1.概念
协议是指计算机通信网络中两台计算机之间进行通信所必须共同遵守的规定或规则,超文本传输协议(HTTP)是一种通信协议,它允许将超文本标记语言(HTML)文档从Web服务器传送到客户端的浏览器。
HTTP协议,即超文本传输协议(Hypertext transfer protocol)。是一种详细规定了浏览器和万维网(WWW = World Wide Web)服务器之间互相通信的规则,通过因特网传送万维网文档的数据传送协议。
HTTP协议是用于从WWW服务器传输超文本到本地浏览器的传送协议。它可以使浏览器更加高效,使网络传输减少。它不仅保证计算机正确快速地传输超文本文档,还确定传输文档中的哪一部分,以及哪部分内容首先显示(如文本先于图形)等。
HTTP是一个应用层协议,由请求和响应构成,是一个标准的客户端服务器模型。HTTP是一个无状态的协议。
在Internet中所有的传输都是通过TCP/IP进行的。HTTP协议作为TCP/IP模型中应用层的协议也不例外。HTTP协议通常承载于TCP协议之上,有时也承载于TLS或SSL协议层之上,这个时候,就成了我们常说的HTTPS。(HTTP默认的端口号为80,HTTPS的端口号为443。)

****浏览网页是HTTP的主要应用,但是这并不代表HTTP就只能应用于网页的浏览。HTTP是一种协议,只要通信的双方都遵守这个协议,HTTP就能有用武之地。比如咱们常用的QQ,迅雷这些软件,都会使用HTTP协议(还包括其他的协议)。
2.HTTP协议的特点
HTTP协议永远都是客户端发起请求,服务器回送响应。
HTTP协议,无法实现在客户端没有发起请求的时候,服务器将消息推送给客户端。
HTTP协议特点:
1.支持客户/服务器模式。支持基本认证和安全认证。
2.简单快速:客户向服务器请求服务时,只需传送请求方法和路径。请求方法常用的有GET、HEAD、POST。每种方法规定了客户与服务器联系的类型不同。由于HTTP协议简单,使得HTTP服务器的程序规模小,因而通信速度很快。
3.灵活:HTTP允许传输任意类型的数据对象。正在传输的类型由Content-Type加以标记。
4.HTTP 0.9和1.0使用非持续连接:限制每次连接只处理一个请求,服务器处理完客户的请求,并收到客户的应答后,即断开连接。
HTTP 1.1使用持续连接:不必为每个web对象创建一个新的连接,一个连接可以传送多个对象,采用这种方式可以节省传输时间。
5.无状态:HTTP协议是无状态协议。无状态是指协议对于事务处理没有记忆能力。缺少状态意味着如果后续处理需要前面的信息,则它必须重传,这样可能导致每次连接传送的数据量增大。
无状态的协议:
协议的状态是指下一次传输可以“记住”这次传输信息的能力。
http是不会为了下一次连接而维护这次连接所传输的信息,为了保证服务器内存。
(比如客户获得一张网页之后关闭浏览器,然后再一次启动浏览器,再登陆该网站,但是服务器并不知道客户关闭了一次浏览器。)
由于Web服务器要面对很多浏览器的并发访问,为了提高Web服务器对并发访问的处理能力,在设计HTTP协议时规定Web服务器发送HTTP应答报文和文档时,不保存发出请求的Web浏览器进程的任何状态信息。这有可能出现一个浏览器在短短几秒之内两次访问同一对象时,服务器进程不会因为已经给它发过应答报文而不接受第二期服务请求。由于Web服务器不保存发送请求的Web浏览器进程的任何信息,因此HTTP协议属于无状态协议(Stateless Protocol)。
HTTP协议是无状态的和Connection: keep-alive的区别:
无状态是指协议对于事务处理没有记忆能力,服务器不知道客户端是什么状态。从另一方面讲,打开一个服务器上的网页和你之前打开这个服务器上的网页之间没有任何联系。
HTTP是一个无状态的面向连接的协议,无状态不代表HTTP不能保持TCP连接,更不能代表HTTP使用的是UDP协议(无连接)。
从HTTP/1.1起,默认都开启了Keep-Alive,保持连接特性,简单地说,当一个网页打开完成后,客户端和服务器之间用于传输HTTP数据的TCP连接不会关闭,如果客户端再次访问这个服务器上的网页,会继续使用这一条已经建立的连接。
Keep-Alive不会永久保持连接,它有一个保持时间,可以在不同的服务器软件(如Apache)中设定这个时间。
3.工作流程
一次HTTP操作称为一个事务,其工作过程可分为四步:
1)首先客户机与服务器需要建立连接。只要单击某个超级链接,HTTP的工作开始。
2)建立连接后,客户机发送一个请求给服务器,请求方式的格式为:统一资源标识符(URL)、协议版本号,后边是MIME信息包括请求修饰符、客户机信息和可能的内容。
3)服务器接到请求后,给予相应的响应信息,其格式为一个状态行,包括信息的协议版本号、一个成功或错误的代码,后边是MIME信息包括服务器信息、实体信息和可能的内容。
4)客户端接收服务器所返回的信息通过浏览器显示在用户的显示屏上,然后客户机与服务器断开连接。
如果在以上过程中的某一步出现错误,那么产生错误的信息将返回到客户端,有显示屏输出。对于用户来说,这些过程是由HTTP自己完成的,用户只要用鼠标点击,等待信息显示就可以了。
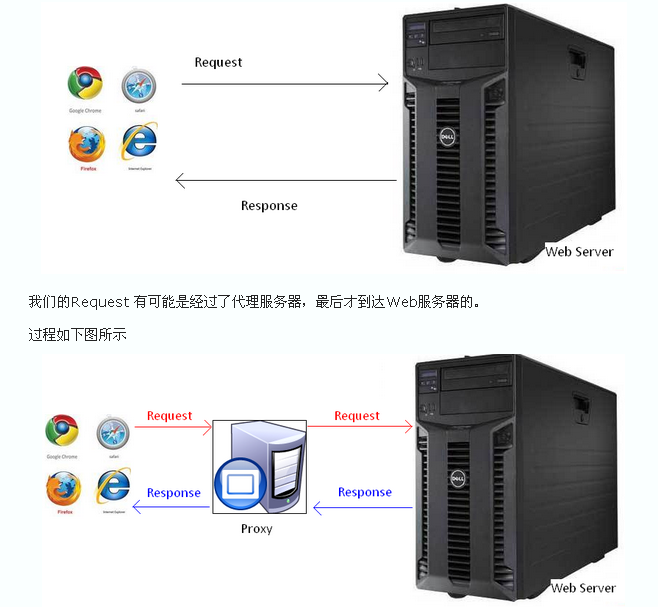
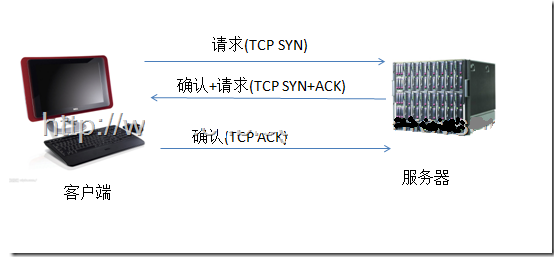
在HTTP开始传输之前,先进行TCP链接的“三次握手”!!
HTTP是基于传输层的TCP协议,而TCP是一个端到端的面向连接的协议。所谓的端到端可以理解为进程到进程之间的通信。
在TCP三次握手之后,建立了TCP连接,此时HTTP就可以进行传输了。一个重要的概念是面向连接,既HTTP在传输完成之间并不断开TCP连接。在HTTP1.1中(通过Connection头设置)这是默认行为。
4.HTTP协议信息
GET和POST的区别:
1、GET提交的数据会放在URL之后,以分割URL和传输数据,参数之间以&相连,如EditPosts.aspx?name=test1&id=123456. POST方法是把提交的数据放在HTTP包的Body中。
2、GET提交的数据大小有限制,最多只能有1024字节(因为浏览器对URL的长度有限制),而POST方法提交的数据没有限制。
3、GET方式需要使用Request.QueryString来取得变量的值,而POST方式通过Request.Form来获取变量的值。
4、GET方式提交数据,会带来安全问题,比如一个登录页面,通过GET方式提交数据时,用户名和密码将出现在URL上,如果页面可以被缓存或者其他人可以访问这台机器,就可以从历史记录获得该用户的账号和密码。
请求报文头:(分为请求行,实体头,头部结束标志:回车标记!)
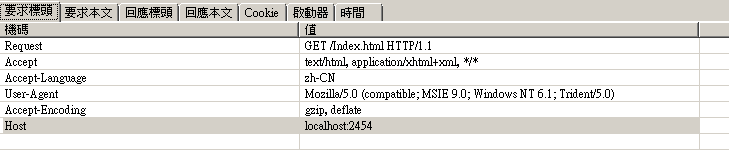
1.Request GET /Index.html HTTP/1.1 --> 请求的方式,请求的页面地址,HTTP协议的版本。 --请求行
2.Accept text/html, application/xhtml+xml, */* --> 浏览器告诉服务器,浏览器能处理的数据类型
3.Accept-Language zh-CN --> 浏览器的语言版本
4.User-Agent Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0) --> 浏览器告诉服务器,浏览器用到的操作系统的版本
5.Accept-Encoding gzip, deflate --> 浏览器告诉服务器,浏览器采用的压缩方式 (压缩的操作是由服务器操作的,按照浏览器支持的压缩方式,由服务器按照浏览器这个算法来压缩!!)
6.Host localhost:2454 --> 服务器的地址
**Connection Keep-Alive --> 保持长连接。HTTP1.1 自行规定的
响应报文头:(分为响应行,实体头,头部结束标志:回车标记!)

1.回應 HTTP/1.1 304 Not Modified --> HTPP协议的版本,响应状态码
2.Content-Type text/html --> 返回的数据类型
3.Content-Length 223 --> 响应报文体的长度
5.解决HTTP无状态的问题
1.通过Cookies保存状态信息
通过Cookies,服务器就可以清楚的知道请求2和请求1来自同一个客户端。

2.通过Session保存状态信息
Session机制是一种服务器端的机制,服务器使用一种类似于散列表的结构(也可能就是使用散列表)来保存信息。
当程序需要为某个客户端的请求创建一个session的时候,服务器首先检查这个客户端的请求里是否已包含了一个session标识 - 称为 session id,如果已包含一个session id则说明以前已经为此客户端创建过session,服务器就按照session id把这个 session检索出来使用(如果检索不到,可能会新建一个),如果客户端请求不包含session id,则为此客户端创建一个session并且生成一个与此session相关联的session id,session id的值应该是一个既不会重复,又不容易被找到规律以仿造的字符串,这个session id将被在本次响应中返回给客户端保存。
Session的实现方式:
1、使用Cookie来实现
2、使用URL回写来实现
**Cookies和Session的明细的不同点
3.通过表单变量保持状态
除了Cookies之外,还可以使用表单变量来保持状态,比如Asp.net就通过一个叫ViewState的Input=“hidden”的框来保持状态,比如:
<input type="hidden" name="__VIEWSTATE" id="__VIEWSTATE" value="/wEPDwUKMjA0OTM4MTAwNGRkXUfhlDv1Cs7/qhBlyZROCzlvf5U=" />
这个原理和Cookies大同小异,只是每次请求和响应所附带的信息变成了表单变量。
4.通过QueryString保持状态
QueryString通过将信息保存在所请求地址的末尾来向服务器传送信息,通常和表单结合使用,一个典型的QueryString比如:www.xxx.com/xxx.aspx?var1=value&var2=value2