https://luajit.org/install.html
LuaJIT的运行环境包括一个用手写汇编实现的Lua解释器和一个可以直接生成机器代码的JIT编译器。Lua代码在被执行之前总是会先被lfn生成LuaJIT自己定义的字节码ByteCode。
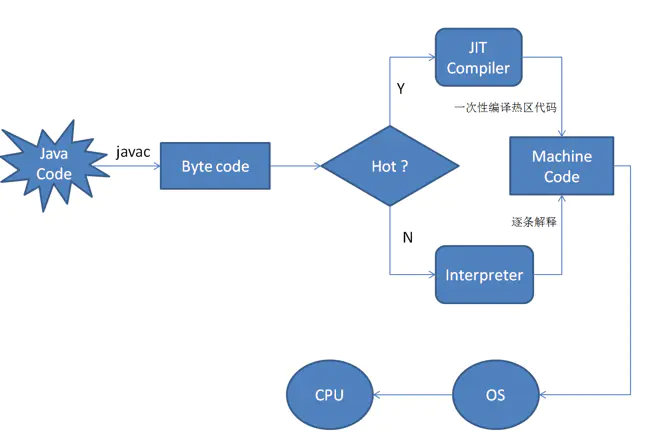
开始时Lua字节码总是被LuaJIT的解释器解释执行,LuaJIT的解释器会在执行字节码时同时记录一些运行时的统计信息,如每个Lua函数调用入口的实际运行次数,还有每个Lua循环的实际执行次数。当这些次数超过某个预设的阈值时,便认为对应的Lua函数入口或对应的Lua循环足够的热,此时便会触发JIT编译器开始工作。
JIT编译器会从热函数的入口或热循环的某个位置开始尝试编译对应的Lua代码路径,编译的过程是把LuaJIT字节码先转换成LuaJIT自己定义的中间码(IR),然后再生成针对目标体系结构的机器码,如x86_64指令组成的机器码。如果当前Lua代码路径上的所有操作都可以被JIT编译器顺利编译,则这条编译过的代码路径便被称为一个trace,在物理上对应一个trace类型的GC对象,即参与Lua GC的对象。
即时编译器
什么是JIT(Just In Time)呢?
程序运行通常有两种方式:静态编译和动态解释,即时编译混合了二者。即时编译是动态编译的一种形式,是一种优化虚拟机运行的技术。
即时编译器会将频繁执行的代码编译成机器码缓存起来,下次调用时将直接执行机器码。相比原生逐条执行虚拟机指令效率更高。而对于那些只执行一次的代码仍然逐条执行。
值得注意的是,即时编译带来的效率提升,并不一定能抵消编译效率的下降。因为当虚拟机执行指令时并不会立即用JIT进行编译,由于只有部分指令需要JIT进行编译,JIT将决定那些代码将被编译。而延迟编译则有助于JIT选择一个最佳的解决方案。
为什么要使用JIT呢?
对于静态编译的缺点是不够灵活、无法支持热更,而且平台兼容性差。而对于动态解释而言,效率低和代码暴露是其主要缺陷。即时编译混合了动态解释和静态编译,在执行效率上要高于解释执行却低于静态编译。安全性上一般都会将源代码转换成字节码。而无论是源码或是字节码,本质上都是资源,因此可采用热更新机制。在兼容性上,由于虚拟机的存在,可以处理不同平台的差异,对用户保持透明。
JVM JIT
即使编译可以分为2种:方法即时编译Method JIT和跟踪编即时译Trace JIT。
以Java为例,实际上是指的是JIT的一个变种:自适应动态编译
简单来说可分为2个步骤
- 跟踪热点函数或
trace,编译成机器码执行,并缓存以供下次使用。 - 非热点函数解释执行
那么为什么只编译热点函数呢?
对于只执行一次的代码而言,解释执行其实是比JIT编译执行要快,对于那些代码JIT编译在执行反而得不偿失。而对于只执行少量次数的代码,即使编译带来的速度的提升也未必能抵消最初编译带来的开销,只有对频繁执行的代码,即使编译才能保证有正面的收益。
luajit下载源码后
make && make install
luajit -b ./hello.lua ./hello.luajit
luajit 执行的lua文件名