flatMapGroupsWithState的出现解决了什么问题:
flatMapGroupsWithState的出现在spark structured streaming原因(从spark.2.2.0开始才开始支持):
1)可以实现agg函数;
2)就目前最新spark2.3.2版本来说在spark structured streming中依然不支持对dataset多次agg操作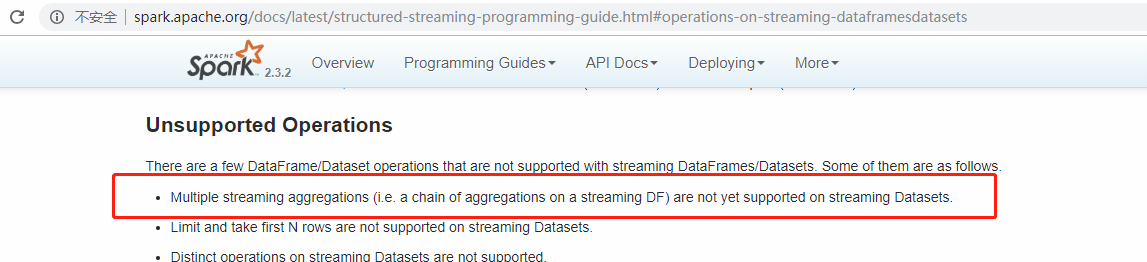
,而flatMapGroupsWithState可以替代agg的作用,同时它允许在sink为append模式下在agg之前使用。
注意:尽管允许agg之前使用,但前提是:输出(sink)方式Append方式。

flatMapGroupsWithState的使用示例(从网上找到):
参考:《https://jaceklaskowski.gitbooks.io/spark-structured-streaming/spark-sql-streaming-KeyValueGroupedDataset-flatMapGroupsWithState.html》
说明:以下示例代码实现了“select deviceId,count(0) as count from tbName group by deviceId.”。
1)spark2.3.0版本下定义一个Signal实体类:
scala> spark.version res0: String = 2.3.0-SNAPSHOT import java.sql.Timestamp type DeviceId = Int case class Signal(timestamp: java.sql.Timestamp, value: Long, deviceId: DeviceId)
2)使用Rate source方式生成一些测试数据(随机实时流方式),并查看执行计划:
// input stream import org.apache.spark.sql.functions._ val signals = spark. readStream. format("rate"). option("rowsPerSecond", 1). load. withColumn("value", $"value" % 10). // <-- randomize the values (just for fun) withColumn("deviceId", rint(rand() * 10) cast "int"). // <-- 10 devices randomly assigned to values as[Signal] // <-- convert to our type (from "unpleasant" Row) scala> signals.explain == Physical Plan == *Project [timestamp#0, (value#1L % 10) AS value#5L, cast(ROUND((rand(4440296395341152993) * 10.0)) as int) AS deviceId#9] +- StreamingRelation rate, [timestamp#0, value#1L]
3)对Rate source流对象进行groupBy,使用flatMapGroupsWithState实现agg
// stream processing using flatMapGroupsWithState operator val device: Signal => DeviceId = { case Signal(_, _, deviceId) => deviceId } val signalsByDevice = signals.groupByKey(device) import org.apache.spark.sql.streaming.GroupState type Key = Int type Count = Long type State = Map[Key, Count] case class EventsCounted(deviceId: DeviceId, count: Long) def countValuesPerKey(deviceId: Int, signalsPerDevice: Iterator[Signal], state: GroupState[State]): Iterator[EventsCounted] = { val values = signalsPerDevice.toList println(s"Device: $deviceId") println(s"Signals (${values.size}):") values.zipWithIndex.foreach { case (v, idx) => println(s"$idx. $v") } println(s"State: $state") // update the state with the count of elements for the key val initialState: State = Map(deviceId -> 0) val oldState = state.getOption.getOrElse(initialState) // the name to highlight that the state is for the key only val newValue = oldState(deviceId) + values.size val newState = Map(deviceId -> newValue) state.update(newState) // you must not return as it's already consumed // that leads to a very subtle error where no elements are in an iterator // iterators are one-pass data structures Iterator(EventsCounted(deviceId, newValue)) } import org.apache.spark.sql.streaming.{GroupStateTimeout, OutputMode} val signalCounter = signalsByDevice.flatMapGroupsWithState( outputMode = OutputMode.Append, timeoutConf = GroupStateTimeout.NoTimeout)(func = countValuesPerKey)
4)使用Console Sink方式打印agg结果:
import org.apache.spark.sql.streaming.{OutputMode, Trigger} import scala.concurrent.duration._ val sq = signalCounter. writeStream. format("console"). option("truncate", false). trigger(Trigger.ProcessingTime(10.seconds)). outputMode(OutputMode.Append). start
5)console print
... ------------------------------------------- Batch: 0 ------------------------------------------- +--------+-----+ |deviceId|count| +--------+-----+ +--------+-----+ ... 17/08/21 08:57:29 INFO StreamExecution: Streaming query made progress: { "id" : "a43822a6-500b-4f02-9133-53e9d39eedbf", "runId" : "79cb037e-0f28-4faf-a03e-2572b4301afe", "name" : null, "timestamp" : "2017-08-21T06:57:26.719Z", "batchId" : 0, "numInputRows" : 0, "processedRowsPerSecond" : 0.0, "durationMs" : { "addBatch" : 2404, "getBatch" : 22, "getOffset" : 0, "queryPlanning" : 141, "triggerExecution" : 2626, "walCommit" : 41 }, "stateOperators" : [ { "numRowsTotal" : 0, "numRowsUpdated" : 0, "memoryUsedBytes" : 12599 } ], "sources" : [ { "description" : "RateSource[rowsPerSecond=1, rampUpTimeSeconds=0, numPartitions=8]", "startOffset" : null, "endOffset" : 0, "numInputRows" : 0, "processedRowsPerSecond" : 0.0 } ], "sink" : { "description" : "ConsoleSink[numRows=20, truncate=false]" } } 17/08/21 08:57:29 DEBUG StreamExecution: batch 0 committed ... ------------------------------------------- Batch: 1 ------------------------------------------- Device: 3 Signals (1): 0. Signal(2017-08-21 08:57:27.682,1,3) State: GroupState(<undefined>) Device: 8 Signals (1): 0. Signal(2017-08-21 08:57:26.682,0,8) State: GroupState(<undefined>) Device: 7 Signals (1): 0. Signal(2017-08-21 08:57:28.682,2,7) State: GroupState(<undefined>) +--------+-----+ |deviceId|count| +--------+-----+ |3 |1 | |8 |1 | |7 |1 | +--------+-----+ ... 17/08/21 08:57:31 INFO StreamExecution: Streaming query made progress: { "id" : "a43822a6-500b-4f02-9133-53e9d39eedbf", "runId" : "79cb037e-0f28-4faf-a03e-2572b4301afe", "name" : null, "timestamp" : "2017-08-21T06:57:30.004Z", "batchId" : 1, "numInputRows" : 3, "inputRowsPerSecond" : 0.91324200913242, "processedRowsPerSecond" : 2.2388059701492535, "durationMs" : { "addBatch" : 1245, "getBatch" : 22, "getOffset" : 0, "queryPlanning" : 23, "triggerExecution" : 1340, "walCommit" : 44 }, "stateOperators" : [ { "numRowsTotal" : 3, "numRowsUpdated" : 3, "memoryUsedBytes" : 18095 } ], "sources" : [ { "description" : "RateSource[rowsPerSecond=1, rampUpTimeSeconds=0, numPartitions=8]", "startOffset" : 0, "endOffset" : 3, "numInputRows" : 3, "inputRowsPerSecond" : 0.91324200913242, "processedRowsPerSecond" : 2.2388059701492535 } ], "sink" : { "description" : "ConsoleSink[numRows=20, truncate=false]" } } 17/08/21 08:57:31 DEBUG StreamExecution: batch 1 committed ... ------------------------------------------- Batch: 2 ------------------------------------------- Device: 1 Signals (1): 0. Signal(2017-08-21 08:57:36.682,0,1) State: GroupState(<undefined>) Device: 3 Signals (2): 0. Signal(2017-08-21 08:57:32.682,6,3) 1. Signal(2017-08-21 08:57:35.682,9,3) State: GroupState(Map(3 -> 1)) Device: 5 Signals (1): 0. Signal(2017-08-21 08:57:34.682,8,5) State: GroupState(<undefined>) Device: 4 Signals (1): 0. Signal(2017-08-21 08:57:29.682,3,4) State: GroupState(<undefined>) Device: 8 Signals (2): 0. Signal(2017-08-21 08:57:31.682,5,8) 1. Signal(2017-08-21 08:57:33.682,7,8) State: GroupState(Map(8 -> 1)) Device: 7 Signals (2): 0. Signal(2017-08-21 08:57:30.682,4,7) 1. Signal(2017-08-21 08:57:37.682,1,7) State: GroupState(Map(7 -> 1)) Device: 0 Signals (1): 0. Signal(2017-08-21 08:57:38.682,2,0) State: GroupState(<undefined>) +--------+-----+ |deviceId|count| +--------+-----+ |1 |1 | |3 |3 | |5 |1 | |4 |1 | |8 |3 | |7 |3 | |0 |1 | +--------+-----+ ... 17/08/21 08:57:41 INFO StreamExecution: Streaming query made progress: { "id" : "a43822a6-500b-4f02-9133-53e9d39eedbf", "runId" : "79cb037e-0f28-4faf-a03e-2572b4301afe", "name" : null, "timestamp" : "2017-08-21T06:57:40.005Z", "batchId" : 2, "numInputRows" : 10, "inputRowsPerSecond" : 0.9999000099990002, "processedRowsPerSecond" : 9.242144177449168, "durationMs" : { "addBatch" : 1032, "getBatch" : 8, "getOffset" : 0, "queryPlanning" : 19, "triggerExecution" : 1082, "walCommit" : 21 }, "stateOperators" : [ { "numRowsTotal" : 7, "numRowsUpdated" : 7, "memoryUsedBytes" : 19023 } ], "sources" : [ { "description" : "RateSource[rowsPerSecond=1, rampUpTimeSeconds=0, numPartitions=8]", "startOffset" : 3, "endOffset" : 13, "numInputRows" : 10, "inputRowsPerSecond" : 0.9999000099990002, "processedRowsPerSecond" : 9.242144177449168 } ], "sink" : { "description" : "ConsoleSink[numRows=20, truncate=false]" } } 17/08/21 08:57:41 DEBUG StreamExecution: batch 2 committed // In the end... sq.stop // Use stateOperators to access the stats scala> println(sq.lastProgress.stateOperators(0).prettyJson) { "numRowsTotal" : 7, "numRowsUpdated" : 7, "memoryUsedBytes" : 19023 }