----项目3(scrapy框架+pymsql包抓取数据到本地):
利用scrapy框架完成对 https://www.phei.com.cn/module/goods/searchkey.jsp?Page=1&searchKey=python网页所有页面的图书信息抓取。
构思:初始想法使用更高级的CrawlSpider爬取,因为里面的rules规则可以直接自动爬取符合该Rule的所有URL,但这里有个问题是在项目2中,我们之所以可以使用CrawlSpider爬取符合Rule的URL,那是因为在网页的源代码里符合该Rule的URL是保存在某个标签的href里,我们是可以抓取到的,而该网页的URL都是写到js的函数中,它的跳转是通过js的next_page函数实现,无法获得跳转下一页的URL,因此就不能使用该方法(或者说可以使用但是目前我还不会。。),因此就可以使用scrapy的普通功能加入循环来控制翻页。下面上图为可以使用CrawlSpider的网页源代码,下图为不可以使用的源代码:

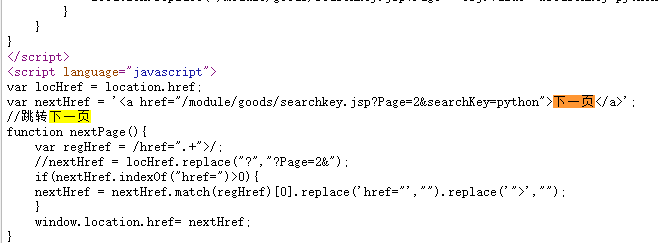
下面就开始编码。
设置setting文件:
...... ...... ...... BOT_NAME = 'book_test' SPIDER_MODULES = ['book_test.spiders'] NEWSPIDER_MODULE = 'book_test.spiders' ...... ...... ...... ROBOTSTXT_OBEY = False ...... ...... ...... DEFAULT_REQUEST_HEADERS = { 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8', 'Accept-Language': 'en', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36' } ...... ...... ...... ITEM_PIPELINES = { 'book_test.pipelines.BookTestPipeline': 300, } ...... ...... ......
写爬虫文件:
# -*- coding: utf-8 -*- import scrapy from book_test.items import BookTestItem from bs4 import BeautifulSoup import requests class BookSpiderSpider(scrapy.Spider): name = 'book_spider' allowed_domains = ['phei.com.cn'] start_urls = ['https://www.phei.com.cn/module/goods/searchkey.jsp?Page=1&searchKey=python'] def parse(self, response): title = response.xpath("//span[@class='book_title']/a/text()").getall() author = response.xpath("//span[@class='book_author']/text()").getall() price = response.xpath("//span[@class='book_price']/b/text()").getall() book_urls = response.xpath("//span[@class='book_title']/a/@href").getall() sources=[] for book_url in book_urls: sources.append("https://www.phei.com.cn"+book_url) introduction=[] for source in sources: response_source = requests.get(source).content.decode("utf8") soup = BeautifulSoup(response_source,'html5lib') source_introduction = soup.find('div',class_='book_inner_content') introduction.append(source_introduction.find('p').text) item = BookTestItem(title=title,author=author,price=price,sources=sources,introduction=introduction) yield item for i in range(2,6): next_url = "https://www.phei.com.cn/module/goods/searchkey.jsp?Page="+str(i)+"&searchKey=python" yield scrapy.Request(next_url,callback=self.parse)
设置item模式:
# -*- coding: utf-8 -*- # Define here the models for your scraped items # # See documentation in: # https://doc.scrapy.org/en/latest/topics/items.html import scrapy class BookTestItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() title = scrapy.Field() author = scrapy.Field() price = scrapy.Field() sources = scrapy.Field() introduction = scrapy.Field()
写pipelines文件,注意pymysql包的用法:
# -*- coding: utf-8 -*- import pymysql # Define your item pipelines here # # Don't forget to add your pipeline to the ITEM_PIPELINES setting # See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html class BookTestPipeline(object): def __init__(self): self.conn = pymysql.connect(host="localhost", user="root", passwd="7458", db="sys", port=3306) self.cur = self.conn.cursor() def process_item(self, item, spider): for i in range(0, len(item["title"])): title = item["title"][i] author = item["author"][i] price = item["price"][i] sources = item["sources"][i] introduction = item["introduction"][i] sql = "insert into book_db(title,author,price,sources,introduction) values('" + title + "','" + author + "','" + price + "','" + sources + "','" + introduction + "')" self.cur.execute(sql) self.conn.commit() return item conn.close()
设置启动文件:
from scrapy import cmdline cmdline.execute("scrapy crawl book_spider".split())
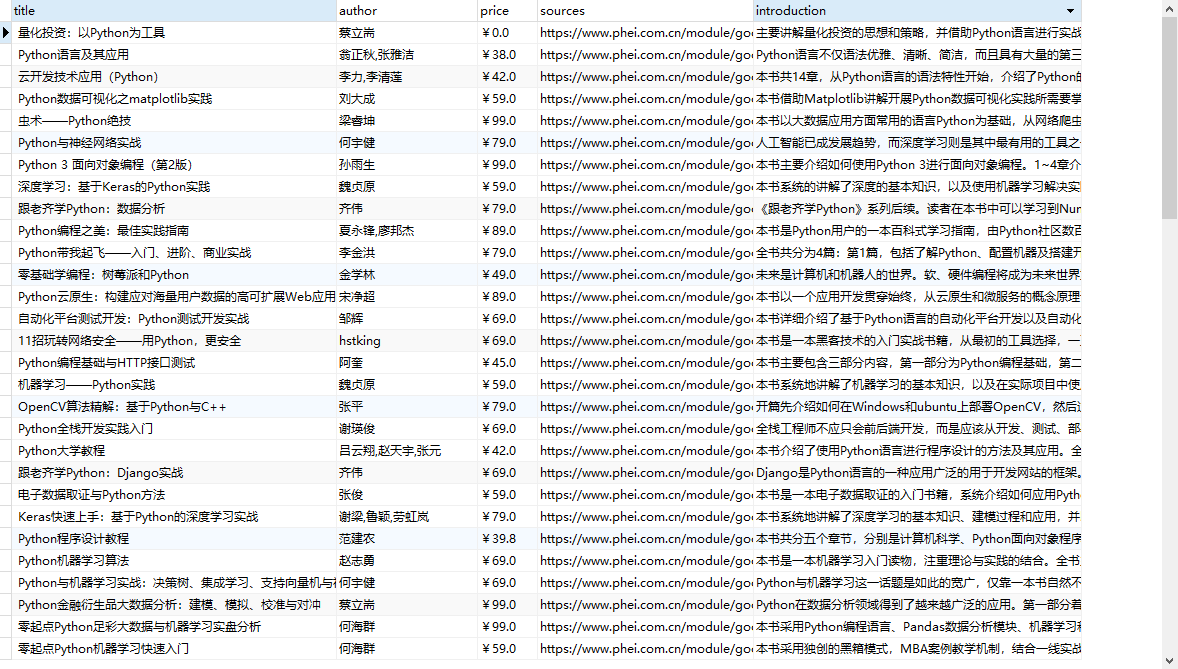
运行前数据库中要建好表(navicat非常好用,而且可以修改密码。。。。),最终book_db中的内容为: