基于scrapy框架的爬影评
爬虫主程序:
import scrapy from ..items import DoubanmovieItem class MoviespiderSpider(scrapy.Spider): name = 'moviespider' allowed_domains = ['douban.com'] start_urls = ['http://movie.douban.com/top250'] def parse(self, response): movie_items=response.xpath('//div[@class="item"]') for item in movie_items: #print(type(item)) movie =DoubanmovieItem() movie['rank']=item.xpath('div[@class="pic"]/em/text()').extract() movie['title']=item.xpath('div[@class="info"]/div[@class="hd"]/a/span[@class="title"][1]/text()').extract() movie['quote'] = item.xpath( 'div[@class="info"]/div[@class="bd"]/p[@class="quote"]/span[@class="inq"][1]/text()').extract() movie['star'] = item.xpath( 'div[@class="info"]/div[@class="bd"]/div[@class="star"]/span/text()').extract() movie['src']=item.xpath( 'div[@class="pic"]/a/img/@src').extract() yield movie pass #取下一页的地址 nextPageURL = response.xpath('//span[@class="next"]/a/@href').extract() #print(nextPageURL) if nextPageURL: url = response.urljoin(nextPageURL[-1]) #print('url', url) # 发送下一页请求并调用parse()函数继续解析 yield scrapy.Request(url, self.parse, dont_filter=False) pass else: print("退出") pass
items 对象
import scrapy class DoubanmovieItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() rank=scrapy.Field() title=scrapy.Field() quote=scrapy.Field() star=scrapy.Field() src=scrapy.Field() pass
pipelines 输出管道
class DoubanmoviePipeline(object): def process_item(self, item, spider): print('电影排名:{0}'.format(item['rank'][0])) print('电影名称:{0}'.format(item['title'][0])) print('电影短评:{0}'.format(item['quote'][0])) print('评价分数:{0}'.format(item['star'][0])) print('评价人数:{0}'.format(item['star'][1]))
print('图片链接:{0}'.format(item['src']))
print('-' * 20)
return item
在控制台输出的结果
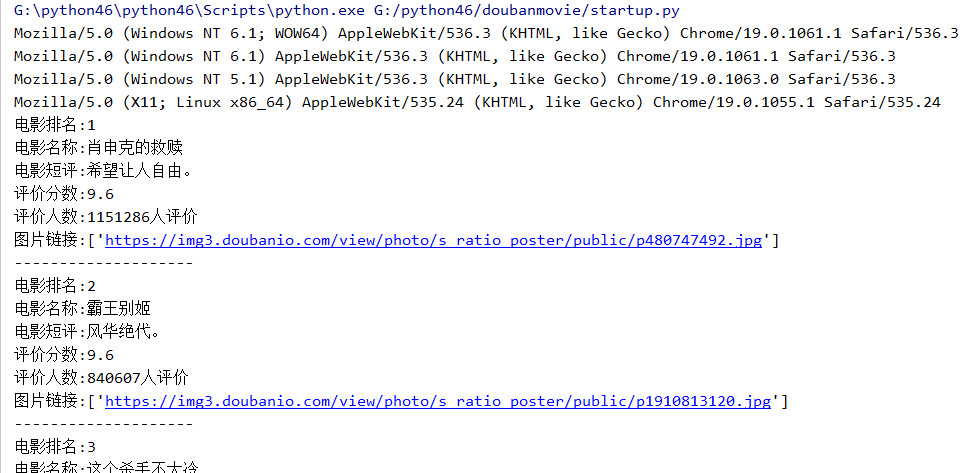
可以通过爬出的图片链接,下载电影的剧照,这就另说了,也可以设置一个插入数据库的管道,将这些数据插入到数据库中