|
项目名称 |
Crawling is going on |
|
项目版本 |
Alpha版本 |
|
负责人 |
北京航空航天大学计算机学院 远航1617 小组 |
|
联系方式 |
http://www.cnblogs.com/yuanhang1617 |
|
要求发布日期 |
2013-11-13 |
1 更新内容
1.1 修复缺陷
a) 运行时无法链接远程数据库的问题已修复。
b) 源网址写死的问题已修复。
1.2 新增功能
a) 允许自选源网址的爬取方式,源网址由用户输入。
b) 界面进行了排版和优化。
c) 界面新增所有爬取网页的显示功能。
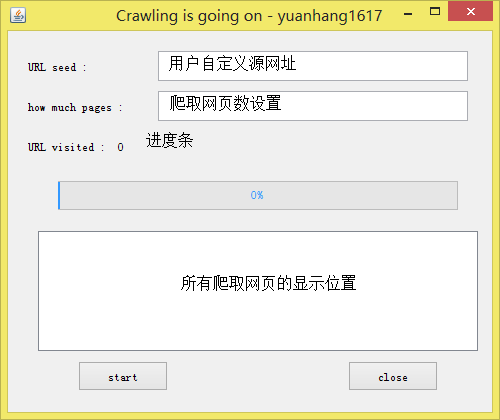
d) 对广告过滤有了更严格的限制。
2 环境要求
|
操作系统需求 |
WINDOWS XP,WINDOWS 7,WINDOWS 8 |
|
运行环境需求 |
需安装eclipse开发环境和最新版本的JRE |
|
数据库需求 |
在联网的环境下可以直接连接服务器的数据库,本地数据库没有特殊要求 |
|
旧版本处理方式 |
备份处理 |
3 安装说明
3.1 更新方法
将软件压缩包中的全部文件解压到本地,覆盖所有原文件。
3.2 回退预案
使用备份文件替换。
4 已知缺陷和限制
以下缺陷和限制将在Beta版中加以完善和补充。
a) 目前爬取只针对html类型文件;其他类型的文件暂时无法爬取。
b) 目前界面比较简单,有待进一步优化。
c) 对于广告只能简单过滤,更高级的广告过滤算法有待开发。
d) url中有汉字的网站不能进行爬取。
e) 对广告过滤过于严格,有时候可能会过滤掉不是广告的网页。
f) 在一次爬取的过程中,当有错误之后,爬取过程将中断。
5 发布地址
该版本代码发布在服务器219.224.191.24上,可自行下载试用。