A Multiple Granularity Co-Reasoning Model for Multi-choice Reading Comprehension
Abstract:
针对多选式阅读理解任务,我们提出了一个多粒度推理性模型,该模型基于段落、问句和候选答案之间的交互信息来选出正确答案。首先,我们引入了一个多粒度文本匹配模块以实现段落与问句和每个候选答案间的交互。我们利用从多语义空间中提取的信息去构造文本序列之间更加丰富的匹配特征。有了该模块的帮助,我们就能更好地对段落与问句和候选答案进行匹配以聚合相关信息。此外,我们利用多语句推理性模块实现了跨语句的句子推理。另外,我们使用多个不同卷积核的一维卷积网络和自注意循环神经网络对句子关系进行了建模。这个模块可以更好地聚合句子级证据,从而完成最终的判定。RACE数据集上的实验结果证明我们的模型在单模型中实现了最先进的性能。
- INTRODUCTION
机器阅读理解是一项极具挑战的任务,它致力于使得计算机可以像人一样理解自然语言。具体来说,它要求AI代理可以根据给定的段落去回答问题。随着一些大规模数据集的出现和深度学习的快速发展,机器阅读理解领域的研究已实现巨大的进步。目前研究者可以以端到端的方式训练基于深度学习的机器阅读系统,而在一些特征数据集上,有些研究的结果已接近人类水平。
机器阅读理解数据集基本上可以分为三类:填空式(CNN/Daily Mail),抽取式(SQuAD)和考试数据集(RACE and MCTest),考试数据集通常以多选选择题的形式给出。在本文中,我们主要研究多选式阅读理解任务,它的目标是基于段落、问句和候选答案的交互选出正确答案。与另外两种任务相比,多选式阅读理解需要更高水平的推理和理解能力,这是因为在这种任务中,候选答案并不是在原文中直接提取的,而是由人工生成的。例如,在SQuAD数据集中,大约70%的问题的答案可以通过词或短语的匹配直接找到,只有20%的问题需要深度推理。而RACE中有一半的问题涉及了单语句推理和多语句推理。为了更好地完成这个任务,我们需要对句子级推理投入更多的关注,以得到原文中跨多语句的信息和证据。
先前的大多数研究都将多选式阅读理解视作词级文本序列匹配问题。首先,通过一个编码器对段落、问句和选项分别进行编码。随后计算得到段落与问句的词级注意力矩阵,并得到问句感知的上下文表示。最后通过计算上下文表示与每个选项的相似度来选出正确答案。然而,这种方法句子推理能力。这个匹配过程是在词级上进行的,它在词的匹配问题中表现不错,但对于答案的线索在原文中相距较远的部分时,该方法就不能捕获句子的内部信息了。而另一方面,这些方法没有顾及不同句子间的逻辑信息。对于涉及到多语句推理的问题,答案的线索可能不在单条语句中,而是分散在多条语句中,因此句子级的推理对于捕获多语句间的关系和交互就是必需的。
为解决上述问题,针对文本序列的匹配和推理,我们提出了多粒度推理性模型。先前方法是仅基于一种文本表示的简单的词级匹配机制实现的,而我们是构造了多粒度文本匹配机制,在多语义空间中对段落、问句和答案进行匹配。具体来说,给定段落、问句的编码表示,我们先用一系列具有不同尺寸卷积核的1D-CNN在多个粒度上去捕获每个序列的局部信息。在这之后,每个序列都可被表示为多种表示向量。然后通过计算不同语义空间中相应表示对的相似度来建立多个匹配矩阵。这是受人类阅读策略的启发,我们人类在对序列进行比较时,不会仅对比序列中的词。相反,我们会考虑句子中多个词和短语的意义以便更好地理解这些待比较的文本。

至于多语句推理,[A co-matching model for multi-choice reading comprehension] 利用分层LSTM捕获句子级信息。[An option gate module for sentence inference on machine reading comprehension]使用了一个选项门模块控制了段落对于每个选项的证据信息。然而,这些方法缺少跨多语句推理的能力,因为它们没有考虑到某些句子的局部关系。当我们人类做阅读理解任务时,如果我们发现一个句子与给定的问题和一些选项高度相关,我们趋向于关注该句子前面和后边的少部分句子,并对它们之间的逻辑关系有更多的关注。表1中的样例证明了这个策略。根据这个问题,我们可以在文中找到很多与该问题相关的句子:“These strange men are dangerous for my kids.”。然而,为了选出正确答案C,我们必须查看这个句子的前边和后边的内容,并思考它们之间的逻辑关系。受该策略的启发,我们使用不同大小卷积核的CNN去捕获多语句间的关系,聚合句子级信息以做出最后的选择。与RNN试图提取一篇文章的整体信息不同,CNN能够对一些区域中句子的局部信息进行建模,并使得模型对于句子的推理能更好。
最后,我们工作的贡献如下:
(1) 我们提出了多粒度匹配机制,用于文本序列的匹配和对齐。与词与词的注意力相比,我们的方法可以在多语义表示空间中捕获更加丰富的交互信息。
(2) 我们利用多语句推理模块,基于段落信息的重构表示,去捕获多语句的句子级局部特征。
本文的剩余部分组织如下。第二部分介绍了多选式阅读理解和文本匹配机制的相关工作。第三部分描述了我们模型的整体结构。第四部分总结了我们模型的训练细节和主要结果。
II. RELATED WORK
A. 多选阅读理解
多选式阅读理解是一项通用性任务,它用于验证人类阅读和理解的能力。与填空式阅读理解和抽取式阅读理解相比,多选式阅读理解具有更多的挑战,这是因为正确答案没有被限制在文中的连续文本中。另外,它要求模型具有更多的句子推理和总结能力,这是自然语言处理和自然语言理解中的一项长期问题。MCTest是早期出版的具有高质量问题和答案的多选式阅读理解数据集,它由人类设计并由众包完成的。然而,对于深度神经网络的训练来说,这个数据集太小了。
RACE是近期发表的大规模数据集,它是在中国初中的高中的英语阅读理解考试中收集的。与MCTest相比,RACE更加复杂并且要求更多的跨多语句推理和推断。[1]公布了两个深度学习模型作为基准模型:Stanford Attentive Reader (SAR) and Gated-Attention Readers (GA) 。这两个模型都通过注意力机制建立了问题感知的篇章表示,再通过bilinear注意力层计算候选答案和篇章表示的相似度来确定最终的答案。考虑到这两个模型没有利用篇章和选项建的交互,[8]提出了在三者之间两两进行分层交互的方法,利用选项去修正选项表示。[10]利用动态多匹配策略去融合篇章、问题和选项为注意力向量,并设计了多步推理用于答案选择。[8]利用协同匹配策略使得篇章同时对问题和选项进行匹配,引入分层聚合组件以捕获篇章的句子结构。
B. 序列匹配和对齐机制
序列匹配和对齐机制是多选式阅读理解的核心步骤,它是对给定序列对进行交互建模。事实上,这些机制已被广泛用于NLP任务,例如自然语言理解、复述识别和答案选择。大多数序列匹配模型都是基于词级的注意力机制的。比较典型的是,两个序列被CNN或RNN编码。然后词级注意力被用于匹配两个序列中每个状态的表示。最终我们可以通过软对齐机制得到重构的句子对编码表示。[11]提出了一个比较-聚合结构来比较两个序列的相似度,并聚合匹配特征用于最终的判断。[12]使用一个BiLSTM去编码序列,用另一个BiLSTM去聚合匹配信息。这些方法都是使用两个序列的一种表示去完成匹配过程。[13]引入了协栈残差亲和网络去匹配序列对,它在四类匹配任务上均实现了最先进的性能。这个方法基于编码表示计算匹配得分,这个编码表示是由多个堆叠式递归编码器编码得到的,它包含更广泛的匹配信息。我们的多粒度匹配机制就是受这项工作的启发。但我们并不是堆叠RNN去提取分层特征,相反,我们使用多个不同尺寸卷积核的CNN去提取局部特征,它能在多个语义空间中衡量序列对的相似度。
III. MULTI-GRANULARITY CO-REASONING MODEL
在本节中,我们描述了我们模型的整体结构。我们的模型包含四个主要模块:上下文编码模块,多粒度文本序列匹配模块,多语句协同推理模块和答案选择模块,如图1所示。在多语句协同推理模块中,我们采用自注意力BiGRU和1D-CNN来聚合句子级信息。为了简化说明,我们假设我们模型的输入是三元对(文章、问句和选项),它被表示为{P,Q,O}。它的目标是基于三者的交互在选项中选出正确答案。
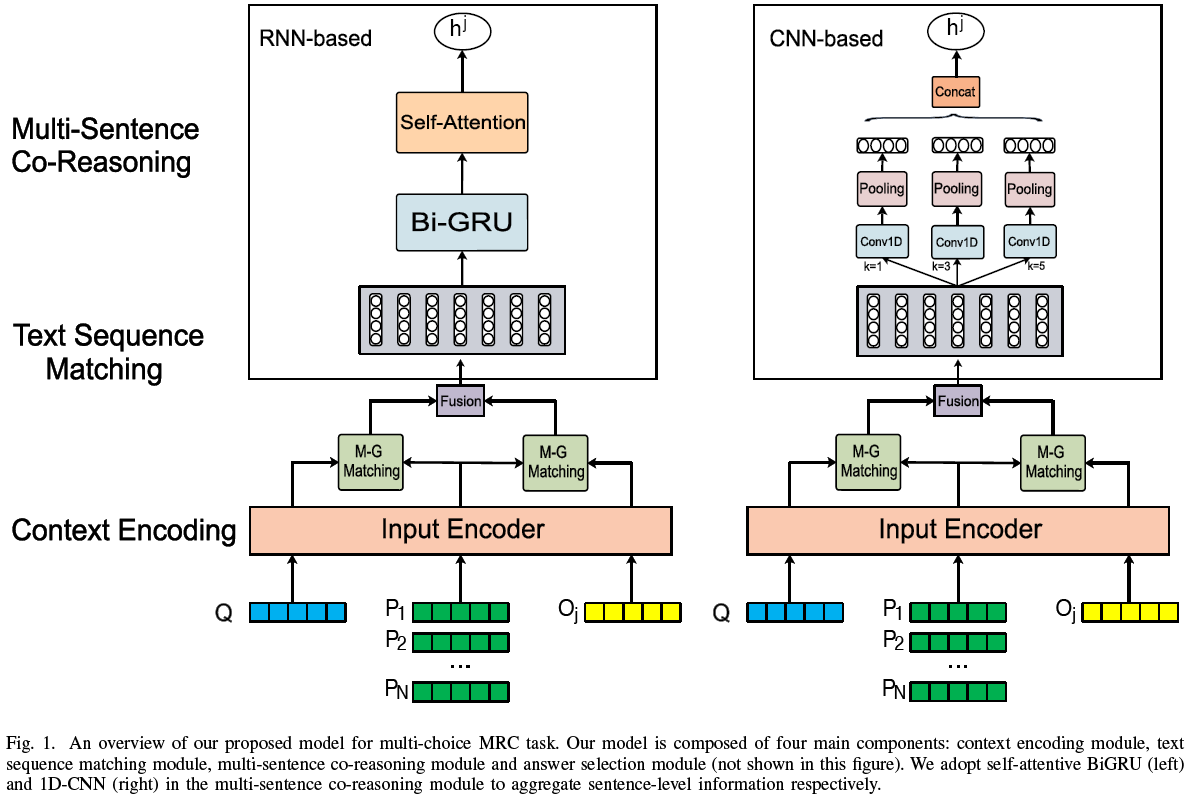
A. 上下文编码层
给定段落、问题和选项,我们先将段落划分为句子并将输入表示为{Q,Pi,Oj},这里的Pi表示文章中的第i个句子,i∈[1,2,…,N],N是文章中的句子数量;Oj表示选项中的第j个选项,j∈[1,2,3,4]。然后我们通过预训练嵌入模型将序列中的每个词转化为d维向量。在这之后,我们就能得到输入三元组的嵌入表示{Qemb,Piemb,Ojemb}。接着,我们将这些词嵌入送入BIGRU中进行处理,从而获得每个序列中相邻词的上下文编码:

这里的u是嵌入表示经BiGRU处理后的编码表示。
B. 多粒度文本序列匹配模块
该模块负责捕获多个语义空间上两个编码序列之间的深层交互。如图2所示,我们以Pi和Q的匹配过程为例来对该模块进行介绍。为简便起见,我们删除Pi的下标i。给定上下文表示uP和uQ,我们对其应用一系列一层的具有多种预定义大小卷积核的1D-CNN去提取每个上下文表示的局部特征。然后我们获得了多种语义空间下的一系列新的特征表示。

通常,为了使得新表示的维度与相应上下文表示的维度相等,我们使用0填充并设置每个一维CNN的输入和输出通道使其相等。对于每个卷积核,我们有
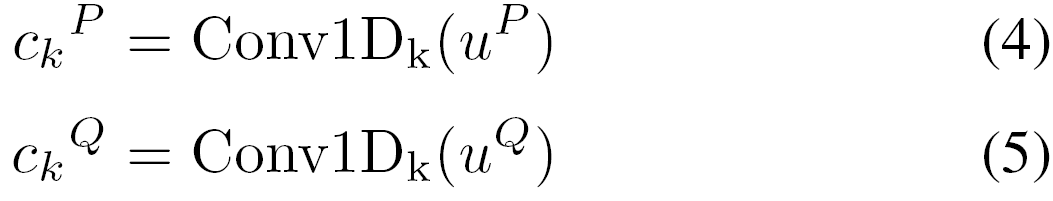
这里的ck是卷积核大小k的CNN提取的局部信息表示。然后我们通过软注意力机制计算相似矩阵:
![]()
这里的Sk表示卷积核大小为k的软注意力得分矩阵,它里面的每个元素表示ckQ的第i个隐状态和ckP的第j个隐状态的相关性得分。Wp是待训练参数。受[13]启发,为确定两个序列在哪个语义神经空间上具有最高匹配分数,我们应用最大池化层在每个软排列矩阵中选择信息量最大的匹配分数,并获得最终的亲和度矩阵:
![]()
在这之后,我们用这个矩阵来优化文章的表示:
![]()
接下来,受多项工作中的匹配策略启发,我们通过下述公式聚合原始的上下文表示uP和uQ:
![]()
Wc和bc是待训练参数。受协同匹配模型的启发,为了利用文章与每个选项之间的交互信息,我们也将篇章和每个选项进行匹配。经此步骤,我们可以得到文中每个句子的最终优化表示,该表示是基于与问句和选项交互的,分别将其记为vQ和vO。
C. 多语句协同推理模块
该模块的作用是将问题感知的文章表示和选项感知的文章信息进行融合,将文中跨语句信息和证据聚合起来。给定输入元组{Q,P,Oj},我们通过文本序列匹配模块可以得到两个优化表示。然后完整的文章就可以表示为{viQ}i=1N和{viOj}i=1N,这两种表示分别基于文章与问题和第j个候选答案各自的交互。首先,我们用与上一小节中一样的聚合策略来融合这两种匹配结果:
![]() 为得到句子表示的丰富聚合信息,我们对上面的ci使用了最大池化和平均池化,并对两种池化结果进行联接:
为得到句子表示的丰富聚合信息,我们对上面的ci使用了最大池化和平均池化,并对两种池化结果进行联接:
![]() 我们用了两种多语句协同推理方法,以便捕获和聚合句子向量的高层信息。
我们用了两种多语句协同推理方法,以便捕获和聚合句子向量的高层信息。
a) 基于自注意力RNN的句子推理:我们使用BiGRU捕获文章中的长距离依赖:
![]() 我们并没有使用池化操作来聚合高层信息,而是使用自注意力机制提取文章中的语义信息:
我们并没有使用池化操作来聚合高层信息,而是使用自注意力机制提取文章中的语义信息:
![]() aj表示注意力向量,Ws1和Ws2是权重矩阵。最终,我们根据注意力向量将sj中的隐状态进行加和:
aj表示注意力向量,Ws1和Ws2是权重矩阵。最终,我们根据注意力向量将sj中的隐状态进行加和:
![]()
hj是基于三者交互的最终输出向量。
b) 基于CNN的句子推理:为了捕获文中相关句子的局部信息,我们利用一系列卷积核大小不同的1-D CNN和最大池化去提取句子级文章表示的局部特征:
![]()
Hj表示卷积核大小为k的句子级聚合文章表示,k∈[1,3,5]。具有不同大小卷积核的CNN可以对不同范围的句子间关系进行建模。之后,联接所有的hkj以得到最终的文章表示:
![]()
D. 答案选择模块
对于每个候选答案Oj,我们都将其对应的最终输出向量送入全连接层,以获得该选项的匹配分数:
![]() WP是待训练参数。接着一个softmax层被用于获得该选项是正确答案的概率:
WP是待训练参数。接着一个softmax层被用于获得该选项是正确答案的概率:
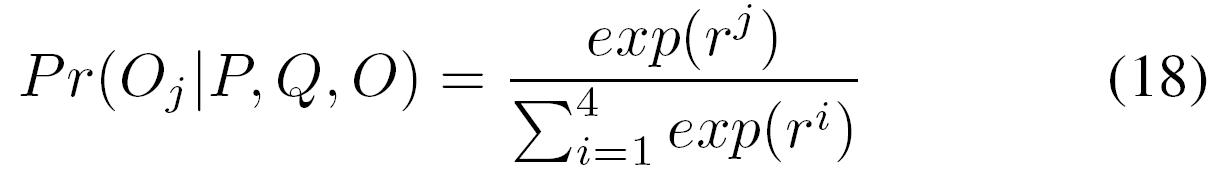
该模型通过反向传播最小化负似然损失函数进行训练。
IV. EXPERIMENT
在本节中,我们首先介绍了用于训练和验证我们模型性能的数据集。然后简单介绍了多选式阅读理解任务的现有基准方法和最先进的模型。最终,我们在上述数据集上进行了实验,以验证我们模型的性能。实验结果表明我们的模型超过了所有的基准方法。另外,我们还进行了消融研究,以便分析我们模型中每个组件的贡献。
A. 数据集
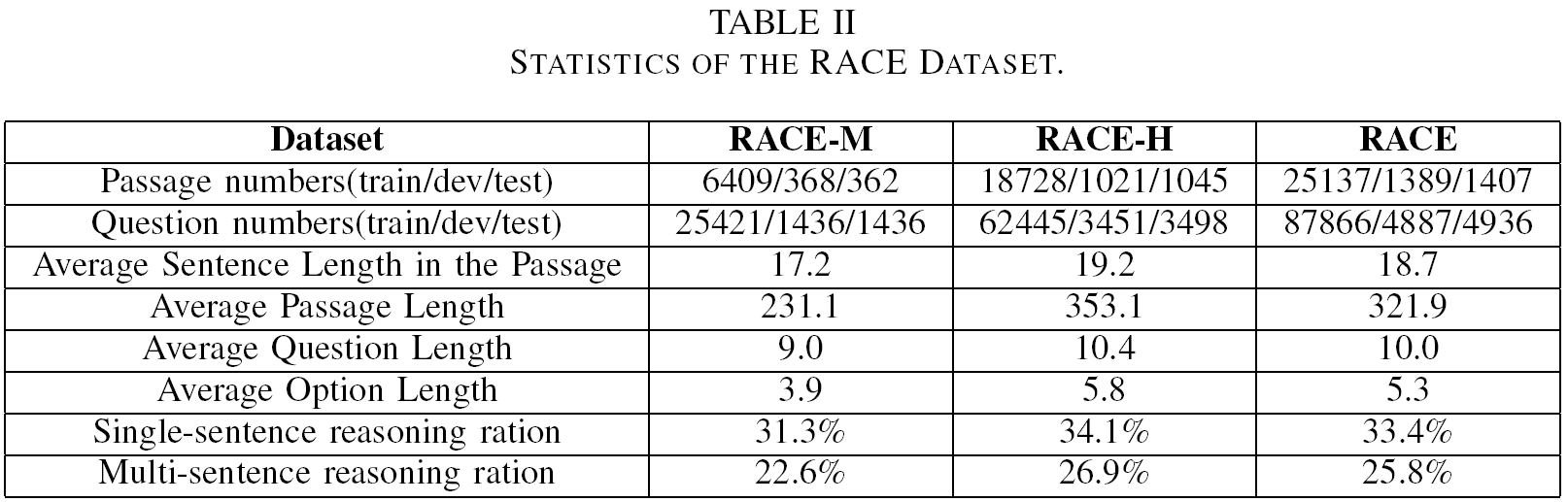
我们主要使用RACE来训练和验证我们模型的性能。RACE是一个流行的多选式阅读理解数据集,它来自中国英语阅读理解考试。每篇文章斗鱼几个问题相关,每个问题只有一个正确答案。这个数据集包含两部分:高中部分和初中部分,表示为RACE-H和RACE-M。这两者的主要区别是RACE-H中的问题需要更多的句子推理和推断,因此它比RACE-M更复杂。该数据集的统计数据如表2所示。
B. 实验设置
我们首先将文章划分为句子。每篇文章最多保留50个句子,每个句子最长不超过50个词。问题和选项中的句子最长不超过25个词。我们用NLTK完成word stemming和lemmatization。使用在维基百科上预训练的300维Glove词嵌入来初始化嵌入矩阵。词表大小设置为50000。未知词用0进行填充。为了避免过拟合,我们为每层GRU设置dropout为0.25,为每个线性层设置dropout为0.5。此外,我们将GRU的神经元数量设为128。在文本序列匹配模块,我们设置卷积核大小为[1,3,5]。在基于CNN的句子推理模块中,其卷积核大小也被设置为[1,3,5]。该模块中的最大池化操作使用按行池化进行。我们的模型采用Adam为优化器,学习率设为0.001,batch size设为32。为了公平比较,我们不使用外部上下文嵌入,例如ELMo,GPT等。
C. 对比方法
我们与以下基准方法和最新的方法对比我们的模型性能。
Stanford AR。该方法使用软注意力机制获得问题感知的文章表示,并用bilinear注意力来计算文章表示和每个选项的匹配得分。
GA Readers。该方法使用门控机制去迭代提取和优化基于与问题交互的文章表示。
ElimiNet。该方法通过一个elimination模块来去掉不相关的选项,然后文本表示通过与未去掉的选项进行迭代交互进行优化。
Hierarchical Attention Flow。文章、问题和选项的交互被分层计算,选项修正被用于优化选项表示。
Dynamic Fusion Network。该方法使用动态多匹配策略去融合文章、问题和选项,将其整合为注意力向量,再采用多步推理去选择正确答案。
Hierarchical Co-Matching。该文章联合匹配问题和选项以获得文章的协同匹配状态,随后使用分层LSTM去聚合句子级信息。
BiAttention + Simple MRU。该方法采用多范围门的句子编码器对文章、问题和选项进行双向注意处理。
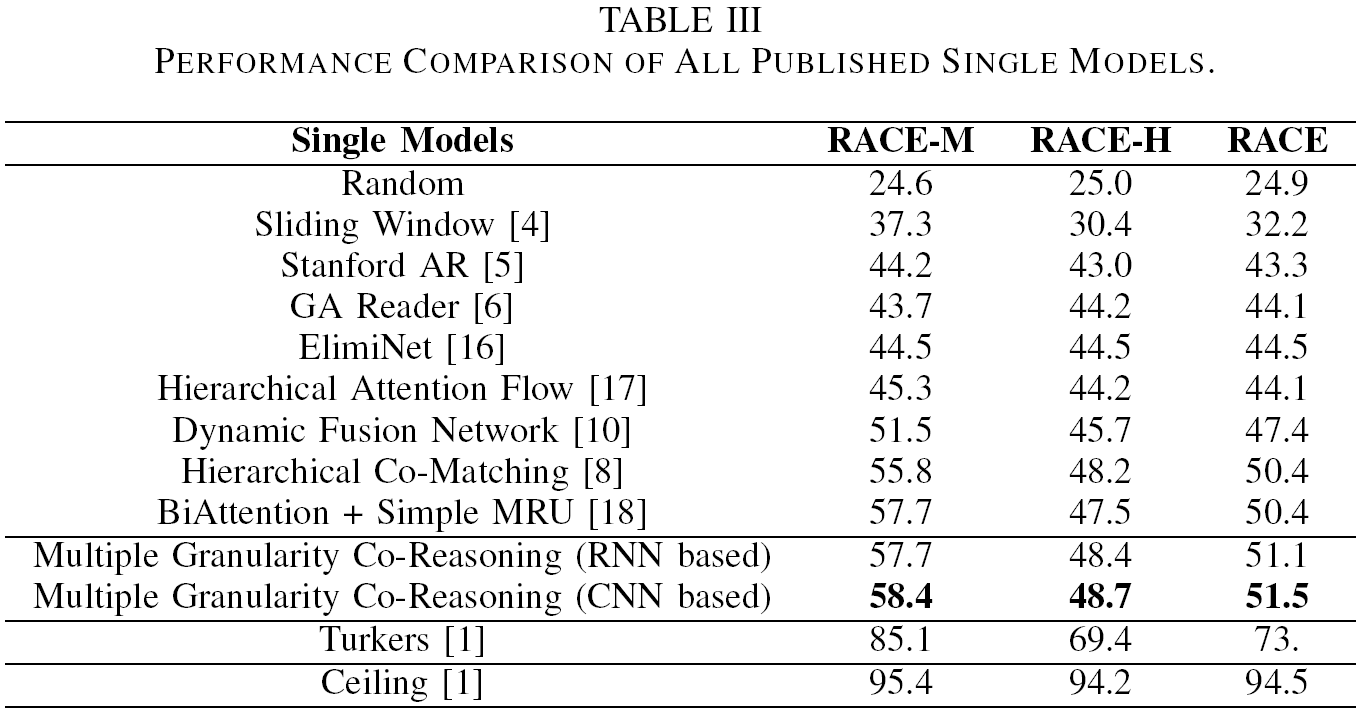
D. 主要结果
在RACE数据集中,通常使用accuracy来验证模型性能。我们对参数进行随机初始化,并运行了五次,最后报道的是平均结果。我们模型和其他模型的结果被展示在表3中。我们报道的对比方法的结果均来自它们各自的原始文献。我们这里仅比较单模型的性能。正如表3所示,在RACE-M,RACE-H和RACE上,我们的模型比所有的单模型性能都要更有效。在RACE-H数据集中,模型被要求具有更高的句子推理能力,而我们的模型比Hierarchical Co-Matching and BiAttention with simple MRU encoder分别高出了0.5%和1.2%。我们也发现使用基于CNN的句子推理模块要逼使用基于RNN的句子推理模块的效果稍好一点。这表示CNN可以更好地捕获跨语句的局部特征,这有助于聚合句子级证据,并作出更好地判断。
E. 消融研究
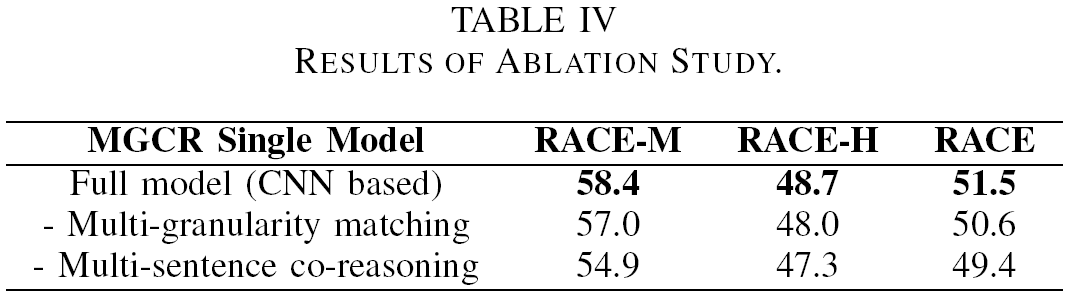
我们构造了消融研究以判定我们模型中的每个组件的贡献,其结果展示在表4中。我们主要集中研究了两个模块的影响:多粒度匹配模块和多语句协同推理模块。首先,我们去掉了多粒度匹配模块,直接通过词级注意力机制来计算优化的文章表示。我们发现结果下降了0.9%。然后我们去掉了多语句协同推理模块,将文章视为一个整体而不是将其划分为多个句子。之后再文本序列匹配模块中,我们仅联接两个优化的文章表示,并使用池化操作去得到最终输出向量。我们发现结果下降了2.1%,这表示我们的多语句协同推理模块对我们的模型的贡献更大。
V. CONCLUSION
在本文中,我们介绍了一个多粒度协同推理模型去解决多选式阅读理解任务中的句子匹配和推理问题。我们针对文本序列匹配文题提出了多粒度序列匹配模块。该模块可以在不同的语义空间中匹配两个文本序列。通过这种方式,我们可以更好地对文章、问题和选项进行匹配并聚合相关信息。另外,针对跨语句的句子推理问题,我们设计了句子级协同推理模块。我们使用多个具有不同大小卷积核1D CNN和自注意力RNN对多个优化的句子向量关系进行建模。实验结果显示我们的模型优于RACE上所有的单模型方法。在未来,我们将聚焦于多语句推理,并尝试提高深度神经网络的句子推理能力。