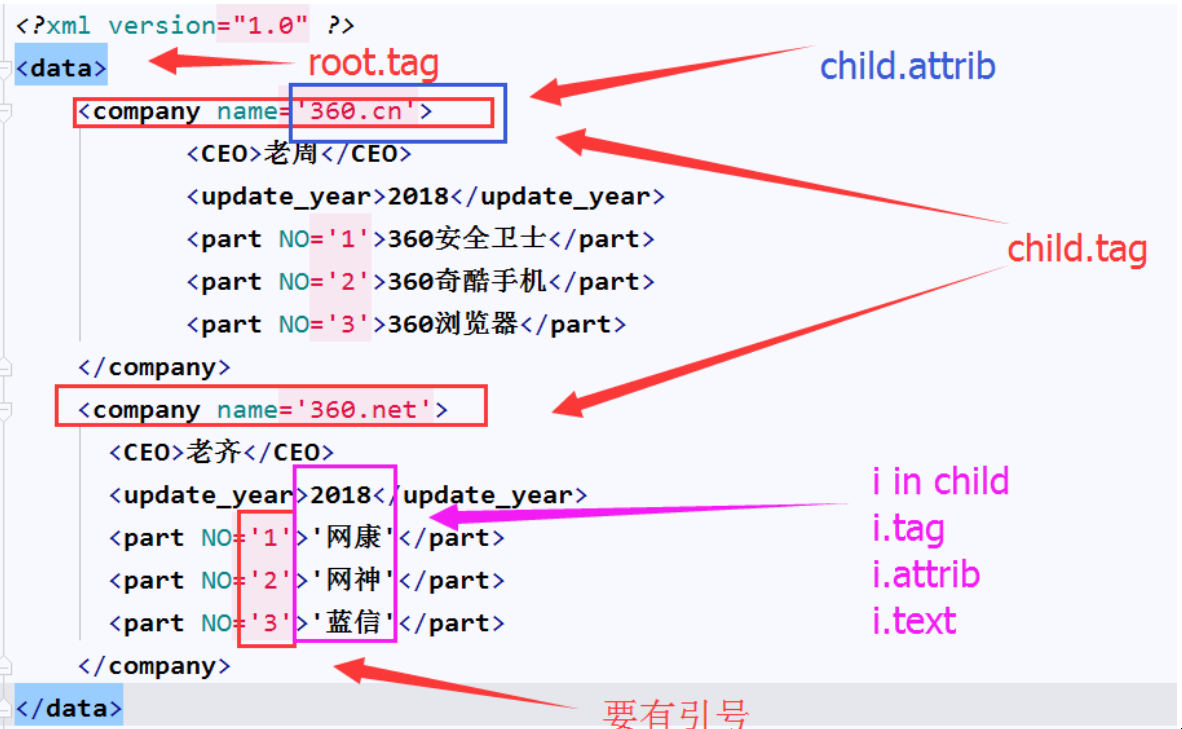
3、只遍历某个节点的方法,iter过滤
for child in FileRoot.iter('part'):#通过iter来找某个关键参数 print(child.tag,child.attrib,child.text) --------------------------------- part {'NO': '1'} 360安全卫士 part {'NO': '2'} 360奇酷手机 part {'NO': '3'} 360浏览器 part {'NO': '1'} 网康 part {'NO': '2'} 网神 part {'NO': '3'} 蓝信
4、内容修改
4.1、打开文件 parse
4.2、获取根 getroot
4.3、修改内容
4.4、增加attrib
4.5、保存文件 write
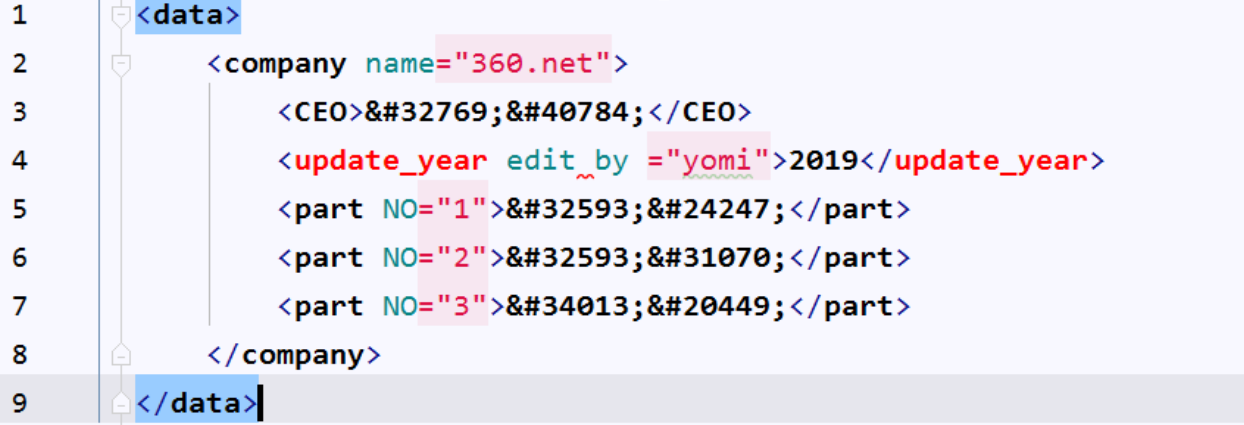
for child in FileRoot.iter('update_year'): new_childtext=int(child.text)+1 获取值 child.text=str(new_childtext) 赋值修改text child.set('edit by ','yomi') set 添加attrib FileTree.write('360_new.xml') wirte写入
<data> <company name="360.cn"> <CEO>老周</CEO> <update_year edit by ="yomi">2019</update_year> <part NO="1">360安全卫士</part> <part NO="2">360奇酷手机</part> <part NO="3">360浏览器</part> </company> <company name="360.net"> <CEO>老齐</CEO> <update_year edit by ="yomi">2019</update_year> <part NO="1">网康</part> <part NO="2">网神</part> <part NO="3">蓝信</part> </company> </data> ------------------ <?xml version="1.0" encoding="UTF-8"?> <data> <company name='360.cn'> <CEO>老周</CEO> <update_year>2018</update_year> <part NO='1'>360安全卫士</part> <part NO='2'>360奇酷手机</part> <part NO='3'>360浏览器</part> </company> <company name='360.net'> <CEO>老齐</CEO> <update_year>2018</update_year> <part NO='1'>网康</part> <part NO='2'>网神</part> <part NO='3'>蓝信</part> </company> </data>
5、条件删除
删除node
使用findall和find结合来完成删除
for company in FileRoot.findall('company'): if company.find('CEO').text=='老周': print('----------------') for i in company: print(i.tag,i.text) FileRoot.remove(company) FileTree.write('360_deltest.xml') ----------------------- CEO 老周 update_year 2019 part 360安全卫士 part 360奇酷手机 part 360浏览器
6、创建新的xml
#第一步 内存中生成 #建立根节点并命名 newroot=ET.Element() 生成根节点 SubElement() 生成子节点
#第二步写入文件 #ElementTree生成这个树 #dump(根)可以输出这个xml #生成根 school_db newroot=ET.Element('SCHOOL_DB') #生成子节点,添加attrib school1=ET.SubElement(newroot,'SCHOOL1',attrib={'校名':'北京大学'}) school2=ET.SubElement(newroot,'SCHOOL2',attrib={'校名':'清华大学'}) #生成子节点的子节点 history1=ET.SubElement(school1,"history") history2=ET.SubElement(school2,"history") score1=ET.SubElement(school1,'score') score2=ET.SubElement(school2,'score') #设置子节点的text history1.text='100' history2.text='120' score1.text='687' score2.text='666' #生成这个树结构 newxml_tree=ET.ElementTree(newroot) newxml_tree.write('newtree.xml',encoding='utf-8',xml_declaration=True)#此处文件已经写完 ET.dump(newroot)#相当于close句柄 #dump可以输出这个root

五、configparser模块的使用 -- 配置文件模块
1、生成 configer 文件的方法 parser()
import configparser #导入模块 configfile=configparser.ConfigParser()#生成要处理的file对象 configfile['baidu']={} #定义节点 configfile['tencent']={} configfile['alibaba']={} configfile['baidu']={ 'url':'www.baidu.com', 'location':'beijing', 'ceo':'李彦宏' }#节点赋值 #节点赋值方法二 configfile['tencent']['url']='www.qq.com' configfile['tencent']['location']='shenzhen' configfile['tencent']['ceo']='马化腾' #节点赋值方法三 ali=configfile['alibaba'] ali['url']='www.taobao.com' ali['location']='' ali['ceo']='NULL' 保存文件 with open('tmp.conf','w',encoding='utf-8')as f: configfile.write(f) ************************** 效果展示 [baidu] url = www.baidu.com location = beijing ceo = 李彦宏 [tencent] url = www.qq.com location = shenzhen ceo = 马化腾 [alibaba] url = www.taobao.com location = ceo = NULL
2、读取配置文件
需要知道print(file)、i in file 、print(file.sections())、i in file.sections()、file[i][j]这些的区别
file=configparser.ConfigParser()#做个对象 file.read('tmp.conf',encoding='utf-8')#给对象读文件 for i in file:#每个配置文件中都有default print(i) print(file.sections()) #print sections 不包括default for i in file.sections(): print(file[i]) for j in file[i]: print(j,file[i][j]) #使用循环的方式能知道config中又哪些key 以及values ----------------------------- DEFAULT baidu tencent alibaba ['baidu', 'tencent', 'alibaba'] <Section: baidu> url www.baidu.com location beijing ceo 李彦宏 <Section: tencent url www.qq.co location shenzhen ceo 马化腾 <Section: alibaba> url www.taobao.com location ceo NULL
3、删除节点 remove_section()
file.remove_section('baidu') print(file.sections()) #with open () as f: # file.write(f) #修改后记得写入文件 ['tencent', 'alibaba']
六、hashlib 模块,包含两个部分hash sha,两种摘要算法
Sha:security hash,sha比hash更安全
1、如何md5
x=Hashlib.md5()#定义一个变量 x.update(b‘’)#或者 x.update(‘’.encode(‘’)) print(x.hexdigest())#三步骤
2、多次update的情况,判断是叠加还是重新来
mm.update('中文'.encode('utf-8'))#中文的加密方式encode print(mm.hexdigest()) mm.update(b'hello') print(mm.hexdigest()) mmm.update('中文hello'.encode('utf-8')) print(mmm.hexdigest())#证明update是一直叠加的
说明:
mm分两次一次update了hello 一次update了中文
Mmm update一次(’中文hello’)
对比发现两次的md5值一致,证明update是一直叠加的
3、sha的使用
#和md5一样的方式 s=hashlib.sha512()#定义变量 s.update(b'hello')#update print(s.hexdigest())#密码长度变长
4、hmac模块
#hmac.new的使用 h=hmac.new(b'mykey',b'mymessage')#组合一个key再来摘要算法 print(h.hexdigest())
import hashlib m=hashlib.md5() mm=hashlib.md5() mmm=hashlib.md5() m.update(b'hello') #要加密成相应的字节格式进行hash print(m.hexdigest())#5d41402abc4b2a76b9719d911017c592 print(m.digest()) #b']A@*xbcK*vxb9qx9dx91x10x17xc5x92'不用管这个,记住使用hexdigest即可 mm.update('中文'.encode('utf-8'))#中文的加密方式encode print(mm.hexdigest()) mm.update(b'hello') print(mm.hexdigest()) mmm.update('中文hello'.encode('utf-8')) print(mmm.hexdigest())#证明update是一直叠加的 s=hashlib.sha512() s.update(b'hello') print(s.hexdigest())#密码长度变长 import hmac h=hmac.new(b'mykey',b'mymessage')#组合一个key再来摘要算法 print(h.hexdigest()) -------------------------------------------------- 5d41402abc4b2a76b9719d911017c592 b']A@*xbcK*vxb9qx9dx91x10x17xc5x92'#digest的输出 a7bac2239fcdcb3a067903d8077c4a07 878450a797d671e43cc656b97c7bddd8 878450a797d671e43cc656b97c7bddd8 9b71d224bd62f3785d96d46ad3ea3d73319bfbc2890caadae2dff72519673ca72323c3d99ba5c11d7c7acc6e14b8c5da0c4663475c2e5c3adef46f73bcdec043 d811630c4e62c6ef90d1bfe540212aaf
注意点:一般用hexdigest十六进制输出,了解一下digest的输出格式。