数据序列化
我们知道,数据在分布式系统上运行程序数据是需要在机器之间通过网络传输的,这些数据必须被编码成一个个的字节才可以进行传输,这个其实就是我们所谓的数据序列化。数据中心中,最稀缺的资源就是网络带宽!在数据量巨大的分布式系统中,数据的紧凑高效传输和解析十分重要。
什么是数据的序列化?
数据的序列化简单点来说就是根据一套协议,在客户端上将内存中的数据编码成字节码,然后将这些字节码通过网络传输到另外一台服务器上,另外一台服务器通过相同的协议将这些字节码翻译成相应的数据存在内存中。一般来水,数据序列化需要满足以下四个条件。
(1) 紧凑。序列化出来的字节尽量的少。
(2) 快速。编码速度和解码速度要快。
(3) 可扩展。如果我增加了新的序列化协议,我们可以在原有的基础上进行扩展。
(4) 支持互操作。我们需要在不同语言所编写的程序之间能够使用相同的序列化协议。
为什么不用Java的序列化?
Java Jdk内部也提供了一套序列化的方法,为什么我们在hadoop程序中不适用java的序列化方法?这是因为java的序列化方法比较重,重表现在他将很多的信息都冗余到了最后编码出来的字节码中,这样就不满足紧凑的条件。所以说,在hadoop中,他自己提供了一套序列化方法,这套序列化的方法都实现了一个接口Writable接口。
Writable接口
public interface Writable {
void write(DataOutput var1) throws IOException;
void readFields(DataInput var1) throws IOException;
}
我们可以看到Writable接口又两个方法。write(DataOutput var1)方法是将对象数据编码成字节,readFields(DataInput var1)方法是一个逆的过程,就是将字节码反序列化内存中的数据。我们知道接口是没有具体的实现的,在Hadoop框架中,他已经默认帮我们实现了Java基本类型的Writable封装,对String类型的封装Text类,以及对Array和Map集合类型的Writable封装。
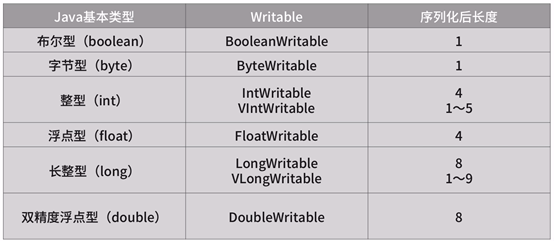
基本类型:
String类型:
String不是一个基本类型,而是一个char数组,为了方便使用,hadoop也在内部进行了封装。
集合类型:
集合类型的封装。我们在序列化的时候,首先将集合的大小写入进去,然后再将几何中的元素依次的序列化。
自定义Writable类型:
自定义Writable封装类一般由基本类型,集合类型和引用类型组成。
通用Writable类型:
在java中我们又object这个超类,在hadoop中我们也有类似的类型,即ObjectWritable。该类型处理了null,java数组,字符串String,java基本类型,枚举和Writable的子类6种情况。如果我们数据的类型是这6种中的一种,我们可以直接将数据标记为ObjectWritable类型,但是使用这种方法序列化会造成资源的浪费。因为ObjectWritable首先会将类名进行序列化,通常一个类的完整类名是非常长的,最后才将这个类的数据进行序列化,会造成资源浪费。
所以在日常使用中一般不使用ObjectWritable类型,而使用GenericWritable。GenericWritable使用的场景是我们大多数使用的场景,他适用于类型的数量不是很多,而且事先可以知道,这样我们就可以通过一个静态的数组,将所有事先知道的类型都列举出来,然后在序列化的时候使用数组下标代替类名序列化。数组的下标可以用一个字节存储,这样就大大缩小了序列化后的长度。
文件压缩
我们知道我们很多mr任务的输出都是hdfs上的文件,如果我们使用压缩格式存储文件可以大大的减少对存储的使用。如果我们在数据传输之前对数据进行压缩,也可以减少数据在网路上传输的大小。常用的与hadoop结合的压缩算法有以下的几种。

文件分片
文件分片对于mr的执行效率十分重要。如果文件不支持分片,则会产生两个问题:
(1) 一个map只能处理一个文件,Map处理时间厂。
(2) 牺牲了数据本地性,一个大文件的多个块存在不同的节点上,如果文件不能分片,则需要将所有的块通过网络传输到一个Map上计算。
选择合理的压缩格式
综合节约磁盘空间,网络带宽和mr的执行效率,一般使用如下的压缩格式:
(1)对于经常访问的数据 使用LZO+索引的方式存储。因为他解压速度比较快,我们读取文件里的数据也就比较快。
(2)对于不经常访问的数据,比如历史比较久远的数据,采用bzip2压缩存储。
(3)Map和Reduce中间的数据传输,采用Snappy压缩。因为他压缩速度和解压所读都非常快。