一、线进程若干概念
1.并发:程序,任务,用户
2.多道程序设计:A_IO阻塞----->切换到B_通道----->B_IO阻塞------>切换到C_通道
3.spooling(外部设备联机并行操作):它是Simultaneous Peripheral Operations On-Line的缩写,它是关于慢速字符设备如何与计算机主机交换信息一种技术,通常称为“假脱机技术”。原理就是当一个额外的设备送到内存等待区域时,当操作系统处理完一个事件后,额外设备中的事件可以迅速被操作系统读出,装进空出来的内存区运行。
二、实例导入:
线程:threading.Thread(target=函数名,args=形参名)
import threading from time import ctime, sleep import time def ListenMusic(name): print("Berlin listening to %s. %s" %(name,ctime())) sleep(3) print("end listening %s"%ctime()) def RecordBlog(title): print("Begin recording the %s! %s"%(title,ctime())) sleep(5)
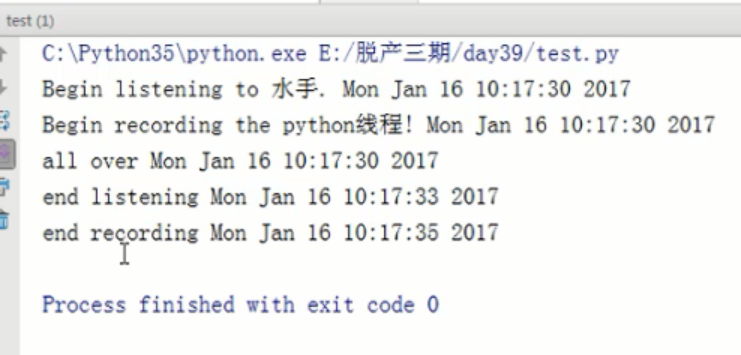
线程和进程若干方法
1.守护线程Setdaemon
t1 = threading.Thread(target=ListenMusic,args=("Battal Call")
t2 = threading.Thread(target=RecordingBlog,args=("python线程"))
threads.append(t1)
threads.append(t2)
if __name__ == "__main__":
t1.setDaemon(True)
t2.setDaemon(True)
for t in threads:
#t1(t2).setDaemon(True) 一定在start之前设置
t.start()
#t.join()
print("all over %s"%ctime())
设置守护线程后,主进程结束,线程结束。
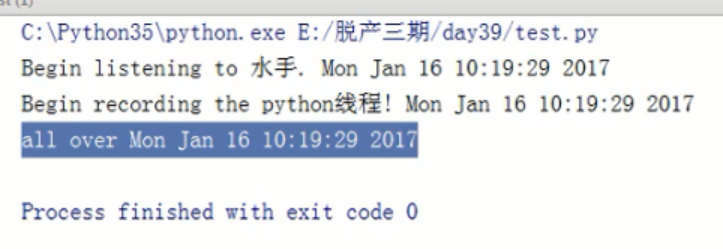
以上实例总结:
#以下是单线程的例子
import threading def sub():
global num
num -= 1
num = 100
l = []
for i range(100):
t = threading.Thread(target=sub) #定义线程
t.start()
l.append(t)
for i range(100):
t.join()
#以下是多线程例子 import threading def ListenMusic(name): xxx def RecordBlog(name): xxx l = [] t1 = threading.Thread(target=ListenMusic,args=("BattleCall")) t2 = threading.Thread(target=RecordBlog,args=("python线程")) l.append(t1) l.append(t2) if __name__ == "__main__": for t in l: t.start() #开启线程 t.join() #开启线程阻塞 print(...)
2.join方法
在子线程完成操作之前,主进程将一直被阻塞,即主程序等待子程序运行,主程序被卡在调用子程序函数处。
3.其他方法

三、并发并行和同步异步
并发与并行
并发A:指系统具有处理多个任务(动作)的能力;
并行B:指系统具有 同时 处理多个任务(动作)的能力。
A与B关系,B∈A
同步与异步
同步:当进程执行到一个IO(等待外部数据)的时候;(等待数据到来)
异步:进程执行无需一个IO数据到来。(不等待数据到来)
四、GIL概念
GIL:全局解释锁,因为有GIL,所以同一时刻,只有一个线程被CPU执行
两种任务类型:IO密集型/计算密集型
对于IO密集型的任务:python的多线程是有意义的(不妨采用多线程+协程)
对于计算密集型的任务:python的多线程不推荐,此时不仅需要消耗GIL切换的时间,同时CPU要消耗大量时间执行计算任务,其中一个计算任务被执行,其余计算任务被搁置(python不适用)
五.同步锁
#框架
#串行
lock.acquire() 执行代码 lock.release() lcok = threading.Lock()
六.队列(用于多线程)
队列引入
import threading, time li = [1,2,3,4,5] def pri(): while li: a = li[-1] print(a) time.sleep(1) li.remove(a) try: li.remove(a) except Exception as e: print("---",a,e) t1 = threading.Thread(target=pri,args=()) t1.start() t2 = threading.Thread(target=pri,args=()) t2.start()
#程序报错,两个线程都拿到数字5,进程删除5,再删除5?不能删除,则报错。
#列表删除,线程不安全
队列模式1 First in First out(FIFO)
import queue #线程队列,3种模式,默认先进先出 q = queue.Queue() q.put(12) q.put("hello") q.put({"name":"yuan"}) while 1: data = q.get() print(data) print("---------------------")
#输出:12,hello,"name":yuan
队列模式2 Late in First out(Lifo)
import queue #线程队列,3种模式,默认先进先出 q = queue.LifoQueue() q.put(12) q.put("hello") q.put({"name":"yuan"}) while 1: data = q.get() print(data) print("---------------------")
#输出:"name":yuan,hello,12
队列模式3 按优先级输出
import queue #线程队列,3种模式,默认先进先出 q = queue.PriorityQueue() q.put([3,12]) q.put([2,"hello"]) q.put([4,{"name":"yuan"}]) while 1: data = q.get() print(data) #data包括两个参数,优先级+内容分别是data[0]和data[1] print("---------------------") #输出:hello,12,"name":"yuan"
队列其他函数
q.qsize() #判断队列大小 q.empty() #如果队列为空,返回True,反之False q.full() #如果队列满了,返回True,反之False q.put_nowait(56) #等同于 q.put(block=Flase)
q.task_done() #在完成一项工作之后,q.task_done() 函数向任务已经完成的队列发送一个信号
q.join() #实际上意味着等到队列为空,再执行别的操作
七.生产者模型消费者模型
为什么要使用生产者和消费者模式?
运行线程时,生产者就是生产数据的线程,消费者就是消费数据的线程。在多线程开发当中,如果生产者处理速度很快,而消费者处理速度很慢,那么生产者就必须等待消费者处理完,才能继续生产数据。同样的道理,如果消费者的处理能力大于生产者,那么消费者就必须等待生产者。为了解决生产者和消费者之间的时间矛盾,引入生产者和消费者模式。
生产者消费者模式定义?
生产者消费者模式是通过一个容器来解决生产者和消费者的强耦合问题。生产者和消费者彼此之间不直接通讯,而通过阻塞队列进行通讯,所以生产者生产完数据之后不用等待消费者处理,直接扔给阻塞队列,消费者不找生产者要数据,同样直接从阻塞队列里取,阻塞队列就相当于一个缓冲区,平衡生产者和消费者的处理能力。
这就像,在餐厅,厨师做好菜不直接和客户交流,而是交给前台,而客户去饭菜也不需要找厨师,直接去前台领取,这是一个解耦的过程。


import time,random import queue,threading q = queue.Queue() def Producer(name): count = 0 while count < 10: print("making...") time.sleep(5) q.put(count) print("Producer %s has produced %s baozi..."%(name,count)) count +=1 q.join() print("ok...") def Consumer(name): count = 0 while count < 10: time.sleep(random.randrange(4)) data = q.get() print("eating...") time.sleep(4) q.task_done() print('�33[32;1mConsumer %s has eat %s baozi...�33[0m' %(name, data)) count+=1 p1 = threading.Thread(target=Producer, args=("A person",)) c2 = threading.Thread(target=Producer, args=("B person",)) c3 = threading.Thread(target=Producer, args=("C person",)) c4 = threading.THread(target=Producer, args=("D person",)) p1.start() c1.start() c2.start() c3.start()