1.1为什么选择序列模型
(1)序列模型广泛应用于语音识别,音乐生成,情感分析,DNA序列分析,机器翻译,视频行为识别,命名实体识别等众多领域。
(2)上面那些问题可以看成使用(x,y)作为训练集的监督学习,但是输入与输出的对应关系有非常多的组合,比如一对一,多对多,一对多,多对一,多对多(个数不同)等情况来针对不同的应用。
1.2数学符号
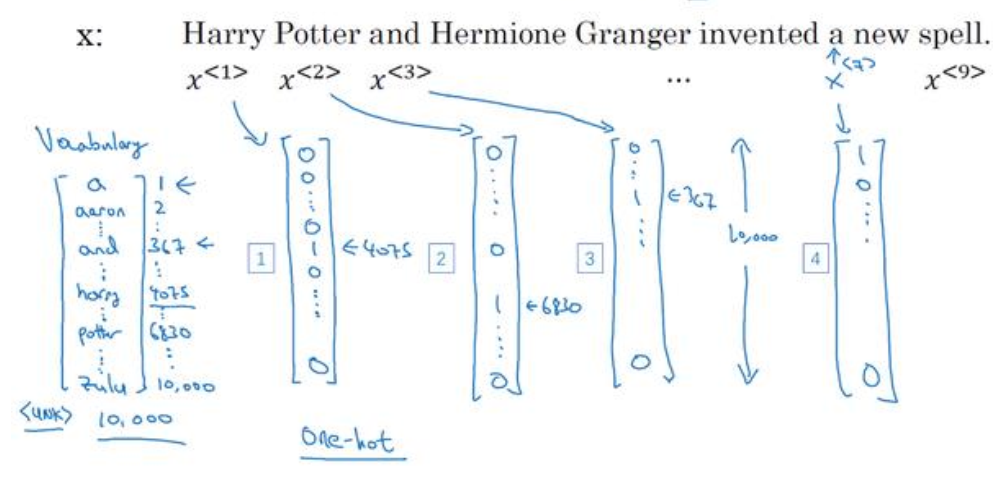
(1)x(i)<t>前面的i表示第i个训练样本,t表示某个序列样本中索引位置,如下面的一句话是一个样本,“and”的索引是3,序列的长度用Tx表示,下面句子中Tx=9。
![]()
(2)单词是无法直接输入到网络中,所以必须转成数子,用数字来表示单词。方法是将数据集中出现次数最多的10000个单词(这里用10000为例,可以更多),然后用one-hot来表示每一个单词,如下图所示:
1.3循环神经网络模型
(1)使用标准网络来做上面的命名实体识别,即找出句子中的人名,会存在两个明显的问题:第一是不同的训练样本的单词数不一样,当然可以使用pad来填充,第二是不能狗共享不同位置上学到的特征,用循环神经网络可以解决这些问题。
(2)循环神经网络将按照下图进行计算:
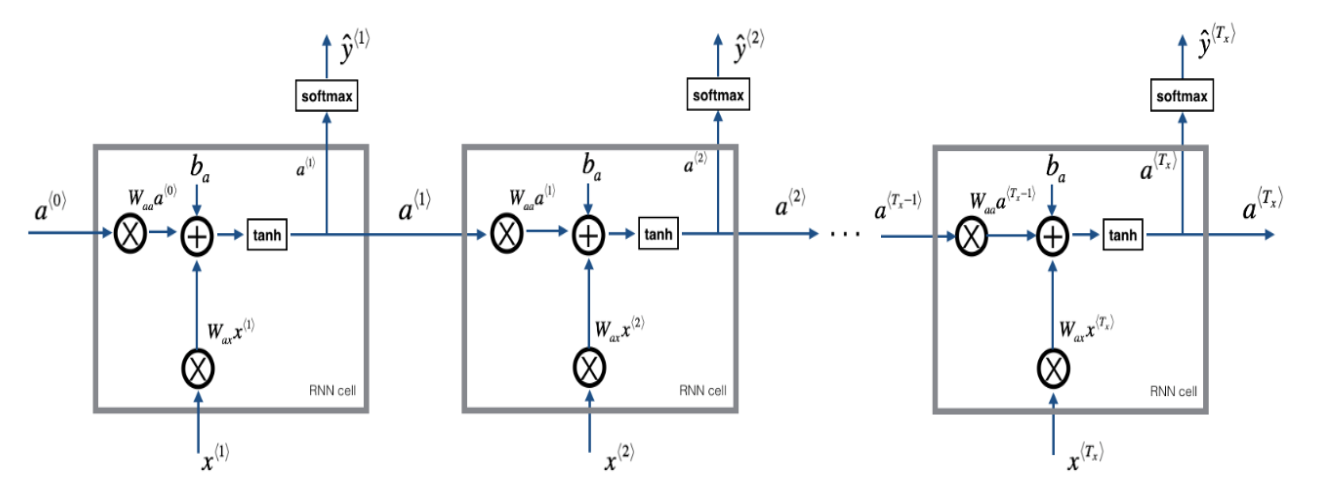
(3)数学式子如下所示:
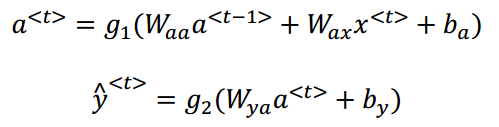
将Waa和Wax合并在一起:
![]()
![]()
得到
![]()
![]()
(4)激活函数常用tanh,另外输出由于是用0,1表示是否是人名,所以用sotfmax激活函数。
1.4通过时间的反向传播
(1)一个元素的代价函数(一个0,1二分类问题,注意下面式子中应该是(1-y<t>)):
![]()
(2)每一个样本的代价函数:
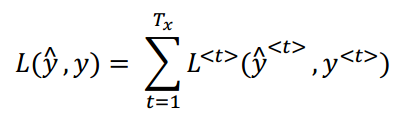
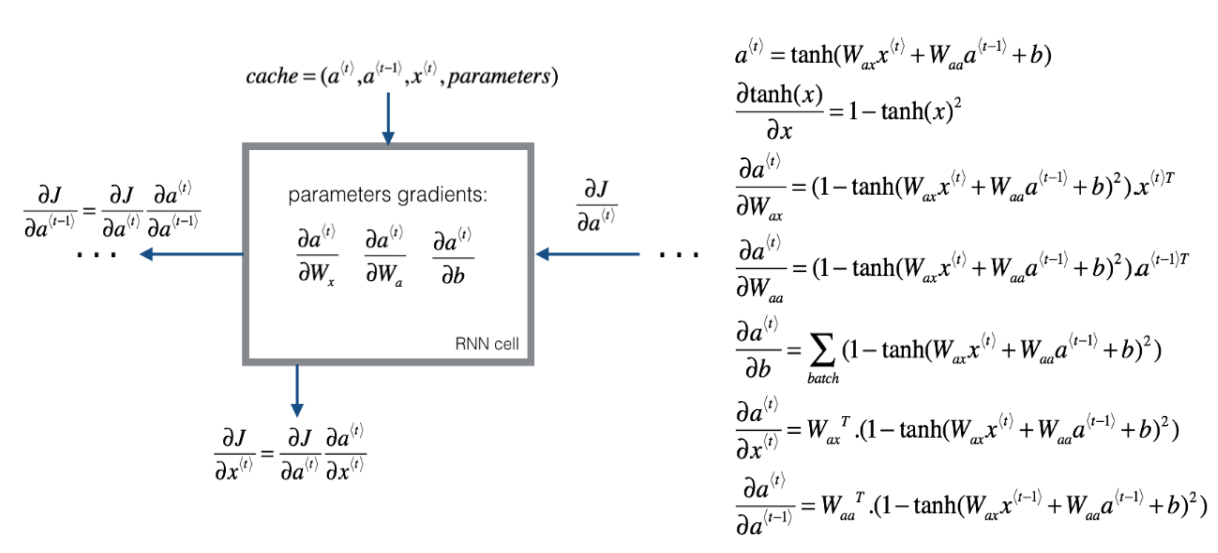
(3)RNN反向传播示意图:
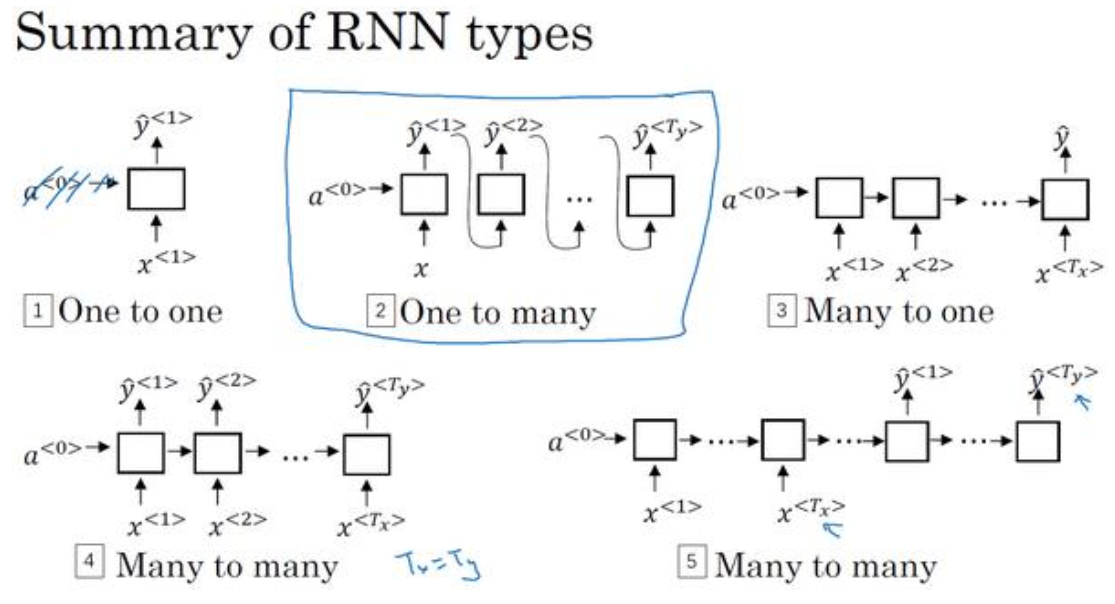
1.5不同类型的循环神经网络
(1)如下图中,第一种是传统标准的网络层,第二是一对多(音乐生成),第三是多对一(情感分析),第四是多对多(输出与输入个数相等,语音识别),第五是多对多(输出与输入个数不一定相等,机器翻译)。
1.6语言模型和序列生成
(1)语言模型以下面两个句子为例,语言模型要解决的就是那个句子出现的概率更大,则输出哪个。
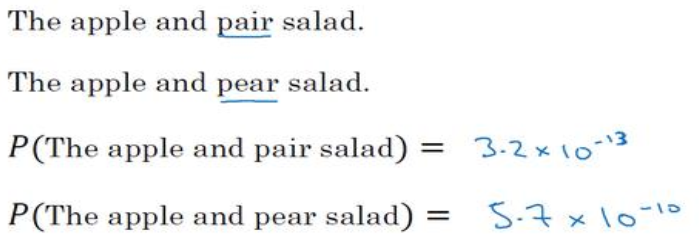
(2)句子的结束句号可以用one-hot表示,关于不在字典中的10000个词的其他词,可以统一用UNK表示,UNK是用one-hot表示的额,所以可以看成总共有10002个字典。
(3)语言模型如下图所示,首先第一个输出是在无任何提示下输出各个词的概率,第二个输出是在给定第一个输出标签时各个词(10002)输出的概率,以此类推,每一个输出都是在给定条件下一个输出各个单词的概率。
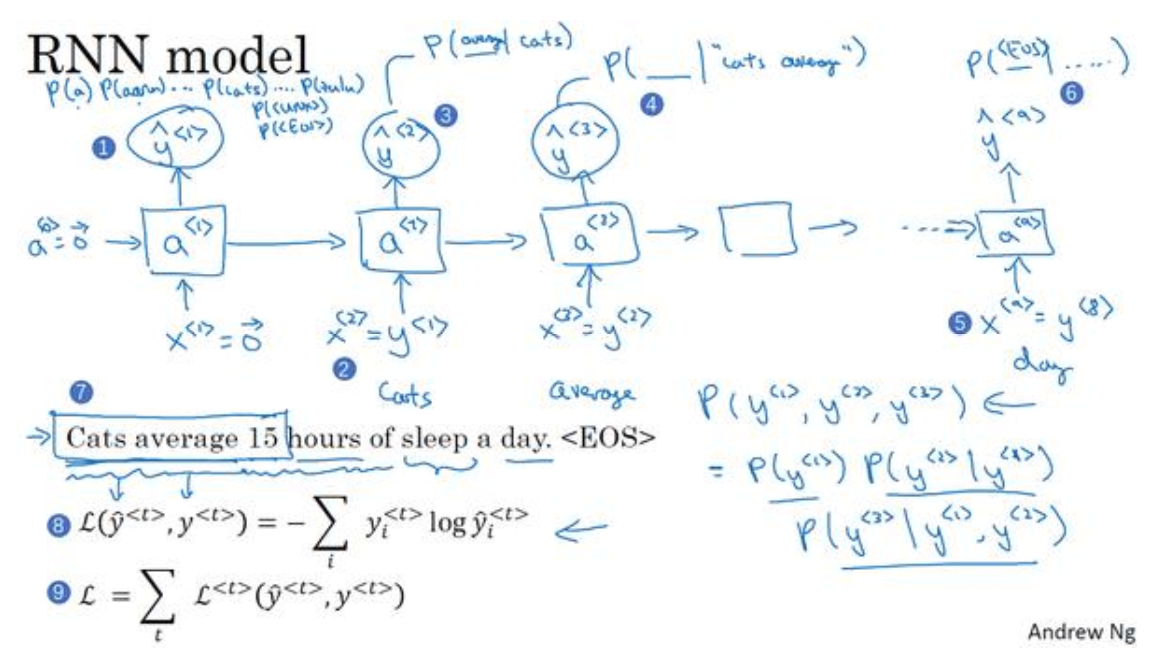
(4)训练网络时,上图中序号8和9分别代表了一个元素和一个样本的代价函数,代价函数使用的是交叉熵。
(5)在使用网络时,现在有一个包含三个词(y<1>,y<2>,y<3>)的句子,这时网络没有任何信息的条件下求是y<1>的概率,然后计算在给定y<1>条件下y<2>的概率,最后在给定y<1>,y<2>条件下y<3>的概率。最后可以确定,输出是这个句子的概率如下图所示,回到最初的两个句子,可以分别求两个句子的概率,取概率最大的句子即可:
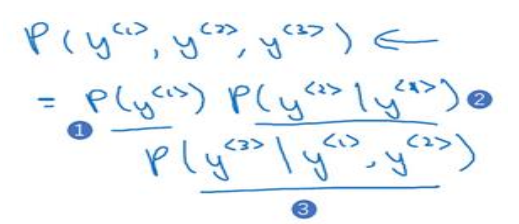
1.7对新序列采样
(1)在应用上面训练好的网络时,只需要用numpy取出来第一个输出中单词概率最大的单词,这样就实现了对序列的采样,然后将获得的词作为已知条件,取获取下一个单词。如下图所示:
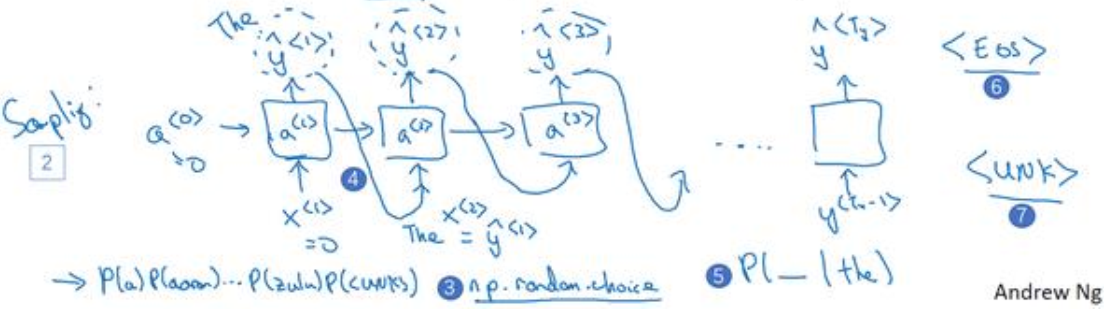
(2)可以用当获得结束符时结束网络采样,也可以当采样数到达预定的个数(如50个词)时结束(这时如果碰到结束符,那么重复则在剩下的词重采样,意思就是取概率次大的单词作为输出)。
(3)可以是如上基于词汇的语言模型,也可以有基于字符的语言模型,由于后者计算量大,前后关系捕捉范围有限,所以前者使用更为广泛。
(4)不同语料生成的语言模型是不一样的,比如以新闻为语料的语言模型,最终模型采样出来的可能看上去偏向于新闻的口吻,而比如以莎士比亚的作品为语料的语言模型,最终模型采样结果看上去更像莎士比亚写的风格。如下图所示:

1.8循环神经网络的梯度消失
(1)训练很深的神经网络时,随着层数的增加,导数有可能指数型的下降或者指数型的增加,我们可能会遇到梯度消失或者梯度爆炸的问题。RNN中如果输入长度为1000的序列(其实求梯度时就相当于1000层),所以同样存在梯度消失和梯度爆炸的问题 。
(2)梯度爆炸时,可以通过梯度修剪来解决,即设定阈值,当梯度超过这个阈值时,缩放梯度向量,保证他不会太大。梯度爆炸比较容易解决。
(3)RNN最主要是存在梯度消失问题,这意味着某一个输出只依赖于很近范围内的值,很远的值无法影响到它,所以像下面的句子因为cats,cat离得很远所以是使用were还是was无法判断:


1.9GRU单元
(1)GRU即门控循环单元,可以解决循环神经网络的梯度消失问题,进而可以解决上面的远距离也能影响后面的输出。
(2)简化版的GRU如下图所示:

下面式子激活函数时tanh
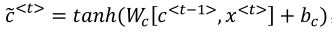
下面式子激活函数时sigmoid
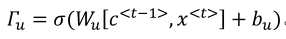
下面的乘法是元素对应相乘
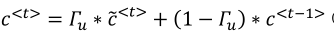
输出的话也是可以加上一个适当的激活函数来输出,如softmax。
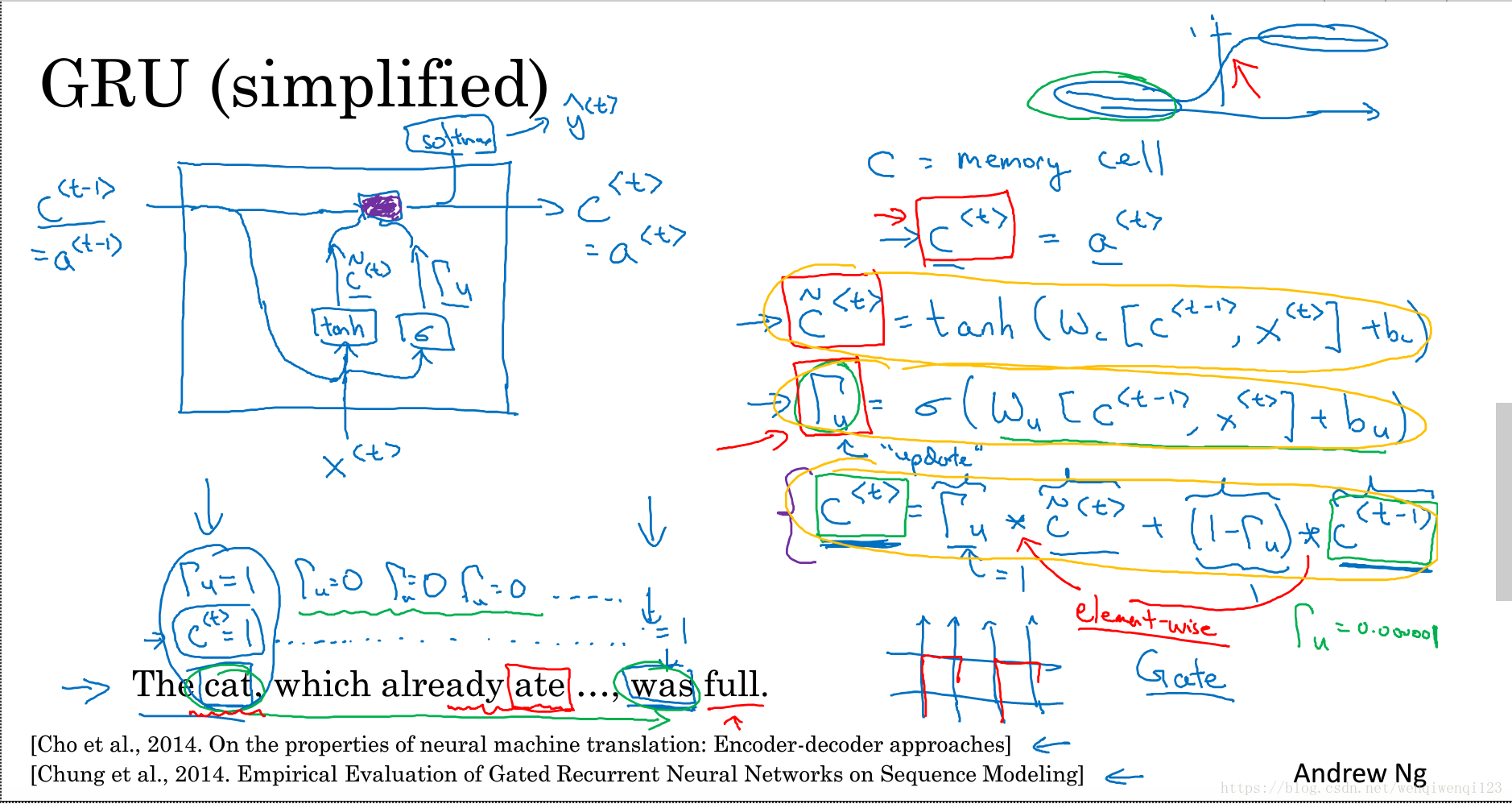
(3)当门控值为0,是即保持之前的值,当为1时,即完全更新为候选值,当然还可以 是0到1之间。
(4)需要理解的是,c其实是一个多维度的向量,所以可以看成是某个一特征是用来记住主语的单复数的,当没有被使用时一直保持,被使用之后或者新的主语出现然后被更新。其他特征用来记住其他的信息。
(5)完整的GRU增加了一个相关门,用来告诉你下一个c<t>与候选值和上一个c<t-1>有多大的相关性
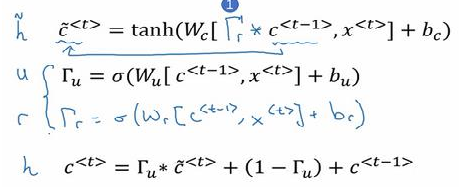
1.10长短期记忆
(1)GRU的再次总结:

(2)LSTM包括遗忘门、更新门和输出门,具体数学公式如下图所示: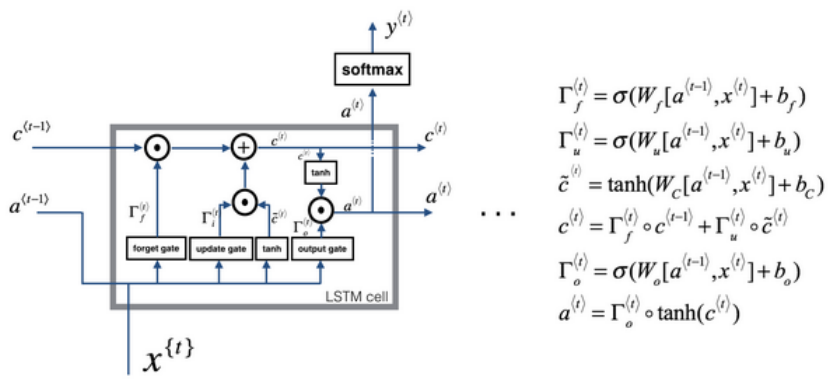
1.11双向循环神经网络
(1)命名实体识别案例:判断下面句子中Teddy是否是人名,如果只从前面两个词是无法得知Teddy是否是人名,如果能有后面的信息就很好判断了,这就需要用的双向循环神经网络。至于网络单元到底是标准的RNN还是GRU或者是LSTM是没有关系的,都可以使用。

(2)双向循环神经网络如下图所示,每一个输出都是综合考虑两个方向获得的结果再输出:
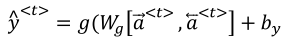
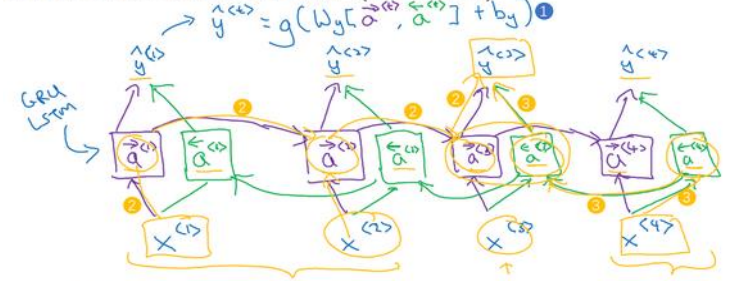
(3)LSTM有一个缺点就是在使用时需要完整的数据序列,你才能预测任意位置。比如用来构建语音识别系统,需要人把话说完,才能进行处理。
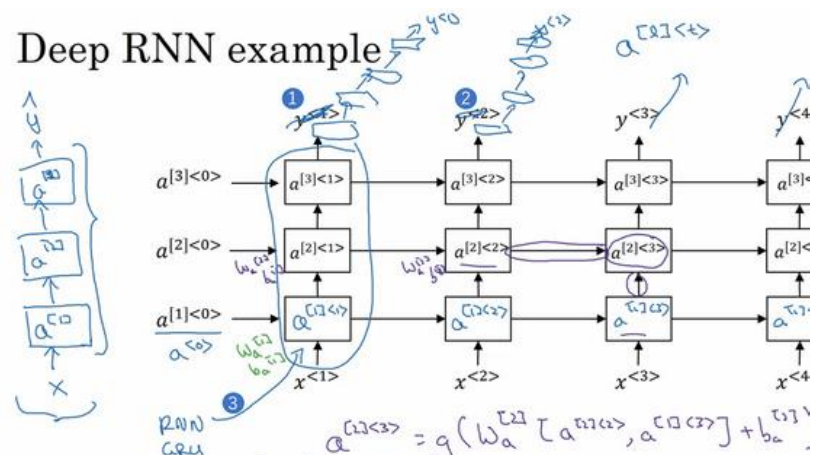
1.12深层循环神经网络
(1)深层循环神经网络如下图所示:
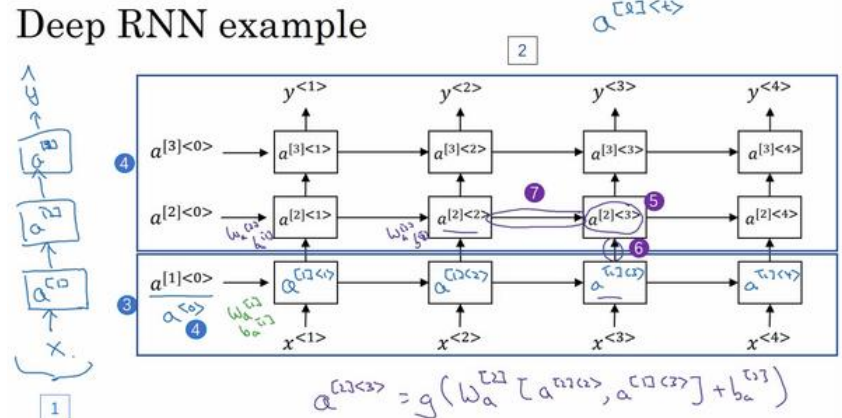
(2)表示方法a[2]<3>方括号表示网络的第几层,尖括号里面的表示第几个时间序列。
(3)在构建网络时,一般循环神经网络的层比较少,有三层已经算不少了,因为如果一层中有50个序列,其实也就相当于有50层那么深了。
(4)下面是一种比较常见的连接方式,就是讲循环层的输出接上普通的深层网络: