1.stream Map() FlatMap()区别
map: 对于Stream中包含的元素使用给定的转换函数进行转换操作,新生成的Stream只包含转换生成的元素。
flatMap:和map类似,不同的是其每个元素转换得到的是Stream对象,会把子Stream中的元素压缩到父集合中。
下面这张图比较直观

跑一下,注意标红:

2.wait() notify() notifyAll() 语法 场景
wait()、notify()、notifyAll()必须在同步块/同步方法内执行,因为只有在调用线程在获得对象的锁时,才能调用对象的wait()、notify()、notifyAll()方法,如果在未获得对象的锁的情况下调用对象的这三个方法,将抛出IllegalMonitorStateException异常。
3.Redis Aof Rdb 持久化区别
RDB持久化在指定时间间隔内生成数据集的时间点快照。
优点:保存某个时间点的数据集,适合备份,恢复数据集的速度快。
缺点:数据量大时,保存速度慢,如果快照频率慢,故障停机时,可能会丢失大量数据。
AOF持久化记录服务器所执行的所有写操作,通过重新执行命令还原数据集。
优点:AOF使redis非常耐久,可设置不同的fsync策略,AOF文件是一个只进行追加操作的日志文件,故障停机时,丢失数据量小。
缺点:对于相同的数据集,AOF文件的体积可能要大于RDB文件体积,根据不同的fsync策略,AOF速度可能会慢于RDB速度。
4.唯一索引 普通索引 性能
- 查询过程:select id from table where cal = 6;
不管哪种索引,都先从B+树的树根开始,按层搜索找到叶子节点,先找到数据页,再根据二分发定位记录。
对于普通索引,找到满足条件的记录后,会继续查找下面的记录,知道找到第一个不满足条件的记录为止。
对于唯一索引,因为索引项定义了唯一性,所以找到满足条件的记录后就会停止检索。
在查询过程中,普通索引相对与唯一索引仅多做了查找和判断下一条操作,性能差别不大,除非通过普通索引查到的第一条符合条件的记录在数据页的最后一条,这种情况会复杂一些,但是概率很低。
- 更新过程:
首先要理解一下什么是change buffer:当需要更新一个数据页的某条记录时,如果这个数据页在内存中就直接更新,如果不在内存中,在不影响数据一致性的前提下,InooDB就会将更新操作缓存到change buffer中,这样就无需从磁盘中读取这个数据页,当下次有查询操作访问到这个数据页是,InooDB将数据页读入内存,并且执行change buffer中有关这个数据页的操作。将change buffer记录的操作应用到原数据页的操作叫merge,除访问数据页会触发merge外,后台也有线程会定期merge。使用change buffer 主要是减少IO操作,并且提高内存利用率。对与写多读少对业务,使用change buffer效果好。
对于唯一索引来说,所有的更新操作都要判断操作是否违背唯一性约束,也就是在插入记录之前,会先检索表中是否已经存在符合条件都记录,所以必须先将数据页读到内存,所以使用唯一索引更新操作时,不能使用change buffer。只有唯一索引更新操作时,才可以使用change buffer。
总而言之,更新操作中,普通索引性能较高。
参考:https://www.cnblogs.com/jimmyhe/p/11027141.html
5.stream peek()和map()的区别
peek()的入参为Consumer,Consumer的实现类仅有一个方法,并且返回类型为void。
map()的入参为Function,Function实现类的方法有返回值。
总结:peek接收一个没有返回值的λ表达式,可以做一些输出,外部处理等。map接收一个有返回值的λ表达式,之后Stream的泛型类型将转换为map参数λ表达式返回的类型。
6.单例模式
- 双锁模式
public class Singleton { private Singleton(){} private static volatile Singleton instance; public static Singleton getInstance(){ if(instance == null){ synchronized(Singleton.class){ if(instance == null){ instance = new Singleton(); } } } return instance; } }
- 静态内部类
public class Singleton { private Singleton(){} private static class SingletonHolder { private static Singleton instance = new Singleton(); } public static Singleton getInstance(){ return SingletonHolder.instance; } }
- 枚举
public enum Singleton { INSTANCE; public void fun(){} }
7.快速失败机制
8.jvm内存模型
- 程序计数器 作为当前线程的行号指示器
- java虚拟机栈 存储局部变量和部分运行结果
- 本地方法栈 native
- 堆 所有对象实例以及 数组 线程共享
- 方法区 存储类信息 常量 静态变量等
9.HashMap扩容为何是2的N次方
HashMap无论存取操作,都需要计算数据的hash值mod桶的长度,源码中通过hash&(n-1)位运算计算mod值,n为桶的长度,如果n为2的幂次方,那么n-1转换为二进制后,每一位都是1,与不同key的哈希值取做&运算,将得到不同的下标,减少碰撞的几率,提高存取的效率。
10.volatile 关键字作用
- 每次针对该变量的操作都激发一次load and save。处理数据时,线程会把值load到本地,处理之后再save回去。使用volatile关键字的变量,保证其在多线程之间的可见性,每次读到volatile关键字修饰的变量,一定是最新的数据。
- 禁止重排序
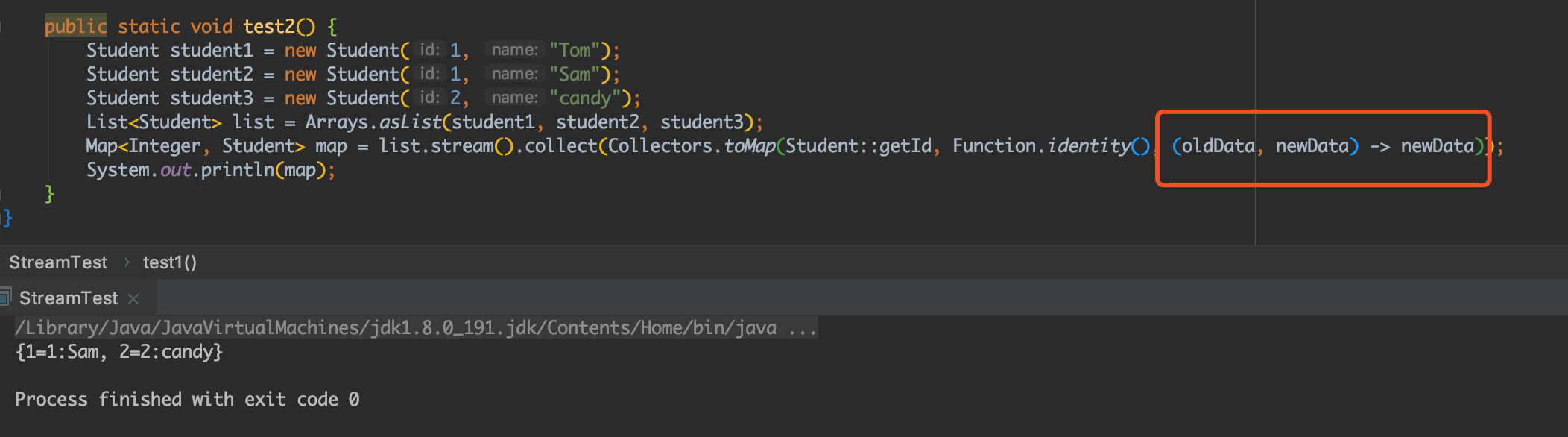
11.Lambda List 转Map 如何键值重复处理
12.线程池创建核心参数以及拒绝策略
- 核心参数
- 四种拒绝策略