什么是ceph:
Ceph是一种为优秀的性能、可靠性和可扩展性而设计的统一的、分布式的存储系统。Ceph 独一无二地用统一的系统提供了对象、块、和文件存储功能,它可靠性高、管理简便、并且是开源软件。 Ceph 的强大足以改变贵公司的 IT 基础架构、和管理海量数据的能力。Ceph 可提供极大的伸缩性——供成千用户访问 PB 乃至 EB 级的数据。 Ceph 节点以普通硬件和智能守护进程作为支撑点, Ceph 存储集群组织起了大量节点,它们之间靠相互通讯来复制数据、并动态地重分布数据。
ceph的核心组件:
Ceph的核心组件包括Ceph OSD、Ceph Monitor和Ceph MDS三大组件。
Ceph OSD:OSD的英文全称是Object Storage Device,它的主要功能是存储数据、复制数据、平衡数据、恢复数据等,与其它OSD间进行心跳检查等,并将一些变化情况上报给Ceph Monitor。一般情况下一块硬盘对应一个OSD,由OSD来对硬盘存储进行管理,当然一个分区也可以成为一个OSD。
Ceph Monitor:由该英文名字我们可以知道它是一个监视器,负责监视Ceph集群,维护Ceph集群的健康状态,同时维护着Ceph集群中的各种Map图,比如OSD Map、Monitor Map、PG Map和CRUSH Map,这些Map统称为Cluster Map,Cluster Map是RADOS的关键数据结构,管理集群中的所有成员、关系、属性等信息以及数据的分发,比如当用户需要存储数据到Ceph集群时,OSD需要先通过Monitor获取最新的Map图,然后根据Map图和object id等计算出数据最终存储的位置。
Ceph MDS:全称是Ceph MetaData Server,主要保存的文件系统服务的元数据,但对象存储和块存储设备是不需要使用该服务的。
查看各种Map的信息可以通过如下命令:ceph osd(mon、pg) dump
ceph架构:

Ceph系统逻辑层次结构:
自下向上,可以将Ceph系统分为四个层次:
- (1)基础存储系统RADOS(Reliable, Autonomic, Distributed Object Store,即可靠的、自动化的、分布式的对象存储)
顾名思义,这一层本身就是一个完整的对象存储系统,所有存储在Ceph系统中的用户数据事实上最终都是由这一层来存储的。而Ceph的高可靠、高可扩展、高性能、高自动化等等特性本质上也是由这一层所提供的。因此,理解RADOS是理解Ceph的基础与关键。
- (2)基础库librados
这一层的功能是对RADOS进行抽象和封装,并向上层提供API,以便直接基于RADOS(而不是整个Ceph)进行应用开发。特别要注意的是,RADOS是一个对象存储系统,因此,librados实现的API也只是针对对象存储功能的。
RADOS采用C++开发,所提供的原生librados API包括C和C++两种。物理上,librados和基于其上开发的应用位于同一台机器,因而也被称为本地API。应用调用本机上的librados API,再由后者通过socket与RADOS集群中的节点通信并完成各种操作。
- (3)高层应用接口
这一层包括了三个部分:RADOS GW(RADOS Gateway)、 RBD(Reliable Block Device)和Ceph FS(Ceph File System),其作用是在librados库的基础上提供抽象层次更高、更便于应用或客户端使用的上层接口。
RADOS GW是一个提供与Amazon S3和Swift兼容的RESTful API的gateway,以供相应的对象存储应用开发使用。RADOS GW提供的API抽象层次更高,但功能则不如librados强大。因此,开发者应针对自己的需求选择使用。
RBD则提供了一个标准的块设备接口,常用于在虚拟化的场景下为虚拟机创建volume。目前,Red Hat已经将RBD驱动集成在KVM/QEMU中,以提高虚拟机访问性能。
Ceph FS是通过Linux内核客户端和FUSE来提供一个兼容POSIX的文件系统。
RADOS的存储逻辑架构
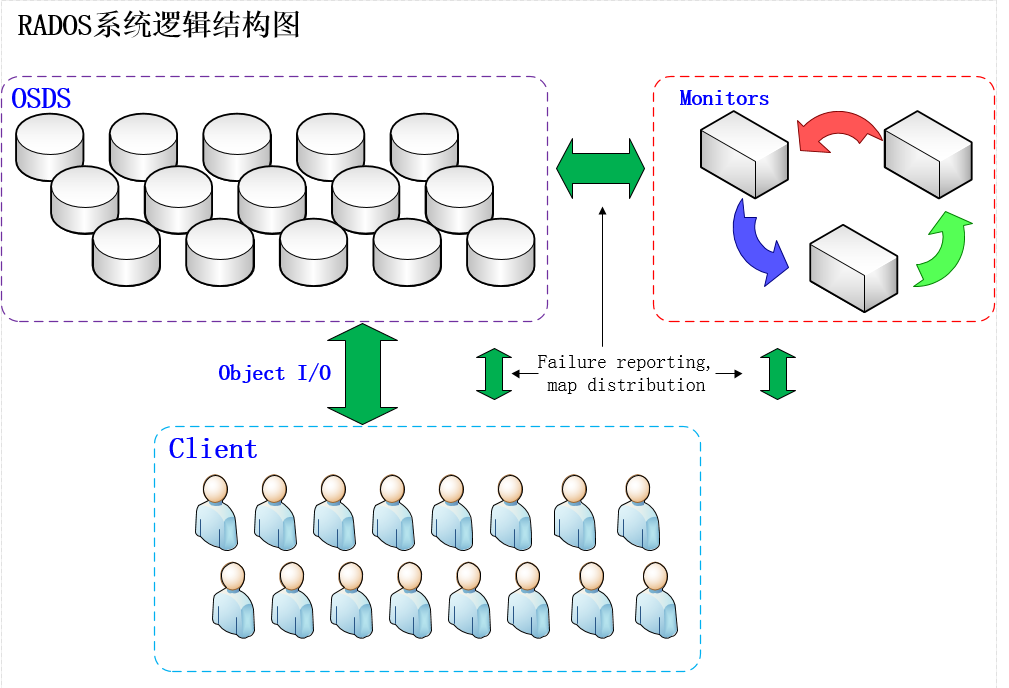
RADOS如图所示,RADOS集群主要由2种节点组成。一种是负责数据存储和维护功能的OSD,另一种则是若干个负责完成系统状态监测和维护的monitor。OSD和monitor之间相互传输节点的状态信息,共同得出系统的总体工作运行状态,并形成一个全局系统状态记录数据结构,即所谓的cluster map。这个数据结构和RADOS提供的特定算法相结合,便实现了Ceph“无需查表,算算就好”的核心机制和若干优秀特性。
在使用RADOS系统时,大量的客户端程序通过与OSD或者monitor的交互获取cluster map,然后直接在本地进行计算,得出对象的存储位置后,便直接与对应的OSD通信,完成数据的各种操作。可见,在此过程中,只要保证cluster map不频繁更新,则客户端显然可以不依赖于任何元数据服务器,不进行任何查表操作,便完成数据访问流程。在RADOS的运行过程中,cluster map的更新完全取决于系统的状态变化,而导致这一变化的常见事件只有两种:OSD出现故障,或者RADOS规模扩大。而正常应用场景下,这两种事件发生的频率显然远远低于客户端对数据进行访问的频率。
luminous版部署
http://docs.ceph.com/docs/master/start/
部署前准备
#设置主机名解析 [root@ceph-node1 ~]# cat /etc/hosts 192.168.0.122 ceph-node1 192.168.0.126 ceph-node2 192.168.0.127 ceph-node3 #配置yum源 [root@ceph-node1 ~]# wget -O /etc/yum.repos.d/ceph.repo https://raw.githubusercontent.com/aishangwei/ceph-demo/master/ceph-deploy/ceph.repo #同步时间 [root@ceph-node1 ~]# yum install ntp ntpdate [root@ceph-node1 ~]# ntpdate cn.ntp.org.cn 14 Feb 09:58:28 ntpdate[9481]: adjust time server 202.108.6.95 offset -0.005293 sec #创建用户 [root@ceph-node1 ~]# useradd ceph-admin [root@ceph-node1 ~]# echo "123456" | passwd --stdin ceph-admin #设置sudo权限 [root@ceph-node1 ~]# echo "ceph-admin ALL = (root) NOPASSWD:ALL" | tee /etc/sudoers.d/ceph-admin ceph-admin ALL = (root) NOPASSWD:ALL [root@ceph-node1 ~]# cat /etc/sudoers.d/ceph-admin ceph-admin ALL = (root) NOPASSWD:ALL [root@ceph-node1 ~]# chmod 0440 /etc/sudoers.d/ceph-admin [root@ceph-node1 ~]# sed -i 's/Default requiretty/#Default requiretty/' /etc/sudoers #设置免密钥登陆 [root@ceph-node1 ~]# su - ceph-admin [ceph-admin@ceph-node1 ~]$ ssh-keygen [ceph-admin@ceph-node1 ~]$ ssh-copy-id ceph-admin@ceph-node1 [ceph-admin@ceph-node1 ~]$ ssh-copy-id ceph-admin@ceph-node2 [ceph-admin@ceph-node1 ~]$ ssh-copy-id ceph-admin@ceph-node3
安装ceph-deploy
[ceph-admin@ceph-node1 ~]$ sudo yum install ceph-deploy python-pip python-setuptools -y
部署节点
[ceph-admin@ceph-node1 ~]$ mkdir my-cluster [ceph-admin@ceph-node1 ~]$ cd my-cluster [ceph-admin@ceph-node1 my-cluster]$ ceph-deploy new ceph-node1 ceph-node2 ceph-node3 [ceph-admin@ceph-node1 my-cluster]$ ls ceph.conf ceph-deploy-ceph.log ceph.mon.keyring [ceph-admin@ceph-node1 my-cluster]$ vim ceph.conf [global] fsid = cde2c9f7-009e-4bb4-a206-95afa4c43495 mon_initial_members = ceph-node1, ceph-node2, ceph-node3 mon_host = 192.168.0.122,192.168.0.126,192.168.0.127 auth_cluster_required = cephx auth_service_required = cephx auth_client_required = cephx public network = 192.168.0.0/24 cluster network = 192.168.0.0/24 mon clock drift allowed = 2 mon clock drift warn backoff = 30
安装ceph包,替代ceph-deploy install
[ceph-admin@ceph-node1 my-cluster]$ sudo yum install ceph ceph-radosgw [ceph-admin@ceph-node2 ~]$ sudo yum install ceph ceph-radosgw [ceph-admin@ceph-node3 ~]$ sudo yum install ceph ceph-radosgw
查看安装版本‘
[ceph-admin@ceph-node1 my-cluster]$ ceph --version ceph version 12.2.11 (26dc3775efc7bb286a1d6d66faee0ba30ea23eee) luminous (stable)
初始化monitor,并收集所有密钥
[ceph-admin@ceph-node1 my-cluster]$ ceph-deploy mon create-initial [ceph-admin@ceph-node1 my-cluster]$ ll total 68 -rw------- 1 ceph-admin ceph-admin 71 Feb 14 12:02 ceph.bootstrap-mds.keyring -rw------- 1 ceph-admin ceph-admin 71 Feb 14 12:02 ceph.bootstrap-mgr.keyring -rw------- 1 ceph-admin ceph-admin 71 Feb 14 12:02 ceph.bootstrap-osd.keyring -rw------- 1 ceph-admin ceph-admin 71 Feb 14 12:02 ceph.bootstrap-rgw.keyring -rw------- 1 ceph-admin ceph-admin 63 Feb 14 12:02 ceph.client.admin.keyring -rw-rw-r-- 1 ceph-admin ceph-admin 318 Feb 14 11:43 ceph.conf -rw-rw-r-- 1 ceph-admin ceph-admin 38197 Feb 14 12:02 ceph-deploy-ceph.log -rw------- 1 ceph-admin ceph-admin 73 Feb 14 11:41 ceph.mon.keyring
把配置拷贝到个节点
[ceph-admin@ceph-node1 my-cluster]$ ceph-deploy admin ceph-node1 ceph-node2 ceph-node3
配置osd
for dev in /dev/sdb /dev/sdc /dev/sdd do deph-deploy disk zap ceph-node1 $dev ceph-deploy osd create ceph-node1 --data $dev deph-deploy disk zap ceph-node2 $dev ceph-deploy osd create ceph-node2 --data $dev deph-deploy disk zap ceph-node3 $dev ceph-deploy osd create ceph-node3 --data $dev done
[ceph-admin@ceph-node1 my-cluster]$ lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT sda 8:0 0 80G 0 disk ├─sda1 8:1 0 1G 0 part /boot ├─sda2 8:2 0 2G 0 part [SWAP] └─sda3 8:3 0 77G 0 part / sdb 8:16 0 20G 0 disk └─ceph--a98a1209--9b95--40b5--a273--5a24399670f3-osd--block--67017f33--62e3--44e4--b9b2--461e1a591817 253:0 0 20G 0 lvm sdc 8:32 0 20G 0 disk └─ceph--d1aac3cb--e1a7--4482--a2ae--3146659ca059-osd--block--7c47ad95--0641--45d5--b2b9--9f2db701d98a 253:1 0 20G 0 lvm sdd 8:48 0 20G 0 disk └─ceph--b84386fc--b02b--485e--99b5--94ab76e8f996-osd--block--b951860d--325c--48a6--9e98--3dfb2f676546 253:2 0 20G 0 lvm sr0 11:0 1 906M 0 rom
部署mgr
[ceph-admin@ceph-node1 my-cluster]$ ceph-deploy mgr create ceph-node1 ceph-node2 ceph-node3
#开启dashboard模块
[ceph-admin@ceph-node1 my-cluster]$ ceph mgr module enable dashboard
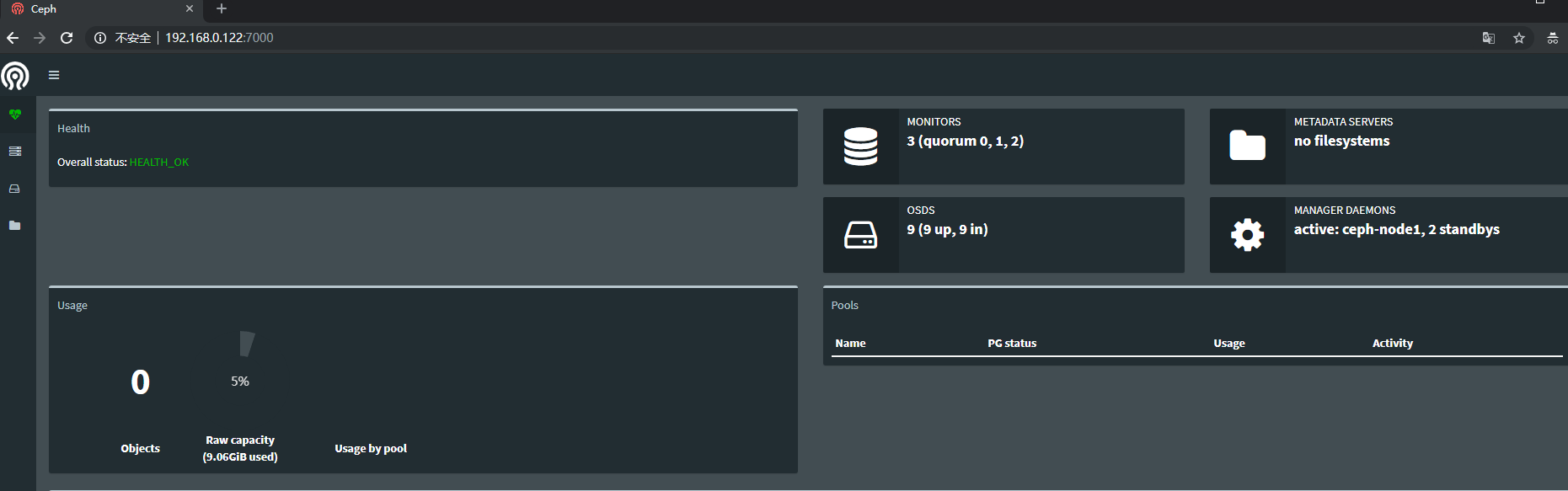
浏览器访问192.168.0.122:7000