手把手使用numpy搭建卷积神经网络
主要内容来自DeepLearning.AI的卷积神经网络
本文使用numpy实现卷积层和池化层,包括前向传播和反向传播过程。
在具体描述之前,先对使用符号做定义。
- 上标[I]表示神经网络的第Ith层。
- (a^{[4]})表示第4层神经网络的激活值;(W^{[5]})和(b^{[5]})表示神经网络第5层的参数;
- 上标(i)表示第i个数据样本
- (x^{(i)})表示第i个输入样本
- 下标i表示向量的第i个元素
- (a_i^{[l]})表示神经网络第l层的激活向量的第i个元素。
- (n_H,n_W,n_C)表示当前层神经网络的高度、宽度和通道数。
- (n_{H_{prev}},n_{W_{prev}},n_{C_{prev}})表示上一层神经网络的高度、宽度和通道数。
1. 导入包
首先,导入需要使用的工具包。
import numpy as np
import h5py
import matplotlib.pyplot as plt
%matplotlib inline
plt.rcParams['figure.figsize'] = (5.0, 4.0) # set default size of plots
plt.rcParams['image.interpolation'] = 'nearest'
plt.rcParams['image.cmap'] = 'gray'
%load_ext autoreload
%autoreload 2
np.random.seed(1) # 指定随机数种子
2. 大纲
本文要实现的卷积神经网络的几个网络块,每个网络包含的功能模块如下。
-
卷积函数Convolution
- 0填充边界
- 卷积窗口
- 卷积运算前向传播
- 卷积运算反向传播
-
池化函数Pooling
- 池化函数前向传播
- 掩码创建
- 值分配
- 池化的反向传播

在每个前向传播的函数中,在参数更新时会有一个反向传播过程;此外,在前向传播过程会缓存一个参数,用于在反向传播过程中计算梯度。
3. 卷积神经网络
尽管当下存在很多深度学习框架使得卷积网络使用更为便捷,但是卷积网络在深度学习中仍然是一个难以理解的运算。卷积层能将输入转换为具有不同维度的输出,如下图所示。
接下来,我们自己实现卷积运算。首先,实现两个辅助函数:0填充边界和计算卷积。
3.1 0值边界填充
0值边界填充顾名思义,使用0填充在图片的边界周围。
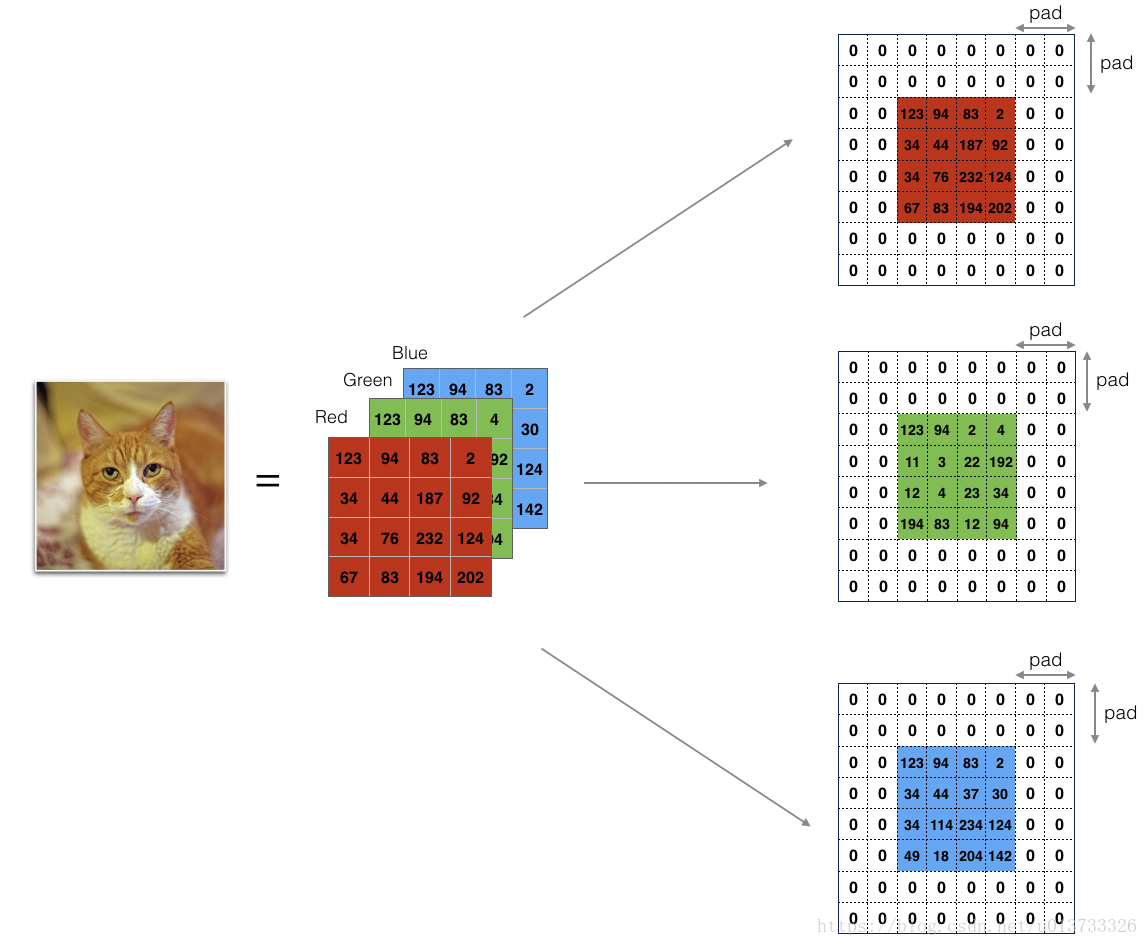
使用边界填充的优点:
- 可以保证使用上一层的输出结果经过卷积运算后,其高度和宽度不会发生变化。这个特性对于构建深层网络非常重要,否则随着网络深度的增加,计算结果会逐步缩水,直至降为1。一种特殊的的“Same”卷积,可以保证计算结果的宽度和高度不发生变化
- 可以在图像边界保留更多的信息。不适用填充的情况下,图像的边缘像素对下一层结果的影响小(图像的中间像素使用滑动窗口时会遍历多次,而边界元素则比较少,有可能只使用1次)。
# GRADED FUNCTION: zero_pad
def zero_pad(X, pad):
"""
把数据集X的图像边界用0值填充。填充情况发生在每张图像的宽度和高度上。
参数:
X -- 图像数据集 (m, n_H, n_W, n_C),分别表示样本数、图像高度、图像宽度、通道数
pad -- 整数,每个图像在垂直和水平方向上的填充量
返回:
X_pad -- 填充后的图像数据集 (m, n_H + 2*pad, n_W + 2*pad, n_C)
"""
# X数据集有4个维度,填充发生在第2个维度和第三个维度上;填充方式为0值填充
X_pad = np.pad(X, (
(0, 0),# 样本数维度,不填充
(pad, pad), #n_H维度,上下各填充pad个像素
(pad, pad), #n_W维度,上下各填充pad个像素
(0, 0)), #n_C维度,不填充
mode='constant', constant_values = (0, 0))
return X_pad
我们来测试一下:
np.random.seed(1)
x = np.random.randn(4, 3, 3, 2)
x_pad = zero_pad(x, 2)
print ("x.shape =
", x.shape)
print ("x_pad.shape =
", x_pad.shape)
print ("x[1,1] =
", x[1,1])
print ("x_pad[1,1] =
", x_pad[1,1])
fig, axarr = plt.subplots(1, 2)
axarr[0].set_title('x')
axarr[0].imshow(x[0,:,:,0])
axarr[1].set_title('x_pad')
axarr[1].imshow(x_pad[0,:,:,0])
测试结果:
x.shape = (4, 3, 3, 2)
x_pad.shape = (4, 7, 7, 2)
x[1,1] = [[ 0.90085595 -0.68372786]
[-0.12289023 -0.93576943]
[-0.26788808 0.53035547]]
x_pad[1,1] = [[ 0. 0.]
[ 0. 0.]
[ 0. 0.]
[ 0. 0.]
[ 0. 0.]
[ 0. 0.]
[ 0. 0.]]
3.2 单步卷积(单个滑动窗口计算过程)
实现一个单步卷积的计算过程,将卷积核和输入的一个窗口片进行计算,之后使用这个函数实现真正的卷积运算。卷积运算包括:
- 接受一个输入
- 将卷积核和输入的每个窗口分片进行单步卷积计算
- 输出计算结果(维度通常与输入维度不同)
我们看一个卷积运算过程:
在计算机视觉应用中,左侧矩阵的每个值代表一个像素,我们使用一个3x3的卷积核和输入图像对应窗口片进行element-wise相乘然后求和,最后加上bias完成一个卷积的单步运算。
# GRADED FUNCTION: conv_single_step
def conv_single_step(a_slice_prev, W, b):
"""
使用卷积核与上一层的输出结果的一个分片进行卷积运算
参数:
a_slice_prev -- 输入分片, (f, f, n_C_prev)
W -- 权重参数,包含在一个矩阵中 (f, f, n_C_prev)
b -- 偏置参数,包含在一个矩阵中 (1, 1, 1)
返回:
Z -- 一个实数,表示在输入数据X的分片a_slice_prev和滑动窗口(W,b)的卷积计算结果
"""
# 逐元素相乘,结果维度为(f,f,n_C_prev)
s = np.multiply(a_slice_prev, W)
# 求和
Z = np.sum(s)
# 加上偏置参数b,使用float将(1,1,1)变为一个实数
Z = Z + float(b)
return Z
我们测试一下代码:
np.random.seed(1)
a_slice_prev = np.random.randn(4, 4, 3)
W = np.random.randn(4, 4, 3)
b = np.random.randn(1, 1, 1)
Z = conv_single_step(a_slice_prev, W, b)
print("Z =", Z)
输出结果为:
Z = -6.99908945068
3.3 卷积层的前向传播
在卷积层的前向传播过程中会使用多个卷积核,每个卷积核与输入图片计算得到一个2D矩阵,然后将多个卷积核的计算结果堆叠起来形成最终输出。
我们需要实现一个卷积函数,这个函数接收上一层的输出结果A_prev,然后使用大小为fxf卷积核进行卷积运算。这里的输入A_prev为若干张图片,同时卷积核的数量也可能有多个。
为了方便理解卷积的计算过程,我们这里使用for循环进行描述。
提示:
-
如果需要在(5,5,3)的矩阵的左上角截取一个2x2的分片,可以使用:
a_slice_prev = a_prev[0:2,0:2,:];值得注意的是分片结果具有3个维度(2,2,n_C_prev) -
如果想自定义分片,需要明确分片的位置,可以使用vert_start, vert_end, horiz_start 和horiz_end四个值来确定。如图
-
卷积层计算结果的维度计算,可以使用公式确定:
卷积层代码如下:
# GRADED FUNCTION: conv_forward
def conv_forward(A_prev, W, b, hparameters):
"""
卷积层的前向传播
参数:
A_prev --- 上一层网络的输出结果,(m, n_H_prev, n_W_prev, n_C_prev),
W -- 权重参数,指这一层的卷积核参数 (f, f, n_C_prev, n_C),n_C个大小为(f,f,n_C_prev)的卷积核
b -- 偏置参数 (1, 1, 1, n_C)
hparameters -- 超参数字典,包含 "stride" and "pad"
返回:
Z -- 卷积计算结果,维度为 (m, n_H, n_W, n_C)
cache -- 缓存卷积层反向传播计算需要的数据
"""
# 输出参数的维度,包含m个样from W's shape (≈1 line)
(m, n_H_prev, n_W_prev, n_C_prev) = A_prev.shape
# 权重参数
(f, f, n_C_prev, n_C) = W.shape
# 获取本层的超参数:步长和填充宽度
stride = hparameters['stride']
pad = hparameters['pad']
# 计算输出结果的维度
# 使用int函数代替np.floor向下取整
n_H = int((n_H_prev + 2 * pad - f)/stride) + 1
n_W = int((n_W_prev + 2 * pad - f)/stride) + 1
# 声明输出结果
Z = np.zeros((m, n_H, n_W, n_C))
# 1. 对输出数据A_prev进行0值边界填充
A_prev_pad = zero_pad(A_prev, pad)
for i in range(m): # 依次遍历每个样本
a_prev_pad = A_prev_pad[i] # 获取当前样本
for h in range(n_H): # 在输出结果的垂直方向上循环
for w in range(n_W):#在输出结果的水平方向上循环
# 确定分片边界
vert_start = h * stride
vert_end = vert_start + f
horiz_start = w * stride
horiz_end = horiz_start + f
for c in range(n_C): # 遍历输出的通道
# 在输入数据上获取当前切片,结果是3D
a_slice_prev = a_prev_pad[vert_start:vert_end,horiz_start:horiz_end,:]
# 获取当前的卷积核参数
weights = W[:,:,:, c]
biases = b[:,:,:, c]
# 输出结果当前位置的计算值,使用单步卷积函数
Z[i, h, w, c] = conv_single_step(a_slice_prev, weights, biases)
assert(Z.shape == (m, n_H, n_W, n_C))
# 将本层数据缓存,方便反向传播时使用
cache = (A_prev, W, b, hparameters)
return Z, cache
我们来测试一下:
np.random.seed(1)
A_prev = np.random.randn(10,5,7,4)
W = np.random.randn(3,3,4,8)
b = np.random.randn(1,1,1,8)
hparameters = {"pad" : 1, "stride": 2}
Z, cache_conv = conv_forward(A_prev, W, b, hparameters)
print("Z's mean =
", np.mean(Z))
print("Z[3,2,1] =
", Z[3,2,1])
print("cache_conv[0][1][2][3] =
", cache_conv[0][1][2][3])
输出值为:
Z's mean = 0.692360880758
Z[3,2,1] = [ -1.28912231 2.27650251 6.61941931 0.95527176 8.25132576
2.31329639 13.00689405 2.34576051]
cache_conv[0][1][2][3] = [-1.1191154 1.9560789 -0.3264995 -1.34267579]
最后,卷积层应该包含一个激活函数,我们可以添加以下代码完成:
# 获取输出个某个单元值
Z[i, h, w, c] = ...
# 使用激活函数
A[i, h, w, c] = activation(Z[i, h, w, c])
4. 池化层
池化层可以用于缩小输入数据的高度和宽度。池化层有利于简化计算,同时也有助于对输入数据的位置更加稳定。池化层有两种类型:
- 最大池化:在输入数据上用一个(f, f)的窗口进行滑动,在输出中保存窗口的最大值
- 平均池化:在输入数据上用一个(f, f)的窗口进行滑动,在输出中保存窗口的平均值
池化层没有参数需要训练,但是它们有像窗口大小f的超参数,它指定了窗口的大小为f x f,这个窗口用于计算最大值和平均值。
4.1 前向传播
我们这里在同一个函数中实现最大池化和平均池化。
提示:
池化层没有填充项,输出结果的维度和输入数据的维度相关,计算公式为:
实现代码如下:
def pool_forward(A_prev, hparameters, mode = "max"):
"""
池化层的前向传播
参数:
A_prev -- 输入数据,维度为 (m, n_H_prev, n_W_prev, n_C_prev)
hparameters -- 超参数字典,包含 "f" and "stride"
mode -- string;表示池化方式, ("max" or "average")
返回:
A -- 输出结果,维度为 (m, n_H, n_W, n_C)
cache -- 缓存数据,用于池化层的反向传播, 缓存输入数据和池化层的超参数(f、stride)
"""
(m, n_H_prev, n_W_prev, n_C_prev) = A_prev.shape
f = hparameters["f"]
stride = hparameters["stride"]
# 计算输出数据的维度
n_H = int(1 + (n_H_prev - f) / stride)
n_W = int(1 + (n_W_prev - f) / stride)
n_C = n_C_prev
# 定义输出结果
A = np.zeros((m, n_H, n_W, n_C))
# 逐个计算,对A的元素进行赋值
for i in range(m): # 遍历样本
for h in range(n_H):# 遍历n_H维度
# 确定分片垂直方向上的位置
vert_start = h * stride
vert_end =vert_start + f
for w in range(n_W):# 遍历n_W维度
# 确定分片水平方向上的位置
horiz_start = w * stride
horiz_end = horiz_start + f
for c in range (n_C):# 遍历通道
# 确定当前样本上的分片
a_prev_slice = A_prev[i, vert_start:vert_end, horiz_start:horiz_end, c]
# 根据池化方式,计算当前分片上的池化结果
if mode == "max":# 最大池化
A[i, h, w, c] = np.max(a_prev_slice)
elif mode == "average":# 平均池化
A[i, h, w, c] = np.mean(a_prev_slice)
# 将池化层的输入和超参数缓存
cache = (A_prev, hparameters)
# 确保输出结果维度正确
assert(A.shape == (m, n_H, n_W, n_C))
return A, cache
5. 反向传播
在深度学习框架中,你只需要实现前向传播,框架可以自动实现反向传播过程,因此大多数深度学习工程师不需要关注反向传播过程。卷积层的反向传播过程比较复杂。
在之前的我们实现全连接神经网络,我们使用反向传播计算损失函数的偏导数进而对参数进行更新。类似的,在卷积神经网络中我们也可以计算损失函数对参数的梯度进而进行参数更新。
5.1 卷积层的反向传播
我们这里实现卷积层的反向传播过程。
5.1.1 计算dA
下面是计算dA的公式:
其中(W_c)表示一个卷积核,(dZ_{hw})是损失函数对卷积层的输出Z的第h行第w列的梯度。值得注意的是,每次更新dA时都会用相同的(W_c)乘以不同的(dZ). 因为卷积层在前向传播过程中,同一个卷积核会和输入数据的每一个分片逐元素相乘然后求和。所以在反向传播计算dA时,需要把所有a_slice的梯度都加进来。我们可以在循环中添加代码:
da_prev_pad[vert_start:vert_end, horiz_start:horiz_end, :] += W[:,:,:,c] * dZ[i, h, w, c]
5.1.2 计算dW
计算(dW_c)的公式(Wc是一个卷积核):
其中,(a_{slice})表示(Z_{hw})对应的输入分片。因为我们使用卷积核作为一个窗口对输入数据进行切片计算卷积,滑动了多少次就对应多少个分片,也就需要累加多少梯度数据。在代码中我们只需要添加一行代码:
dW[:,:,:,c] += a_slice * dZ[i, h, w, c]
5.1.3 计算db
损失函数对当前卷积层的参数b的梯度db的计算公式:
和之前的神经网络类似,db是由dZ累加计算而成。只需要将conv的输出Z的所有梯度累加即可。在循环中添加一行代码:
db[:,:,:,c] += dZ[i, h, w, c]
5.1.4 函数实现
def conv_backward(dZ, cache):
"""
实现卷积层的反向传播过程
参数:
dZ -- 损失函数对卷积层输出Z的梯度, 维度和Z相同(m, n_H, n_W, n_C)
cache -- 卷积层前向传播过程中缓存的数据
返回:
dA_prev -- 损失函数对卷积层输入A_prev的梯度,其维度和A_prev相同(m, n_H_prev, n_W_prev, n_C_prev)
dW -- 损失函数对卷积层权重参数的梯度,其维度和W相同(f, f, n_C_prev, n_C)
db -- 损失函数对卷积层偏置参数b的梯度,其维度和b相同(1, 1, 1, n_C)
"""
# 得到前向传播中的缓存数据,方便后续使用
(A_prev, W, b, hparameters) = cache
# 输入数据的维度
(m, n_H_prev, n_W_prev, n_C_prev) = A_prev.shape
# Retrieve dimensions from W's shape
(f, f, n_C_prev, n_C) = W.shape
# Retrieve information from "hparameters"
stride = hparameters['stride']
pad = hparameters['pad']
(m, n_H, n_W, n_C) = dZ.shape
# 对输出结果进行初始化
dA_prev = np.zeros_like(A_prev)
dW = np.zeros_like(W)
db = np.zeros_like(b)
# 对卷积层输入A_prev进行边界填充;卷积运算时使用的是A_prev_pad
A_prev_pad = zero_pad(A_prev, pad)
dA_prev_pad = zero_pad(dA_prev, pad)
# 我们先计算dA_prev_pad,然后切片得到dA_prev
for i in range(m): # 遍历样本
# 选择一个样本
a_prev_pad = A_prev_pad[i]
da_prev_pad = dA_prev_pad[i]
for h in range(n_H):# 在输出的垂直方向量循环
for w in range(n_W):# 在输出的水平方向上循环
for c in range(n_C):# 在输出的通道上循环
# 确定输入数据的切片边界
vert_start = h * strider
vert_end = vert_start + f
horiz_start = w * stride
horiz_end = horiz_start + f
a_slice = a_prev_pad[vert_start:vert_end, horiz_start:horiz_end, :]
# 计算各梯度
da_prev_pad[vert_start:vert_end, horiz_start:horiz_end, :] += W[:,:,:,c] * dZ[i, h, w, c]
dW[:,:,:,c] += a_slice * dZ[i,h,w,c]
db[:,:,:,c] += dZ[i,h,w,c]
# 在填充后计算结果中切片得到填充之前的dA_prev梯度;
dA_prev[i, :, :, :] = da_prev_pad[pad:-pad, pad:-pad, :]
assert(dA_prev.shape == (m, n_H_prev, n_W_prev, n_C_prev))
return dA_prev, dW, db
我们来测试一下:
np.random.seed(1)
A_prev = np.random.randn(10,4,4,3)
W = np.random.randn(2,2,3,8)
b = np.random.randn(1,1,1,8)
hparameters = {"pad" : 2,
"stride": 2}
Z, cache_conv = conv_forward(A_prev, W, b, hparameters)
# Test conv_backward
dA, dW, db = conv_backward(Z, cache_conv)
print("dA_mean =", np.mean(dA))
print("dW_mean =", np.mean(dW))
print("db_mean =", np.mean(db))
输出结果:
dA_mean = 1.45243777754
dW_mean = 1.72699145831
db_mean = 7.83923256462
5.2 池化层的反向传播
接下来,我们选择从最大池化开始实现池化层的反向传播过程。尽管池化层没有参数需要训练,但是我们仍然需要计算梯度,因为我们需要将梯度通过池化层传递下去,计算下一层参数的梯度。
5.2.1 最大池化的反向传播
在实现池化层的反向传播之前,我们需要实现一个辅助函数create_mask_from_window(),用于实现:
这个函数依据输入的X创建了一个掩码,以保存输入数据的最大值位置。掩码中1表示对应位置为最大值(我们假设只有一个最大值)。
提示:
- np.max()用于计算输入数组的最大值
- 矩阵X和实数x,那么,A = (X == x)将返回一个和X相同的矩阵,其中:
- A[i, j] = True if X[i, j] = x
- A[i, j] = False if X[i, j] != x
- 不考虑矩阵中存在多个最大值的情况
def create_mask_from_window(x):
"""
根据输入X创建一个保存最大值位置的掩码
参数:
x -- 输入数据,维度为 (f, f)
返回值:
mask -- 形状和x相同的保存其最大值位置的掩码矩阵
"""
mask = (x == np.max(x))
return mask
我们来测试一下:
np.random.seed(1)
x = np.random.randn(2,3)
mask = create_mask_from_window(x)
print('x = ', x)
print("mask = ", mask)
输出结果为:
x = [[ 1.62434536 -0.61175641 -0.52817175]
[-1.07296862 0.86540763 -2.3015387 ]]
mask = [[ True False False]
[False False False]]
5.2.2 平均池化的反向传播
在最大池化中,每个输入窗口的对输出的影响仅仅来源于窗口的最大值;在平均池化中,窗口的每个元素对输出结果有相同的影响。所以我们需要设计一个函数实现上述功能。
我们来看一个具体的例子:
def distribute_value(dz, shape):
"""
将梯度值均衡分布在shape的矩阵中
参数:
dz -- 标量,损失函数对某个参数的梯度
shape -- 输出的维度(n_H, n_W)
Returns:
a -- 将dz均衡散布在(n_H, n_W)后的矩阵
"""
(n_H, n_W) = shape
# 每个元素的值
average = dz / (n_H * n_W)
# 输出结果
a = np.ones(shape) * average
return a
我们来测试一下:
a = distribute_value(2, (2,2))
print('distributed value =', a)
输出结果:
distributed value = [[ 0.5 0.5]
[ 0.5 0.5]]
5.2.3 代码实现
将上述的辅助函数集合起来实现池化层的反向传播过程:
def pool_backward(dA, cache, mode = "max"):
"""
实现池化层的反向传播
参数:
dA -- 损失函数对池化层输出数据A的梯度,维度和A相同
cache -- 池化层的缓存数据,包括输入数据和超参数
mode -- 字符串,表明池化类型 ("max" or "average")
返回:
dA_prev -- 对池化层输入数据A_prv的梯度,维度和A_prev相同
"""
(A_prev, hparameters) = cache
stride = hparameters['stride']
f = hparameters['f']
m, n_H_prev, n_W_prev, n_C_prev = A_prev.shape
m, n_H, n_W, n_C = dA.shape
# 对输出结果进行初始化
dA_prev = np.zeros_like(A_prev)
for i in range(m):# 遍历m个样本
a_prev = A_prev[i]
for h in range(n_H):# 在垂直方向量遍历
for w in range(n_W):#在水平方向上循环
for c in range(n_C):# 在通道上循环
# 找到输入的分片的边界
vert_start = h * stride
vert_end = vert_start + f
horiz_start = w * stride
horiz_end = horiz_start + f
# 根据池化方式选择不同的计算过程
if mode == "max":
# 确定输入数据的切片
a_prev_slice = a_prev[vert_start:vert_end, horiz_start:horiz_end, c]
# 创建掩码
mask = create_mask_from_window(a_prev_slice)
# 计算dA_prev
dA_prev[i, vert_start: vert_end, horiz_start: horiz_end, c] += np.multiply(mask, dA[i,h,w,c])
elif mode == "average":
# 获取da值, 一个实数
da = dA[i,h,w,c]
shape = (f, f)
# 反向传播
dA_prev[i, vert_start: vert_end, horiz_start: horiz_end, c] += distribute_value(da, shape)
assert(dA_prev.shape == A_prev.shape)
return dA_prev
测试一下:
np.random.seed(1)
A_prev = np.random.randn(5, 5, 3, 2)
hparameters = {"stride" : 1, "f": 2}
A, cache = pool_forward(A_prev, hparameters)
dA = np.random.randn(5, 4, 2, 2)
dA_prev = pool_backward(dA, cache, mode = "max")
print("mode = max")
print('mean of dA = ', np.mean(dA))
print('dA_prev[1,1] = ', dA_prev[1,1])
print()
dA_prev = pool_backward(dA, cache, mode = "average")
print("mode = average")
print('mean of dA = ', np.mean(dA))
print('dA_prev[1,1] = ', dA_prev[1,1])
输出结果为:
mode = max
mean of dA = 0.145713902729
dA_prev[1,1] = [[ 0. 0. ]
[ 5.05844394 -1.68282702]
[ 0. 0. ]]
mode = average
mean of dA = 0.145713902729
dA_prev[1,1] = [[ 0.08485462 0.2787552 ]
[ 1.26461098 -0.25749373]
[ 1.17975636 -0.53624893]]
至此,我们完成了卷积层和池化层的前向传播和反向传播过程,之后我们可以来构建卷积神经网络。