一、迭代器
1. 迭代器设计思维——STL关键所在 在《Design Patterns》一书中对iterator模式定义如下:提供一种方法,使之能够依序巡访某个聚合物(容器)所含的各个元素,而又无需暴露该聚合物的内部表达方式。
STL的中心思想在于:将数据容器(containers)和算法(algorithms)分开,彼此独立设计,最后再以一贴胶着剂将它们撮合在一起。容器和算法的泛型化,从技术角度来看并不困难,C++ 的class templates 和 function templates 可分别达成目标。如何设计出两者之间的良好胶着剂,才是大难题。
2. 迭代器(iterator)是一种smart pointer 迭代器是一种行为类似指针的对象,而指针的各种行为中最常见也最重要的便是内容提领(dereference)和成员访问(member access),因此,迭代器最重要的编程工作就是对 operator* 和 operator-> 进行重载(overloading)工作。可参考auto_ptr(源码在<memory>中)。
《STL源码剖析》P83处代码:可以看出,为了完成一个针对List 而设计的迭代器,我们无可避免地暴露了太多List实现细节:在main() 之中为了制作begin 和 end 两个迭代器,我们暴露了ListItem;在ListIter class 之中为了达成 operator++ 的目的,我们暴露了ListItem的操作函数next()。如果不是为了迭代器,ListItem原本应该完成隐藏起来不曝光的。换句话说,要设计出ListIter ,首先必须对List 的实现细节有非常丰富的了解。既然这无可避免,干脆就把迭代器的开发工作交给List 的设计者好了,如此一来,所有实现细节反而得以封装起来不被使用者看到。这正是为什么每一种STL容器都提供有专属迭代器的缘故。
3. 迭代器相应型别(associated types) 什么是相应型别?迭代器所指之物的型别便是其一。假设算法中有必要声明一个变量,以“迭代器所指对象的型别”为型别,如何是好?毕竟C++只支持sizeof(),并未支持typeof()。即便动用RTTI 性质中的typeid(),获得的也只是型别名称,不能拿来做变量声明之用。
解决方法1:利用function template 的参数推导(argument deducation)机制。如下:
template <class I, class T> void func_impl(I iter, T t) { T tmp; // 这里解决了问题。T就是迭代器所指之物的型别,本例为int // .... 这里做原本func() 应该做的全部工作 }; template <class I> inline void func(I iter) { // 函数转调用 func_impl(iter, *iter); // func 的工作全部移往func_impl }; int main() { int i; func(&i); };
我们以func() 为对外接口,却把实际操作全部置于func_impl()之中。由于func_impl()是一个function template,一旦被调用,编译器会自动进行template参数推导。于是导出型别T,顺利解决问题。
迭代器相应型别不只是“迭代器所指对象的型别”一种而已。根据经验,最常用的相应型别有五种,然而并非任何情况下任何一种都可利用上述的template参数推导机制来取得。我们需要更全面的解法。
二、Traits 编程技法——STL源代码门钥 迭代器所指对象的型别,称为该迭代器的value type。上述的参数型别推导技巧虽然可用于value type,却非全面可用:万一value type必须用于函数的传回值,就束手无策了,毕竟函数的“template参数推导机制”推而导之的只是参数,无法推导函数的返回值型别。
解决方法2:声明内嵌型别似乎是个好主意,如下:
template <class T> struct MyIter { typedef T value_type; // 内嵌型别声明(nested type) T* ptr; MyIter(T* p = 0):ptr(p) { } T& operator*() const { return *ptr; } // ... }; template <class T> typename I::value_type // 需要使用typename,这一正行是func的返回值型别 func(I ite) { return *iter; }; //.... MyIter<int> ite(new int(8)); cout << func(ite); //输出8
注意,func() 的回返型别必须加上关键词typename,因为T是一个template参数,在它被编译器具现化之前,编译器对T一无所悉,换句话说,编译器此时并不知道MyIter<T>::value_type代表的是一个型别或是一个member function 或是一个 data member。关键词typename的用意在于告诉编译器这是一个型别,如此才能顺利通过编译。
看起来不错。但是有个隐晦的陷阱:并不是所有迭代器都是class type。原生指针就不是!如果不是class type,就无法为它定义内嵌型别。但STL(以及整个泛型思维)绝对必须接受原生指针作为一种迭代器,所以上面这样还不够。有没有办法可以让上述的一般化概念针对特定情况(例如针对原生指针)做特殊化处理呢?
解决方法3:template partial specialization (模板偏特化)可以做到 如果class template 拥有一个以上的template参数,我们可以针对其中某个(或数个,但非全部)template参数进行特化工作。换句话说,我们可以在泛化设计中提供一个特化版本(也就是将泛化版本中的某些template参数赋予明确的指定)。
假设有一个class template 如下:
template <typename U, typename V, typename T>
class C { ... };
partial specialization的字面意义容易误导我们以为,所谓“偏特化版”一定是对template参数U或V或T(或某种组合)指定某个参数值。其实不然,《泛型思维》一书对partial specialization的定义是:“针对(任何)template参数更进一步的条件限制所设计出来的一个特化版本”。由此,面对以下这么一个class template:
template<typename T> class C { ... }; // 这个泛化版本允许(接受)T为任何型别
我们便很容易接受它有一个形式如下的partial specialization:
template<typename T> class C<T*> { ... }; // 这个特化版本仅适用于“T 为原生指针”的情况 // “T为原生指针"便是“T为任何型别”的一个更进一步的条件限制
有了这项利器,我们便可以解决前述“内嵌型别”未能解决的问题。先前的问题是,原生指针并非class,因此无法为它们定义内嵌型别。现在,我们可以针对“迭代器之template参数为指针”者,设计特化版的迭代器。
注意,我们进入关键地带了。下面这个 class template 专门用来“萃取”迭代器的特性,而value_type 正是迭代器的特性之一:
template <class I> struct iterator_traits // traits 意为“特性” { typedef typename I::value_type value_type; };
这个所谓的traits,其意义是,如果I定义有自己的value_type,那么通过这个traits的作用,萃取出来的value_type 就是 I::value_type。换句话说,如果I定义有自己的value_type,先前那个func() 可以改写成这样:
template <class T> typename iterator_traits<I>::value_type // 这一整行是函数回返型别 func(I ite) { return *ite; };
多了这一层间接性所带来的好处是:traits可以拥有特化版本(因为只有类模板有偏特化,函数模板没有偏特化,参见本人模板系列博文)。现在,我们令iterator_traites拥有一个partial specialization如下:
template <class T> struct iterator_traits<T*> // 偏特化版——迭代器是个原生指针 { typedef T value_type; };
于是,原生指针int* 虽然不是一种class type,亦可通过traits 取其value type。这就解决了先前的问题。
但是请注意,针对“指向常数对象的指针”,下面这个式子得到什么结果:
iterator_traits<const int*>::value_type
获得的是const int 而非 int 。这可能不是我们所期望的。我们希望利用这种机制来声明一个临时变量,使其型别于迭代器的value type相同,而现在,声明一个无法赋值(因const 之故)的临时变量,没什么用!因此,如果迭代器是个pointer-to-const,我们应该设法另其value type 为一个non-const 型别。没问题,只要另外设计一个特化版本,就能解决这个问题:
template <class T> struct iterator_traits<const T*> // 偏特化版——当迭代器是个pointer-to-const时, { // 萃取出来的型别应该是T而非 const T typedef T value_type; };
现在,不论面对的是迭代器MyIter,或是原生指针int* 或 const int*,都可以通过traits 取出正确的(我们所期望的)value type。
根据经验,最常用到的迭代器相应型别有五种:value type, difference type, pointer, reference, iterator category。如果你希望你所开发的容器能与STL水乳交融,一定要为你的容器的迭代器定义这五种相应型别。“特性萃取机”traits 会很忠实地将原汁原味榨取出来。
template <class T> struct iterator_traits { typedef typename I::iterator_category iterator_category; typedef typename I::value_type value_type; typedef typename I::difference_type difference_type; typedef typename I::pointer pointer; typedef typename I::reference reference; };
iterator_traits必须针对传入之型别为pointer 及 pointer-to-const者,设计特化版本。
1. 迭代器相应型别之一——value type
如上所述。
2. 迭代器相应型别之二——difference type
difference type用来表示两个迭代器之间的距离,因此它也可以用来表示一个容器的最大容量,因为对于连续空间的容器而言,头尾之间的距离就是其最大容量。
3. 迭代器相应型别之三——reference type
从“迭代器所指之物的内容是否允许改变”的角度视之,迭代器分为两种:不允许改变“所指对象之内容”者,称为constant iterators,例如 const int *pic; 允许改变“所指对象之内容”者,称为mutable iterators,例如 int* pi。当我们对一个mutable iterators进行提领操作时,获得的不应该是一个右值,应该是一个左值,因为右值不允许赋值操作,左值才允许。
在C++中,函数如果要传回左值,都是以by reference 的方式进行,所以当p是个mutable iterators 时,如果其value type 是T,那么*p 的型别不应该是T,应该是T&。将此道理扩充,如果p是一个constant iterators,其value type 是T,那么*p的型别不应该是const T,而应该是const T&。这里所讨论的*p的型别,即所谓的reference type。(其中一个例子便是"++运算子"的实现,参见C++易混淆知识点整理)
4. 迭代器相应型别之四——pointer type
pointers 和 references 在C++ 中有非常密切的关联。如果“传回一个左值,令它代表p所指之物”是可能的,那么“传回一个左值,令它代码p所指之物的地址”也一定可以。也就是说,我们能够传回一个pointer,指向迭代器所指之物。
5. 迭代器相应型别之五——iterator_category
在讨论iterator_category之前,我们先要说一下迭代器的分类。根据移动特性与施行操作,迭代器被分为五类:
(1)Input Iterator:只读
(2)Output Iterator:只写
(3)Forward Iterator:允许“写入型”算法(例如replace())在此种迭代器所形成的区间上进行读写操作。
(4)Bidirectional Iterator:可双向移动。
(5)Random Access Iterator:前四种迭代器都只供应一部分指针算术能力(前三种支持 operator++,第四种再加上 operator--),第五种则涵盖所有指针算术能力,包括p+n, p-n, p[n], p1-p2, p1<p2。
下图可以表示这些迭代器的分类和从属关系。直线和箭头代表的并非C++的继承关系,而是所谓concept(概念)与refinement(强化)的关系。
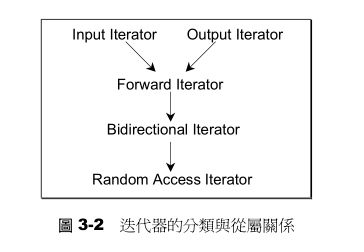
设计算法时,如果可能,我们尽量针对图3-2中的某种迭代器提供一个明确定义,并针对更强化的某种迭代器提供另一种定义,这样才能在不同情况下提供最大效率。在研究STL的过程中,效率是个重要课题。假设有个算法可接受Rorward Iterator,你以Random Access Iterator 喂给它,它当然也会接受,因为一个Random Access Iterator必然是一个Forward Iterator(见图3-2)。但是可用并不代表最佳!
以advanced()为例
这是许多算法内部常用的一个函数。该函数有两个参数,迭代器p和数值n;函数内部将p累进n次(前进n距离)。下面有三份定义,一份针对Input iterator,一份针对Bidirectional Iterator,另一份针对Random Access Iterator。倒是没有针对Forward Iterator而设计的版本,因为那和针对Input Iterator 而设计的版本完全一致。
template <class InputIterator, class Distance> void advance_II(InputIterator& i, Distance n) { // 单向,逐一前进 while(n--) ++i; // 或写成for (; n > 0; --n, ++i); }; template <class BidirectionalIterator, class Distance> void advance_BI(BidirectionalIterator& i, Distance n) { // 双向,逐一前进 if (n>=0) while(n--) ++i; else while(n++) --i; }; template <class RandomAccessIterator, class Distance> void advance_RAI(RandomAccessIterator& i, Distance n) { // 双向,跳跃前进 i += n; };
现在,当程序调用advance() 时,应该选用(调用)哪一份函数定义呢?如果选择advance_II(),对Random Access Iterator而言极度缺乏效率,原本O(1)的操作竟成为O(n)。如果选择advance_RAI(),则它无法接受 Input Iterator。我们需要将三者合一,如下:
template <class InputIterator, class Distance> void advance(InputIterator& i, Distance n) { if (is_random_access_iterator(i)) advance_RAI(i, n); else if (is_bidirectional_iterator(i)) advance_BI(i, n); else advance_II(i, n); }
但是像这样在执行时期才决定使用哪一个版本,会影响程序效率。最好能够在编译期就选择正确的版本。重载函数机制可以达成这个目标。
前述三个advance_x() 都有两个函数参数,型别都未定(因为都是template 参数)。为了令其同名,形成重载函数,我们必须加上一个型别已确定的函数参数,使函数重载机制得以有效运作起来。
设计考虑如下:如果traits 有能力萃取出迭代器的种类,我们便可利用这个“迭代器类型”相应型别作为advanced() 的第三参数。这个相应型别一定必须是一个class type,不能只是数值号码类的东西,因为编译器需仰赖它(一个型别)来进行重载决议(overloaded resolution)。下面定义五个classes,代表五种迭代器类型:
// 五个作为标记用的型别(tag types) struct input_iterator_tag { }; struct output_iterator_tag { }; struct forward_iterator_tag : public input_iterator_tag { }; struct bidirectional_iterator_tag : public forward_iterator_tag { }; struct random_access_iterator_tag : public bidirectional_iterator_tag { };
这些classes 只作为标记用,所以不需要任何成员。至于为什么运用继承机制,稍后再解释。现在重新设计 __advance() (由于只在内部使用,所以函数名称加上特定的前导符),并加上第三参数,使它们形成重载:
template <class InputIterator, class Distance> inline void __advance(InputIterator& i, Distance n, forward_iterator_tag) { // 单向,逐一前进 while(n--) ++i; }; template <class ForwardIterator, class Distance> inline void __advance(ForwardIterator& i, Distance n, forward_iterator_tag) { // 单纯地进行传递调用 __advance(i, n, input_iterator_tag()); }; template <class BidirectionalIterator, class Distance> inline void __advance(BidirectionalIterator& i, Distance n, bidirectional_iterator_tag) { // 双向,逐一前进 if (n >= 0) while(n--) ++i; else while(n++) --i; }; template <class RandomAccessIterator, class Distance> inline void __advance(RandomAccessIterator& i, Distance n, random_access_iterator_tag) { // 双向,跳跃前进 i += n; };
注意上述语法,每个__advance() 的最后一个参数都只声明型别,并未指定参数名称,因为它纯粹只是用来激活重载机制,函数之中根本不适用该参数。如果硬要加上参数名称也可以,画蛇添足罢了。
行进至此,还需要一个对外开发的上层控制接口,调用上述各个重载的__advance() 。这一上层接口只需两个参数,当它准备将工作转给上述的__advance()时,才自行加上第三参数:迭代器类型。因此,这个上层函数必须有能力从它所获得的迭代器中推导出其类型——这份工作自然是交给traits机制:
template <class InputIterator, class Distance> inline void advance(InputIterator& i, Distance n) { __advance(i, n, iterator_traits<InputIterator>::iterator_category()); };
注意上述语法,iterator_traits<InputIterator>::iterator_category() 将产生一个临时对象(道理就像int() 会产生一个int暂时对象一样),其型别应该隶属于前述四个迭代器类型(I,F, B,R)之一。然后,根据这个型别,编译器才决定调用哪一个__advance() 重载函数。
因此,为了满足上述行为,traits 必须再增加一个相应的型别:
template <class I> struct iterator_traits { .... typedef typename I::iterator_category iterator_category; }; // 针对原生指针而设计的 “偏特化版” template <class T> struct iterator_traits<T*> { .... // 注意,原生指针是一种Random Access Iterator typedef random_access_iterator_tag iterator_category; }; // 针对原生的pointer-to-const 而设计的“偏特化版” template <class T> struct iterator_traits<const T*> { .... // 注意,原生的pointer-to-const 是一种Random Access Iterator typedef random_access_iterator_tag iterator_category; };
任何一个迭代器,其类型永远应该落在“该迭代器所隶属之各种类型中,最强化的那个”。例如,int*, 既是Random Access Iterator,又是Bidirectional Iterator,同时也是Forward Iterator,而且也是Input iterator,那么,其类型应该归属为random_access_iterator_tag.
注意到advance() 的template 参数名称,按说advance() 既然可以接受各种类型的迭代器,就不应该将其型别参数命名为InputIterator。这其实是STL算法的一个命名规则:以算法所能接受之最低阶迭代器类型,来为其迭代器型别参数命名。
消除“单纯传递调用的函数” 以class 来定义迭代器的各种分类标签,不仅可以促成重载机制的成功运作(使编译器得以正确执行重载决议,overloaded resolution),另一个好处是,通过继承,我们可以不必再写“单纯只做传递调用”的函数(例如前述的advance() ForwardIterator 版)。当参数与参数完全吻合,则调用相应版本函数;否则,因继承关系而自动传递调用父类的相应函数。
《STL源码剖析》有另外一个关于distance()的例子,详见书籍。
三、std::iterator 的保证
为了符合规范,任何迭代器都应该提供五个内嵌相应型别,以利于traits萃取,否则便是自别于整个STL框架,为了避免忘记漏却,将事情简化,STL提供了一个iterator class 如下,如果每个新设计的迭代器都继承自它,就可保证符合STL所需之规范:
template <class Category, class T, class Distance = ptrdiff_t, class Pointer = T*, class Reference = T& > struct iterator { typedef Category iterator_category; typedef T value_type; typedef Distance difference_type; typedef Pointer pointer; typedef Reference reference; };
iterator class 不含任何成员,纯粹只是型别定义,所以继承它并不会招致任何额外负担。由于后三个参数皆有默认值,故新的迭代器只需提供前两个参数即可。
小结:
设计适当的相应型别是迭代器的责任,设计适当的迭代器则是容器的责任。唯容器本身,才知道该设计出怎样的迭代器来遍历自己,并执行迭代器该有的各种行为。至于算法,完成可以独立于容器和迭代器之外自行发展,只要设计时以迭代器为对外接口就行。
traits编程技法大量运用于STL实现品中。它利用“内嵌型别”的编程技巧与编译器的template 参数推导功能,增强C++为能提供的关于型别认证方面的能力,弥补C++不是强型别语言的遗憾。
所有iterator源码,请参见SGI STL<stl_iterator.h>文件。
四、SGI STL 的私房菜:__type_traits traits 编程技法很棒,适度弥补了C++语言本身的不足。STL只对迭代器加以规范,制定出iterator_traits 这样的东西。SGI 把这种技法进一步扩大到迭代器以外的世界,于是有了所谓的__type_traits。双底线前缀词意指这是SGI STL 内部所用的东西,不再STL标准规范之内。
iterator_traits负责萃取迭代器的特性,__type_traits则负责萃取型别(type)的特性。此处我们所关注的型别特性是指:这个型别是否具备non-trivial defalt ctor?是否具备non-trivial copy ctor?是否具备non-trivial assignment operator?是否具备non-trivial dtor?如果答案是否定的,我们在对这个型别进行构造、析构、拷贝、赋值等操作时,就可以采用最高效率的措施(例如根本不调用身居高位,不谋实事的那些constructor,destructor),而采用内存直接处理操作如malloc(),memcpy()等等,获得最高效率。这对于大规模而操作频繁的容器,有责显著的效率提升。
定义于SGI <type_traits.h>中的__type_traits,提供了一种机制,允许针对不同的型别属性,在编译时期完成函数派送决定。这对于撰写template很有帮助。例如,当我们准备对一个“元素型别未知”的数组执行copy操作时,如果我们能事先知道其元素型别是否有一个trivial copy constructor ,便能够帮助我们决定是否可使用快速的memcpy() 或 memmove()。
根据iterator_traits得来的经验,我们希望,程序之中可以这样运用__type_traits<T>,T代表任意型别:
__type_traits<T>::has_trivial_default_constructor __type_traits<T>::has_trivial_copy_constructor __type_traits<T>::has_trivial_assignment_operator __type_traits<T>::has_trivial_destructor __type_traits<T>::is_POD_type // POD : Plain Old Data
我们希望上述式子响应我们“真” 或 “假”(以便我们决定采取什么策略),但其结果不应该只是个bool值,应该是个有着 真/假 性质的“对象”,因为我们希望利用其响应结果来进行参数推导,而编译器只有面对class object 形式的参数,才会做参数推导。为此,上述式子应该传回这样的东西:
struct __true_type { }; struct __false_type { };
这两个空白classes没有任何成员,不会带来额外负担,却又能够标示真假,满足我们所需。
为了达成上述五个式子,__type_traits 内必须定义一些typedefs,其值不是__true_type 就是 __false_type。 下面是SGI的做法:
template <class type> struct __type_traits { typedef __true_type this_dummy_member_must_be_first; /* 不要移除这个成员,它通知“有能力自动将 __type_traits 特化”的编译器说,我们现在所看到的这个 __type_traits template 是特殊的。 这是为了确保万一编译器也使用一个名为 __type_traits 而其实域此处定义并无任何关联的 template 时,所有事情都仍将顺利运作 */ /*以下条件应被遵守,因为编译器有可能自动为各型别产生专属的 __type_traits 特化版本: - 你可以重新排列以下的成员次序; - 你可以移除以下任何成员 - 绝对不可以将以下成员重新命名而却没有改变编译器中的对应名称 - 新加入的成员会被视为一般成员,除非你在编译器中加上适当支持 */ typedef __false_type has_trivial_default_constructor typedef __false_type has_trivial_copy_constructor typedef __false_type has_trivial_assignment_operator typedef __false_type has_trivial_destructor typedef __false_type is_POD_type };
为什么SGI 把所有内嵌型别都定义为 __false_type 呢?是的,SGI 定义出最保守的值,然后再针对每一个标量型别(C++基本型别:char, signed char, unsigned char, short, unsigned short, int, unsigned int, long, unsigned long, float, double, long double提供特化版本。注意,每一个成员的值都是 __true_type,表示这些型别都是可采用最快速方式(例如memcopy)来进行拷贝(copy) 或 赋值(assign)操作。)设计适当的 __type_traits 特化版本,这样就解决了问题。
下面提供一个例子(《STL源码剖析》第2.3.3节):
template <class ForwardIterator, class Size, class T> inline ForwardIterator uninitialized_fill_n(ForwardIterator first, Size n, const T& x) { return __uninitialized_fill_n(first, n, x, value_type(first)); };
该函数以x为蓝本,自迭代器first开始构造n个元素。为求取最大效率,首先以value_type() 萃取出迭代器first 的value_type ,再利用 __type_traits 判断该型别是否为POD型别:
template <class ForwardIterator, class Size, class T, class T1> inline ForwardIterator uninitialized_fill_n(ForwardIterator first, Size n, const T& x, T1*) { typedef typename __type_traits<T1>::is_POD_type is_POD; return __uninitialized_fill_n_aux(first, n, x, is_POD()); };
以下就“是否为POD型别”采取最适当的措施:
// 如果不是POD型别 template <class ForwardIterator, class Size, class T> ForwardIterator uninitialized_fill_n_aux(ForwardIterator first, Size n, const T& x, __false_type) { ForwardIterator cur = first; // 为求阅读顺畅简化,以下将原本有的异常处理去除 for ( ; n > 0 ; --n, ++cur ) construct(&*cur, x); // 参见 2.2.3节 return cur; }; // 如果是POD型别 template <class ForwardIterator, class Size, class T> inline ForwardIterator uninitialized_fill_n_aux(ForwardIterator first, Size n, const T& x, __true_type) { return fill_n(first, n, x); // 交由高阶函数执行 }; // 以下是定义于<stl_algobase.h> 中的fill_n() template <class OutputIterator, class Size, class T> OutputIterator fill_n(OutputIterator first, Size n, const T& value) { for ( ; n > 0 ; --n, ++first) *first = value; return first; }
究竟一个class 什么时候该有自己的non-trivial default constructor, non-trivial copy constructor, non-trivial assignment operator, non-trivial destructor 呢?一个简单的判断准则是:如果class内含指针成员,并且对它进行内存动态配置,那么这个class就需要实现出自己的non-trivial-xxx.(进行深度拷贝)。