SparkSQL简介
一:什么是sparkSQL呢?
SQL是Spark用来处理结构化数据的一个模块,它提供了一个编程抽象叫做DataFrame并且作为分布式SQL查询引擎的作用,实际上它也是一个API。Spark SQL中提供的接口将会提供给Spark更多关于结构化数据和计算的信息。
名词解释:
1.结构化数据:
所有关系型数据库中的数据全部为结构化数据
任何一列数据不可再细分
任何一列的数据都有相同的数据类型
2. DataFrame
在Spark中,DataFrame是一个以命名列方式组织的分布式数据集,等同于关系型数据库中的一个表。DataFrame可以由结构化数据文件转换而来,也可以从Hive中的表得来,以及可以转换自外部数据库
3.抽象编程
抽象编程是通过抽象的方法来减少编程工作量或有效地减轻编程难度称为抽象编程
二:sparkSQL的特点?
(1)集成
将SQL查询与Spark程序无缝对接。
Spark SQL允许您使用SQL或熟悉的DataFrame API查询Spark程序内的结构化数据。
(2)统一的数据访问
以同样的方式连接到任何数据源。
DataFrames和SQL提供了访问各种数据源的常用方式,包括Hive,Avro,Parquet,ORC,JSON和JDBC。 您甚至可以通过这些来源加入数据。
(3)Hive集成
在现有仓库上运行SQL或HiveQL查询。
Spark SQL支持HiveQL语法和UDF,允许您访问现有的Hive仓库。
(4)标准连接
通过JDBC或ODBC连接。
三:SparkSQL总体上由四个模块组成:core、catalyst、hive、hive-Thriftserver:
1)core处理数据的输入输出,从不同的数据源获取数据(RDD、Parquet、json等),将查询结果输出成schemaRDD;
2)catalyst处理查询语句的整个处理过程,包括解析、绑定、优化、物理计划等,说其是优化器,还不如说是查询引擎;
3)hive对hive数据的处理
4)hive-ThriftServer提供CLI(命令行界面)和JDBC/ODBC接口
catalyst处于最核心的部分,其性能优劣将影响整体的性能。

从上图看,catalyst主要的实现组件有:
1)sqlParse,完成sql语句的语法解析功能,目前只提供了一个简单的sql解析器;
2)Analyzer,主要完成绑定工作,将不同来源的Unresolved LogicalPlan和数据元数据(如hive metastore、Schema catalog)进行绑定,生成resolved LogicalPlan;
3)optimizer对resolved LogicalPlan进行优化,生成optimized LogicalPlan;
4)Planner(该对象中定义了一系列的执行策略,这些策略用来指定实际查询时所做的操作。)将LogicalPlan转换成PhysicalPlan;
5)CostModel,主要根据过去的性能统计数据,选择最佳的物理执行计划
四: SparkSQL运行架构
类似于关系型数据库,SparkSQL也是语句也是由Projection(a1,a2,a3)、Data Source(tableA)、Filter(condition)组成,分别对应sql查询过程中的Result、Data Source、Operation,也就是说SQL语句按Result-->DataSource-->Operation的次序来描述的。
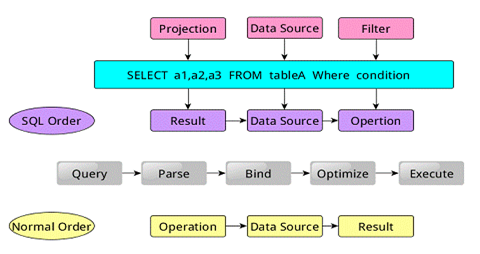
当执行SparkSQL语句的顺序为:
1.对读入的SQL语句进行解析(Parse),分辨出SQL语句中哪些词是关键词(如SELECT、FROM、WHERE),哪些是表达式、哪些是Projection、哪些是Data Source等,从而判断SQL语句是否规范;
2.将SQL语句和数据库的数据字典(列、表、视图等等)进行绑定(Bind),如果相关的Projection、Data Source等都是存在的话,就表示这个SQL语句是可以执行的;
3.一般的数据库会提供几个执行计划,这些计划一般都有运行统计数据,数据库会在这些计划中选择一个最优计划(Optimize);
4.计划执行(Execute),按Operation-->DataSource-->Result的次序来进行的,在执行过程有时候甚至不需要读取物理表就可以返回结果,比如重新运行刚运行过的SQL语句,可能直接从数据库的缓冲池中获取返回结果。
五:SparkSQL的两个分支:
SparkSQL有两个分支,sqlContext和hiveContext,sqlContext现在只支持SQL语法解析器;hiveContext现在支持SQL语法解析器和hivesql语法解析器,默认为hiveSQL语法解析器,用户可以通过配置切换成SQL语法解析器,来运行hiveSQL不支持的语法
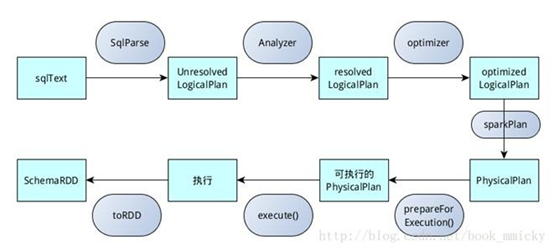
sqlContext总的一个过程如下图所示:
1.SQL语句经过SqlParse解析成UnresolvedLogicalPlan(提取关键字,检查基本的语法,如果有问题下一步直接不能运行);
2.使用analyzer结合数据数据字典(catalog)进行绑定,生成resolvedLogicalPlan;
3.使用optimizer对resolvedLogicalPlan()进行优化,生成optimizedLogicalPlan;
4.使用SparkPlan将LogicalPlan转换成PhysicalPlan;
5.使用prepareForExecution()将PhysicalPlan转换成可执行物理计划;
6.使用execute()执行可执行物理计划;
7.生成SchemaRDD。

hiveContext总的一个过程如下图所示:
1.SQL语句经过HiveQl.parseSql解析成Unresolved LogicalPlan,在这个解析过程中对hiveql语句使用getAst()获取AST树(转为抽象语法树更利于程序的分析),然后再进行解析;
2.使用analyzer结合数据hive源数据Metastore(新的catalog)进行绑定,生成resolved LogicalPlan;
3.使用optimizer(优化器)对resolved LogicalPlan进行优化,生成optimized LogicalPlan,优化前使用了ExtractPythonUdfs(catalog.PreInsertionCasts(catalog.CreateTables(analyzed)))进行预处理;
4.使用hivePlanner将LogicalPlan转换成PhysicalPlan;
5.使用prepareForExecution()将PhysicalPlan转换成可执行物理计划;
6.使用execute()执行可执行物理计划;
7.执行后,使用map(_.copy)将结果导入SchemaRDD。
