因为有在北京租房的打算,于是上网浏览了一下链家网站的房价,想将他们爬取下来,并保存到本地。
先看链家网的源码。。房价信息 都保存在 ul 下的li 里面

![]()
爬虫结构:
![]() 其中封装了一个数据库处理模块,还有一个user-agent池。。
其中封装了一个数据库处理模块,还有一个user-agent池。。
先看mylianjia.py
# -*- coding: utf-8 -*- import scrapy from ..items import LianjiaItem from scrapy.http import Request from parsel import Selector import requests import os class MylianjiaSpider(scrapy.Spider): name = 'mylianjia' #allowed_domains = ['lianjia.com'] start_urls = ['https://bj.lianjia.com/ershoufang/chaoyang/pg'] def start_requests(self): for i in range(1, 101): #100页的所有信息 url1 = self.start_urls + list(str(i)) #print(url1) url = '' for j in url1: url += j + '' yield Request(url, self.parse) def parse(self, response): print(response.url) ''' response1 = requests.get(response.url, params={'search_text': '粉墨', 'cat': 1001}) if response1.status_code == 200: print(response1.text) dirPath = os.path.join(os.getcwd(), 'data') if not os.path.exists(dirPath): os.makedirs(dirPath) with open(os.path.join(dirPath, 'lianjia.html'), 'w', encoding='utf-8')as fp: fp.write(response1.text) print('网页源码写入完毕') ''' infoall=response.xpath("//div[4]/div[1]/ul/li") #infos = response.xpath('//div[@class="info clear"]') #print(infos) #info1 = infoall.xpath('div/div[1]/a/text()').extract_first() #print(infoall) for info in infoall: item =LianjiaItem() #print(info) info1 = info.xpath('div/div[1]/a/text()').extract_first() info1_url = info.xpath('div/div[1]/a/@href').extract_first() #info2 = info.xpath('div/div[2]/div/text()').extract_first() info2_dizhi = info.xpath('div/div[2]/div/a/text()').extract_first() info2_xiangxi= info.xpath('div/div[2]/div/text()').extract() #info3 = info.xpath('div/div[3]/div/a/text()').extract_first() #info4 = info.xpath('div/div[4]/text()').extract_first() price = info.xpath('div/div[4]/div[2]/div/span/text()').extract_first() perprice = info.xpath('div/div[4]/div[2]/div[2]/span/text()').extract_first() #print(info1,'--',info1_url,'--',info2_dizhi,'--',info2_xiangxi,'--',info4,'--',price,perprice) info2_xiangxi1 = '' for j1 in info2_xiangxi: info2_xiangxi1 += j1 + '' #print(info2_xiangxi1) #化为字符串 item['houseinfo']=info1 item['houseurl']=info1_url item['housedizhi']=info2_dizhi item['housexiangxi']=info2_xiangxi1 item['houseprice']=price item['houseperprice']=perprice yield item
再看items.py
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class LianjiaItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
houseinfo=scrapy.Field()
houseurl=scrapy.Field()
housedizhi=scrapy.Field()
housexiangxi=scrapy.Field()
houseprice=scrapy.Field()
houseperprice=scrapy.Field()
pass
接下来看pipelines.py
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
class LianjiaPipeline(object):
def process_item(self, item, spider):
print('房屋信息:',item['houseinfo'])
print('房屋链接:', item['houseurl'])
print('房屋位置:', item['housedizhi'])
print('房屋详细信息:', item['housexiangxi'])
print('房屋总价:', item['houseprice'],'万')
print('平方米价格:', item['houseperprice'])
print('===='*10)
return item
接下来看csvpipelines.py
import os
print(os.getcwd())
class LianjiaPipeline(object):
def process_item(self, item, spider):
with open('G:pythonAI爬虫大全lianjiadatahouse.txt', 'a+', encoding='utf-8') as fp:
name=str(item['houseinfo'])
dizhi=str(item['housedizhi'])
info=str(item['housexiangxi'])
price=str(item['houseprice'])
perprice=str(item['houseperprice'])
fp.write(name + dizhi + info+ price +perprice+ '
')
fp.flush()
fp.close()
return item
print('写入文件成功')
接下来看 settings.py
# -*- coding: utf-8 -*-
# Scrapy settings for lianjia project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://doc.scrapy.org/en/latest/topics/settings.html
# https://doc.scrapy.org/en/latest/topics/downloader-middleware.html
# https://doc.scrapy.org/en/latest/topics/spider-middleware.html
BOT_NAME = 'lianjia'
SPIDER_MODULES = ['lianjia.spiders']
NEWSPIDER_MODULE = 'lianjia.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'lianjia (+http://www.yourdomain.com)'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
# Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32
# Configure a delay for requests for the same website (default: 0)
# See https://doc.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
DOWNLOAD_DELAY = 0.5
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16
# Disable cookies (enabled by default)
#COOKIES_ENABLED = False
# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False
# Override the default request headers:
#DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
#}
# Enable or disable spider middlewares
# See https://doc.scrapy.org/en/latest/topics/spider-middleware.html
SPIDER_MIDDLEWARES = {
'lianjia.middlewares.LianjiaSpiderMiddleware': 543,
#'scrapy.contrib.downloadermiddleware.useragent.UserAgentMiddleware' : None,
#'lianjia.rotate_useragent.RotateUserAgentMiddleware' :400
}
# Enable or disable downloader middlewares
# See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html
DOWNLOADER_MIDDLEWARES = {
'lianjia.middlewares.LianjiaDownloaderMiddleware': 543,
}
# Enable or disable extensions
# See https://doc.scrapy.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#}
# Configure item pipelines
# See https://doc.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'lianjia.pipelines.LianjiaPipeline': 300,
#'lianjia.iopipelines.LianjiaPipeline': 301,
'lianjia.csvpipelines.LianjiaPipeline':302,
}
# Enable and configure the AutoThrottle extension (disabled by default)
# See https://doc.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False
# Enable and configure HTTP caching (disabled by default)
# See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
HTTPCACHE_ENABLED = True
HTTPCACHE_EXPIRATION_SECS = 0
HTTPCACHE_DIR = 'httpcache'
HTTPCACHE_IGNORE_HTTP_CODES = []
HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
LOG_LEVEL='INFO'
LOG_FILE='lianjia.log'
最后看starthouse.py
from scrapy.cmdline import execute execute(['scrapy', 'crawl', 'mylianjia'])
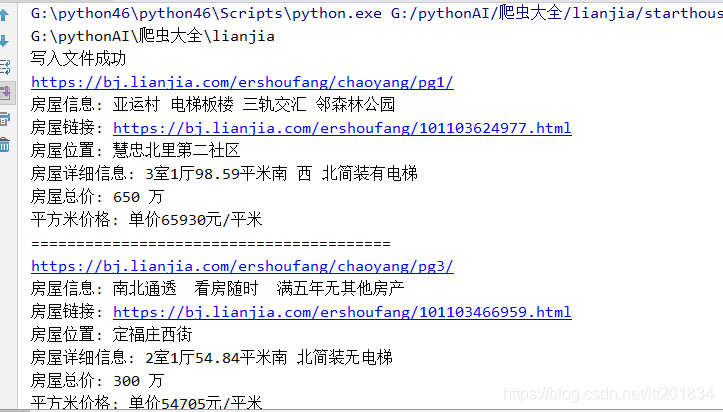
代码运行结果
![]()
保存到本地效果:

![]()
完成,事后可以分析一下房价和每平方米的方剂,,因为是海淀区的,,可以看到 都是好几万一平米,总价也得几百万了 而且是二手房,,,可以看出来 ,在北京买房太难。。。。
源码 tyutltf/lianjia: 爬取链家北京房价并保存txt文档 https://github.com/tyutltf/lianjia