一.DAGScheduler
SparkContext在初始化时,创建了DAG调度和Task调度来负责RDD Action操作的调度执行。
DAGScheduler负责Spark的最高级别的任务调度,调度的粒度是Stage,它为每个Job的所有Stage计算一个有向无环图,控制它们的并发,并找到一个最佳路径来执行它们。具体的执行过程是将Stage下的Task任务集提交给TaskScheduler对象,由它来提交到集群上去申请资源并最终完成执行。
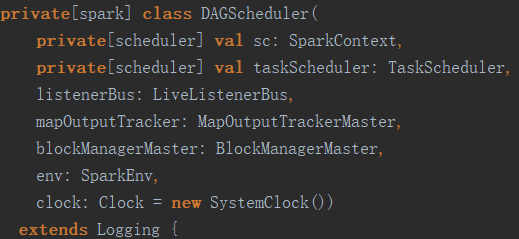
DAGScheduler初始化时除了需要一个SparkContext对象外,最重要的是需要输入一个TaskScheduler对象来负责Task的执行。源码如下:
1.runJob过程
所有需要执行的RDD Action,都会调用SparkContext.runJob来提交任务,而SparkContext.runJob调用的是DAGScheduler.runJob。如下:

runJob调用submitJob提交任务,并等待任务结束。任务提交后的处理过程如下:
1.submitJob生成新的Job ID,发送消息JobSubmitted。
2.DAG收到JobSubmitted消息,调用handleJobSubmitted来处理。
3.handleJobSubmitted创建一个ResultStage,并使用submitStage来提交这个ResultStage。
上面的过程看起来没执行完,实际上大的过程已经结束了,猫腻在submitStage中。Spark的执行过程是懒加载的,这在这里得到了完整的体现。任务提交时,不是按Job的先后顺序提交的,而是倒序的。每个Job的最后一个操作是Action操作,DAG把这个最后的Action操作当作一个Stage,首先提交,然后逆向逐级递归填补缺少的上级Stage,从而生成一颗实现最后Action操作的最短的【都是必须的】有向无环图,然后再从头开始计算。submitStage方法的实现代码如下:
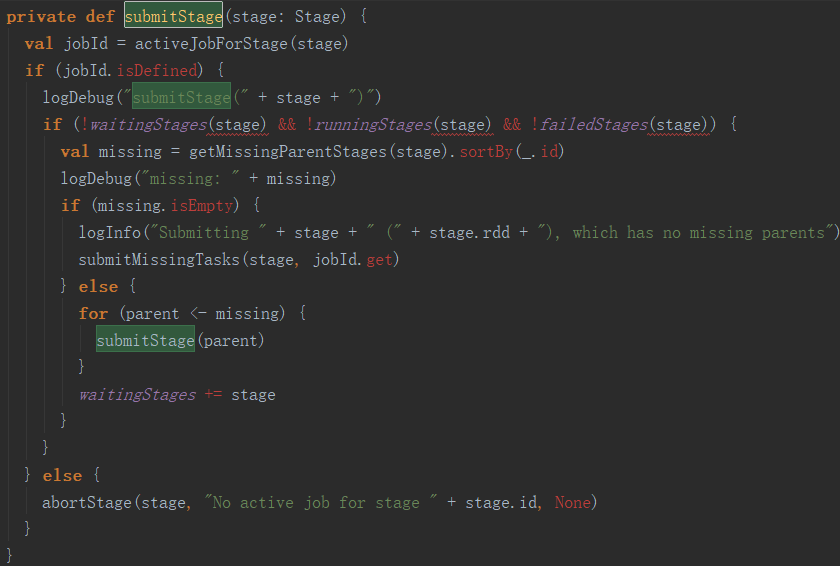
可以看到,这是一个逆向递归的过程,先查找所有缺失的上级Stage并提交,待所有上级Stage都提交执行了,才轮到执行当前Stage对应的Task。查找上级Stage的过程,其实就是递归向上遍历所有RDD依赖列表并生成Stage的过程,代码如下:
private def getMissingParentStages(stage: Stage): List[Stage] = { val missing = new HashSet[Stage] val visited = new HashSet[RDD[_]] // We are manually maintaining a stack here to prevent StackOverflowError // caused by recursively visiting val waitingForVisit = new ArrayStack[RDD[_]] def visit(rdd: RDD[_]) { if (!visited(rdd)) { visited += rdd val rddHasUncachedPartitions = getCacheLocs(rdd).contains(Nil) if (rddHasUncachedPartitions) { for (dep <- rdd.dependencies) { dep match { case shufDep: ShuffleDependency[_, _, _] => val mapStage = getOrCreateShuffleMapStage(shufDep, stage.firstJobId) if (!mapStage.isAvailable) { missing += mapStage } case narrowDep: NarrowDependency[_] => waitingForVisit.push(narrowDep.rdd) } } } } } waitingForVisit.push(stage.rdd) while (waitingForVisit.nonEmpty) { visit(waitingForVisit.pop()) } missing.toList }
遍历的过程是非递归的层序遍历【不是前序、中序或后序遍历】,使用了一个堆栈来协助遍历,而且保证了层序的顺序与DAG中的依赖顺序一致。
2.Stage
值得注意的是,仅对依赖类型是ShuffleDependency的RDD操作创建Stage,其它的RDD操作并没有创建Stage。RDD操作有两类依赖:一类是窄依赖,一个RDD分区只依赖上一个RDD的部分分区,而且这些分区都在相同的节点上;另外一类依赖是Shuffle依赖,一个RDD分区可能会依赖上一级RDD的全部分区,一个典型的例子是groupBy聚合操作。这两类操作在计算上有明显的区别,窄依赖都在同一个节点上进行计算,而Shuffle依赖垮越多个节点,甚至所有涉及的计算节点。因此,DAG在调度时,对于在相同节点上进行的Task计算,会合并为一个Stage。
二.TaskScheduler
相对DAGScheduler而言,TaskScheduler是低级别的调度接口,允许实现不同的Task调度器。目前,已经实现的Task调度器除了自带的以外,还有YARN和Mesos调度器。每个TaskScheduler对象只服务于一个SparkContext的Task调度。TaskScheduler从DAGScheduler的每个Stage接收一组Task,并负责将它们发送到集群上,运行它们,如果出错还会重试,最后返回消息给DAGScheduler。
TaskScheduler的主要接口包括一个钩子接口【也称hook,表示定义好之后,不是用户主动调用的】,被调用的时机是在初始化完成之后和调度启动之前:
def postStartHook(){}
还有启动和停止调度的命令:
def start(): Unit
def stop():Unit
此外,还有提交和撤销Task集的命令:
def submitTasks(taskSet : TaskSet): Unit
def cancelTasks(stageId: Int, interruptThread: Boolean): Unit