缓存主要分为:页面缓存和数据缓存 Memcache 、redis、mongodb都是做数据缓存的
Memcache是什么?
是一个高性能的分布式的内存对象缓存系统,通过在内存里维护一个统一的巨大的hash表,它能够用来存储各种格式的数据,包括图像、视频、文件以及数据库检索的结果等。简单的说就是将数据调用到内存中,然后从内存中读取,从而大大提高读取速度。 Memcache缓存什么数据? Memcache将数据存放在内存中,还可用于缓存其他东西,例如图片、视频等等。
Memcache如何存值?
MemCaChe是一个存储键值对的HashMap,在内存中对任意的数据(比如字符串、对象等)所使用的key-value存储,数据可以来自数据库调用、API调用,或者页面渲染的结果。MemCache设计理念就是小而强大,它简单的设计促进了快速部署、易于开发并解决面对大规模的数据缓存的许多难题,而所开放的API使得MemCache能用于Java、C/C++/C#、Perl、Python、PHP、Ruby等大部分流行的程序语言。
什么场合用memcache?
Memcache是分布式的内存对象缓存系统,而那些不需要分布的,不需要共享的,或者干脆规模小到只有一台服务器的应用,memcached不会带来任何好处,相反还会拖慢系统效率,因为网络连接同样需要资源。Memcached在很多时候都是作为数据库前端cache使用,因为他比数据库少了很多sql解析、磁盘操作等开销,而且它是使用内存来管理数据的, 所以它可以提供比直接读取数据库更好的性能,在大型系统中,访问同样的数据是很频繁的,memcached可以大大降低数据库压力,使系统执行效率提升。 另外,memcached也经常作为服务器之间数据共享的存储媒介,例如在SSO系统中保存系统单点登陆状态的数据就可以保存在memcached 中,被多个应用共享。
需要注意的是,memcached使用内存管理数据,所以它是易失的,当服务器重启,或者memcached进程中止,数据便会丢失,所以memcached不能用来持久保存数据。很多人的错误理解,memcached的性能非常好,好到了内存和硬盘的对比程度,其实memcached使用 内存并不会得到成百上千的读写速度提高,它的实际瓶颈在于网络连接,它和使用磁盘的数据库系统相比,好处在于它本身非常“轻”,因为没有过多的开销和直接 的读写方式,它可以轻松应付非常大的数据交换量,所以经常会出现两条千兆网络带宽都满负荷了,memcached进程本身并不占用多少CPU资源的情 况 。
MemCache虽然被称为"分布式缓存",但是MemCache本身完全不具备分布式的功能,MemCache集群之间不会相互通信(与之形成对比的,比如JBoss Cache,某台服务器有缓存数据更新时,会通知集群中其他机器更新缓存或清除缓存数据),所谓的"分布式",完全依赖于客户端程序的实现。
Memcache访问模型:

Memcache一次写缓存的流程:
1、应用程序输入需要写缓存的数据;
2、API将Key输入路由算法模块,路由算法根据Key和MemCache集群服务器列表得到一台服务器编号;
3、由服务器编号得到MemCache及其的ip地址和端口号
4、API调用通信模块和指定编号的服务器通信,将数据写入该服务器,完成一次分布式缓存的写操作
注:读缓存和写缓存一样,只要使用相同的路由算法和服务器列表,只要应用程序查询的是相同的Key,MemCache客户端总是访问相同的客户端去读取数据,只要服务器中还缓存着该数据,就能保证缓存命中。
这种MemCache集群的方式也是从分区容错性的方面考虑的,假如Node2宕机了,那么Node2上面存储的数据都不可用了,此时由于集群中Node0和Node1还存在,下一次请求Node2中存储的Key值的时候,肯定是没有命中的,这时先从数据库中拿到要缓存的数据,然后路由算法模块根据Key值在Node0和Node1中选取一个节点,把对应的数据放进去,这样下一次就又可以走缓存了,这种集群的做法很好,但是缺点是成本比较大。
从上图看出对服务器集群的管理,路由的算法至关重要,其实路由的算法就和负载均衡差不多,他决定着究竟该访问集群中的哪一台服务器,路由算法主要有:余数hash 一致性hash
余数hash: 余数hash他可以保证缓存数据在整个memcache服务器集群中均衡分布,但是如果考虑到服务器集群的伸缩性,那余数hash就远远不能解决了!
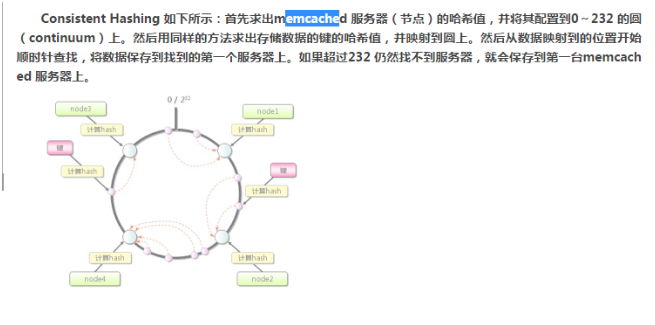
一致性hash: 一致性hash算法就是通过一个叫做一致性hash环的数据结构实现key到缓存服务器的hash映射!

缓存服务器集群扩容

Hashcode 就是一个签名。当两个对象的hashcode一样时,两个对象就有可能一样。如果不一样的话两个对象就肯定不一样。一般用hashcode来进行比较两个东西是不是一样的,可以很容易的排除许多不一样的东西。 最常用的地方就是在一堆东西里找一个东西。先用你要找的东西的hashcode和所有东西的hashcode比较,如果不一样的话就肯定不是你要找的东西。如果一样的话就很可能是你要找的东西。然后再进行仔细的比较两个东西是不是真的一模一样。
两个不同的东西的hashcode可以是一样的,不过这样会减慢运行速度,所以尽量避免(也就是所谓的碰撞)
一致性hash缺点:
1、原有节点1,2,3,在2和3之间加入节点4,那么影响的就是2与4之间的路径,那么节点3上的访问量就会减少,给节点4,但是节点1,2,不受影响,如果1,2,3,4的配置性能都一样,这样负载不均衡的问题不是我们所想要的!
2、如有三个节点Node1,Node2,Node3,分布在环上时三个节点挨的很近,落在环上的key寻找节点时,大量key顺时针总是分配给Node2,而其它两个节点被找到的概率都会很小。
解决方法:改善Hash算法,均匀分配各节点到环上;[引文]使用虚拟节点的思想,为每个物理节点(服务器)在圆上分配100~200个点。这样就能抑制分布不均匀,最大限度地减小服务器增减时的缓存重新分布。用户数据映射在虚拟节点上,就表示用户数据真正存储位置是在该虚拟节点代表的实际物理服务器上
memcache怎么启动多个服务器?
php操作memcache可以利用Memcache::addServer添加多台memcache服务器 $memcache = new memcahce; $memcache->addServer($ip1,11211); $memcache->addServer($ip2,11211);
memcache实现原理:
memcache要比传统的关系型数据库查询速度要快的多,因为传统的关系型数据库要保持数据的持久性,所以要把数据存在硬盘里面,导致IO操作速度慢!!而memcache的重启将会意味着数据的丢失!MemCache的数据存放在内存中,会受到机器位数的限制,32位机器最多只能使用2GB的内存空间,64位机器可以认为没有上限!
slab_class、slab、page、chunk的简单介绍:
1、MemCache将内存空间分为一组slab
2、每个slab下又有若干个page,每个page默认是1M,如果一个slab占用100M内存的话,那么这个slab下应该有100个page
3、每个page里面包含一组chunk,chunk是真正存放数据的地方,同一个slab里面的chunk的大小是固定的
4、有相同大小chunk的slab被组织在一起,称为slab_class MemCache内存分配的方式称为allocator,slab的数量是有限的,几个、十几个或者几十个,这个和启动参数的配置相关 相邻slab内的chunk基本以1.25为比例进行增长,MemCache启动时可以用-f指定这个比例)
Memcache优化
1,-n 参数的设置,注意将此参数设置为1024可以整除的数(还要考虑48B的差值),否则余下来的部分就浪费了。
2,不要存储超过1m的数据。因为要拆成多个chunk,计算和时间成本都成倍增加。
3,善用stats命令查看memcached状态。
4,消灭eviction(被删除的数据)。造成eviction是因为内存不够,有三个思路:
一是在CPU有余力的情况下开启压缩(PHP扩展);
二是增加内存;
三是调整-f参数,减少内存浪费。
5,调整业务代码,提高命中率。
6,缓存小数据。省带宽,省网络I/O时间,省内存。
7,根据业务特点,为数据尺寸区间小的业务分配专用的memcached实例。这样可以调小 -f 参数,使数据集中存在少数几个slab上,内存浪费较少。
Memcache不够用了怎么办?存放的时候报一个out of memory的错。
MemCache会把这个slab中最近最少使用的chunk中的数据清理掉,然后放上最新的数据
MemCache的内存分配及回收算法,总结三点:
1、MemCache的内存分配chunk里面会有内存浪费,88字节的value分配在128字节(紧接着大的用)的chunk中,就损失了30字节,但是这也避免了管理内存碎片的问题
2、MemCache的LRU算法不是针对全局的,是针对slab的
3、应该可以理解为什么MemCache存放的value大小是限制的,因为一个新数据过来,slab会先以page为单位申请一块内存,申请的内存最多就只有1M,所以value大小自然不能大于1M了
分布式: 将不同的键保存到不同的服务器上,就实现了memcached的分布式。 memcached服务器增多后,键就会分散,即使一台memcached服务器发生故障无法连接,也不会影响其他的缓存,系统依然能继续运行
memcache的利用率为什么是70%?怎么提高?
chunk块的大小可以为64B,128B,256B...1024KB .使用何种大小的chunk块是由memcache根据数据的长度来决定的.
MemCache的内存分配chunk里面会有内存浪费,88字节的value分配在128字节(紧接着大的用)的chunk中,就损失了30字节
提高: 如果预先知道客户端发送的数据的公用大小,或者仅缓存大小相同的数据的情况下,只要使用适合数据大小的组的列表,就可以减少浪费。以上的操作还没有实现,但是我们可以调节slab class 的大小的差别注意:
1. 不能往memcached存储一个大于1MB的数据.
2. 往memcached存储的所有数据,如果数据的大小分布于各种chunk大小区间,从64B到1MB都有,可能会造成内存的极大浪费以及memcached的异常.
命中率
命中:直接从缓存中读取到想要的数据。
不命中:缓存中没有想要的数据,还需要到数据库进行一次查询才能读取到想要的数据。
命中率越高,数据库查询的次数就越少。 读取缓存的速度远比数据库查询的速度高得多。 所以命中率越高,性能越高。
Memcached是以守护程序(监听)方式运行于一个或多个服务器中,随时会接收客户端的连接和操作!
注意:
1.memcache已经分配的内存不会再主动清理。
2. memcache分配给某个slab的内存页不能再分配给其他slab。
3. flush_all不能重置memcache分配内存页的格局,只是给所有的item置为过期。
4. memcache最大存储的item(key+value)大小限制为1M,这由page大小1M限制
5.由于memcache的分布式是客户端程序通过hash算法得到的key取模来实现,不同的语言可能会采用不同的hash算法,同样的客户端程序也有可能使用相异的方法,因此在多语言、多模块共用同一组memcached服务时,一定要注意在客户端选择相同的hash算法
6.启动memcached时可以通过-M参数禁止LRU替换,在内存用尽时add和set会返回失败
7.memcached启动时指定的是数据存储量,没有包括本身占用的内存、以及为了保存数据而设置的管理空间。因此它占用的内存量会多于启动时指定的内存分配量,这点需要注意。
8.memcache存储的时候对key的长度有限制,php和C的最大长度都是250
什么样的业务用到memcache?
一、经常被读取并且实时性要求不强可以等到自动过期的数据。例如网站首页最新文章列表、某某排行等数据。也就是虽然新数据产生了,但对用户体验不会产生任何影响的场景。 这类数据就使用典型的缓存策略,设置一过合理的过期时间,当数据过期以后再从数据库中读取。当然你得制定一个缓存清除策略,便于编辑或者其它人员能马上看到效果。
二、经常被读取并且实时性要求强的数据。比如用户的好友列表,用户文章列表,用户阅读记录等。 这类数据首先被载入到memcached中,当发生更改(添加、修改、删除)时就清除缓存。在缓存的时候,我将查询的SQL语句md5()得到它的 hash值作为key,结果数组作为值写入memcached,并且将该SQL涉及的table_name以及hash值配对存入memcached中。 当更改了这个表时,我就将与此表相配对的key的缓存全部删除。
三、统计类缓存,比如文章浏览数、网站PV等 此类缓存是将在数据库的中来累加的数据放在memcached来累加。获取也通过memcached来获取。但这样就产生了一个问题,如果 memcached服务器down掉的话这些数据就有可能丢失,所以一般使用memcached的永固性存储,这方面我们新浪使用memcachedb。
四、活跃用户的基本信息或者某篇热门文章。 此类数据的一个特点就是数据都是一行,也就是一个一维数组,当数据被update时(比如修改昵称、文章的评论数),在更改数据库数据的同时,使用Memcache::replace替换掉缓存里的数据。这样就有效了避免了再次查询数据库。
五、session数据 使用memcached来存储session的效率是最高的。memcached本身也是非常稳定的,不太用担心它会突然down掉引起session数据的丢失,即使丢失就重新登录了,也没啥。
怎么添加缓存,清除缓存 Cmd上清除?
flush_all 清空所有键值,但不会删除items,所以此时MemCache依旧占用内存
quit关闭连接
add 无条件地设置一个Key值,没有就增加,有就覆盖
set 按照相应的Key值添加数据,如果Key已经存在则会操作失败
replace 按照相应的Key值替换数据,如果Key值不存在则会操作失败