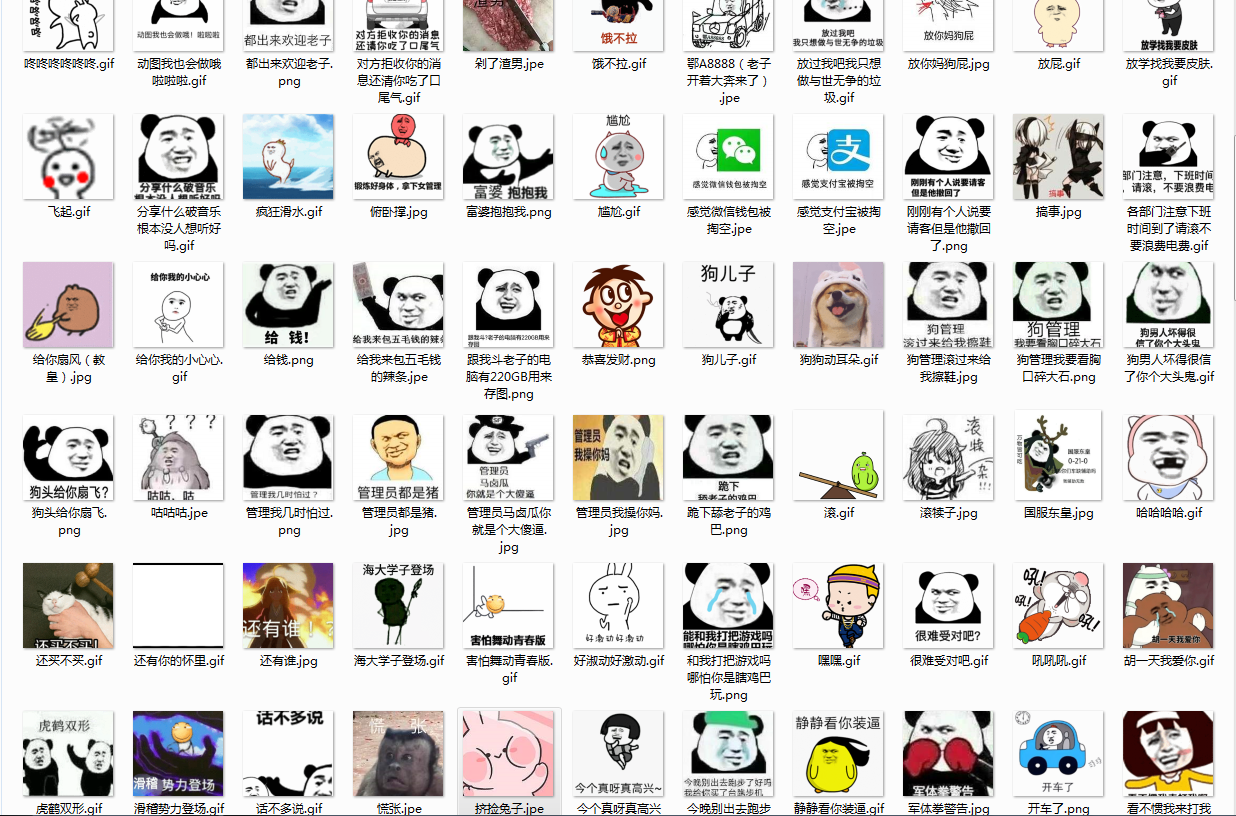
普通爬取:
1 # -*- coding:utf-8 -*- 2 # author:zxy 3 # Date:2018-10-21 4 import requests 5 from lxml import etree 6 import re 7 import urllib 8 import os 9 import time 10 11 12 13 def parse_page(url): 14 headers={ 15 'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) ' 16 'AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36', 17 'Cookie':'__cfduid=ddb28ef1934faef742f7fb8911d7b33bd1540080067; UM_distinctid=16693ece9945b2-0b031da4b19f32-333b5602-1fa400-16693ece9958e4;' 18 ' _ga=GA1.2.1950184368.1540080070; _gid=GA1.2.1249143498.1540080070; _gat=1' 19 } 20 response=requests.get(url,headers=headers) 21 text=response.text 22 html=etree.HTML(text) 23 imgs=html.xpath("//div[@class='page-content text-center']//img[@class!='gif']") 24 for img in imgs: 25 img_url=img.get('data-original') 26 alt=img.get('alt') 27 alt=re.sub(r'[??.、.!!,,]','',alt) 28 suffix1=os.path.splitext(img_url)[1] 29 suffix=suffix1[0:4] 30 filename=alt+suffix 31 urllib.request.urlretrieve(img_url,'D:\我的图片\emoticon\%s'%filename) 32 33 34 35 def main(): 36 for x in range(1,101): 37 url="http://www.doutula.com/photo/list/?page=%d"%x 38 parse_page(url) 39 time.sleep(1) 40 # url="http://www.doutula.com/photo/list/?page=1" 41 # parse_page(url) 42 43 if __name__ == '__main__': 44 main()
多线程爬取:
1 # -*- coding:utf-8 -*- 2 # author:zxy 3 # Date:2018-10-21 4 5 from queue import Queue 6 import requests 7 from lxml import etree 8 import re 9 import urllib 10 import os 11 import time 12 import threading 13 from urllib import request 14 15 class Procude(threading.Thread): 16 headers = { 17 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) ' 18 'AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36', 19 'Cookie': '__cfduid=ddb28ef1934faef742f7fb8911d7b33bd1540080067; UM_distinctid=16693ece9945b2-0b031da4b19f32-333b5602-1fa400-16693ece9958e4;' 20 ' _ga=GA1.2.1950184368.1540080070; _gid=GA1.2.1249143498.1540080070; _gat=1' 21 } 22 def __init__(self,page_queue,img_queue,*args,**kwargs): 23 super(Procude, self).__init__(*args,**kwargs) 24 self.page_queue=page_queue 25 self.img_queue=img_queue 26 27 def run(self): 28 while True: 29 if self.page_queue.empty(): 30 break 31 url=self.page_queue.get() 32 self.parse_page(url) 33 34 def parse_page(self,url): 35 response=requests.get(url,headers=self.headers) 36 text=response.text 37 html=etree.HTML(text) 38 imgs=html.xpath("//div[@class='page-content text-center']//img[@class!='gif']") 39 for img in imgs: 40 img_url=img.get('data-original') 41 alt=img.get('alt') 42 alt=re.sub(r'[??.、.!!,,*]','',alt) 43 suffix1=os.path.splitext(img_url)[1] 44 suffix=suffix1[0:4] 45 filename=alt+suffix 46 self.img_queue.put((img_url,filename)) 47 48 class Consumer(threading.Thread): 49 def __init__(self,page_queue,img_queue,*args,**kwargs): 50 super(Consumer, self).__init__(*args,**kwargs) 51 self.page_queue=page_queue 52 self.img_queue=img_queue 53 def run(self): 54 while True: 55 if self.img_queue.empty() and self.page_queue.empty(): 56 break 57 58 img_url,filename=self.img_queue.get() #元组解包 59 request.urlretrieve(img_url,'D:\我的图片\emoticon\%s'%filename) 60 print(filename+"下载完成") 61 62 63 def main(): 64 page_queue=Queue(100) 65 img_queue=Queue(1000) 66 for x in range(1,101): 67 url="http://www.doutula.com/photo/list/?page=%d"%x 68 page_queue.put(url) 69 # time.sleep(1) 70 71 for x in range(5): 72 t=Procude(page_queue,img_queue) 73 t.start() 74 75 for x in range(5): 76 t=Consumer(page_queue,img_queue) 77 t.start() 78 79 80 if __name__ == '__main__': 81 main()
爬取效果如下所示: