如何搭建配置centos虚拟机请参考《Kafka:ZK+Kafka+Spark Streaming集群环境搭建(一)VMW安装四台CentOS,并实现本机与它们能交互,虚拟机内部实现可以上网。》
如何安装hadoop2.9.0请参考《Kafka:ZK+Kafka+Spark Streaming集群环境搭建(二)安装hadoop2.9.0》
如何配置hadoop2.9.0 HA 请参考《Kafka:ZK+Kafka+Spark Streaming集群环境搭建(十)安装hadoop2.9.0搭建HA》
安装spark的服务器:
192.168.0.120 master 192.168.0.121 slave1 192.168.0.122 slave2 192.168.0.123 slave3
从spark官网下载spark安装包:
官网地址:http://spark.apache.org/downloads.html
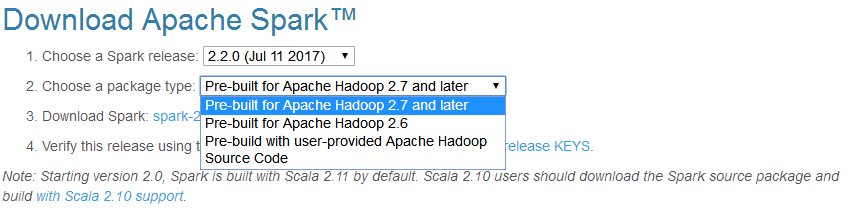
注意:上一篇文章中我们安装了hadoop2.9.0,但是这里没有发现待下载spark对应的hadoop版本可选项中发现hadoop2.9.0,因此也只能选择“Pre-built for Apache Hadoop 2.7 and later”。

这spark可选版本比较多,就选择“2.2.1(Dec 01 2017)”。
选中后,此时带下来的spark安装包版本信息为:

下载“spark-2.2.1-bin-hadoop2.7.tgz”,上传到master的/opt目录下,并解压:
[root@master opt]# tar -zxvf spark-2.2.1-bin-hadoop2.7.tgz [root@master opt]# ls hadoop-2.9.0 hadoop-2.9.0.tar.gz jdk1.8.0_171 jdk-8u171-linux-x64.tar.gz scala-2.11.0 scala-2.11.0.tgz spark-2.2.1-bin-hadoop2.7 spark-2.2.1-bin-hadoop2.7.tgz [root@master opt]#
配置Spark
[root@master opt]# ls hadoop-2.9.0 hadoop-2.9.0.tar.gz jdk1.8.0_171 jdk-8u171-linux-x64.tar.gz scala-2.11.0 scala-2.11.0.tgz spark-2.2.1-bin-hadoop2.7 spark-2.2.1-bin-hadoop2.7.tgz [root@master opt]# cd spark-2.2.1-bin-hadoop2.7/conf/ [root@master conf]# ls docker.properties.template metrics.properties.template spark-env.sh.template fairscheduler.xml.template slaves.template log4j.properties.template spark-defaults.conf.template [root@master conf]# scp spark-env.sh.template spark-env.sh [root@master conf]# ls docker.properties.template metrics.properties.template spark-env.sh fairscheduler.xml.template slaves.template spark-env.sh.template log4j.properties.template spark-defaults.conf.template [root@master conf]# vi spark-env.sh
在spark-env.sh末尾添加以下内容(这是我的配置,你需要根据自己安装的环境情况自行修改):
export SCALA_HOME=/opt/scala-2.11.0
export JAVA_HOME=/opt/jdk1.8.0_171
export HADOOP_HOME=/opt/hadoop-2.9.0
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
SPARK_MASTER_IP=master
SPARK_LOCAL_DIRS=/opt/spark-2.2.1-bin-hadoop2.7
SPARK_DRIVER_MEMORY=1G
注:在设置Worker进程的CPU个数和内存大小,要注意机器的实际硬件条件,如果配置的超过当前Worker节点的硬件条件,Worker进程会启动失败。
vi slaves在slaves文件下填上slave主机名:
[root@master conf]# scp slaves.template slaves [root@master conf]# vi slaves
配置内容为:
#localhost
slave1
slave2
slave3
将配置好的spark-2.2.1-bin-hadoop2.7文件夹分发给所有slaves吧
scp -r /opt/spark-2.2.1-bin-hadoop2.7 spark@slave1:/opt/ scp -r /opt/spark-2.2.1-bin-hadoop2.7 spark@slave2:/opt/ scp -r /opt/spark-2.2.1-bin-hadoop2.7 spark@slave3:/opt/
注意:此时默认slave1,slave2,slave3上是没有/opt/spark-2.2.1-bin-hadoop2.7,因此直接拷贝可能会出现无权限操作 。
解决方案,分别在slave1,slave2,slave3的/opt下创建spark-2.2.1-bin-hadoop2.7,并分配777权限。
[root@slave1 opt]# mkdir spark-2.2.1-bin-hadoop2.7 [root@slave1 opt]# chmod 777 spark-2.2.1-bin-hadoop2.7 [root@slave1 opt]#
之后,再次操作拷贝就有权限操作了。
启动Spark
在spark安装目录下执行下面命令才行 , 目前的master安装目录在/opt/spark-2.2.1-bin-hadoop2.7
sbin/start-all.sh
此时,我使用非root账户(spark用户名的用户)启动spark,出现master上spark无权限写日志的问题:
[spark@master opt]$ cd /opt/spark-2.2.1-bin-hadoop2.7 [spark@master spark-2.2.1-bin-hadoop2.7]$ sbin/start-all.sh mkdir: cannot create directory ‘/opt/spark-2.2.1-bin-hadoop2.7/logs’: Permission denied chown: cannot access ‘/opt/spark-2.2.1-bin-hadoop2.7/logs’: No such file or directory starting org.apache.spark.deploy.master.Master, logging to /opt/spark-2.2.1-bin-hadoop2.7/logs/spark-spark-org.apache.spark.deploy.master.Master-1-master.out /opt/spark-2.2.1-bin-hadoop2.7/sbin/spark-daemon.sh: line 128: /opt/spark-2.2.1-bin-hadoop2.7/logs/spark-spark-org.apache.spark.deploy.master.Master-1-master.out: No such file or directory failed to launch: nice -n 0 /opt/spark-2.2.1-bin-hadoop2.7/bin/spark-class org.apache.spark.deploy.master.Master --host master --port 7077 --webui-port 8080 tail: cannot open ‘/opt/spark-2.2.1-bin-hadoop2.7/logs/spark-spark-org.apache.spark.deploy.master.Master-1-master.out’ for reading: No such file or directory full log in /opt/spark-2.2.1-bin-hadoop2.7/logs/spark-spark-org.apache.spark.deploy.master.Master-1-master.out slave1: starting org.apache.spark.deploy.worker.Worker, logging to /opt/spark-2.2.1-bin-hadoop2.7/logs/spark-spark-org.apache.spark.deploy.worker.Worker-1-slave1.out slave3: starting org.apache.spark.deploy.worker.Worker, logging to /opt/spark-2.2.1-bin-hadoop2.7/logs/spark-spark-org.apache.spark.deploy.worker.Worker-1-slave3.out slave2: starting org.apache.spark.deploy.worker.Worker, logging to /opt/spark-2.2.1-bin-hadoop2.7/logs/spark-spark-org.apache.spark.deploy.worker.Worker-1-slave2.out [spark@master spark-2.2.1-bin-hadoop2.7]$ cd .. [spark@master opt]$ su root Password: [root@master opt]# chmod 777 spark-2.2.1-bin-hadoop2.7 [root@master opt]# su spark [spark@master opt]$ cd spark-2.2.1-bin-hadoop2.7 [spark@master spark-2.2.1-bin-hadoop2.7]$ sbin/start-all.sh starting org.apache.spark.deploy.master.Master, logging to /opt/spark-2.2.1-bin-hadoop2.7/logs/spark-spark-org.apache.spark.deploy.master.Master-1-master.out slave2: org.apache.spark.deploy.worker.Worker running as process 3153. Stop it first. slave3: org.apache.spark.deploy.worker.Worker running as process 3076. Stop it first. slave1: org.apache.spark.deploy.worker.Worker running as process 3241. Stop it first. [spark@master spark-2.2.1-bin-hadoop2.7]$ sbin/stop-all.sh slave1: stopping org.apache.spark.deploy.worker.Worker slave3: stopping org.apache.spark.deploy.worker.Worker slave2: stopping org.apache.spark.deploy.worker.Worker stopping org.apache.spark.deploy.master.Master [spark@master spark-2.2.1-bin-hadoop2.7]$ sbin/start-all.sh starting org.apache.spark.deploy.master.Master, logging to /opt/spark-2.2.1-bin-hadoop2.7/logs/spark-spark-org.apache.spark.deploy.master.Master-1-master.out slave1: starting org.apache.spark.deploy.worker.Worker, logging to /opt/spark-2.2.1-bin-hadoop2.7/logs/spark-spark-org.apache.spark.deploy.worker.Worker-1-slave1.out slave3: starting org.apache.spark.deploy.worker.Worker, logging to /opt/spark-2.2.1-bin-hadoop2.7/logs/spark-spark-org.apache.spark.deploy.worker.Worker-1-slave3.out slave2: starting org.apache.spark.deploy.worker.Worker, logging to /opt/spark-2.2.1-bin-hadoop2.7/logs/spark-spark-org.apache.spark.deploy.worker.Worker-1-slave2.out
解决方案:给master的spark安装目录也分配777操作权限。
验证 Spark 是否安装成功
启动过程发现问题:
1)以spark on yarn方式运行spark-shell抛出异常:ERROR cluster.YarnSchedulerBackend$YarnSchedulerEndpoint: Sending RequestExecutors(0,0,Map(),Set()) to AM was unsuccessful:解决方案参考《Kafka:ZK+Kafka+Spark Streaming集群环境搭建(六)针对spark2.2.1以yarn方式启动spark-shell抛出异常:ERROR cluster.YarnSchedulerBackend$YarnSchedulerEndpoint: Sending RequestExecutors(0,0,Map(),Set()) to AM was unsuccessful》
用jps检查,在 master 上正常启动包含以下几个进程:
$ jps 7949 Jps 7328 SecondaryNameNode 7805 Master 7137 NameNode 7475 ResourceManager
在 slave 上正常启动包含以下几个进程:
$jps 3132 DataNode 3759 Worker 3858 Jps 3231 NodeManager
进入Spark的Web管理页面: http://192.168.0.120:8080

运行示例
本地方式两线程运行测试:
[spark@master spark-2.2.1-bin-hadoop2.7]$ cd /opt/spark-2.2.1-bin-hadoop2.7 [spark@master spark-2.2.1-bin-hadoop2.7]$ ./bin/run-example SparkPi 10 --master local[2]

Spark Standalone 集群模式运行
[spark@master spark-2.2.1-bin-hadoop2.7]$ cd /opt/spark-2.2.1-bin-hadoop2.7 [spark@master spark-2.2.1-bin-hadoop2.7]$ ./bin/spark-submit > --class org.apache.spark.examples.SparkPi > --master spark://master:7077 > examples/jars/spark-examples_2.11-2.2.1.jar > 100
此时是可以从spark监控界面查看到运行状况:

Spark on YARN 集群上 yarn-cluster 模式运行
[spark@master spark-2.2.1-bin-hadoop2.7]$ cd /opt/spark-2.2.1-bin-hadoop2.7 [spark@master spark-2.2.1-bin-hadoop2.7]$ ./bin/spark-submit > --class org.apache.spark.examples.SparkPi > --master yarn-cluster > /opt/spark-2.2.1-bin-hadoop2.7/examples/jars/spark-examples_2.11-2.2.1.jar > 10
执行日志信息:
[spark@master hadoop-2.9.0]$ cd /opt/spark-2.2.1-bin-hadoop2.7 [spark@master spark-2.2.1-bin-hadoop2.7]$ ./bin/spark-submit > --class org.apache.spark.examples.SparkPi > --master yarn-cluster > /opt/spark-2.2.1-bin-hadoop2.7/examples/jars/spark-examples_2.11-2.2.1.jar > 10 Warning: Master yarn-cluster is deprecated since 2.0. Please use master "yarn" with specified deploy mode instead. 18/06/30 22:55:37 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable 18/06/30 22:55:37 INFO client.RMProxy: Connecting to ResourceManager at master/192.168.0.120:8032 18/06/30 22:55:38 INFO yarn.Client: Requesting a new application from cluster with 3 NodeManagers 18/06/30 22:55:38 INFO yarn.Client: Verifying our application has not requested more than the maximum memory capability of the cluster (2048 MB per container) 18/06/30 22:55:38 INFO yarn.Client: Will allocate AM container, with 1408 MB memory including 384 MB overhead 18/06/30 22:55:38 INFO yarn.Client: Setting up container launch context for our AM 18/06/30 22:55:38 INFO yarn.Client: Setting up the launch environment for our AM container 18/06/30 22:55:38 INFO yarn.Client: Preparing resources for our AM container 18/06/30 22:55:40 WARN yarn.Client: Neither spark.yarn.jars nor spark.yarn.archive is set, falling back to uploading libraries under SPARK_HOME. 18/06/30 22:55:47 INFO yarn.Client: Uploading resource file:/opt/spark-2.2.1-bin-hadoop2.7/spark-f46b4dc7-8074-4bb3-babd-c3124d1a7e07/__spark_libs__1523582418834894726.zip -> hdfs://master:9000/user/spark/.sparkStaging/application_1530369937777_0001/__spark_libs__1523582418834894726.zip 18/06/30 22:56:02 INFO yarn.Client: Uploading resource file:/opt/spark-2.2.1-bin-hadoop2.7/examples/jars/spark-examples_2.11-2.2.1.jar -> hdfs://master:9000/user/spark/.sparkStaging/application_1530369937777_0001/spark-examples_2.11-2.2.1.jar 18/06/30 22:56:02 INFO yarn.Client: Uploading resource file:/opt/spark-2.2.1-bin-hadoop2.7/spark-f46b4dc7-8074-4bb3-babd-c3124d1a7e07/__spark_conf__4967231916988729566.zip -> hdfs://master:9000/user/spark/.sparkStaging/application_1530369937777_0001/__spark_conf__.zip 18/06/30 22:56:02 INFO spark.SecurityManager: Changing view acls to: spark 18/06/30 22:56:02 INFO spark.SecurityManager: Changing modify acls to: spark 18/06/30 22:56:02 INFO spark.SecurityManager: Changing view acls groups to: 18/06/30 22:56:02 INFO spark.SecurityManager: Changing modify acls groups to: 18/06/30 22:56:02 INFO spark.SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(spark); groups with view permissions: Set(); users with modify permissions: Set(spark); groups with modify permissions: Set() 18/06/30 22:56:02 INFO yarn.Client: Submitting application application_1530369937777_0001 to ResourceManager 18/06/30 22:56:02 INFO impl.YarnClientImpl: Submitted application application_1530369937777_0001 18/06/30 22:56:03 INFO yarn.Client: Application report for application_1530369937777_0001 (state: ACCEPTED) 18/06/30 22:56:03 INFO yarn.Client: client token: N/A diagnostics: AM container is launched, waiting for AM container to Register with RM ApplicationMaster host: N/A ApplicationMaster RPC port: -1 queue: default start time: 1530370563128 final status: UNDEFINED tracking URL: http://master:8088/proxy/application_1530369937777_0001/ user: spark 18/06/30 22:56:04 INFO yarn.Client: Application report for application_1530369937777_0001 (state: ACCEPTED) 18/06/30 22:56:05 INFO yarn.Client: Application report for application_1530369937777_0001 (state: ACCEPTED) 18/06/30 22:56:06 INFO yarn.Client: Application report for application_1530369937777_0001 (state: ACCEPTED) 18/06/30 22:56:07 INFO yarn.Client: Application report for application_1530369937777_0001 (state: ACCEPTED) 18/06/30 22:56:08 INFO yarn.Client: Application report for application_1530369937777_0001 (state: ACCEPTED) 18/06/30 22:56:09 INFO yarn.Client: Application report for application_1530369937777_0001 (state: ACCEPTED) 18/06/30 22:56:10 INFO yarn.Client: Application report for application_1530369937777_0001 (state: ACCEPTED) 18/06/30 22:56:11 INFO yarn.Client: Application report for application_1530369937777_0001 (state: ACCEPTED) 18/06/30 22:56:12 INFO yarn.Client: Application report for application_1530369937777_0001 (state: ACCEPTED) 18/06/30 22:56:13 INFO yarn.Client: Application report for application_1530369937777_0001 (state: ACCEPTED) 18/06/30 22:56:14 INFO yarn.Client: Application report for application_1530369937777_0001 (state: ACCEPTED) 18/06/30 22:56:15 INFO yarn.Client: Application report for application_1530369937777_0001 (state: ACCEPTED) 18/06/30 22:56:16 INFO yarn.Client: Application report for application_1530369937777_0001 (state: ACCEPTED) 18/06/30 22:56:17 INFO yarn.Client: Application report for application_1530369937777_0001 (state: ACCEPTED) 18/06/30 22:56:18 INFO yarn.Client: Application report for application_1530369937777_0001 (state: ACCEPTED) 18/06/30 22:56:19 INFO yarn.Client: Application report for application_1530369937777_0001 (state: ACCEPTED) 18/06/30 22:56:20 INFO yarn.Client: Application report for application_1530369937777_0001 (state: ACCEPTED) 18/06/30 22:56:22 INFO yarn.Client: Application report for application_1530369937777_0001 (state: RUNNING) 18/06/30 22:56:22 INFO yarn.Client: client token: N/A diagnostics: N/A ApplicationMaster host: 192.168.0.121 ApplicationMaster RPC port: 0 queue: default start time: 1530370563128 final status: UNDEFINED tracking URL: http://master:8088/proxy/application_1530369937777_0001/ user: spark 18/06/30 22:56:23 INFO yarn.Client: Application report for application_1530369937777_0001 (state: RUNNING) 18/06/30 22:56:24 INFO yarn.Client: Application report for application_1530369937777_0001 (state: RUNNING) 18/06/30 22:56:25 INFO yarn.Client: Application report for application_1530369937777_0001 (state: RUNNING) 18/06/30 22:56:26 INFO yarn.Client: Application report for application_1530369937777_0001 (state: RUNNING) 18/06/30 22:56:27 INFO yarn.Client: Application report for application_1530369937777_0001 (state: RUNNING) 18/06/30 22:56:29 INFO yarn.Client: Application report for application_1530369937777_0001 (state: RUNNING) 18/06/30 22:56:30 INFO yarn.Client: Application report for application_1530369937777_0001 (state: RUNNING) 18/06/30 22:56:31 INFO yarn.Client: Application report for application_1530369937777_0001 (state: RUNNING) 18/06/30 22:56:32 INFO yarn.Client: Application report for application_1530369937777_0001 (state: RUNNING) 18/06/30 22:56:33 INFO yarn.Client: Application report for application_1530369937777_0001 (state: RUNNING) 18/06/30 22:56:34 INFO yarn.Client: Application report for application_1530369937777_0001 (state: RUNNING) 18/06/30 22:56:35 INFO yarn.Client: Application report for application_1530369937777_0001 (state: RUNNING) 18/06/30 22:56:36 INFO yarn.Client: Application report for application_1530369937777_0001 (state: RUNNING) 18/06/30 22:56:37 INFO yarn.Client: Application report for application_1530369937777_0001 (state: RUNNING) 18/06/30 22:56:38 INFO yarn.Client: Application report for application_1530369937777_0001 (state: RUNNING) 18/06/30 22:56:39 INFO yarn.Client: Application report for application_1530369937777_0001 (state: RUNNING) 18/06/30 22:56:40 INFO yarn.Client: Application report for application_1530369937777_0001 (state: RUNNING) 18/06/30 22:56:41 INFO yarn.Client: Application report for application_1530369937777_0001 (state: RUNNING) 18/06/30 22:56:42 INFO yarn.Client: Application report for application_1530369937777_0001 (state: RUNNING) 18/06/30 22:56:43 INFO yarn.Client: Application report for application_1530369937777_0001 (state: RUNNING) 18/06/30 22:56:45 INFO yarn.Client: Application report for application_1530369937777_0001 (state: RUNNING) 18/06/30 22:56:46 INFO yarn.Client: Application report for application_1530369937777_0001 (state: RUNNING) 18/06/30 22:56:47 INFO yarn.Client: Application report for application_1530369937777_0001 (state: RUNNING) 18/06/30 22:56:48 INFO yarn.Client: Application report for application_1530369937777_0001 (state: RUNNING) 18/06/30 22:56:49 INFO yarn.Client: Application report for application_1530369937777_0001 (state: RUNNING) 18/06/30 22:56:50 INFO yarn.Client: Application report for application_1530369937777_0001 (state: RUNNING) 18/06/30 22:56:51 INFO yarn.Client: Application report for application_1530369937777_0001 (state: RUNNING) 18/06/30 22:56:52 INFO yarn.Client: Application report for application_1530369937777_0001 (state: RUNNING) 18/06/30 22:56:53 INFO yarn.Client: Application report for application_1530369937777_0001 (state: RUNNING) 18/06/30 22:56:54 INFO yarn.Client: Application report for application_1530369937777_0001 (state: RUNNING) 18/06/30 22:56:55 INFO yarn.Client: Application report for application_1530369937777_0001 (state: RUNNING) 18/06/30 22:56:56 INFO yarn.Client: Application report for application_1530369937777_0001 (state: RUNNING) 18/06/30 22:56:57 INFO yarn.Client: Application report for application_1530369937777_0001 (state: RUNNING) 18/06/30 22:56:58 INFO yarn.Client: Application report for application_1530369937777_0001 (state: RUNNING) 18/06/30 22:56:59 INFO yarn.Client: Application report for application_1530369937777_0001 (state: RUNNING) 18/06/30 22:57:00 INFO yarn.Client: Application report for application_1530369937777_0001 (state: RUNNING) 18/06/30 22:57:01 INFO yarn.Client: Application report for application_1530369937777_0001 (state: FINISHED) 18/06/30 22:57:01 INFO yarn.Client: client token: N/A diagnostics: N/A ApplicationMaster host: 192.168.0.121 ApplicationMaster RPC port: 0 queue: default start time: 1530370563128 final status: SUCCEEDED tracking URL: http://master:8088/proxy/application_1530369937777_0001/ user: spark 18/06/30 22:57:01 INFO util.ShutdownHookManager: Shutdown hook called 18/06/30 22:57:01 INFO util.ShutdownHookManager: Deleting directory /opt/spark-2.2.1-bin-hadoop2.7/spark-f46b4dc7-8074-4bb3-babd-c3124d1a7e07
从hadoop yarn监控界面查看执行任务:

另外也可以进入http://slave1:8042查看slave1的信息:

注意:Spark on YARN 支持两种运行模式,分别为yarn-cluster和yarn-client,具体的区别可以看这篇博文,从广义上讲,yarn-cluster适用于生产环境;而yarn-client适用于交互和调试,也就是希望快速地看到application的输出。