1、正则化
范数,L1范数,L2范数 范数都是距离计算的一种,如下,具体可以参考《数值分析》

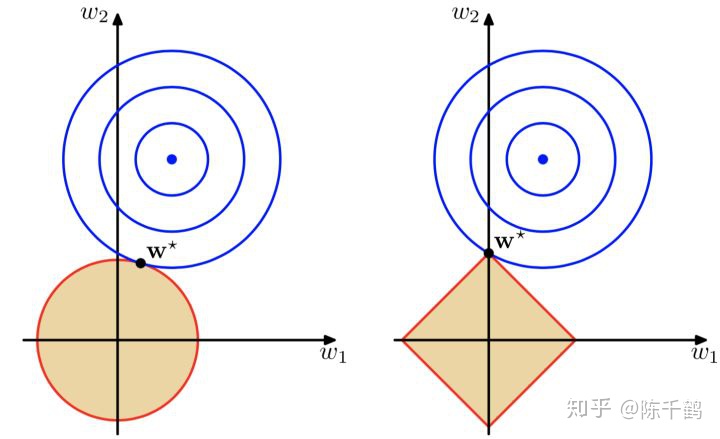
左面是L2(x^2+y^2)约束下解空间的图像,右面是L1(|x|+|y|)约束下解空间的图像。
蓝色的圆圈表示损失函数的等值线。同一个圆上的损失函数值相等的,圆的半径越大表示损失值越大,由外到内,损失函数值越来越小,中间最小。
如果没有L1和L2正则化约束的话,w1和w2是可以任意取值的,损失函数可以优化到中心的最小值的,此时中心对应的w1和w2的取值就是模型最终求得的参数。
但是填了L1和L2正则化约束就把解空间约束在了黄色的平面内。黄色图像的边缘与损失函数等值线的交点,便是满足约束条件的损失函数最小化的模型的参数的解。 由于L1正则化约束的解空间是一个菱形,所以等值线与菱形端点相交的概率比与线的中间相交的概率要大很多,端点在坐标轴上,一些参数的取值便为0。L2正则化约束的解空间是圆形,所以等值线与圆的任何部分相交的概率都是一样的,所以也就不会产生稀疏的参数。详见https://zhuanlan.zhihu.com/p/164560266
总而言之,范数作用于权重矩阵等,防止过拟合,过于多的参数,是可以达到很好的效果,但是容易过拟合,正则化就是来约束参数数量,防止过拟合,但又可以保证曲线的光滑程度
2、梯度
梯度是一种矢量,对应到数学里就是偏导数,一些训练次数和层数太多时,也即是求导次数次增多,导数趋近于0,导致梯度消失
一些优化算法,对偏导前面即分母上,系数进行变换(一般默认为1),如Adam优化,弹性放缩系数
3、自然界中的一些分布
数学前辈们,探寻出一些概率分布,我们现在对数据进行处理,看看符合那种自然分布,以分布函数来预测等会更为准确
4、似然、贝叶斯
p(x|θ) 似然求解θ;
p(θ|x) 贝叶斯求解x,具体可以看看https://www.cnblogs.com/z-712/p/14817763.html
5、激活函数
Layer保存自己认为重要的特征,每一层,都是sampling,激活函数的本初就是分类,把数据投影到例如[0,1]区间内,设一个Threshold,
6、Batch size
Batch_size 是用于在每次迭代中训练模型的数据数量,一般的设置是32、64、128、256、512
选择正确的Batch_size用于确保cost function和参数值的收敛,以及模型的泛华能力
Batch_size决定更新的频率,Batch_size越小,更新就越快
Batch越大,梯度越精准,也就是说,在迭代计算的时候更容易跳过局部区域
比较打的Batch_size,往往GPU memory是不够用的,需要通过并行计算的方式解决[1]
7、有监督/无监督 学习中的 训练集和测试集
有监督学习中:https://blog.csdn.net/zzj_csdn/article/details/103228738/
无监督学习中:https://zhuanlan.zhihu.com/p/32387092
=================================节选 1========================================
有了模型后,训练集就是用来训练参数的,说准确点,一般是用来梯度下降的。而验证集基本是在每个epoch完成后,用来测试一下当前模型的准确率。因为验证集跟训练集没有交集,因此这个准确率是可靠的。那么为啥还需要一个测试集呢?
这就需要区分一下模型的各种参数了。事实上,对于一个模型来说,其参数可以分为普通参数和超参数。在不引入强化学习的前提下,那么普通参数就是可以被梯度下降所更新的,也就是训练集所更新的参数。另外,还有超参数的概念,比如网络层数、网络节点数、迭代次数、学习率等等,这些参数不在梯度下降的更新范围内。尽管现在已经有一些算法可以用来搜索模型的超参数,但多数情况下我们还是自己人工根据验证集来调
那也就是说,从狭义来讲,验证集没有参与梯度下降的过程,也就是说是没有经过训练的;但从广义上来看,验证集却参与了一个“人工调参”的过程,我们根据验证集的结果调节了迭代数、调节了学习率等等,使得结果在验证集上最优。因此,我们也可以认为,验证集也参与了训练。
那么就很明显了,我们还需要一个完全没有经过训练的集合,那就是测试集,我们既不用测试集梯度下降,也不用它来控制超参数,只是在模型最终训练完成后,用来测试一下最后准确率
聪明的读者就会类比到,其实这是一个无休止的过程。如果测试集准确率很差,那么我们还是会去调整模型的各种参数,这时候又可以认为测试集也参与训练了。好吧,我们可能还需要一个“测试测试集”,也许还需要“测试测试测试集”...
算了吧,还是在测试集就停止吧。
=================================节选 2========================================
对于有监督学习,由于标签作为输入端,其作用于训练集(Test set)和验证集(Validation set)上;对于无监督习,标签主要作用于验证集(Validation set)上。
标签对无监督算法有什么用呢?
1. 标签用来评价无监督学习,也就是来判断无监督学习的好坏。其常用指标有三个:检测率(Detection rate),召回率(Recall)和准确率(precision)。你的模型到底好不好?来,跟我们现在的标签比对一下,看你和我的交集(overlap)有多少,看你比我多抓了多少坏人!
2. 标签用来调优无监督模型,也就是标签作用于验证集上。任何一种机器学习算法都包含参数,调参是模型调优的主要工作。有监督的调参主要在training set上进行,例如ANN的权值;而无监督没有training set,调参主要是在validation set上进行。换言之,有监督的标签是用来输入训练模型的,无监督的标签是研究人员用来看(验证)的。
参考链接
[1] https://blog.csdn.net/weixin_38477351/article/details/108965622