背景:
调研过OOZIE和AZKABA,这种都是只是使用spark-submit.sh来提交任务,任务提交上去之后获取不到ApplicationId,更无法跟踪spark application的任务状态,无法kill application,更无法获取application的日志信息。因此,为了实现一个spark的调度平台所以有了以下调研及测试结论。
调研目前流行的SPARK任务调度:Oozie和Azkaban。
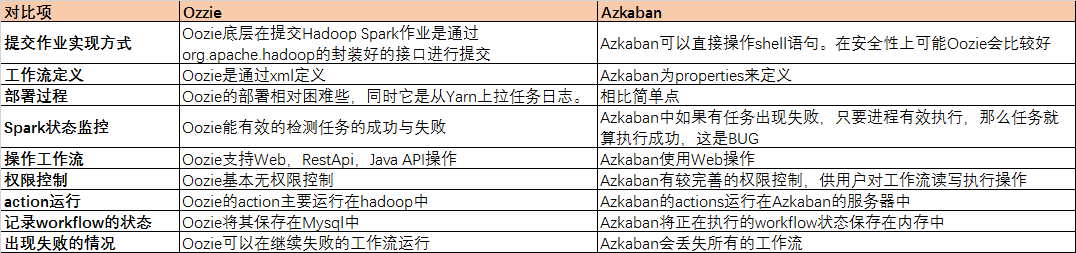
但是这两个平台不能满足以下功能(这些功能是希望有的):
1) 无法满足即安全(使用shell提交任务,操作用户权限控制)又可以Spark状态监控(跟踪SPARK application的任务状态);
2) 无法满足监控集群运行状态;
3) 无法满足对每个任务设置监控策略。比如:任务假死状态判定。
一个合格的spark调度平台要具有的基本功能:可以submit,kill,监控,获取日志,跟踪历史记录。
本篇文章主要讲解如何使用YarnClient API实现,借助于YarnClient来实现监控任务,杀死任务,获取日志,使用org.apache.spark.deploy.yarn.Client提交spark任务并返回spark任务的applicationId。
备注:之前研究过使用SparkLauncher类进行调度,该方案也是一种不错的方案,如果读者你喜欢也可以尝试使用SparkLauncher,它一样可以提交后返回spark任务的applicationid(提交后无状态,需要等待applicaitonId不为空为止)。
环境配置:
1)由于我们是使用java 代码(需要发布到web项目中,而不是shell调用[不可以再shell中设置环境变量])去调用,因此我们需要centos系统环境变量中包含以下变量:
SPARK_KAFKA_VERSION
HADOOP_HOME
HADOOP_COMMON_HOME
SPARK_HOME
SPARK_CONF_DIR
HADOOP_CONF_DIR
YARN_CONF_DIR
SPARK_DIST_CLASSPATH
SPARK_EXTRA_LIB_PATH
LD_LIBRARY_PATH
如果你对spark-env.sh文件比较熟悉的话,你会发现上边这些变量来自于该文件,那么,我们嗯只需要把spark-env.sh引入到/ect/profile就可以。
spark-env.sh


1 bash-4.1$ more /home1/opt/cloudera/parcels/SPARK2-2.3.0.cloudera3-1.cdh5.13.3.p0.458809/lib/spark2/conf/spark-env.sh 2 #!/usr/bin/env bash 3 ## 4 # Generated by Cloudera Manager and should not be modified directly 5 ## 6 7 SELF="$(cd $(dirname $BASH_SOURCE) && pwd)" 8 if [ -z "$SPARK_CONF_DIR" ]; then 9 export SPARK_CONF_DIR="$SELF" 10 fi 11 12 export SPARK_HOME=/home1/opt/cloudera/parcels/SPARK2-2.3.0.cloudera3-1.cdh5.13.3.p0.458809/lib/spark2 13 14 SPARK_PYTHON_PATH="" 15 if [ -n "$SPARK_PYTHON_PATH" ]; then 16 export PYTHONPATH="$PYTHONPATH:$SPARK_PYTHON_PATH" 17 fi 18 19 export HADOOP_HOME=/home1/opt/cloudera/parcels/CDH-5.13.0-1.cdh5.13.0.p0.29/lib/hadoop 20 export HADOOP_COMMON_HOME="$HADOOP_HOME" 21 22 if [ -n "$HADOOP_HOME" ]; then 23 LD_LIBRARY_PATH=$LD_LIBRARY_PATH:${HADOOP_HOME}/lib/native 24 fi 25 26 SPARK_EXTRA_LIB_PATH="/home1/opt/cloudera/parcels/GPLEXTRAS-5.13.0-1.cdh5.13.0.p0.29/lib/hadoop/lib/native" 27 if [ -n "$SPARK_EXTRA_LIB_PATH" ]; then 28 LD_LIBRARY_PATH=$LD_LIBRARY_PATH:$SPARK_EXTRA_LIB_PATH 29 fi 30 31 export LD_LIBRARY_PATH 32 33 HADOOP_CONF_DIR=${HADOOP_CONF_DIR:-$SPARK_CONF_DIR/yarn-conf} 34 export HADOOP_CONF_DIR 35 36 PYLIB="$SPARK_HOME/python/lib" 37 if [ -f "$PYLIB/pyspark.zip" ]; then 38 PYSPARK_ARCHIVES_PATH= 39 for lib in "$PYLIB"/*.zip; do 40 if [ -n "$PYSPARK_ARCHIVES_PATH" ]; then 41 PYSPARK_ARCHIVES_PATH="$PYSPARK_ARCHIVES_PATH,local:$lib" 42 else 43 PYSPARK_ARCHIVES_PATH="local:$lib" 44 fi 45 done 46 export PYSPARK_ARCHIVES_PATH 47 fi 48 49 # Spark uses `set -a` to export all variables created or modified in this 50 # script as env vars. We use a temporary variables to avoid env var name 51 # collisions. 52 # If PYSPARK_PYTHON is unset, set to CDH_PYTHON 53 TMP_PYSPARK_PYTHON=${PYSPARK_PYTHON:-''} 54 # If PYSPARK_DRIVER_PYTHON is unset, set to CDH_PYTHON 55 TMP_PYSPARK_DRIVER_PYTHON=${PYSPARK_DRIVER_PYTHON:-} 56 57 if [ -n "$TMP_PYSPARK_PYTHON" ] && [ -n "$TMP_PYSPARK_DRIVER_PYTHON" ]; then 58 export PYSPARK_PYTHON="$TMP_PYSPARK_PYTHON" 59 export PYSPARK_DRIVER_PYTHON="$TMP_PYSPARK_DRIVER_PYTHON" 60 fi 61 62 # Add the Kafka jars configured by the user to the classpath. 63 SPARK_DIST_CLASSPATH= 64 SPARK_KAFKA_VERSION=${SPARK_KAFKA_VERSION:-'0.10'} 65 case "$SPARK_KAFKA_VERSION" in 66 0.9) 67 SPARK_DIST_CLASSPATH="$SPARK_HOME/kafka-0.9/*" 68 ;; 69 0.10) 70 SPARK_DIST_CLASSPATH="$SPARK_HOME/kafka-0.10/*" 71 ;; 72 None) 73 ;; 74 *) 75 echo "Invalid Kafka version: $SPARK_KAFKA_VERSION" 76 exit 1 77 ;; 78 esac 79 80 export SPARK_DIST_CLASSPATH="$SPARK_DIST_CLASSPATH:$(paste -sd: "$SELF/classpath.txt")"
接下来在/ect/profile文件最后一样追加
source /home1/opt/cloudera/parcels/SPARK2-2.3.0.cloudera3-1.cdh5.13.3.p0.458809/lib/spark2/conf/spark-env.sh
,保存,然后source /etc/profile使其生效。
2)需要修改yarn上传资源文件存储位置,否则会出现错误找不到资源文件(文件之所以找不到,是因为那些资源文件spark_lib.zip,spark_conf.zip,*.jar被上传到本地的/curent_user[root、zhangsan、lisi]/.sparkStaging/{appId}/*.jar下,在其他executor|container上找不到),必须修改yarn资源文件上传到hdfs目录下:
第一步:提交任务代码中设置SparkConf变量:
sparkConf.set("spark.yarn.stagingDir", "hdfs://vm192.168.0.141.com.cn:8020/user/");
第二步:手动创建hdfs目录 /user/.sparkStaging,给分配权限:
bash-4.1$ sudo -uhdfs hadoop fs -mkdir /user/.sparkStaging bash-4.1$ sudo -uhdfs hadoop fs -chown zhangsan:zhangsan /user/.sparkStaging
第三步:导入pom.xml依赖包
<properties> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> <es.version>6.4.2</es.version> <spark.version>2.3.0</spark.version> <scala.version>2.11</scala.version> </properties> <dependencies> <!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-yarn-client --> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-yarn-client</artifactId> <version>2.6.5</version> </dependency> <!--Spark --> <!-- https://mvnrepository.com/artifact/org.apache.spark/spark-yarn --> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-yarn_${scala.version}</artifactId> <version>${spark.version}</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_${scala.version}</artifactId> <version>${spark.version}</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-streaming_${scala.version}</artifactId> <version>${spark.version}</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-sql_${scala.version}</artifactId> <version>${spark.version}</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-sql-kafka-0-10_${scala.version}</artifactId> <version>${spark.version}</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-streaming-kafka-0-10_${scala.version}</artifactId> <version>${spark.version}</version> </dependency> <!-- https://mvnrepository.com/artifact/org.apache.spark/spark-launcher --> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-launcher_${scala.version}</artifactId> <version>${spark.version}</version> </dependency> <dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka_2.11</artifactId> <version>0.10.0.1</version> </dependency> <dependency> <groupId>org.scala-lang</groupId> <artifactId>scala-library</artifactId> <version>2.11.6</version> </dependency> <dependency> <groupId>com.twitter</groupId> <artifactId>bijection-avro_${scala.version}</artifactId> <version>0.9.5</version> </dependency> <dependency> <groupId>com.databricks</groupId> <artifactId>spark-avro_${scala.version}</artifactId> <version>3.2.0</version> <type>jar</type> </dependency> <dependency> <groupId>org.elasticsearch</groupId> <artifactId>elasticsearch-spark-20_${scala.version}</artifactId> <version>${es.version}</version> </dependency> <dependency> <groupId>org.elasticsearch.client</groupId> <artifactId>transport</artifactId> <version>${es.version}</version> </dependency> <!-- https://mvnrepository.com/artifact/com.alibaba/fastjson --> <dependency> <groupId>com.alibaba</groupId> <artifactId>fastjson</artifactId> <version>1.2.54</version> </dependency> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>3.8.1</version> <scope>test</scope> </dependency> </dependencies>
spark提交任务:
参数类YarnSubmitConditions:
1 import java.util.List; 2 import java.util.Map; 3 4 public class YarnSubmitConditions { 5 private List<String> otherArgs; 6 private String applicationJar; 7 private String mainClass; 8 private String appName; 9 private String[] additionalJars; 10 private String sparkYarnJars; 11 public String[] files; 12 public String yarnResourcemanagerAddress; 13 public String sparkFsDefaultFS; 14 private String driverMemory; 15 private String numExecutors; 16 private String executorMemory; 17 private String executorCores; 18 private String sparkHome; 19 private String deployMode; 20 private String master; 21 public Map<String, String> sparkProperties; 22 23 public List<String> getOtherArgs() { 24 return otherArgs; 25 } 26 27 public void setOtherArgs(List<String> otherArgs) { 28 this.otherArgs = otherArgs; 29 } 30 31 public String getApplicationJar() { 32 return applicationJar; 33 } 34 35 public void setApplicationJar(String applicationJar) { 36 this.applicationJar = applicationJar; 37 } 38 39 public String getMainClass() { 40 return mainClass; 41 } 42 43 public void setMainClass(String mainClass) { 44 this.mainClass = mainClass; 45 } 46 47 public String getAppName() { 48 return appName; 49 } 50 51 public void setAppName(String appName) { 52 this.appName = appName; 53 } 54 55 public String[] getAdditionalJars() { 56 return additionalJars; 57 } 58 59 public void setAdditionalJars(String[] additionalJars) { 60 this.additionalJars = additionalJars; 61 } 62 63 public String getSparkYarnJars() { 64 return sparkYarnJars; 65 } 66 67 public void setSparkYarnJars(String sparkYarnJars) { 68 this.sparkYarnJars = sparkYarnJars; 69 } 70 71 public String[] getFiles() { 72 return files; 73 } 74 75 public void setFiles(String[] files) { 76 this.files = files; 77 } 78 79 public String getYarnResourcemanagerAddress() { 80 return yarnResourcemanagerAddress; 81 } 82 83 public void setYarnResourcemanagerAddress(String yarnResourcemanagerAddress) { 84 this.yarnResourcemanagerAddress = yarnResourcemanagerAddress; 85 } 86 87 public Map<String, String> getSparkProperties() { 88 return sparkProperties; 89 } 90 91 public void setSparkProperties(Map<String, String> sparkProperties) { 92 this.sparkProperties = sparkProperties; 93 } 94 95 public String getSparkFsDefaultFS() { 96 return sparkFsDefaultFS; 97 } 98 99 public void setSparkFsDefaultFS(String sparkFsDefaultFS) { 100 this.sparkFsDefaultFS = sparkFsDefaultFS; 101 } 102 103 public String getDriverMemory() { 104 return driverMemory; 105 } 106 107 public void setDriverMemory(String driverMemory) { 108 this.driverMemory = driverMemory; 109 } 110 111 public String getNumExecutors() { 112 return numExecutors; 113 } 114 115 public void setNumExecutors(String numExecutors) { 116 this.numExecutors = numExecutors; 117 } 118 119 public String getExecutorMemory() { 120 return executorMemory; 121 } 122 123 public void setExecutorMemory(String executorMemory) { 124 this.executorMemory = executorMemory; 125 } 126 127 public String getExecutorCores() { 128 return executorCores; 129 } 130 131 public void setExecutorCores(String executorCores) { 132 this.executorCores = executorCores; 133 } 134 135 public String getSparkHome() { 136 return sparkHome; 137 } 138 139 public void setSparkHome(String sparkHome) { 140 this.sparkHome = sparkHome; 141 } 142 143 public String getDeployMode() { 144 return deployMode; 145 } 146 147 public void setDeployMode(String deployMode) { 148 this.deployMode = deployMode; 149 } 150 151 public String getMaster() { 152 return master; 153 } 154 155 public void setMaster(String master) { 156 this.master = master; 157 } 158 }
提交函数:
/** * 提交任务到yarn集群 * * @param conditions * yarn集群,spark,hdfs具体信息,参数等 * @return appid */ public static String submitSpark(YarnSubmitConditions conditions) { logger.info("初始化spark on yarn参数"); // 初始化yarn客户端 logger.info("初始化spark on yarn客户端"); List<String> args = Lists.newArrayList(// "--jar", conditions.getApplicationJar(),// "--class", conditions.getMainClass()// ); if (conditions.getOtherArgs() != null && conditions.getOtherArgs().size() > 0) { for (String s : conditions.getOtherArgs()) { args.add("--arg"); args.add(org.apache.commons.lang.StringUtils.join(new String[] { s }, ",")); } } // identify that you will be using Spark as YARN mode System.setProperty("SPARK_YARN_MODE", "true"); System.out.println("SPARK_YARN_MODE:" + System.getenv("SPARK_YARN_MODE")); System.out.println("SPARK_CONF_DIR:" + System.getenv("SPARK_CONF_DIR")); System.out.println("HADOOP_CONF_DIR:" + System.getenv("HADOOP_CONF_DIR")); System.out.println("YARN_CONF_DIR:" + System.getenv("YARN_CONF_DIR")); System.out.println("SPARK_KAFKA_VERSION:" + System.getenv("SPARK_KAFKA_VERSION")); System.out.println("HADOOP_HOME:" + System.getenv("HADOOP_HOME")); System.out.println("HADOOP_COMMON_HOME:" + System.getenv("HADOOP_COMMON_HOME")); System.out.println("SPARK_HOME:" + System.getenv("SPARK_HOME")); System.out.println("SPARK_DIST_CLASSPATH:" + System.getenv("SPARK_DIST_CLASSPATH")); System.out.println("SPARK_EXTRA_LIB_PATH:" + System.getenv("SPARK_EXTRA_LIB_PATH")); System.out.println("LD_LIBRARY_PATH:" + System.getenv("LD_LIBRARY_PATH")); SparkConf sparkConf = new SparkConf(); sparkConf.setSparkHome(conditions.getSparkHome()); sparkConf.setMaster(conditions.getMaster()); sparkConf.set("spark.submit.deployMode", conditions.getDeployMode()); sparkConf.setAppName(conditions.getAppName()); // --driver-memory sparkConf.set("spark.driver.memory", conditions.getDriverMemory()); // --executor-memory sparkConf.set("spark.executor.memory", conditions.getExecutorMemory()); // --executor-cores sparkConf.set("spark.executor.cores", conditions.getExecutorCores()); // --num-executors sparkConf.set("spark.executor.instance", conditions.getNumExecutors()); // The folder '.sparkStaging' will be created auto. // System.out.println("SPARK_YARN_STAGING_DIR:"+System.getenv("SPARK_YARN_STAGING_DIR")) sparkConf.set("spark.yarn.stagingDir", "hdfs://vm192.168.0.141.com.cn:8020/user/"); // sparkConf.set("spark.jars",); // sparkConf.set("spark.yarn.jars", conditions.getSparkYarnJars()); if (conditions.getAdditionalJars() != null && conditions.getAdditionalJars().length > 0) { sparkConf.set("spark.repl.local.jars", org.apache.commons.lang.StringUtils.join(conditions.getAdditionalJars(), ",")); sparkConf.set("spark.yarn.dist.jars", org.apache.commons.lang.StringUtils.join(conditions.getAdditionalJars(), ",")); } // "--files","hdfs://node1:8020/user/root/yarn-site.xml", if (conditions.getFiles() != null && conditions.getFiles().length > 0) { sparkConf.set("spark.files", org.apache.commons.lang.StringUtils.join(conditions.getFiles(), ",")); } for (Map.Entry<String, String> e : conditions.getSparkProperties().entrySet()) { sparkConf.set(e.getKey().toString(), e.getValue().toString()); } // mapred-site.xml // 指定使用yarn框架 sparkConf.set("mapreduce.framework.name", "yarn"); // 指定historyserver sparkConf.set("mapreduce.jobhistory.address", "vm192.168.0.141.com.cn:10020"); // yarn-site.xml // 添加这个参数,不然spark会一直请求0.0.0.0:8030,一直重试 sparkConf.set("yarn.resourcemanager.hostname", conditions.getYarnResourcemanagerAddress().split(":")[0]); // 指定资源分配器 sparkConf.set("yarn.resourcemanager.scheduler.address", "vm192.168.0.141.com.cn:8030"); // 设置为true,不删除缓存的jar包,因为现在提交yarn任务是使用的代码配置,没有配置文件,删除缓存的jar包有问题, sparkConf.set("spark.yarn.preserve.staging.files", "false"); // spark2.2 // 初始化 yarn的配置 // Configuration cf = new Configuration(); // String cross_platform = "false"; // String os = System.getProperty("os.name"); // if (os.contains("Windows")) { // cross_platform = "true"; // } // 配置使用跨平台提交任务 // cf.set("mapreduce.app-submission.cross-platform", cross_platform); // 设置yarn资源,不然会使用localhost:8032 // cf.set("yarn.resourcemanager.address", // conditions.getYarnResourcemanagerAddress()); // 设置namenode的地址,不然jar包会分发,非常恶心 // cf.set("fs.defaultFS", conditions.getSparkFsDefaultFS()); // spark2.2 // Client client = new Client(cArgs, cf, sparkConf); // spark2.3 ClientArguments cArgs = new ClientArguments(args.toArray(new String[args.size()])); org.apache.spark.deploy.yarn.Client client = new Client(cArgs, sparkConf); logger.info("提交任务,任务名称:" + conditions.getAppName()); try { ApplicationId appId = client.submitApplication(); return appId.toString(); } catch (Exception e) { logger.error("提交spark任务失败", e); return null; } finally { if (client != null) { client.stop(); } } }
测试函数
private static final org.slf4j.Logger logger = org.slf4j.LoggerFactory.getLogger(TestSubmit.class); public static void main(String[] args) { YarnSubmitConditions conditions = new YarnSubmitConditions(); conditions.setAppName("test yarn submit app"); conditions.setMaster("yarn"); conditions.setSparkHome("/home1/opt/cloudera/parcels/SPARK2/lib/spark2/"); conditions.setDeployMode("cluster"); conditions.setDriverMemory("3g"); conditions.setExecutorMemory("3g"); conditions.setExecutorCores("1"); conditions.setNumExecutors("5"); // /etc/hadoop/conf.cloudera.yarn/core-site.xml conditions.setYarnResourcemanagerAddress("vm192.168.0.141.com.cn:8032"); // /etc/hadoop/conf.cloudera.yarn/yarn-site.xml conditions.setSparkFsDefaultFS("hdfs://vm192.168.0.141.com.cn:8020"); conditions.setFiles(new String[] { "/etc/hadoop/conf.cloudera.yarn/hdfs-site.xml",// "/etc/hadoop/conf.cloudera.yarn/mapred-site.xml",// "/etc/hadoop/conf.cloudera.yarn/yarn-site.xml",// }); conditions.setApplicationJar("/home1/zhangsan/mrs-streaming-driver.jar"); conditions.setMainClass("com.boco.mrs.streaming.Main"); conditions.setOtherArgs(Arrays.asList("RSRP", "TestBroadcastDriver")); List<String> sparkJars = getSparkJars("/home1/zhangsan/sparkjars/"); conditions.setAdditionalJars(sparkJars.toArray(new String[sparkJars.size()])); Map<String, String> propertiesMap = null; try { propertiesMap = getSparkProperties("/home1/zhangsan/conf/spark-properties-mrs.conf"); } catch (IOException e) { e.printStackTrace(); } conditions.setSparkProperties(propertiesMap); String appId = submitSpark(conditions); System.out.println("application id is " + appId); System.out.println("Complete ...."); } /** * 加载sparkjars下的jar文件 * */ private static List<String> getSparkJars(String dir) { List<String> items = new ArrayList<String>(); File file = new File(dir); for (File item : file.listFiles()) { items.add(item.getPath()); } return items; } /** * 加载spark-properties.conf配置文件 * */ private static Map<String, String> getSparkProperties(String filePath) throws IOException { Map<String, String> propertiesMap = new HashMap<String, String>(); BufferedReader reader = new BufferedReader(new FileReader(filePath)); String line = null; while ((line = reader.readLine()) != null) { if (line.trim().length() > 0 && !line.startsWith("#") && line.indexOf("=") != -1) { String[] fields = line.split("="); propertiesMap.put(fields[0], fields[1]); } } reader.close(); return propertiesMap; }
测试函数执行脚本:
bash-4.1$ more test.sh #/bin/sh #LANG=zh_CN.utf8 #export LANG export SPARK_KAFKA_VERSION=0.10 export LANG=zh_CN.UTF-8 java -cp ./sparkjars/*:./mrs-streaming-driver.jar com.dx.mrs.streaming.batchmodule.TestSubmit
执行日志:
1 bash-4.1$ ./test.sh 2 log4j:WARN No appenders could be found for logger (com.dx.mrs.streaming.batchmodule.TestSubmit). 3 log4j:WARN Please initialize the log4j system properly. 4 log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info. 5 SPARK_YARN_MODE:null 6 SPARK_CONF_DIR:/home1/opt/cloudera/parcels/SPARK2-2.3.0.cloudera3-1.cdh5.13.3.p0.458809/lib/spark2/conf 7 HADOOP_CONF_DIR:/home1/opt/cloudera/parcels/SPARK2-2.3.0.cloudera3-1.cdh5.13.3.p0.458809/lib/spark2/conf/yarn-conf 8 YARN_CONF_DIR:null 9 SPARK_KAFKA_VERSION:0.10 10 HADOOP_HOME:/home1/opt/cloudera/parcels/CDH-5.13.0-1.cdh5.13.0.p0.29/lib/hadoop 11 HADOOP_COMMON_HOME:/home1/opt/cloudera/parcels/CDH-5.13.0-1.cdh5.13.0.p0.29/lib/hadoop 12 SPARK_HOME:/home1/opt/cloudera/parcels/SPARK2-2.3.0.cloudera3-1.cdh5.13.3.p0.458809/lib/spark2 13 SPARK_DIST_CLASSPATH:/home1/opt/cloudera/parcels/SPARK2-2.3.0.cloudera3-1.cdh5.13.3.p0.458809/lib/spark2/kafka-0.10/*:/home1/opt/cloudera/parcels/CDH-5.13.0-1.cdh5.13.0.p0.29/jars/activation-1.1.jar:/home1/opt/cloudera/parcels/CDH-5.13.0-1.cdh5.13.0.p0.29/jars/aopalliance-1.0.jar:/home1/opt/cloudera/parcels/CDH-5.13.0-1.cdh5.13.0.p0.29/jars/apacheds-i18n-2.0.0-M15.jar:/home1/opt/cloudera/parcels/CDH-5.13.0-1.cdh5.13.0.p0.29/jars/apacheds-kerberos-codec-2.0.0-M15.jar:/home1/opt/cloudera/parcels/CDH-5.13.0-1.cdh5.13.0.p0.29/jars/api-asn1-api-1.0.0-M20.jar:/home1/opt/cloudera/parcels/CDH-5.13.0-1.cdh5.13.0.p0.29/jars/api-util-1.0.0-M20.jar:/home1/opt/cloudera/parcels/CDH-5.13.0-1.cdh5.13.0.p0.29/jars/asm-3.2.jar:/home1/opt/cloudera/parcels/CDH-5.13.0-1.cdh5.13.0.p0.29/jars/avro-1.7.6-cdh5.13.0.jar:/home1/opt/cloudera/parcels/CDH-5.13.0-1.cdh5.13.0.p0.29/jars/aws-java-sdk-bundle-1.11.134.jar:/home1/opt/cloudera/parcels/CDH-5.13.0-1.cdh5.13.0.p0.29/jars/azure-data-lake-store-sdk-2.2.3.jar:/home1/opt/cloudera/parcels/CDH-5.13.0-1.cdh5.13.0.p0.29/jars/commons-beanutils-1.9.2.jar:/home1/opt/cloudera/parcels/CDH-5.13.0-1.cdh5.13.0.p0.29/jars/commons-beanutils-core-1.8.0.jar:/home1/opt/cloudera/parcels/CDH-5.13.0-1.cdh5.13.0.p0.29/jars/commons-codec-1.4.jar:/home1/opt/cloudera/parcels/CDH-5.13.0-1.cdh5.13.0.p0.29/jars/commons-configuration-1.6.jar:/home1/opt/cloudera/parcels/CDH-5.13.0-1.cdh5.13.0.p0.29/jars/commons-daemon-1.0.13.jar:/home1/opt/cloudera/parcels/CDH-5.13.0-1.cdh5.13.0.p0.29/jars/commons-digester-1.8.jar:/home1/opt/cloudera/parcels/CDH-5.13.0-1.cdh5.13.0.p0.29/jars/commons-el-1.0.jar:/home1/opt/cloudera/parcels/CDH-5.13.0-1.cdh5.13.0.p0.29/jars/commons-math3-3.1.1.jar:/home1/opt/cloudera/parcels/CDH-5.13.0-1.cdh5.13.0.p0.29/jars/commons-net-3.1.jar:/home1/opt/cloudera/parcels/CDH-5.13.0-1.cdh5.13.0.p0.29/jars/curator-client-2.7.1.jar:/home1/opt/cloudera/parcels/CDH-5.13.0-1.cdh5.13.0.p0.29/jars/curator-framework-2.7.1.jar:/home1/opt/cloudera/parcels/CDH-5.13.0-1.cdh5.13.0.p0.29/jars/curator-recipes-2.7.1.jar:/home1/opt/cloudera/parcels/CDH-5.13.0-1.cdh5.13.0.p0.29/jars/guava-11.0.2.jar:/home1/opt/cloudera/parcels/CDH-5.13.0-1.cdh5.13.0.p0.29/jars/guice-3.0.jar:/home1/opt/cloudera/parcels/CDH-5.13.0-1.cdh5.13.0.p0.29/jars/hadoop-annotations-2.6.0-cdh5.13.0.jar:/home1/opt/cloudera/parcels/CDH-5.13.0-1.cdh5.13.0.p0.29/jars/hadoop-ant-2.6.0-cdh5.13.0.jar:/home1/opt/cloudera/parcels/CDH-5.13.0-1.cdh5.13.0.p0.29/jars/hadoop-archive-logs-2.6.0-cdh5.13.0.jar:/home1/opt/cloudera/parcels/CDH-5.13.0-1.cdh5.13.0.p0.29/jars/hadoop-archives-2.6.0-cdh5.13.0.jar:/home1/opt/cloudera/parcels/CDH-5.13.0-1.cdh5.13.0.p0.29/jars/hadoop-auth-2.6.0-cdh5.13.0.jar:/home1/opt/cloudera/parcels/CDH-5.13.0-1.cdh5.13.0.p0.29/jars/hadoop-aws-2.6.0-cdh5.13.0.jar:/home1/opt/cloudera/parcels/CDH-5.13.0-1.cdh5.13.0.p0.29/jars/hadoop-azure-2.6.0-cdh5.13.0.jar:/home1/opt/cloudera/parcels/CDH-5.13.0-1.cdh5.13.0.p0.29/jars/hadoop-azure-datalake-2.6.0-cdh5.13.0.jar:/home1/opt/cloudera/parcels/CDH-5.13.0-1.cdh5.13.0.p0.29/jars/hadoop-common-2.6.0-cdh5.13.0.jar:/home1/opt/cloudera/parcels/CDH-5.13.0-1.cdh5.13.0.p0.29/jars/hadoop-datajoin-2.6.0-cdh5.13.0.jar:/home1/opt/cloudera/parcels/CDH-5.13.0-1.cdh5.13.0.p0.29/jars/hadoop-distcp-2.6.0-cdh5.13.0.jar:/home1/opt/cloudera/parcels/CDH-5.13.0-1.cdh5.13.0.p0.29/jars/hadoop-extras-2.6.0-cdh5.13.0.jar:/home1/opt/cloudera/parcels/CDH-5.13.0-1.cdh5.13.0.p0.29/jars/hadoop-gridmix-2.6.0-cdh5.13.0.jar:/home1/opt/cloudera/parcels/CDH-5.13.0-1.cdh5.13.0.p0.29/jars/hadoop-hdfs-2.6.0-cdh5.13.0.jar:/home1/opt/cloudera/parcels/CDH-5.13.0-1.cdh5.13.0.p0.29/jars/hadoop-hdfs-nfs-2.6.0-cdh5.13.0.jar:/home1/opt/cloudera/parcels/CDH-5.13.0-1.cdh5.13.0.p0.29/jars/hadoop-mapreduce-client-app-2.6.0-cdh5.13.0.jar:/home1/opt/cloudera/parcels/CDH-5.13.0-1.cdh5.13.0.p0.29/jars/hadoop-mapreduce-client-common-2.6.0-cdh5.13.0.jar:/home1/opt/cloudera/parcels/CDH-5.13.0-1.cdh5.13.0.p0.29/jars/hadoop-mapreduce-client-core-2.6.0-cdh5.13.0.jar:/home1/opt/cloudera/parcels/CDH-5.13.0-1.cdh5.13.0.p0.29/jars/hadoop-mapreduce-client-hs-2.6.0-cdh5.13.0.jar:/home1/opt/cloudera/parcels/CDH-5.13.0-1.cdh5.13.0.p0.29/jars/hadoop-mapreduce-client-hs-plugins-2.6.0-cdh5.13.0.jar:/home1/opt/cloudera/parcels/CDH-5.13.0-1.cdh5.13.0.p0.29/jars/hadoop-mapreduce-client-jobclient-2.6.0-cdh5.13.0.jar:/home1/opt/cloudera/parcels/CDH-5.13.0-1.cdh5.13.0.p0.29/jars/hadoop-mapreduce-client-nativetask-2.6.0-cdh5.13.0.jar:/home1/opt/cloudera/parcels/CDH-5.13.0-1.cdh5.13.0.p0.29/jars/hadoop-mapreduce-client-shuffle-2.6.0-cdh5.13.0.jar:/home1/opt/cloudera/parcels/CDH-5.13.0-1.cdh5.13.0.p0.29/jars/hadoop-mapreduce-examples-2.6.0-cdh5.13.0.jar:/home1/opt/cloudera/parcels/CDH-5.13.0-1.cdh5.13.0.p0.29/jars/hadoop-nfs-2.6.0-cdh5.13.0.jar:/home1/opt/cloudera/parcels/CDH-5.13.0-1.cdh5.13.0.p0.29/jars/hadoop-openstack-2.6.0-cdh5.13.0.jar:/home1/opt/cloudera/parcels/CDH-5.13.0-1.cdh5.13.0.p0.29/jars/hadoop-rumen-2.6.0-cdh5.13.0.jar:/home1/opt/cloudera/parcels/CDH-5.13.0-1.cdh5.13.0.p0.29/jars/hadoop-sls-2.6.0-cdh5.13.0.jar:/home1/opt/cloudera/parcels/CDH-5.13.0-1.cdh5.13.0.p0.29/jars/hadoop-streaming-2.6.0-cdh5.13.0.jar:/home1/opt/cloudera/parcels/CDH-5.13.0-1.cdh5.13.0.p0.29/jars/hadoop-yarn-api-2.6.0-cdh5.13.0.jar:/home1/opt/cloudera/parcels/CDH-5.13.0-1.cdh5.13.0.p0.29/jars/hadoop-yarn-applications-distributedshell-2.6.0-cdh5.13.0.jar:/home1/opt/cloudera/parcels/CDH-5.13.0-1.cdh5.13.0.p0.29/jars/hadoop-yarn-applications-unmanaged-am-launcher-2.6.0-cdh5.13.0.jar:/home1/opt/cloudera/parcels/CDH-5.13.0-1.cdh5.13.0.p0.29/jars/hadoop-yarn-client-2.6.0-cdh5.13.0.jar:/home1/opt/cloudera/parcels/CDH-5.13.0-1.cdh5.13.0.p0.29/jars/hadoop-yarn-common-2.6.0-cdh5.13.0.jar:/home1/opt/cloudera/parcels/CDH-5.13.0-1.cdh5.13.0.p0.29/jars/hadoop-yarn-registry-2.6.0-cdh5.13.0.jar:/home1/opt/cloudera/parcels/CDH-5.13.0-1.cdh5.13.0.p0.29/jars/hadoop-yarn-server-applicationhistoryservice-2.6.0-cdh5.13.0.jar:/home1/opt/cloudera/parcels/CDH-5.13.0-1.cdh5.13.0.p0.29/jars/hadoop-yarn-server-common-2.6.0-cdh5.13.0.jar:/home1/opt/cloudera/parcels/CDH-5.13.0-1.cdh5.13.0.p0.29/jars/hadoop-yarn-server-nodemanager-2.6.0-cdh5.13.0.jar:/home1/opt/cloudera/parcels/CDH-5.13.0-1.cdh5.13.0.p0.29/jars/hadoop-yarn-server-resourcemanager-2.6.0-cdh5.13.0.jar:/home1/opt/cloudera/parcels/CDH-5.13.0-1.cdh5.13.0.p0.29/jars/hadoop-yarn-server-web-proxy-2.6.0-cdh5.13.0.jar:/home1/opt/cloudera/parcels/CDH-5.13.0-1.cdh5.13.0.p0.29/jars/hamcrest-core-1.3.jar:/home1/opt/cloudera/parcels/CDH-5.13.0-1.cdh5.13.0.p0.29/jars/htrace-core4-4.0.1-incubating.jar:/home1/opt/cloudera/parcels/CDH-5.13.0-1.cdh5.13.0.p0.29/jars/httpclient-4.2.5.jar:/home1/opt/cloudera/parcels/CDH-5.13.0-1.cdh5.13.0.p0.29/jars/httpcore-4.2.5.jar:/home1/opt/cloudera/parcels/CDH-5.13.0-1.cdh5.13.0.p0.29/jars/hue-plugins-3.9.0-cdh5.13.0.jar:/home1/opt/cloudera/parcels/CDH-5.13.0-1.cdh5.13.0.p0.29/jars/jackson-annotations-2.2.3.jar:/home1/opt/cloudera/parcels/CDH-5.13.0-1.cdh5.13.0.p0.29/jars/jackson-core-2.2.3.jar:/home1/opt/cloudera/parcels/CDH-5.13.0-1.cdh5.13.0.p0.29/jars/jackson-core-asl-1.8.8.jar:/home1/opt/cloudera/parcels/CDH-5.13.0-1.cdh5.13.0.p0.29/jars/jackson-databind-2.2.3.jar:/home1/opt/cloudera/parcels/CDH-5.13.0-1.cdh5.13.0.p0.29/jars/jackson-mapper-asl-1.8.8.jar:/home1/opt/cloudera/parcels/CDH-5.13.0-1.cdh5.13.0.p0.29/jars/jasper-compiler-5.5.23.jar:/home1/opt/cloudera/parcels/CDH-5.13.0-1.cdh5.13.0.p0.29/jars/jasper-runtime-5.5.23.jar:/home1/opt/cloudera/parcels/CDH-5.13.0-1.cdh5.13.0.p0.29/jars/java-xmlbuilder-0.4.jar:/home1/opt/cloudera/parcels/CDH-5.13.0-1.cdh5.13.0.p0.29/jars/javax.inject-1.jar:/home1/opt/cloudera/parcels/CDH-5.13.0-1.cdh5.13.0.p0.29/jars/jaxb-api-2.2.2.jar:/home1/opt/cloudera/parcels/CDH-5.13.0-1.cdh5.13.0.p0.29/jars/jaxb-impl-2.2.3-1.jar:/home1/opt/cloudera/parcels/CDH-5.13.0-1.cdh5.13.0.p0.29/jars/jets3t-0.9.0.jar:/home1/opt/cloudera/parcels/CDH-5.13.0-1.cdh5.13.0.p0.29/jars/jettison-1.1.jar:/home1/opt/cloudera/parcels/CDH-5.13.0-1.cdh5.13.0.p0.29/jars/jline-2.11.jar:/home1/opt/cloudera/parcels/CDH-5.13.0-1.cdh5.13.0.p0.29/jars/jsch-0.1.42.jar:/home1/opt/cloudera/parcels/CDH-5.13.0-1.cdh5.13.0.p0.29/jars/jsr305-3.0.0.jar:/home1/opt/cloudera/parcels/CDH-5.13.0-1.cdh5.13.0.p0.29/jars/leveldbjni-all-1.8.jar:/home1/opt/cloudera/parcels/CDH-5.13.0-1.cdh5.13.0.p0.29/jars/log4j-1.2.17.jar:/home1/opt/cloudera/parcels/CDH-5.13.0-1.cdh5.13.0.p0.29/jars/metrics-core-3.0.2.jar:/home1/opt/cloudera/parcels/CDH-5.13.0-1.cdh5.13.0.p0.29/jars/microsoft-windowsazure-storage-sdk-0.6.0.jar:/home1/opt/cloudera/parcels/CDH-5.13.0-1.cdh5.13.0.p0.29/jars/mockito-all-1.8.5.jar:/home1/opt/cloudera/parcels/CDH-5.13.0-1.cdh5.13.0.p0.29/jars/netty-3.10.5.Final.jar:/home1/opt/cloudera/parcels/CDH-5.13.0-1.cdh5.13.0.p0.29/jars/okhttp-2.4.0.jar:/home1/opt/cloudera/parcels/CDH-5.13.0-1.cdh5.13.0.p0.29/jars/okio-1.4.0.jar:/home1/opt/cloudera/parcels/CDH-5.13.0-1.cdh5.13.0.p0.29/jars/paranamer-2.3.jar:/home1/opt/cloudera/parcels/CDH-5.13.0-1.cdh5.13.0.p0.29/jars/protobuf-java-2.5.0.jar:/home1/opt/cloudera/parcels/CDH-5.13.0-1.cdh5.13.0.p0.29/jars/slf4j-api-1.7.5.jar:/home1/opt/cloudera/parcels/CDH-5.13.0-1.cdh5.13.0.p0.29/jars/slf4j-log4j12-1.7.5.jar:/home1/opt/cloudera/parcels/CDH-5.13.0-1.cdh5.13.0.p0.29/jars/snappy-java-1.0.4.1.jar:/home1/opt/cloudera/parcels/CDH-5.13.0-1.cdh5.13.0.p0.29/jars/spark-1.6.0-cdh5.13.0-yarn-shuffle.jar:/home1/opt/cloudera/parcels/CDH-5.13.0-1.cdh5.13.0.p0.29/jars/stax-api-1.0-2.jar:/home1/opt/cloudera/parcels/CDH-5.13.0-1.cdh5.13.0.p0.29/jars/xercesImpl-2.9.1.jar:/home1/opt/cloudera/parcels/CDH-5.13.0-1.cdh5.13.0.p0.29/jars/xml-apis-1.3.04.jar:/home1/opt/cloudera/parcels/CDH-5.13.0-1.cdh5.13.0.p0.29/jars/xmlenc-0.52.jar:/home1/opt/cloudera/parcels/CDH-5.13.0-1.cdh5.13.0.p0.29/jars/zookeeper-3.4.5-cdh5.13.0.jar:/home1/opt/cloudera/parcels/CDH-5.13.0-1.cdh5.13.0.p0.29/lib/hadoop/LICENSE.txt:/home1/opt/cloudera/parcels/CDH-5.13.0-1.cdh5.13.0.p0.29/lib/hadoop/NOTICE.txt:/home1/opt/cloudera/parcels/CDH-5.13.0-1.cdh5.13.0.p0.29/lib/hadoop/lib/jsp-api-2.1.jar:/home1/opt/cloudera/parcels/GPLEXTRAS-5.13.0-1.cdh5.13.0.p0.29/lib/hadoop/lib/COPYING.hadoop-lzo:/home1/opt/cloudera/parcels/GPLEXTRAS-5.13.0-1.cdh5.13.0.p0.29/lib/hadoop/lib/hadoop-lzo-0.4.15-cdh5.13.0.jar 14 SPARK_EXTRA_LIB_PATH:null 15 LD_LIBRARY_PATH::/home1/opt/cloudera/parcels/CDH-5.13.0-1.cdh5.13.0.p0.29/lib/hadoop/lib/native:/home1/opt/cloudera/parcels/GPLEXTRAS-5.13.0-1.cdh5.13.0.p0.29/lib/hadoop/lib/native 16 Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties 17 19/01/10 22:30:26 WARN SparkConf: The configuration key 'spark.yarn.executor.memoryOverhead' has been deprecated as of Spark 2.3 and may be removed in the future. Please use the new key 'spark.executor.memoryOverhead' instead. 18 19/01/10 22:30:27 INFO TestSubmit: 提交任务,任务名称:test yarn submit app 19 19/01/10 22:30:27 INFO RMProxy: Connecting to ResourceManager at /0.0.0.0:8032 20 19/01/10 22:30:29 INFO Client: Requesting a new application from cluster with 6 NodeManagers 21 19/01/10 22:30:29 INFO Client: Verifying our application has not requested more than the maximum memory capability of the cluster (30282 MB per container) 22 19/01/10 22:30:29 INFO Client: Will allocate AM container, with 3456 MB memory including 384 MB overhead 23 19/01/10 22:30:29 INFO Client: Setting up container launch context for our AM 24 19/01/10 22:30:29 INFO Client: Setting up the launch environment for our AM container 25 19/01/10 22:30:29 INFO Client: Preparing resources for our AM container 26 19/01/10 22:30:34 WARN Client: Neither spark.yarn.jars nor spark.yarn.archive is set, falling back to uploading libraries under SPARK_HOME. 27 19/01/10 22:30:36 INFO Client: Uploading resource file:/tmp/spark-03699598-b859-4a74-a65f-bc63e9fae733/__spark_libs__4116956896087694051.zip -> hdfs://vm192.168.0.141.com.cn:8020/user/.sparkStaging/application_1543820999543_0236/__spark_libs__4116956896087694051.zip 28 19/01/10 22:30:43 INFO Client: Uploading resource file:/home1/zhangsan/mrs-streaming-driver.jar -> hdfs://vm192.168.0.141.com.cn:8020/user/.sparkStaging/application_1543820999543_0236/mrs-streaming-driver.jar 29 19/01/10 22:31:33 INFO Client: Uploading resource file:/home1/zhangsan/sparkjars/elasticsearch-cli-6.4.2.jar -> hdfs://vm192.168.0.141.com.cn:8020/user/.sparkStaging/application_1543820999543_0236/elasticsearch-cli-6.4.2.jar 30 19/01/10 22:31:33 INFO Client: Uploading resource file:/home1/zhangsan/sparkjars/elasticsearch-6.4.2.jar -> hdfs://vm192.168.0.141.com.cn:8020/user/.sparkStaging/application_1543820999543_0236/elasticsearch-6.4.2.jar 31 ...... 32 19/01/10 22:31:33 INFO Client: Uploading resource file:/tmp/spark-03699598-b859-4a74-a65f-bc63e9fae733/__spark_conf__339930271770719398.zip -> hdfs://vm192.168.0.141.com.cn:8020/user/.sparkStaging/application_1543820999543_0236/__spark_conf__.zip 33 19/01/10 22:31:34 INFO SecurityManager: Changing view acls to: zhangsan 34 19/01/10 22:31:34 INFO SecurityManager: Changing modify acls to: zhangsan 35 19/01/10 22:31:34 INFO SecurityManager: Changing view acls groups to: 36 19/01/10 22:31:34 INFO SecurityManager: Changing modify acls groups to: 37 19/01/10 22:31:34 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(zhangsan); groups with view permissions: Set(); users with modify permissions: Set(zhangsan); groups with modify permissions: Set() 38 19/01/10 22:31:34 INFO Client: Submitting application application_1543820999543_0236 to ResourceManager 39 19/01/10 22:31:34 INFO YarnClientImpl: Submitted application application_1543820999543_0236 40 application id is application_1543820999543_0236 41 Complete .... 42 19/01/10 22:31:34 INFO ShutdownHookManager: Shutdown hook called 43 19/01/10 22:31:34 INFO ShutdownHookManager: Deleting directory /tmp/spark-03699598-b859-4a74-a65f-bc63e9fae733 44 bash-4.1$
目前调试通之后,测试通过yarn的cluster方式,client模式下任务提交到yarn上去无响应。
spark任务状态:
任务状态封装类
1 public class SparkTaskState{ 2 private String appId; 3 private String state; 4 private float progress; 5 private String finalStatus; 6 7 public String getAppId() { 8 return appId; 9 } 10 public void setAppId(String appId) { 11 this.appId = appId; 12 } 13 14 public String getState() { 15 return state; 16 } 17 public void setState(String state) { 18 this.state = state; 19 } 20 21 public float getProgress() { 22 return progress; 23 } 24 public void setProgress(float progress) { 25 this.progress = progress; 26 } 27 28 public String getFinalStatus() { 29 return finalStatus; 30 } 31 public void setFinalStatus(String finalStatus) { 32 this.finalStatus = finalStatus; 33 } 34 }
/** * 获取spark任务状态 * * @param yarnResourcemanagerAddress * yarn资源管理器地址, 例如:master:8032,查看yarn集群获取具体地址 * @param appIdStr * 需要取消的任务id */ public static SparkTaskState getStatus(String yarnResourcemanagerAddress, String appIdStr) { logger.info("获取任务状态启动,任务id:" + appIdStr); // 初始化 yarn的配置 Configuration cf = new Configuration(); boolean cross_platform = false; String os = System.getProperty("os.name"); if (os.contains("Windows")) { cross_platform = true; } cf.setBoolean("mapreduce.app-submission.cross-platform", cross_platform);// 配置使用跨平台提交任务 // 设置yarn资源,不然会使用localhost:8032 cf.set("yarn.resourcemanager.address", yarnResourcemanagerAddress); logger.info("获取任务状态,任务id:" + appIdStr); SparkTaskState taskState = new SparkTaskState(); // 设置任务id taskState.setAppId(appIdStr); YarnClient yarnClient = YarnClient.createYarnClient(); // 初始化yarn的客户端 yarnClient.init(cf); // yarn客户端启动 yarnClient.start(); ApplicationReport report = null; try { report = yarnClient.getApplicationReport(getAppId(appIdStr)); } catch (Exception e) { logger.error("获取spark任务状态失败"); } if (report != null) { YarnApplicationState state = report.getYarnApplicationState(); taskState.setState(state.name()); // 任务执行进度 float progress = report.getProgress(); taskState.setProgress(progress); // 最终状态 FinalApplicationStatus status = report.getFinalApplicationStatus(); taskState.setFinalStatus(status.name()); } else { taskState.setState("failed"); taskState.setProgress(0.0f); taskState.setFinalStatus("failed"); } // 关闭yarn客户端 yarnClient.stop(); logger.info("获取任务状态结束,任务状态:" + JSON.toJSONString(taskState)); return taskState; } private static ApplicationId getAppId(String appIdStr) { return ConverterUtils.toApplicationId(appIdStr); }
spark日志跟踪:
请参考《https://www.cnblogs.com/lyy-blog/p/9635601.html》
spark关闭任务:
/** * 停止spark任务 * * @param yarnResourcemanagerAddress * yarn资源管理器地址, 例如:master:8032,查看yarn集群获取具体地址 * @param appIdStr * 需要取消的任务id */ public static void killJob(String yarnResourcemanagerAddress, String appIdStr) { logger.info("取消spark任务,任务id:" + appIdStr); // 初始化 yarn的配置 Configuration cf = new Configuration(); boolean cross_platform = false; String os = System.getProperty("os.name"); if (os.contains("Windows")) { cross_platform = true; } // 配置使用跨平台提交任务 cf.setBoolean("mapreduce.app-submission.cross-platform", cross_platform); // 设置yarn资源,不然会使用localhost:8032 cf.set("yarn.resourcemanager.address", yarnResourcemanagerAddress); // 创建yarn的客户端,此类中有杀死任务的方法 YarnClient yarnClient = YarnClient.createYarnClient(); // 初始化yarn的客户端 yarnClient.init(cf); // yarn客户端启动 yarnClient.start(); try { // 根据应用id,杀死应用 yarnClient.killApplication(getAppId(appIdStr)); } catch (Exception e) { logger.error("取消spark任务失败", e); } // 关闭yarn客户端 yarnClient.stop(); }
参考文章:https://blog.csdn.net/weixin_36647532/article/details/80766350