Python 有几种网页解析器?
1、 正则表达式
2、html.parser (Python自动)
3、BeautifulSoup(第三方)(功能比较强大) 是一个HTML/XML的解析器
4、lxml (第三方)
BeautifulSoup 栗子:
地址:https://www.crummy.com/software/BeautifulSoup/bs4/download/
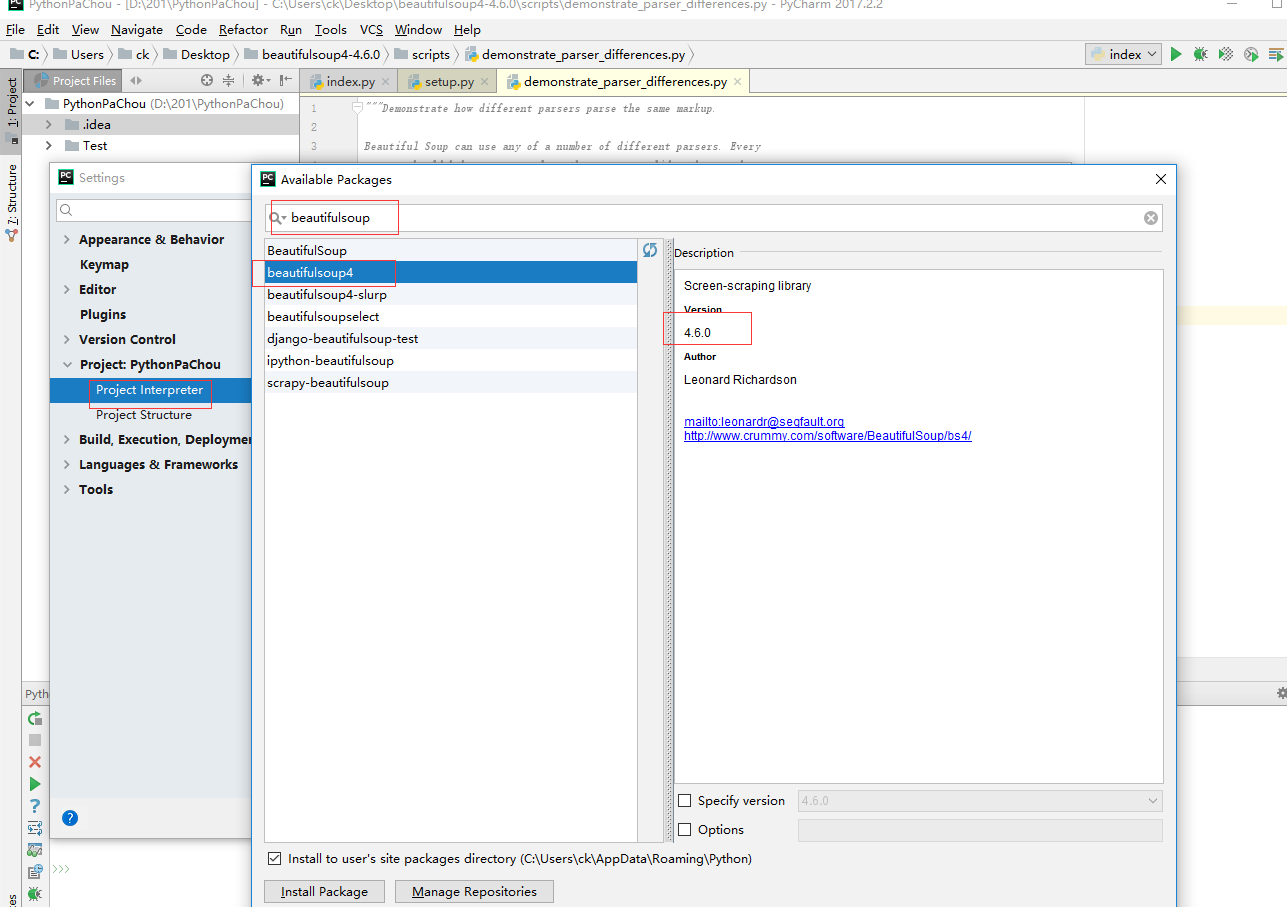
PyCharm安装方法
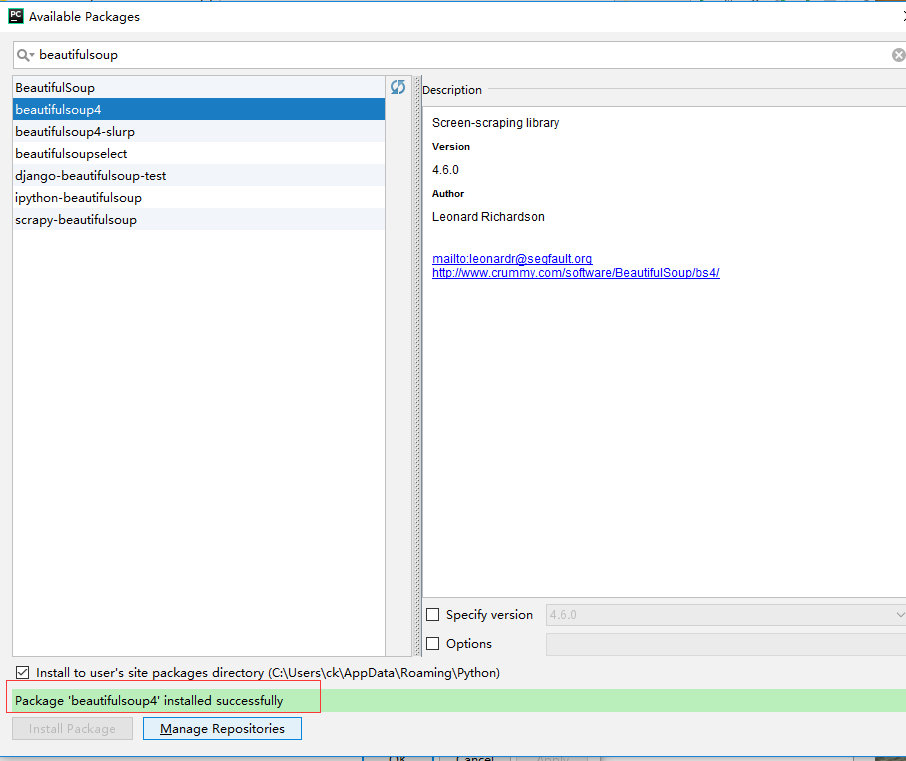
file → Settings → Project Interpreter(这一步需要你自己找一下),点击右边 "+" 加号,输入 beautifulsoup 选择对应的版本就ok了,上图:
来一个栗子:
from bs4 import BeautifulSoup import re html_doc = """ <html><head><title>The Dormouse's story</title></head> <body> <p class="title"><b>The Dormouse's story</b></p> <p class="story">Once upon a time there were three little sisters; and their names were <a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>, <a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and <a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>; and they lived at the bottom of a well.</p> <p class="story">...</p> """ soup = BeautifulSoup(html_doc,'html.parser',from_encoding='utf-8') print('获取所有的连接') links = soup.find_all('a') for link in links: print(link.name,link['href'],link.get_text()) print('获取lacie的连接') link_node = soup.find('a',href='http://example.com/lacie') print(link.name, link['href'], link.get_text()) #模糊匹配 print('正则匹配') link_node = soup.find('a',href=re.compile(r'lll')) print(link.name, link['href'], link.get_text()) print('获取P段落文字') param = input('请输入要检索的样式名称:') p_node = soup.find('p',class_='story') print(p_node.name, p_node.get_text())