程序代码及图解析:
#include <iostream>
#include "book.h"
__global__ void add( int a, int b, int *c ) {
*c = a + b;
}
int main( void ) {
int c;
int *dev_c;
HANDLE_ERROR( cudaMalloc( (void**)&dev_c, sizeof(int) ) );
add<<<1,1>>>( 2, 7, dev_c );
HANDLE_ERROR( cudaMemcpy( &c,
dev_c,
sizeof(int),
cudaMemcpyDeviceToHost ) );
printf( "2 + 7 = %d
", c );
cudaFree( dev_c );
return 0;
}
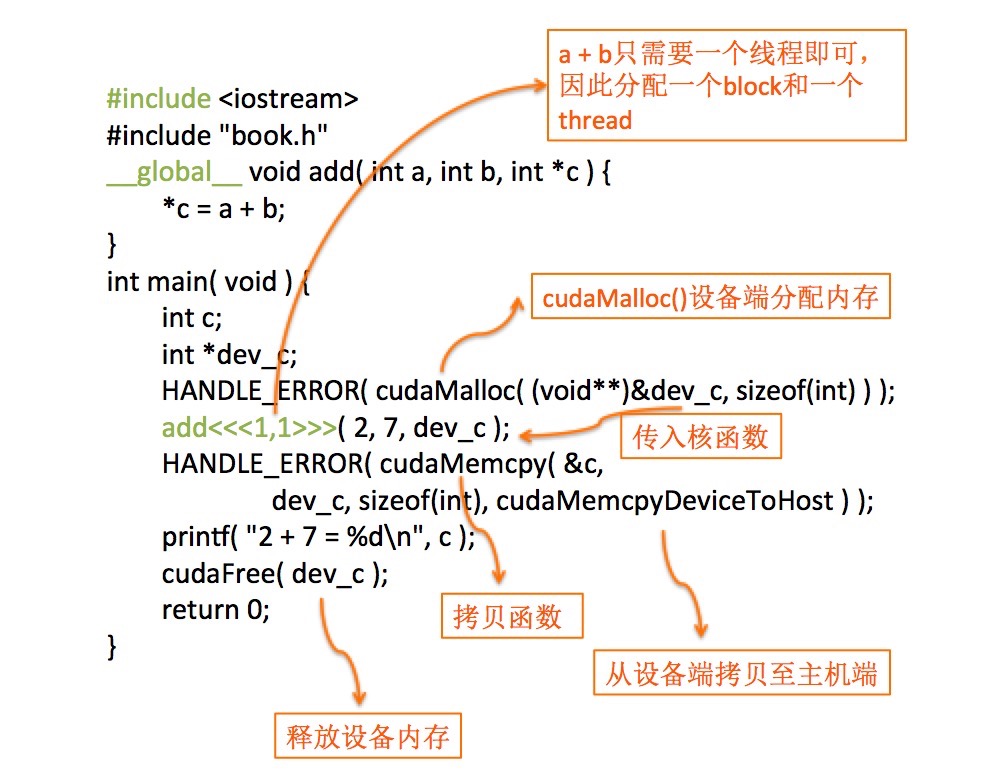
函数原型:__host__cudaError_t cudaMemcpy (void *dst, const void *src, size_t count, cudaMemcpyKind kind)
作用:在设备端和主机端拷贝数据。
参数:dst 目的地址 src 源地址 count 拷贝字节大小kind 传输的类型
返回值:
cudaSuccess, cudaErrorInvalidValue, cudaErrorInvalidDevicePointer, cudaErrorInvalidMemcpyDirection
说明:
从源地址拷贝设定数量的字节数至目的地址,kind类型有四种,分别为:
cudaMemcpyHostToHost, cudaMemcpyHostToDevice, cudaMemcpyDeviceToHost, cudaMemcpyDeviceToDevice,
通过指定方向进行拷贝。存储器区域不可重叠。如若产生未定义拷贝方向的行为,dst和src将不匹配。
正文
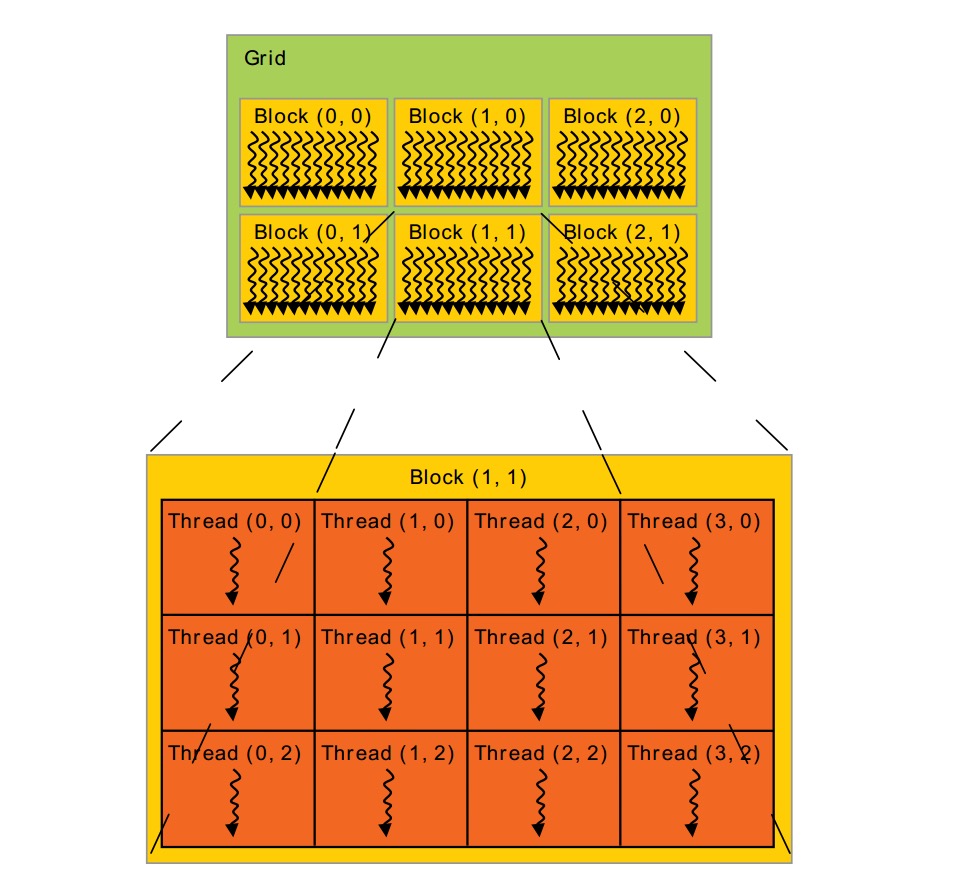
前面的图是最简单的一个CUDA程序,它引出了Grid Block Thread概念。很多threads组成1维,2维or3维的thread block. 为了标记thread在block中的位置(index),我们可以用上面讲的threadIdx。threadIdx是一个维度<=3的vector。还可以用thread index(一个标量)表示这个位置。
thread的index与threadIdx的关系:
| Thread index | |
| 1 | T |
| 2 | T.x + T.y * Dx |
| 3 | T.x+T.y*Dx+z*Dx*Dy |
其中T表示变量threadIdx。(Dx, Dy, Dz)为block的size(每一维有多少threads)。
因为一个block内的所有threads会在同一处理器内核上共享内存资源,所以block内有多少threads是有限制的。目前GPU限制每个 block最多有1024个threads。但是一个kernel可以在多个相同shape的block上执行,效果等效于在一个有N*#thread per block个thread的block上执行。
Block又被组织成grid。同样,grid中block也可以被组织成1维,2维or3维。一个grid中的block数量由系统中处理器个数或待处理的数据量决定。(来自这里)
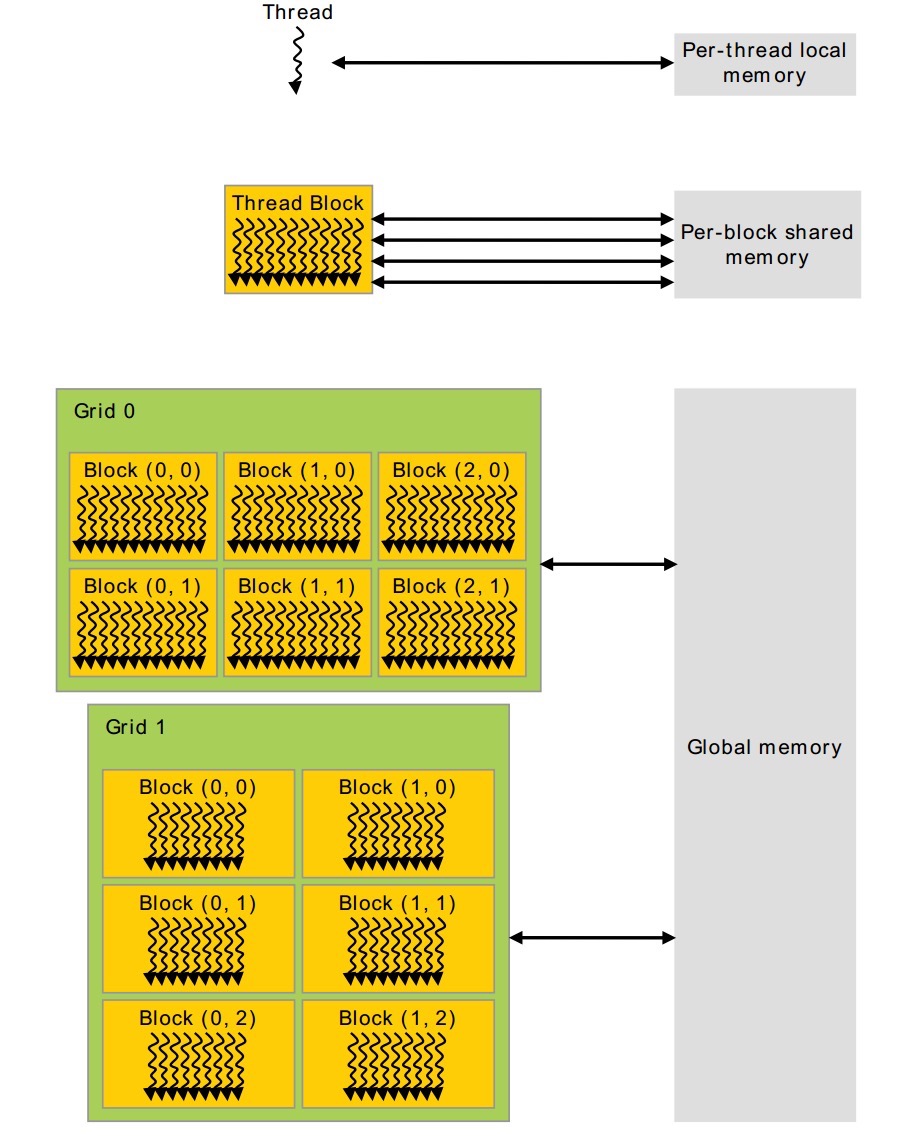
下图中描述了Thread、Block、Grid内存的访问机制。
每个thread有自己的local-memory。每一个block有自己的共享内存、grid和grid之间可以同时访问全局内存。这里要注意:block和block之间不能访问同一个共享内存,他们只能访问自己的共享内存。
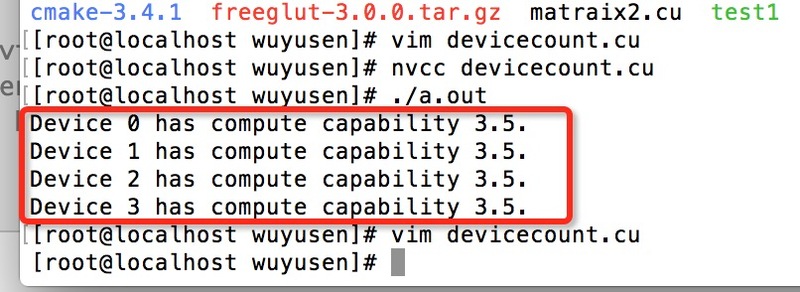
cudaGetDeviceCount( &count )查询服务器的CUDA信息.
#include <stdio.h>
#include <cuda_runtime.h>
int main()
{
int deviceCount;
cudaGetDeviceCount(&deviceCount);
int device;
for(device = 0; device < deviceCount; ++device)
{
cudaDeviceProp deviceProp;
cudaGetDeviceProperties(&deviceProp,device);
printf("Device %d has compute capability %d.%d.
",device,deviceProp.major,deviceProp.minor);
}
}
结果:
struct cudaDeviceProp {
char name[256]; //识别设备的ASCII字符串(例如,“GeForce GTX 280”)
size_t totalGlobalMem; //全局内存大小
size_t sharedMemPerBlock; //每个block内共享内存的大小
int regsPerBlock; //每个block32位寄存器的个数
int warpSize; // warp大小
size_t memPitch; //内存中允许的最大间距字节数
int maxThreadsPerBlock; //每个Block中最大的线程数是多少
int maxThreadsDim[3]; // 一个块中每个维度的最大线程数
int maxGridSize[3]; //一个网格的每个维度的块数量
size_t totalConstMem; //可用恒定内存量
int major; //该设备计算能力的主要修订版号
int minor; //设备计算能力的小修订版本号
int clockRate; //时钟速率
size_t textureAlignment; //该设备对纹理对齐的要求
int deviceOverlap; //一个布尔值,表示该装置是否能够同时进行cudamemcpy()和内核执行
int multiProcessorCount; //设备上的处理器的数量
int kernelExecTimeoutEnabled; //一个布尔值,该值表示在该设备上执行的内核是否有运行时的限制
int integrated; //返回一个布尔值,表示设备是否是一个集成的GPU(即部分的芯片组、没有独立显卡等)
int canMapHostMemory; //表示设备是否可以映射到CUDA设备主机内存地址空间的布尔值
int computeMode; //一个值,该值表示该设备的计算模式:默认值,专有的,或禁止的
int maxTexture1D; //一维纹理内存最大值
int maxTexture2D[2]; //二维纹理内存最大值
int maxTexture3D[3]; //三维纹理内存最大值
int maxTexture2DArray[3]; //二维纹理阵列支持的最大尺寸
int concurrentKernels; //一个布尔值,该值表示该设备是否支持在同一上下文中同时执行多个内核
}
矩阵相乘也非常简单,难在如何在这个基础上提高速率。比如:引入sharememory。
代码:
#include <stdio.h>
#include <cuda_runtime.h>
#include <device_launch_parameters.h>
#include <time.h>
#include <stdlib.h>
__global__ void MatrixMuiOnDevice(int *M,int *N, int *P, int width)
{
int x = threadIdx.x;
int y = threadIdx.y; //获取该线程的位置
float Pervalue = 0;
for (int i = 0; i < width; i++)
{
float Mdlement = M[y * width + i];
float Ndlement = N[width * i + x];
Pervalue += Mdlement * Ndlement;
}
P[y * width + x] = Pervalue;
}
int main()
{
int a[30][30],b[30][30],c[30][30];
int *M, *N, *P;
int width = 30;
int NUM = 900;
dim3 dimBlock(30,30);
cudaEvent_t start,stop;
float elapsedTime;
cudaEventCreate(&start);
cudaEventCreate(&stop);
cudaMalloc((void**)&M, 900*sizeof(int));
cudaMalloc((void**)&N, 900*sizeof(int));
cudaMalloc((void**)&P, 900*sizeof(int));
//初始化
for(int i = 0; i < 30; i++)
for(int j = 0; j < 30; j++)
{
a[i][j] = 2;
b[i][j] = 3;
}
cudaMemcpy(M,a,NUM*sizeof(int),cudaMemcpyHostToDevice);
cudaMemcpy(N,b,NUM*sizeof(int),cudaMemcpyHostToDevice);
cudaMemcpy(c,P,NUM*sizeof(int),cudaMemcpyDeviceToHost);
cudaEventRecord(start,0);
MatrixMuiOnDevice<<<1,dimBlock>>>(M,N,P,width);
cudaThreadSynchronize();
cudaEventRecord(stop,0);
cudaEventSynchronize(stop);
cudaEventElapsedTime(&elapsedTime,start,stop);
printf("%f
",elapsedTime);
for(int i = 0; i < 30; i++)
for(int j = 0; j < 30; j++)
{
printf("%d
",c[i][j]);
}
cudaFree(M);
cudaFree(N);
cudaFree(P);
return 0;
}
share memory 改进。加入同步机制 __syncthreads(),即 等待之前的所有线程执行完毕后再接下去执行。
#include <stdio.h>
#include <cuda_runtime.h>
#include <device_launch_parameters.h>
#include <time.h>
#include <stdlib.h>
#define TILE_WIDTH 25
__global__ void MatrixMuiOnDevice(int *M,int *N, int *P, int width)
{
__shared__ float Mds[TILE_WIDTH][TILE_WIDTH];
__shared__ float Nds[TILE_WIDTH][TILE_WIDTH];
int bx = blockIdx.x;
int by = blockIdx.y;
int tx = threadIdx.x;
int ty = threadIdx.y;
int Col = bx * TILE_WIDTH + tx;
int Row = by * TILE_WIDTH + ty; //获取该线程的位置
int Pervalue = 0;
for (int i = 0; i < width / TILE_WIDTH; i++)
{
Mds[ty][tx] = Md[Row * width+(i * TILE_WIDTH + tx)];
Nds[ty][tx] = Nd[Col + (i * TILE_WIDTH + ty) * width];
__syncthreads();
for (int k = 0; k < width / TILE_WIDTH; k++)
Pervalue += Mds[ty][k] * Nds[k][tx];
__syncthreads();
}
P[Row * width + Col] = Pervalue;
}
int main()
{
int WID = 100;
int a[WID][WID],b[WID][WID],c[WID][WID];
int *M, *N, *P;
int width = WID / 4 ;;
int NUM = WID*WID;
dim3 dimGrid(WID/width,WID/width);
dim3 dimBlock(width,width);
cudaEvent_t start,stop;
float elapsedTime;
cudaEventCreate(&start);
cudaEventCreate(&stop);
cudaMalloc((void**)&M, NUM*sizeof(int));
cudaMalloc((void**)&N, NUM*sizeof(int));
cudaMalloc((void**)&P, NUM*sizeof(int));
//初始化
for(int i = 0; i < 100; i++)
for(int j = 0; j < 100; j++)
{
a[i][j] = 2;
b[i][j] = 3;
}
cudaMemcpy(M,a,NUM*sizeof(int),cudaMemcpyHostToDevice);
cudaMemcpy(N,b,NUM*sizeof(int),cudaMemcpyHostToDevice);
cudaMemcpy(c,P,NUM*sizeof(int),cudaMemcpyDeviceToHost);
cudaEventRecord(start,0);
MatrixMuiOnDevice<<<dim,dimBlock>>>(M,N,P,width);
cudaThreadSynchronize();
cudaEventRecord(stop,0);
cudaEventSynchronize(stop);
cudaEventElapsedTime(&elapsedTime,start,stop);
printf("%f
",elapsedTime);
cudaFree(M);
cudaFree(N);
cudaFree(P);
return 0;
}
小结
第一个执行时间:
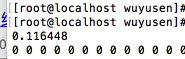
share memory执行时间:

注意,核函数内不是所有线程一起进去执行,这个概念模糊不清。我们需要理解成,所有的线程并行执行核函数里面的程序,即每一个线程都会执行该函数,所有线程执行完,即结束。这个简单的概念,我一开始想了很久。
注:转载请注明出处。