目标
1、根据热水器采集到的数据,划分一次完整用水数据。
2、在划分好的一次完整用水事件中,识别出洗浴事件。
数据预处理
1、原始数据集太大,进行数据抽取
2、由于热水器采集的用水数据属性较多,我们只选择与分析目标相关的属性。
3、如何划分一次完整的用水事件呢?
如果水流量为0的状态记录之间的时间间隔超过一个阈值T,则从该段水流量为0的状态记录向前找到最后一条水流量不为0的用水记录作为上一次用水事件的结束;向后找到水流量不为0的状态记录作为下一个用水事件的开始。
实现方法:
只取水流量>0的值,然后对过滤后的数据进行相邻时间差分运算,差分结果大于给定阈值的差分结果保留下来,统计所有值的个数,就是用水事件数。
data = data[data[u'水流量'] > 0] #只要流量大于0的记录
d = data[u'发生时间'].diff() > threshold #相邻时间作差分,比较是否大于阈值
data[u'事件编号'] = d.cumsum() + 1 #通过累积求和的方式为事件编号
4、阈值寻优模型:
对用户某时间段不同用水时间间隔阈值事件划分个数和划分阈值作图,
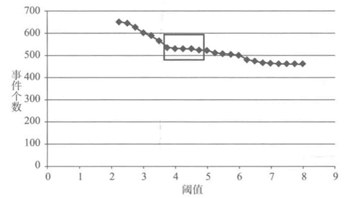
在某段阈值范围内,下降趋势明显,说明在该段阈值范围内,用户的停顿习惯比较集中。在趋势比较平稳部分,说明在对应段阈值范围内,用户的用水停顿习惯趋于稳定,所以取该段时间开始作为阈值,既不会将短的用水事件合并,也不会将长的用水事件拆开。
如何使用程序识别这个最优的阈值呢?
对每一个点求出一个斜率指标,这个指标不是改点和相邻点形成的直线的斜率值,而是从改点往后选取n(3-6)个点,这n个点的相邻点可以求出一个斜率值,将所有的斜率值求出平均值,作为起始点的斜率指标k。如果k<1,就将该点作为最优的阈值点。1是经过实际数据验证的一个专家阈值。当不存在K<1时,则找所有阈值中斜率指标最小的阈值,如果该阈值的斜率指标小于5,则取该阈值作为用水事件划分的阈值,如果该阈值的斜率指标不小于5,则阈值取默认值的阈值为4分钟。其中,斜率指标小于5是一个专家阈值。
代码实现:
n = 4 #使用以后四个点的平均斜率
threshold = pd.Timedelta(minutes = 5) #专家阈值
data = pd.read_excel(inputfile)
data[u'发生时间'] = pd.to_datetime(data[u'发生时间'], format = '%Y%m%d%H%M%S')
data = data[data[u'水流量'] > 0] #只要流量大于0的记录
def event_num(ts):
d = data[u'发生时间'].diff() > ts #相邻时间作差分,比较是否大于阈值
return d.sum() + 1 #这样直接返回事件数
dt = [pd.Timedelta(minutes = i) for i in np.arange(1, 9, 0.25)]
h = pd.DataFrame(dt, columns = [u'阈值']) #定义阈值列
h[u'事件数'] = h[u'阈值'].apply(event_num) #计算每个阈值对应的事件数
h[u'斜率'] = h[u'事件数'].diff()/0.25 #计算每两个相邻点对应的斜率
h[u'斜率指标'] = pd.rolling_mean(h[u'斜率'].abs(), n) #采用后n个的斜率绝对值平均作为斜率指标
ts = h[u'阈值'][h[u'斜率指标'].idxmin() - n]
#注:用idxmin返回最小值的Index,由于rolling_mean()自动计算的是前n个斜率的绝对值平均
#所以结果要进行平移(-n)
if ts > threshold:
ts = pd.Timedelta(minutes = 4)
5、属性构造
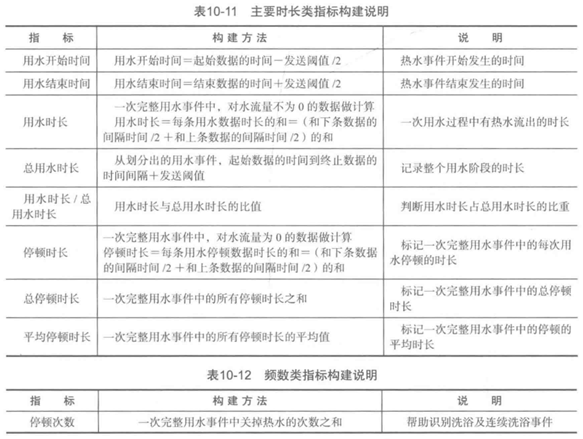
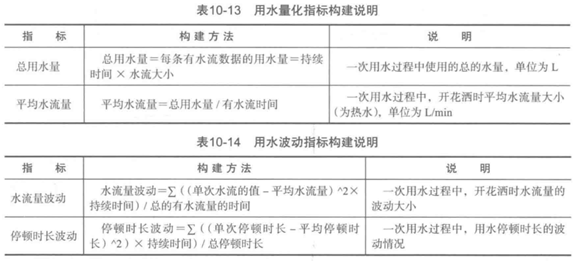
本案例研究的是用水行为,可构造4类指标:时长指标、频率指标、用水的量化指标、用水的波动指标。
属性构建说明:
模型构建
使用MLP进行建模
一般2层的神经网络可以解决大部分分类问题。经反复验证得到两个隐层的 隐节点数分别为17,10时分类效果较好。
代码实现:
model = Sequential() #建立模型
model.add(Dense(11, 17)) #添加输入层、隐藏层的连接
model.add(Activation('relu')) #以Relu函数为激活函数
model.add(Dense(17, 10)) #添加隐藏层、隐藏层的连接
model.add(Activation('relu')) #以Relu函数为激活函数
model.add(Dense(10, 1)) #添加隐藏层、输出层的连接
model.add(Activation('sigmoid')) #以sigmoid函数为激活函数
#编译模型,损失函数为binary_crossentropy,用adam法求解
model.compile(loss='binary_crossentropy', optimizer='adam', class_mode="binary")
model.fit(x_train, y_train, nb_epoch = 100, batch_size = 1) #训练模型