1,从点A开始,并且把它作为待处理点存入一个“开启列表”。开启列表就像一张购物清单。尽管现在列表里只有一个元素,但以后就会多起来。你的路径可能会通过它包含的方格,也可能不会。基本上,这是一个待检查方格的列表。
2,寻找起点周围所有可到达或者可通过的方格,跳过有墙,水,或其他无法通过地形的方格。也把他们加入开启列表。为所有这些方格保存点A作为“父方格”。当我们想描述路径的时候,父方格的资料是十分重要的。后面会解释它的具体用途。
3,从开启列表中删除点A,把它加入到一个“关闭列表”,列表中保存所有不需要再次检查的方格。在这一点,你应该形成如图的结构。在图中,暗绿色方格是你起始方格的中心。它被用浅蓝色描边,以表示它被加入到关闭列表中了。所有的相邻格现在都在开启列表中,它们被用浅绿色描边。每个方格都有一个灰色指针反指他们的父方格,也就是开始的方格。

[图-2]
接着,我们选择开启列表中的临近方格,大致重复前面的过程,如下。但是,哪个方格是我们要选择的呢?是那个F值最低的。
路径评分
选择路径中经过哪个方格的关键是下面这个等式:F = G + H
这里:
* G = 从起点A,沿着产生的路径,移动到网格上指定方格的移动耗费。
* H = 从网格上那个方格移动到终点B的预估移动耗费。这经常被称为启发式的,可能会让你有点迷惑。这样叫的原因是因为它只是个猜测。我们没办法事先知道路径的长度,因为路上可能存在各种障碍(墙,水,等等)。虽然本文只提供了一种计算H的方法,但是你可以在网上找到很多其他的方法。
我们的路径是通过反复遍历开启列表并且选择具有最低F值的方格来生成的。文章将对这个过程做更详细的描述。首先,我们更深入的看看如何计算这个方程。
正如上面所说,G表示沿路径从起点到当前点的移动耗费。在这个例子里,我们令水平或者垂直移动的耗费为,对角线方向耗费为。我们取这些值是因为沿对角线的距离是沿水平或垂直移动耗费的的根号(别怕),或者约.414倍。为了简化,我们用和近似。比例基本正确,同时我们避免了求根运算和小数。这不是只因为我们怕麻烦或者不喜欢数学。使用这样的整数对计算机来说也更快捷。你不就就会发现,如果你不使用这些简化方法,寻路会变得很慢。
既然我们在计算沿特定路径通往某个方格的G值,求值的方法就是取它父节点的G值,然后依照它相对父节点是对角线方向或者直角方向(非对角线),分别增加和。例子中这个方法的需求会变得更多,因为我们从起点方格以外获取了不止一个方格。
H值可以用不同的方法估算。我们这里使用的方法被称为曼哈顿方法,它计算从当前格到目的格之间水平和垂直的方格的数量总和,忽略对角线方向,然后把结果乘以10。这被称为曼哈顿方法是因为它看起来像计算城市中从一个地方到另外一个地方的街区数,在那里你不能沿对角线方向穿过街区。很重要的一点,我们忽略了一切障碍物。这是对剩余距离的一个估算,而非实际值,这也是这一方法被称为启发式的原因。想知道更多?你可以在这里找到方程和额外的注解。
F的值是G和H的和。第一步搜索的结果可以在下面的图表中看到。F,G和H的评分被写在每个方格里。正如在紧挨起始格右侧的方格所表示的,F被打印在左上角,G在左下角,H则在右下角。
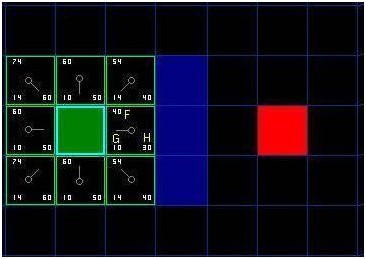
[图-3]
现在我们来看看这些方格。写字母的方格里,G = 10。这是因为它只在水平方向偏离起始格一个格距。紧邻起始格的上方,下方和左边的方格的G值都等于。对角线方向的G值是。
H值通过求解到红色目标格的曼哈顿距离得到,其中只在水平和垂直方向移动,并且忽略中间的墙。用这种方法,起点右侧紧邻的方格离红色方格有格距离,H值就是。这块方格上方的方格有格距离(记住,只能在水平和垂直方向移动),H值是。你大致应该知道如何计算其他方格的H值了~。每个格子的F值,还是简单的由G和H相加得到
继续搜索
为了继续搜索,我们简单的从开启列表中选择F值最低的方格。然后,对选中的方格做如下处理:
4,把它从开启列表中删除,然后添加到关闭列表中。
5,检查所有相邻格子。跳过那些已经在关闭列表中的或者不可通过的(有墙,水的地形,或者其他无法通过的地形),把他们添加进开启列表,如果他们还不在里面的话。把选中的方格作为新的方格的父节点。
6,如果某个相邻格已经在开启列表里了,检查现在的这条路径是否更好。换句话说,检查如果我们用新的路径到达它的话,G值是否会更低一些。如果不是,那就什么都不做。
另一方面,如果新的G值更低,那就把相邻方格的父节点改为目前选中的方格(在上面的图表中,把箭头的方向改为指向这个方格)。最后,重新计算F和G的值。如果这看起来不够清晰,你可以看下面的图示。
好了,让我们看看它是怎么运作的。我们最初的格方格中,在起点被切换到关闭列表中后,还剩格留在开启列表中。这里面,F值最低的那个是起始格右侧紧邻的格子,它的F值是。因此我们选择这一格作为下一个要处理的方格。在紧随的图中,它被用蓝色突出显示。
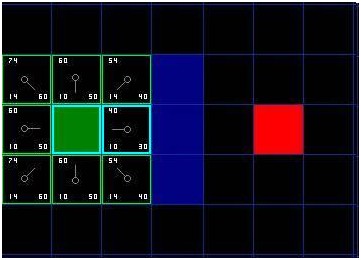
[图-4]
首先,我们把它从开启列表中取出,放入关闭列表(这就是他被蓝色突出显示的原因)。然后我们检查相邻的格子。哦,右侧的格子是墙,所以我们略过。左侧的格子是起始格。它在关闭列表里,所以我们也跳过它。
其他格已经在开启列表里了,于是我们检查G值来判定,如果通过这一格到达那里,路径是否更好。我们来看选中格子下面的方格。它的G值是。如果我们从当前格移动到那里,G值就会等于(到达当前格的G值是,移动到上面的格子将使得G值增加)。因为G值大于,所以这不是更好的路径。如果你看图,就能理解。与其通过先水平移动一格,再垂直移动一格,还不如直接沿对角线方向移动一格来得简单。
当我们对已经存在于开启列表中的个临近格重复这一过程的时候,我们发现没有一条路径可以通过使用当前格子得到改善,所以我们不做任何改变。既然我们已经检查过了所有邻近格,那么就可以移动到下一格了。
于是我们检索开启列表,现在里面只有7格了,我们仍然选择其中F值最低的。有趣的是,这次,有两个格子的数值都是。我们如何选择?这并不麻烦。从速度上考虑,选择最后添加进列表的格子会更快捷。这种导致了寻路过程中,在靠近目标的时候,优先使用新找到的格子的偏好。但这无关紧要。(对相同数值的不同对待,导致不同版本的A*算法找到等长的不同路径)那我们就选择起始格右下方的格子,如图:
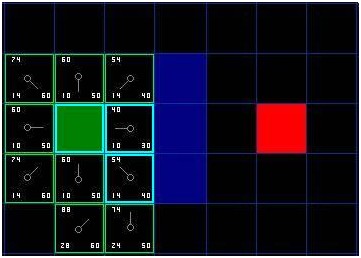
[图-5]
这次,当我们检查相邻格的时候,发现右侧是墙,于是略过。上面一格也被略过。我们也略过了墙下面的格子。为什么呢?因为你不能在不穿越墙角的情况下直接到达那个格子。你的确需要先往下走然后到达那一格,按部就班的走过那个拐角。(注解:穿越拐角的规则是可选的。它取决于你的节点是如何放置的。)
这样一来,就剩下了其他格。当前格下面的另外两个格子目前不在开启列表中,于是我们添加他们,并且把当前格指定为他们的父节点。其余格,两个已经在关闭列表中(起始格,和当前格上方的格子,在表格中蓝色高亮显示),于是我们略过它们。最后一格,在当前格的左侧,将被检查通过这条路径,G值是否更低。不必担心,我们已经准备好检查开启列表中的下一格了。
我们重复这个过程,直到目标格被添加进关闭列表(注解),就如在下面的图中所看到的。
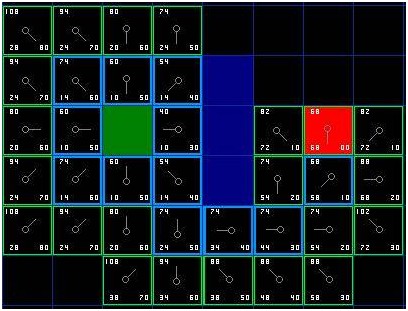
[图-6]
注意,起始格下方格子的父节点已经和前面不同的。之前它的G值是,并且指向右上方的格子。现在它的G值是,指向它上方的格子。这在寻路过程中的某处发生,当应用新路径时,G值经过检查变得低了-于是父节点被重新指定,G和F值被重新计算。尽管这一变化在这个例子中并不重要,在很多场合,这种变化会导致寻路结果的巨大变化。
上述图片和文字来源于:http://www.cppblog.com/mythit/archive/2009/04/19/80492.aspx
算法实现:
import java.util.ArrayList; import java.util.Collection; import java.util.HashMap; import java.util.Iterator; import java.util.List; import java.util.Map; import java.util.Set; public class Astar { Apoint startPoint; Apoint endPoint; List<Apoint>obstruct; public void minDistance(Apoint minD1,double minD,List<Apoint>obstruct,Map<Apoint,Double>distance,Apoint start ,Apoint end,Map<Apoint,Double>open,List<Apoint>close){ if(open==null){ open = new HashMap<Apoint,Double>(); close = new ArrayList<Apoint>(); open.put(start, (double) 0); distance = new HashMap<Apoint,Double>(); } if(close.contains(end)){ return ; } //取出open中minD1 if(minD1==null){ minD1 = new Apoint(); minD1 = start; } Apoint first = minD1; //返回这第一个点周围不包含在close和阻碍点的点集 close.add(first); System.out.println("当前所选点为: "+"( "+first.getX()+" , "+first.getY()+" )"); Map<Apoint,Double>round = first.creatRound(obstruct,close); //open.remove(first); open = new HashMap(); distance.remove(first); open.putAll(round); Set set = open.keySet(); Iterator iter = set.iterator(); //将distance重新计算 //首先遍历open中的点,如果open中的点在distance中,判断加上此open中点的距离小还是原来distance中的距离小,并寻找最小的距离 while (iter.hasNext()) { Apoint point = (Apoint) iter.next(); if(distance.containsKey(point)){ if(minD+open.get(point)<distance.get(point)){ distance.replace(point, minD+open.get(point)); } }else{ distance.put(point, minD+open.get(point)); } } //将distance中距离最小值放到首位置 Set setD = distance.keySet(); Iterator iterD = setD.iterator(); minD1 = (Apoint) iterD.next(); double disMin = distance.get(minD1)+Math.abs(end.getX()-minD1.getX()); while (iterD.hasNext()) { Apoint point = (Apoint) iterD.next(); double dis = distance.get(point)+Math.abs(end.getX()-point.getX()); if(disMin>dis){ minD1 = point; disMin = dis; } } System.out.println(); System.out.println("当前最短距离为: "+disMin); minDistance(minD1,distance.get(minD1),obstruct,distance,start,end,open,close); } }
得出当前最短距离为: 5.656
实现算法时,经历过的错误和注意事项:
1、minD1表示上次搜索的最优点,minD表示从起点到最优点的距离,distance表示所有在open中点到起点之间的距离。
2、open每次都清空,并放入当前点的周围点,close加入当前点的时候,记得将distance中当前点也删除掉。