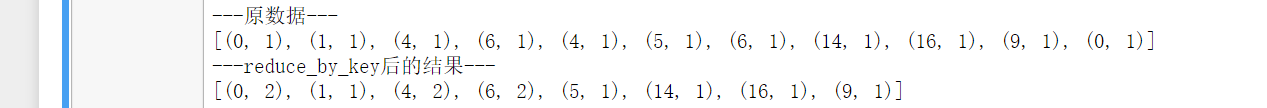# 使用默认的高阶函数map和reduce
import random
def map_function(arg): # 生成测试数据
return (arg,1)
list_map = list(map(map_function,list(ran * random.randint(1,2) for ran in list(range(10)))))
list_map.append((0,1)) # 保持一定有相同的key
print("---原数据---")
print(list_map)
# 实现原理:在第一次调用该函数时根据key是否相同,觉得value是否相加,不管相加与否,都封装成list保存到参数1中
# 之后的调用都先遍历参数1,有匹配则value相加然后覆盖到原list中,不管匹配与否,都重新赋值到参数1中
# 一直到最后返回最终结果
def reduce_by_key(arg1,arg2):
if isinstance(arg1,(tuple)):
if arg1[0] == arg2[0]: # 首次调用且key一样时使用
return [(arg1[0],arg1[1]+arg2[1])]
else: # 首次调用且key不一样时使用
return [arg1,arg2]
else:
bool = 1 # 标记是否匹配
for list_one in arg1:
if list_one[0] == arg2[0]:
arg1[arg1.index(list_one)] = (list_one[0],list_one[1]+arg2[1]) # key相同时value相加
bool = 0
break # 每次最多有一个key相同
if bool: # 不匹配,添加
arg1.append(arg2)
return arg1
from functools import reduce
result = reduce(reduce_by_key,list_map)
print("---reduce_by_key后的结果---")
print(result)
结果: