多重线性回归要求各个自变量之间相互独立,不存在多重共线性。所谓多重共线性,是指自变量之间存在某种相关或者高度相关的关系,其中某个自变量可以被其他自变量组成的线性组合来解释。 医学研究中常见的生理资料,如收缩压和舒张压、总胆固醇和低密度脂蛋白胆固醇等,这些变量之间本身在人体中就存在一定的关联性。
如果在构建多重线性回归模型时,把具有多重共线性的变量一同放在模型中进行拟合,就会出现方程估计的偏回归系数明显与常识不相符,甚至出现符号方向相反的情况,
对模型的拟合带来严重的影响。 今天我们就来讨论一下,如果自变量之间存在多重共线性,如何通过有效的变量筛选来加以解决?
一、多重共线性判断
回顾一下前期讲解多重线性回归时,介绍的判断自变量多重共线性的方法。 1. 计算自变量两两之间的相关系数及其对应的P值,一般认为相关系数>0.7,且P<0.05时可考虑自变量之间存在共线性,可以作为初步判断多重共线性的一种方法。 2. 共线性诊断统计量,即Tolerance(容忍度)和VIF(方差膨胀因子)。一般认为如果Tolerance<0.2或VIF>5(Tolerance和VIF呈倒数关系),
则提示要考虑自变量之间存在多重共线性的问题。
二、多重共线性解决方法:变量剔除
顾名思义,当自变量之间存在多重共线性时,最简单的方法就是对共线的自变量进行一定的筛选,保留更为重要的变量,删除次要或可替代的变量,
从而减少变量之间的重复信息,避免在模型拟合时出现多重共线性的问题。 对于如何去把握应该删除哪一个变量,保留哪一个变量,近期也有小伙伴在微信平台中问到这个问题,下面举个例子进行一个简单的说明。
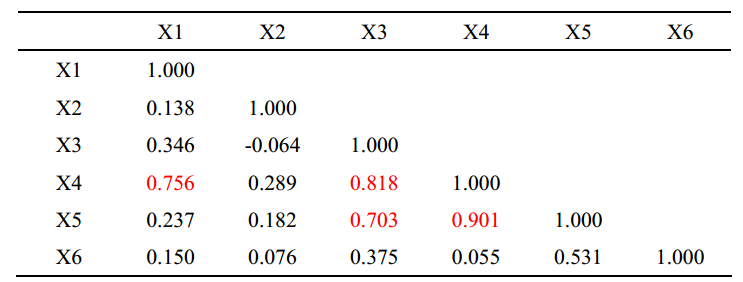
表1. 自变量相关性
如表1所示, X3和X4、X5之间相关系数>0.7,变量X4与X1、X3、X5之间相关系数>0.7,X5与X3、X4之间相关系数>0.7,说明X3、X4、X5之间存在一定的共线性,
由于X4与X1的相关性也较高,故此时建议可以先将X4删除再进行模型拟合,当然也需要结合容忍度和VIF值及专业知识来进行判断。
有些时候共线性不可能从统计上得到完全解决,因此在不损失重要信息的前提下,人为剔除共线的变量往往是最有效的方法。
三、多重共线性解决方法:逐步选择
当自变量之间的关系较为复杂,对于变量的取舍不易把握时,我们还可以利用逐步回归的方法进行变量筛选,以解决自变量多重共线性的问题。
逐步回归法从共线性的自变量中筛选出对因变量影响较为显著的若干个变量,把对因变量贡献不大的自变量排除在模型之外,从而建立最优的回归子集,
不仅克服了共线性问题,而且使得回归方程得到简化。 在SPSS中提供了5种自变量进入模型的方法: 1. Enter(进入法) 将所选自变量强制性引入模型中进行拟合,不涉及变量筛选的问题,为默认选项。 2. Remove(移除法) 将指定的自变量强制性移除模型。Remove方法的第一步是利用Enter法构建回归方程,第二步再用Remove法将指定的自变量移除模型。该方法常与其他筛选变量的方法联合使用。 3. Forward selection(前进法) 即回归方程中的自变量从无到有,由少到多逐个引入来构建模型的一种方法。这里需要提到一个新的概念--偏回归平方和,简单来说就是在模型已经含有其他自变量的基础上,
加入一个新的自变量后,引起的对于回归模型贡献的增加量,或者删除某个自变量后,引起的对于回归模型贡献的减少量。 如果不太好理解,这里打个比方,某个公司(因变量Y)将进行员工(自变量X)选拔。第一步,公司(Y)需要评估一下每个员工(X)对公司(Y)的贡献大小(偏回归平方和),
选拔出贡献最大且有统计学显著性(引入标准Pin<0.05)的第一个员工(X1)。 第二步,在选拔出第一个员工(X1)的基础上,公司(Y)再次评价如果每个员工都与第一个员工(X1)一起工作时所产生的贡献增加量(偏回归平方和),
选拔出贡献最大且有显著性意义的第二个员工(X2)。以此类推不断有员工(X)选拔进来,直到公司认为即使再有员工选拔进来,也不会额外增加对公司(Y)的贡献,
此时选拔结束,以上即为前进法的基本流程。 前进法的优点是可以自动去掉高度相关的自变量,但也有一定的局限性,前进法在自变量选择的过程中,只在自变量引入模型时考察其是否有统计学意义,
并不考虑在引入模型后每个自变量P值的变化,后续变量的引入可能会使先进入方程的自变量变得无统计学意义。 4. Backward elimination(后退法) 后退法与前进法相反,即先建立全变量模型,然后逐步剔除无统计学意义的自变量,以此构建回归模型的一种方法。如果说前进法是选拔员工,那么后退法就相当于公司裁员,
每一次裁掉一个对公司贡献最小且无显著性意义的员工(剔除标准Pout>0.1),然后对剩下的员工再次进行评估,裁掉一个贡献最小的员工,以此类推不断有员工被裁掉,
直到公司认为即使再裁掉其他员工,也不会额外减少对公司的贡献,此时裁员停止,以上即为后退法的基本流程。 后退法的优点是考虑了自变量的组合作用,但是当自变量数目较多或者自变量间高度相关时,可能得不出正确的结论。 5. Stepwise(逐步回归法) 逐步回归法,是在前进法和后退法的基础上,进行双向筛选变量的一种方法。其本质是前进法,也就是说公司(Y)每引入一个员工(X)后,
都要重新对已经进入公司的每个员工的贡献进行评估和检验,如果原有的员工由于后续引入新员工后,其贡献变得不再有显著性,则会将其裁掉,
以确保公司里每一个员工的贡献都是有意义的。 这个过程反复进行,直到既没有不显著的自变量引入回归方程,也没有显著的自变量从回归方程中剔除为止,从而得到一个最优的回归方程。
逐步回归法结合了前进法和后退法的优点,因此被作为自变量筛选的一种常用的方法。
四、注意事项
1. 在Linear Regression对话框中点击Options选项,可以设定自变量引入(Entry)和剔除(Removal)的临界值。
如设定引入标准的Pin值为0.05,剔除标准的Pout值为0.1,或者设定其对应的F值。一般要求引入变量的检验水准要小于等于剔除变量的水准,
即Pin ≤ Pout,P值越小表明选取自变量的标准越严格,对于小样本数据可以适当将P值设定为0.1甚至0.15,0.2。

2. Forward、Backward、Stepwise的侧重点有所不同,三种方法的选择取决于你的研究目的,如果是进行预测,在预测效果差不多的情况下,一般选择自变量最少的方法。
当自变量间不存在多重共线性时,三种方法的计算结果基本一致。当自变量间存在多重共线性时,Forward侧重于引入单独作用较强的变量,
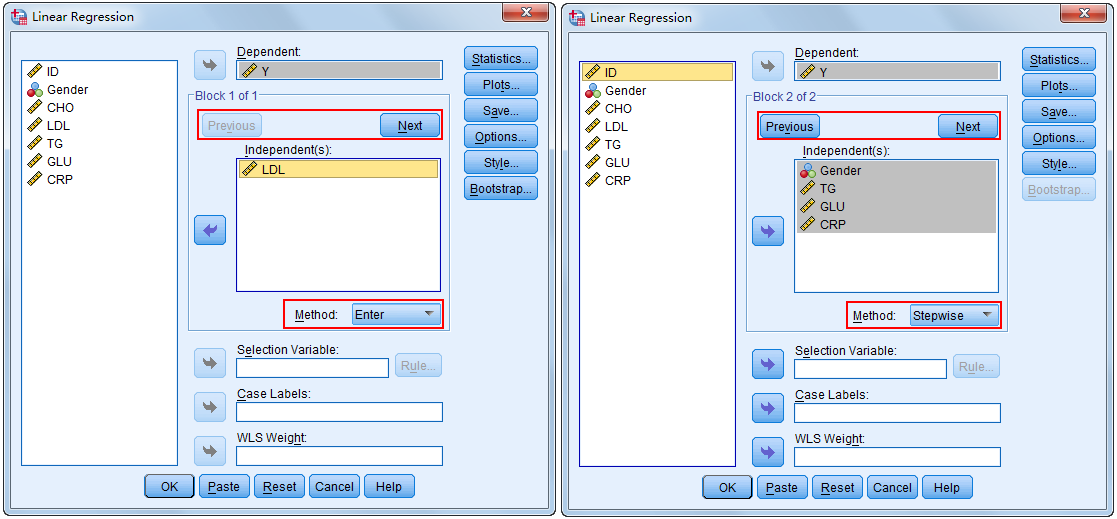
Backward侧重于引入联合作用较强的变量,Stepwise介于两者之间。 3. 在Linear Regression对话框中,可以利用Previous和Next组合选项,将自变量分为不同的块(Block),并且对不同Block中的变量可以指定不同的变量筛选的方法,
以满足复杂变量筛选的要求。例如:首先将LDL选入Independent(s)框中,Method选择Enter法,然后点击Next,再将其他变量选入Independent(s)框中,
Method选择Stepwise法。
4. 这一期内容主要从变量筛选的角度,包括根据相关性和共线性诊断结果进行变量剔除,或者在自变量选择时采用向前、向后或逐步回归的方法,以解决自变量间多重共线性的问题。
在下一期内容中,我们将继续向大家介绍另一种用于处理多重共线性的方法--岭回归法,敬请期待。