该随笔主要记录包括urllib、Requests、Selenium、Lxml、Beautifulsoup、pyquery这几个基于爬虫的常用包,主要用于自己的查看和理解,每个包通过2个例子实现对新浪网的新闻和淘宝的图片爬取到本地的测试。
1.urllib(这是python的内置库,是最基础的爬虫实现包)
--爬取新浪网:
在新浪网页上打开审查元素,在Network中查看源码,ctrl+f查找一条新闻链接,寻找新闻链接的共性,从而构造正则表达式:
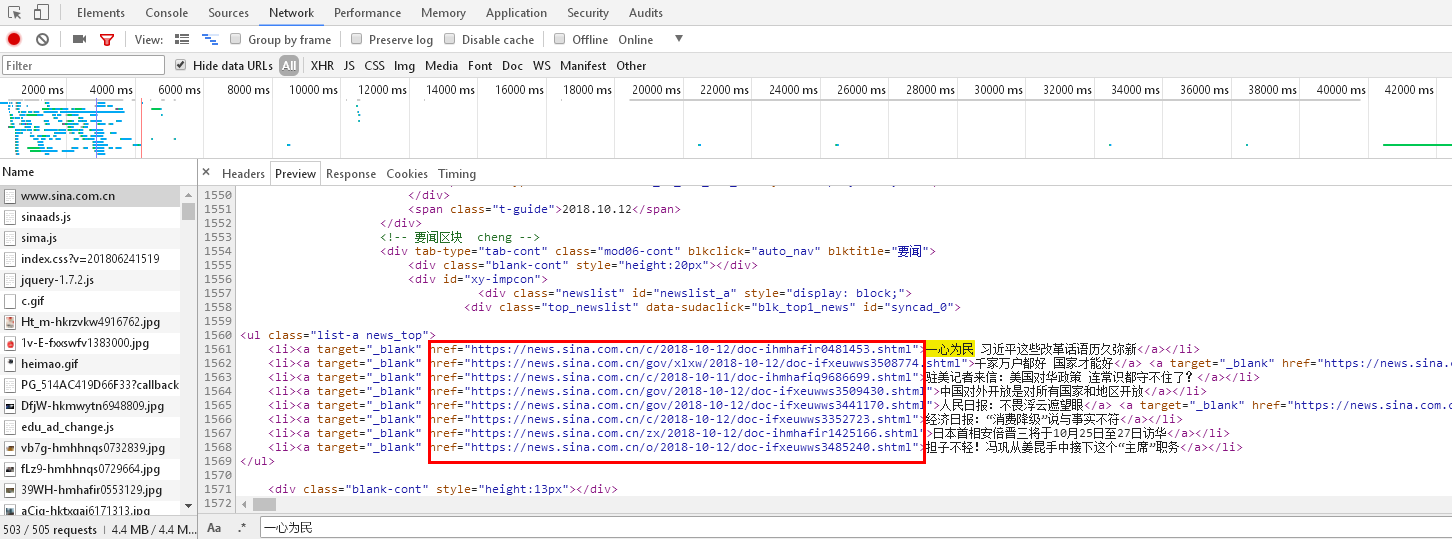
可以看到新闻的前缀是一样的,只有后面不同,因此基于此我们构造如下pat,代码如下:
1 import urllib.request 2 import re 3 data=urllib.request.urlopen("http://news.sina.com.cn/").read().decode("utf8") 4 pat='href="(http://news.sina.com.cn/.*?)"' 5 allurl=re.compile(pat).findall(data) 6 m=0 7 for i in range(0,len(allurl)): 8 thisurl=allurl[i] 9 file="sinanews/"+str(i)+".html" 10 print('***** ' + str(m) + '.html *****' + ' Downloading...') 11 urllib.request.urlretrieve(thisurl,file) 12 m=m+1 13 print("Download complete!")
由此将新浪网页下的所有新闻都保存到了项目路径下的sinanews文件夹下,并且以html格式保存,我们可以直接打开查看。
--爬取淘宝网的图片:
打开淘宝网,随便选择一个词条,比如连衣裙,因为要想抓取网页,首先要选择正确的url,我们观察该词条下的url:
第1页:https://s.taobao.com/list?spm=a21bo.2017.201867-links-0.4.5af911d9LYgSzG&q=%E8%BF%9E%E8%A1%A3%E8%A3%99&cat=16&seller_type=taobao&oetag=6745&source=qiangdiao 第2页:https://s.taobao.com/list?spm=a21bo.2017.201867-links-0.4.5af911d9LYgSzG&q=%E8%BF%9E%E8%A1%A3%E8%A3%99&cat=16&seller_type=taobao&oetag=6745&source=qiangdiao&bcoffset=12&s=60 第3页:https://s.taobao.com/list?spm=a21bo.2017.201867-links-0.4.5af911d9LYgSzG&q=%E8%BF%9E%E8%A1%A3%E8%A3%99&cat=16&seller_type=taobao&oetag=6745&source=qiangdiao&bcoffset=12&s=120 第4页:https://s.taobao.com/list?spm=a21bo.2017.201867-links-0.4.5af911d9LYgSzG&q=%E8%BF%9E%E8%A1%A3%E8%A3%99&cat=16&seller_type=taobao&oetag=6745&source=qiangdiao&bcoffset=12&s=180 .......
再观察地址栏里的url:

可以看到q为我们选择的词条,cat、seller_type、oetag、source、bcoffset这几个关键字可以先不管,发现每增加1页,s增加60,而且一般来说,url标准中只会允许一部分ASCII字符比如数字、字母、部分符号等,而其他的一些字符,比如汉字等,是不符合url标准的。此时,我们需要编码。 如果要进行编码,我们可以使用urllib.request.quote()进行。确定了url,我们就需要确定pat,因为要爬取原始图片,因此我们先打开几个图片的图片链接看一下:
https://gd1.alicdn.com/imgextra/i3/87074513/O1CN011jCzthh4QDGafN9_!!87074513.jpg
https://gd2.alicdn.com/imgextra/i2/262659183/TB2dc7araAoBKNjSZSyXXaHAVXa_!!262659183.jpg
https://img.alicdn.com/imgextra/i1/647360108/O1CN011CfVEUsl2yGMDfj_!!647360108.jpg
.......
然后在审查元素中搜索.jpg:
"pic_url":"//g-search1.alicdn.com/img/bao/uploaded/i4/i3/87074513/O1CN011jCzthh4QDGafN9_!!87074513.jpg"
"pic_url":"//g-search3.alicdn.com/img/bao/uploaded/i4/i2/262659183/TB2dc7araAoBKNjSZSyXXaHAVXa_!!262659183.jpg"
"pic_url":"//g-search3.alicdn.com/img/bao/uploaded/i4/i1/647360108/O1CN011CfVEOB6hhNrGuV_!!647360108.jpg"
.......
我们发现了所有图片的共同点,并且直接复制相同后面的地址确实可以打开该图片,因此pat就知道如何定义了,知道了url和pat就可以爬取了:
import urllib.request import re keyname = "连衣裙" key = urllib.request.quote(keyname) for i in range(0, 2): url = "https://s.taobao.com/list?spm=a21bo.2017.201867-links-0.4.5af911d9RnfrEY&q=" + key + "&cat=16&seller_type=taobao&oetag=6745&source=qiangdiao&bcoffset=12&s=" + str(i * 60) print(url) print("") data = urllib.request.urlopen(url).read().decode("utf-8", "ignore") pat = '"pic_url":"//(.*?)jpg"' imagelist = re.compile(pat).findall(data) # 图片的网站 # print(imagelist) # print("") m=0 # 下面循环爬取每一页中所有的图片 for j in range(0, len(imagelist)): thisimg = imagelist[j] thisimgurl = "http://" + thisimg + "jpg" file = "imgs/" + str(i) + "-" + str(j) + ".jpg" print('***** ' + str(m) + '.jpg *****' + ' Downloading...') urllib.request.urlretrieve(thisimgurl, filename=file) m=m+1 print("Download complete!")
由此将淘宝网的连衣裙词条下的所有图片都保存到了项目路径下的imgs文件夹下,并且以jpg格式保存,我们可以直接打开查看。
至此urllib基本库下的简单爬虫已经实现,后面的库都是基于该库。
2.Requests(需要安装导包)
--新闻爬取:
import requests import re import urllib.request data=requests.get("https://www.sina.com.cn/").content.decode("utf8") #print(data,' ') pat='href="(http://news.sina.com.cn/.*?)"' allurl=re.compile(pat).findall(data) m=0 for i in range(0,len(allurl)): thisurl=allurl[i] file="sinanews/"+str(i)+".html" print('***** ' + str(m) + '.html *****' + ' Downloading...') urllib.request.urlretrieve(thisurl,file) m=m+1 print("Download complete!")
--图片爬取:
如果我们结合正则表达式pat和requests库中的命令完全可以实现图片抓取,现在我们采取requests库和json库结合的方式爬取搜狗图片中的图片,学习一下json库,我们来分析一下搜狗图片库中的信息:
打开审查元素后,可以发现当我们向下滑动时,图片是一行一行加载的,而不是一下全部加载完,因此可以知道图片是动态的,查看审查元素也看不到各个图片的信息,因此我们继续看XHR选项:
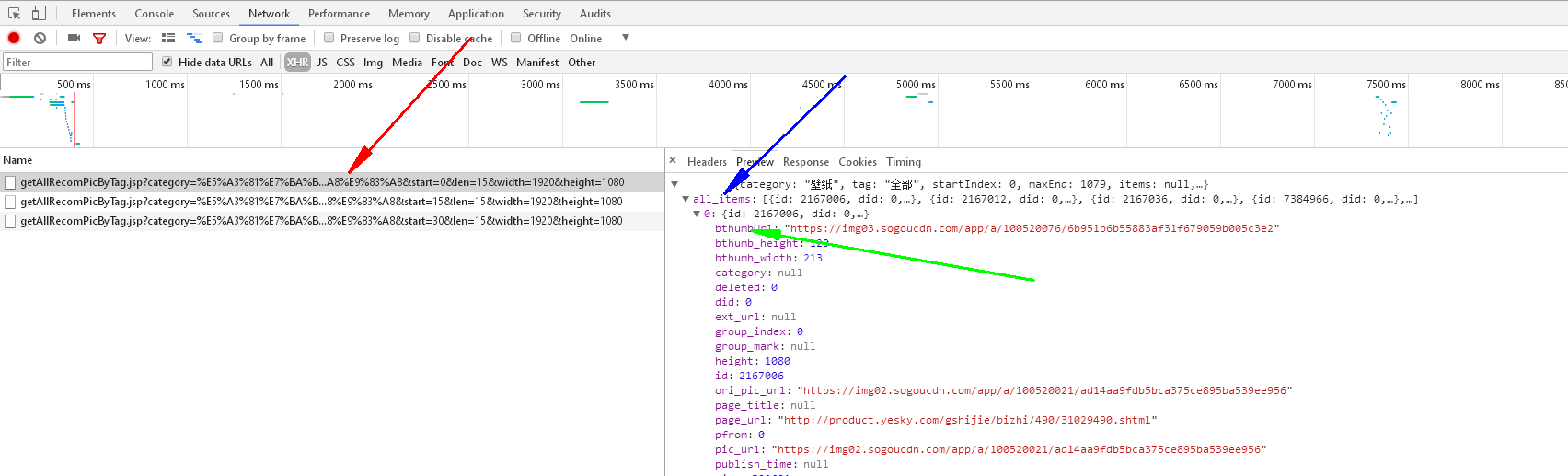
红箭头所指之处表明页面中每加载15个图片将产生一个新的url
蓝箭头所指之处表明该url下的所有图片存放的地方
绿箭头所指之处我们打开url可以显示图片,因此是我们需要的图片url
因为该网页的图片是动态存储,使用的是JSON数据,因此使用json.loads来解析,并且提取出‘all_items’中的‘bthumbUrl’的词条,即图片地址,以下就是代码:
import requests import urllib import json def getSogouImag(category,length,path): n=length cate=category imgs=requests.get('http://pic.sogou.com/pics/channel/getAllRecomPicByTag.jsp?category='+cate+'&tag=%E5%85%A8%E9%83%A8&start=0&len='+str(n)) jd=json.loads(imgs.text) jd=jd['all_items'] imgs_url=[] for j in jd: imgs_url.append(j['bthumbUrl']) m=0 for img_url in imgs_url: print('***** ' + str(m) + '.jpg *****' + ' Downloading...') urllib.request.urlretrieve(img_url,path+str(m)+'.jpg') m=m+1 print('Download complete!') getSogouImag('壁纸',100,'D:/Python/pycharm/program/程序代码/laptop/imags/')
该实现表示当遇到动态的信息存储时,我们需要爬的数据在json文件中,我们该如何爬取的操作。
3.BeautifulSoup库(使用对标签选择器进行选择的方法来获取网页中的内容)
注意事项:
*推荐使用lxml解析库,必要时使用html.parser
*标签选择器筛选功能弱但是速度快
*建议使用find()、find_all()查询匹配单个结果或多个结果
*如果对CSS选择器熟悉建议使用select()
*记住常用的获取属性和文本值的方法
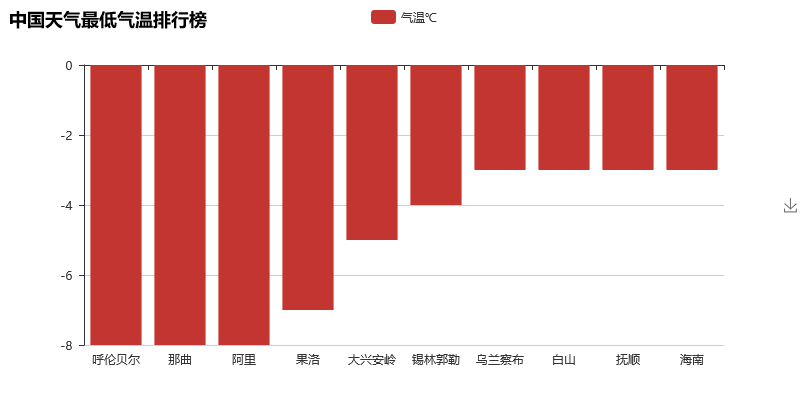
--对中国天气网的数据进行爬取,并对数据进行分析,得出目前位置气温最低的城市
# encoding:utf-8 import requests from bs4 import BeautifulSoup from pyecharts import Bar ALL_DATA = [] def parse_page(url): respones = requests.get(url) # print(respones.text)是乱码,需要解码 # print(respones.content.decode("utf8")) text = respones.content.decode("utf8") # soup=BeautifulSoup(text,"lxml") soup = BeautifulSoup(text, "html5lib") # 解析网页功能更强,但是速度慢 conMidtab = soup.find('div', class_='conMidtab') # print(conMidtab) tables = conMidtab.find_all('table') for table in tables: trs = table.find_all('tr')[2:] for index, tr in enumerate(trs): tds = tr.find_all('td') # print(type(tds[0])) city_name = list(tds[0].stripped_strings)[0] if (index == 0): city_name = list(tds[1].stripped_strings)[0] # print(city_name) min_temp = list(tds[-2].stripped_strings)[0] # print(min_temp) ALL_DATA.append({"city": city_name, "min_temp": int(min_temp)}) # print({"city:":city_name,"min_temp":int(min_temp)}) def main(): area_url = {"hb": "http://www.weather.com.cn/textFC/hb.shtml", "db": "http://www.weather.com.cn/textFC/db.shtml", "hd": "http://www.weather.com.cn/textFC/hd.shtml", "hz": "http://www.weather.com.cn/textFC/hz.shtml", "hn": "http://www.weather.com.cn/textFC/hn.shtml", "xb": "http://www.weather.com.cn/textFC/xb.shtml", "xn": "http://www.weather.com.cn/textFC/xn.shtml", "gat": "http://www.weather.com.cn/textFC/gat.shtml"} for key in area_url.keys(): # url="http://www.weather.com.cn/textFC/hb.shtml" url = area_url[key] parse_page(url) # 分析数据 # 对最低气温进行排序 ALL_DATA.sort(key=lambda data: data["min_temp"]) data = ALL_DATA[0:10] # print(data) cities = list(map(lambda x: x['city'], data)) temps = list(map(lambda y: y['min_temp'], data)) chart = Bar("中国天气最低气温排行榜") chart.add("气温℃", cities, temps) chart.render("temperature.html") print("视图生成完毕!") if __name__ == '__main__': main()
4.pyQuery库(也是对标签进行选择,语法和jQuery一样)
--对猫眼电影的top100电影进行抓取
from pyquery import PyQuery as pq import requests Movies = [] Score = [] Update_time = [] Board_content = [] def pare_page(url): # 对于有些禁止爬虫的网站,设置headers来模拟浏览器登陆 headers = { 'Host': "maoyan.com", 'User-Agent': "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36" } response = requests.get(url, headers=headers) text = response.content.decode("utf8") doc = pq(text) # 获取电影名 movie_item_info = doc('div').filter('.movie-item-info') movie_names = movie_item_info('p').filter(".name") # movie_names=names('a').attr('title') for movie_name in movie_names.items('a'): # print(type(movie_name.text())) Movies.append(movie_name.text()) # 猫眼网站电影的评分是两个标签,所以要分别取出来再合并 score_integers = doc('i').filter('.integer') score_fractions = doc('i').filter('.fraction') integers = [] fractions = [] for score_integer in score_integers.items('i'): integers.append(score_integer.text()) for score_fraction in score_fractions.items('i'): fractions.append(score_fraction.text()) for i in range(len(integers)): Score.append(integers[i] + fractions[i]) # 获取更新时间 Update_time.append(doc('p').filter('.update-time').text()) # 获取榜单规则 Board_content.append(doc('p').filter('.board-content').text()) def main(): num = 0 for i in range(0, 10): if i == 0: url = "http://maoyan.com/board/4" else: url = "http://maoyan.com/board/4" + "?offset=" + str(i * 10) pare_page(url) # 输出 print(Update_time[0]) print(Board_content[0]) for i in range(len(Movies)): print("Top" + str(num + 1) + ":" + Movies[i] + " 评分:" + Score[i]) num=num+1 if __name__ == '__main__': main()
