数值型
1、统计值max,min,mean,std
Series.describe(percentiles=[.05, .25, .75, .95])
2、离散化
将连续值排序后分成一个个区间,然后进行将列属性当中类别型对待,可以进行one-hot编码
在pandas中pd.cut(arr, n)可以将arr进行n等分,也可以进行不均等切分,使用pd.qcut()
为何这样处理:用户购买的商品价格可能只在某一个固定小区间,与其他区间所成的比例不同
离散化可以带来一些非线性的特征
离散化的方法:
1)等宽法
2)等频法
3)基于聚类分析的方法
3、幅度调整
一般在最后处理,将数值幅度调整到[0,1]
类别型
1、one-hot编码 又叫哑变量
可以使用pd.get_dummies()
2、hash与聚类处理
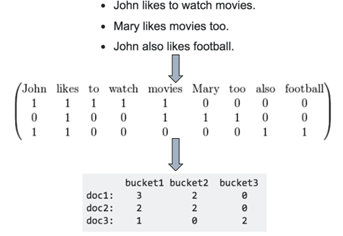
3、统计每个类别变量下各个target比例,转成数字型
举例:histogram映射
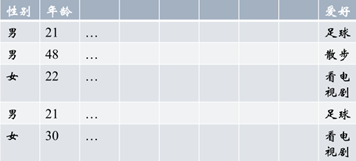
男生人数3,女生人数2,爱好类别3(决定向量维数是3,分别是散步,足球,看电视剧)
男生中爱好的类别数2,女生爱好的类别数1
à男[1/3, 2/3, 0] 女[0, 0, 1],表示有100%的女生喜欢看电视剧,其他爱好的人数为0
时间型
既可以看成连续值,也可以看成离散值
1)连续值
持续时间(单页浏览时长)
间隔时间(上次购买/点击离现在的时间)
2)离散值
一天中哪个时间段
一周中星期几
一年中哪个星期
一年中哪个季度
工作日/周末
文本型
1、词袋(bag of words)
1)单词以词频表示
先获得单词列表,然后将每个文档表示成单词表长度的向量
from sklearn.feature_extraction.txt import CountVectorizer
#将文本向量表示
vectorizer = CountVectorizer(min_df=1)
corpus = [
'This is the first document.',
'This is the second second document.',
'And the third one.',
'Is this the first document?' ]
X = vectorizer.fit_transform(corpus)
X.shape = (4, 9) #4表示有4个句子,9表示单词表长度是9
2)单词以ti-idf权重表示
TF(t) = (词t在当前文中出现次数)/(t在全部文档中出现次数)
IDF(t) = ln(总文档数/含t 的文档数)
TF-IDF权重=TF(t)×IDF(t)
from sklearn.feature_extraction.text import TfidfVectorizer
vectorizer = TfidfVectorizer(min_df=1)
vectorizer.fit_transform(corpus)
3)把词袋中的词扩充到n-gram
CountVectorizer(ngram_range=(1, 2))
2、word2vec
word2vec将每个词映射到一个稠密向量