多线程:




1 import requests 2 import random 3 import json 4 from lxml import etree 5 import time 6 7 #用户代理池 8 USER_AGENT_LISTS = [] 9 with open("zcb/USER_AGENT.json","r",encoding="utf8") as f: 10 USER_AGENT_LISTS = json.load(f) 11 # PROXY_LISTS_ALL = [] 12 # with open("zcb/PROXY_LISTS.json", "r", encoding="utf8") as f: 13 # PROXY_LISTS_ALL = json.load(f) 14 15 class QiuShiBaiKe: 16 def __init__(self): 17 self.base_url = "http://www.lovehhy.net/News/List/ALL/{}/" 18 self.headers = {"User-Agent": random.choice(USER_AGENT_LISTS)} 19 20 #1, 获取所有的url 21 def get_url_lists(self): # --> url_lists [] 22 url_lists = [] 23 for i in range(1,21): #爬取 1-20 页 ! 24 # for i in range(1,2): #爬取 1-2页 ! 25 url_lists.append(self.base_url.format(i)) 26 return url_lists 27 28 #2, 发送请求 29 def send_requests(self,url): 30 time.sleep(1) #加上延迟 31 response = requests.get(url,headers = self.headers) 32 data_str = response.content.decode("gbk") 33 return data_str 34 35 #3,解析数据 36 ''' 37 //div[@class="post_recommend_new"] 38 ''' 39 def parase_data(self,data_str): 40 #a,转换类型 41 data_html = etree.HTML(data_str) 42 #b,解析数据 43 div_lists = data_html.xpath('//div[@class="post_recommend_new"]') #获取所有的帖子 44 45 for div in div_lists: 46 title = div.xpath('.//h3/a/text()')[0] 47 # print(title,type(title)) #['1、Redmi K30发布后,小米集团股价大涨近7%'] <class 'list'> 48 print(title) 49 50 #4,保存数据 51 def save_to_file(self,data_str): 52 with open("01_qiushi.html","w",encoding="utf8") as f: 53 f.write(data_str) 54 55 def _start(self): 56 #a, 获取所有的url 57 url_lists = self.get_url_lists() 58 #b, 循环遍历 url ,保存数据到本地。 59 for url in url_lists: 60 data_str = self.send_requests(url) 61 self.parase_data(data_str) 62 # self.save_to_file(data_str) 63 64 #5,调度方法 65 def run(self): 66 start_time = time.time() 67 self._start() 68 end_time = time.time() 69 70 print("总耗时:{} s".format(end_time-start_time)) # 输出: 总耗时:25.52379059791565 s 20页 71 72 73 if __name__ == '__main__': 74 QiuShiBaiKe().run()
=======================================================1==================================================

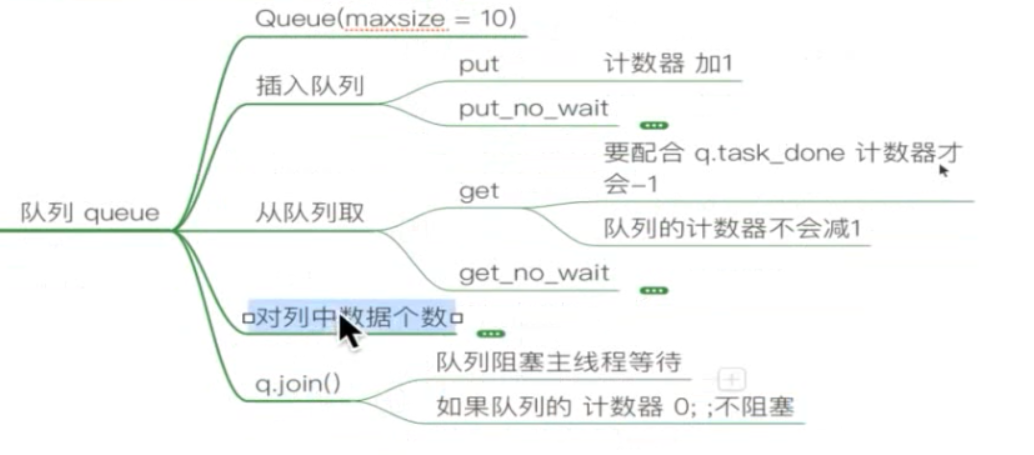
1 import requests 2 import random 3 import json 4 from lxml import etree 5 import time 6 import threading 7 from queue import Queue 8 9 #用户代理池 10 USER_AGENT_LISTS = [] 11 with open("zcb/USER_AGENT.json","r",encoding="utf8") as f: 12 USER_AGENT_LISTS = json.load(f) 13 # PROXY_LISTS_ALL = [] 14 # with open("zcb/PROXY_LISTS.json", "r", encoding="utf8") as f: 15 # PROXY_LISTS_ALL = json.load(f) 16 17 class QiuShiBaiKe: 18 def __init__(self): 19 self.base_url = "http://www.lovehhy.net/News/List/ALL/{}/" 20 self.headers = {"User-Agent": random.choice(USER_AGENT_LISTS)} 21 22 #创建三个队列 23 self.url_queue = Queue() # url 队列 24 self.response_queue = Queue() # response 队列 25 self.parsed_data_queue = Queue() # parse_data_queue 队列 26 27 28 #1, 获取所有的url 29 def get_url_lists(self): # --> url_lists [] 30 for i in range(1,21): #爬取 1-20 页 ! 31 # for i in range(1,2): #爬取 1-2页 ! 32 #q1 url 入队列 33 self.url_queue.put(self.base_url.format(i)) 34 35 #2, 发送请求 36 def send_requests(self): 37 while True: 38 #q1' url 出队列 39 url = self.url_queue.get() 40 41 time.sleep(1) #加上延迟 42 response = requests.get(url,headers = self.headers) 43 44 #q2 响应对像 入队列 45 self.response_queue.put(response) 46 47 # url_response 出队列,如果想让计数器 减一,需要如下设置: 48 self.url_queue.task_done() 49 50 51 #3,解析数据 52 def parase_data(self): 53 while True: 54 #q2' response 队列 出队 55 data_str = self.response_queue.get().content.decode("gbk") 56 57 #a,转换类型 58 data_html = etree.HTML(data_str) 59 #b,解析数据 60 div_lists = data_html.xpath('//div[@class="post_recommend_new"]') #获取所有的帖子 61 62 for div in div_lists: 63 title = div.xpath('.//h3/a/text()')[0] 64 #q3 解析后的data 入队列 65 self.parsed_data_queue.put(title) 66 67 # response_queue出队列,如果想让计数器 减一,需要如下设置: 68 self.response_queue.task_done() 69 70 #4,保存数据 71 def save_to_file(self): 72 while True: 73 # parsed_data_queue 出队, 74 data_str = self.parsed_data_queue.get() 75 print(data_str) 76 77 # parsed_data_queue 出队列,如果想让计数器 减一,需要如下设置: 78 self.parsed_data_queue.task_done() 79 80 def _start(self): 81 #a, 获取所有的url 82 url_lists = self.get_url_lists() 83 #b, 循环遍历 url ,保存数据到本地。 84 for url in url_lists: 85 data_str = self.send_requests(url) 86 self.parase_data(data_str) 87 # self.save_to_file(data_str) 88 89 #5,调度方法 90 def run(self): 91 start_time = time.time() 92 self._start() 93 end_time = time.time() 94 95 print("总耗时:{} s".format(end_time-start_time)) # 输出: 总耗时:26.19527816772461 s 20页 96 97 98 if __name__ == '__main__': 99 QiuShiBaiKe().run()
下面是第四个步骤:
![]()
添加多线程的步骤,如下:

1 import requests 2 import random 3 import json 4 from lxml import etree 5 import time 6 import threading 7 from queue import Queue 8 9 #用户代理池 10 USER_AGENT_LISTS = [] 11 with open("zcb/USER_AGENT.json","r",encoding="utf8") as f: 12 USER_AGENT_LISTS = json.load(f) 13 # PROXY_LISTS_ALL = [] 14 # with open("zcb/PROXY_LISTS.json", "r", encoding="utf8") as f: 15 # PROXY_LISTS_ALL = json.load(f) 16 17 class QiuShiBaiKe: 18 def __init__(self): 19 self.base_url = "http://www.lovehhy.net/News/List/ALL/{}/" 20 self.headers = {"User-Agent": random.choice(USER_AGENT_LISTS)} 21 22 #创建三个队列 23 self.url_queue = Queue() # url 队列 24 self.response_queue = Queue() # response 队列 25 self.parsed_data_queue = Queue() # parse_data_queue 队列 26 27 28 #1, 获取所有的url 29 def get_url_lists(self): # --> url_lists [] 30 for i in range(1,21): #爬取 1-20 页 ! 31 # for i in range(1,2): #爬取 1-2页 ! 32 #q1 url 入队列 33 self.url_queue.put(self.base_url.format(i)) 34 35 #2, 发送请求 36 def send_requests(self): 37 while True: 38 #q1' url 出队列 39 url = self.url_queue.get() 40 41 time.sleep(1) #加上延迟 42 response = requests.get(url,headers = self.headers) 43 44 #q2 响应对像 入队列 45 self.response_queue.put(response) 46 47 # url_response 出队列,如果想让计数器 减一,需要如下设置: 48 self.url_queue.task_done() 49 50 51 #3,解析数据 52 def parase_data(self): 53 while True: 54 #q2' response 队列 出队 55 data_str = self.response_queue.get().content.decode("gbk") 56 57 #a,转换类型 58 data_html = etree.HTML(data_str) 59 #b,解析数据 60 div_lists = data_html.xpath('//div[@class="post_recommend_new"]') #获取所有的帖子 61 62 for div in div_lists: 63 title = div.xpath('.//h3/a/text()')[0] 64 #q3 解析后的data 入队列 65 self.parsed_data_queue.put(title) 66 67 # response_queue出队列,如果想让计数器 减一,需要如下设置: 68 self.response_queue.task_done() 69 70 #4,保存数据 71 def save_to_file(self): 72 while True: 73 # parsed_data_queue 出队, 74 data_str = self.parsed_data_queue.get() 75 print(data_str) 76 77 # parsed_data_queue 出队列,如果想让计数器 减一,需要如下设置: 78 self.parsed_data_queue.task_done() 79 80 def _start(self): 81 # 开多线程 步骤: 1,创建线程 ,2, .setDameon(True)设置守护线程 3, .start() 开始执行 82 th_lists = [] 83 #1 获取url 线程 84 th_url = threading.Thread(target=self.get_url_lists ) #不需要传参数 85 th_lists.append(th_url) 86 #2 发送请求线程 87 #手动设置 并发数 88 th_send = threading.Thread(target=self.send_requests ) #不需要传参数 89 th_lists.append(th_send) 90 91 #3 解析数据线程 92 th_parse = threading.Thread(target=self.parase_data ) #不需要传参数 93 th_lists.append(th_parse) 94 #4 保存数据线程 95 th_save = threading.Thread(target=self.save_to_file) # 不需要传参数 96 th_lists.append(th_save) 97 98 #对四个线程 统一 设置守护线程 和 开始 99 for th in th_lists: 100 th.setDaemon(True) 101 th.start() 102 103 #注意,此时用队列来阻塞主线程 当三个队列都为0 时, 才不阻塞. 104 for q in [self.parsed_data_queue,self.response_queue,self.url_queue]: 105 q.join() 106 107 108 def run(self): 109 start_time = time.time() 110 self._start() 111 end_time = time.time() 112 113 print("总耗时:{} s".format(end_time-start_time)) # 输出: 总耗时:25.04452872276306 s 20页 114 115 116 if __name__ == '__main__': 117 QiuShiBaiKe().run() 118 119 120 121 122 ''' 123 import requests 124 import random 125 import json 126 from lxml import etree 127 import time 128 import threading 129 from queue import Queue 130 131 #用户代理池 132 USER_AGENT_LISTS = [] 133 with open("zcb/USER_AGENT.json","r",encoding="utf8") as f: 134 USER_AGENT_LISTS = json.load(f) 135 # PROXY_LISTS_ALL = [] 136 # with open("zcb/PROXY_LISTS.json", "r", encoding="utf8") as f: 137 # PROXY_LISTS_ALL = json.load(f) 138 139 class QiuShiBaiKe: 140 def __init__(self): 141 self.base_url = "http://www.lovehhy.net/News/List/ALL/{}/" 142 self.headers = {"User-Agent": random.choice(USER_AGENT_LISTS)} 143 144 #创建三个队列 145 self.url_queue = Queue() # url 队列 146 self.response_queue = Queue() # response 队列 147 self.parsed_data_queue = Queue() # parse_data_queue 队列 148 149 150 #1, 获取所有的url 151 def get_url_lists(self): # --> url_lists [] 152 for i in range(1,21): #爬取 1-20 页 ! 153 # for i in range(1,2): #爬取 1-2页 ! 154 #q1 url 入队列 155 self.url_queue.put(self.base_url.format(i)) 156 157 #2, 发送请求 158 def send_requests(self): 159 while True: 160 #q1' url 出队列 161 url = self.url_queue.get() 162 163 time.sleep(1) #加上延迟 164 response = requests.get(url,headers = self.headers) 165 166 #q2 响应对像 入队列 167 self.response_queue.put(response) 168 169 # url_response 出队列,如果想让计数器 减一,需要如下设置: 170 self.url_queue.task_done() 171 172 173 #3,解析数据 174 def parase_data(self): 175 while True: 176 #q2' response 队列 出队 177 data_str = self.response_queue.get().content.decode("gbk") 178 179 #a,转换类型 180 data_html = etree.HTML(data_str) 181 #b,解析数据 182 div_lists = data_html.xpath('//div[@class="post_recommend_new"]') #获取所有的帖子 183 184 for div in div_lists: 185 title = div.xpath('.//h3/a/text()')[0] 186 #q3 解析后的data 入队列 187 self.parsed_data_queue.put(title) 188 189 # response_queue出队列,如果想让计数器 减一,需要如下设置: 190 self.response_queue.task_done() 191 192 #4,保存数据 193 def save_to_file(self): 194 while True: 195 # parsed_data_queue 出队, 196 data_str = self.parsed_data_queue.get() 197 print(data_str) 198 199 # parsed_data_queue 出队列,如果想让计数器 减一,需要如下设置: 200 self.parsed_data_queue.task_done() 201 202 def _start(self): 203 # 开多线程 步骤: 1,创建线程 ,2, .setDameon(True)设置守护线程 3, .start() 开始执行 204 #1 获取url 线程 205 th_url = threading.Thread(target=self.get_url_lists ) #不需要传参数 206 th_url.setDaemon(True) #设置守护线程 207 th_url.start() 208 209 #2 发送请求线程 210 th_send = threading.Thread(target=self.send_requests ) #不需要传参数 211 th_send.setDaemon(True) #设置守护线程 212 th_send.start() 213 214 #3 解析数据线程 215 th_parse = threading.Thread(target=self.parase_data ) #不需要传参数 216 th_parse.setDaemon(True) #设置守护线程 217 th_parse.start() 218 219 #4 保存数据线程 220 th_save = threading.Thread(target=self.save_to_file) # 不需要传参数 221 th_save.setDaemon(True) # 设置守护线程 222 th_save.start() 223 224 def run(self): 225 start_time = time.time() 226 self._start() 227 end_time = time.time() 228 229 print("总耗时:{} s".format(end_time-start_time)) # 输出: 总耗时:26.19527816772461 s 20页 230 231 232 if __name__ == '__main__': 233 QiuShiBaiKe().run() 234 235 236 237 '''
此时的,发请求的线程 只有一个线程,这使得 发送请求也是一个一个的请求,所以我们可以给发请求多加几个线程。例如:给它变为三个线程:
1 import requests 2 import random 3 import json 4 from lxml import etree 5 import time 6 import threading 7 from queue import Queue 8 9 #用户代理池 10 USER_AGENT_LISTS = [] 11 with open("zcb/USER_AGENT.json","r",encoding="utf8") as f: 12 USER_AGENT_LISTS = json.load(f) 13 # PROXY_LISTS_ALL = [] 14 # with open("zcb/PROXY_LISTS.json", "r", encoding="utf8") as f: 15 # PROXY_LISTS_ALL = json.load(f) 16 17 class QiuShiBaiKe: 18 def __init__(self): 19 self.base_url = "http://www.lovehhy.net/News/List/ALL/{}/" 20 self.headers = {"User-Agent": random.choice(USER_AGENT_LISTS)} 21 22 #创建三个队列 23 self.url_queue = Queue() # url 队列 24 self.response_queue = Queue() # response 队列 25 self.parsed_data_queue = Queue() # parse_data_queue 队列 26 27 28 #1, 获取所有的url 29 def get_url_lists(self): # --> url_lists [] 30 for i in range(1,21): #爬取 1-20 页 ! 31 # for i in range(1,2): #爬取 1-2页 ! 32 #q1 url 入队列 33 self.url_queue.put(self.base_url.format(i)) 34 35 #2, 发送请求 36 def send_requests(self): 37 while True: 38 #q1' url 出队列 39 url = self.url_queue.get() 40 41 time.sleep(1) #加上延迟 42 response = requests.get(url,headers = self.headers) 43 44 #q2 响应对像 入队列 45 self.response_queue.put(response) 46 47 # url_response 出队列,如果想让计数器 减一,需要如下设置: 48 self.url_queue.task_done() 49 50 51 #3,解析数据 52 def parase_data(self): 53 while True: 54 #q2' response 队列 出队 55 data_str = self.response_queue.get().content.decode("gbk") 56 57 #a,转换类型 58 data_html = etree.HTML(data_str) 59 #b,解析数据 60 div_lists = data_html.xpath('//div[@class="post_recommend_new"]') #获取所有的帖子 61 62 for div in div_lists: 63 title = div.xpath('.//h3/a/text()')[0] 64 #q3 解析后的data 入队列 65 self.parsed_data_queue.put(title) 66 67 # response_queue出队列,如果想让计数器 减一,需要如下设置: 68 self.response_queue.task_done() 69 70 #4,保存数据 71 def save_to_file(self): 72 while True: 73 # parsed_data_queue 出队, 74 data_str = self.parsed_data_queue.get() 75 print(data_str) 76 77 # parsed_data_queue 出队列,如果想让计数器 减一,需要如下设置: 78 self.parsed_data_queue.task_done() 79 80 def _start(self): 81 # 开多线程 步骤: 1,创建线程 ,2, .setDameon(True)设置守护线程 3, .start() 开始执行 82 th_lists = [] 83 #1 获取url 线程 84 th_url = threading.Thread(target=self.get_url_lists ) #不需要传参数 85 th_lists.append(th_url) 86 #2 发送请求线程 87 # 把发送请求线程 开多一点: 88 for i in range(4): 89 #手动设置 并发数 90 th_send = threading.Thread(target=self.send_requests ) #不需要传参数 91 th_lists.append(th_send) 92 93 #3 解析数据线程 94 th_parse = threading.Thread(target=self.parase_data ) #不需要传参数 95 th_lists.append(th_parse) 96 #4 保存数据线程 97 th_save = threading.Thread(target=self.save_to_file) # 不需要传参数 98 th_lists.append(th_save) 99 100 #对四个线程 统一 设置守护线程 和 开始 101 for th in th_lists: 102 th.setDaemon(True) 103 th.start() 104 105 #注意,此时用队列来阻塞主线程 当三个队列都为0 时, 才不阻塞. 106 for q in [self.parsed_data_queue,self.response_queue,self.url_queue]: 107 q.join() 108 109 110 def run(self): 111 start_time = time.time() 112 self._start() 113 end_time = time.time() 114 115 print("总耗时:{} s".format(end_time-start_time)) #输出: 总耗时:7.036543369293213 s 116 117 118 if __name__ == '__main__': 119 QiuShiBaiKe().run()
此时的速度 快了一倍....
1 import requests 2 import random 3 import json 4 from lxml import etree 5 import time 6 import threading 7 from queue import Queue 8 9 #用户代理池 10 USER_AGENT_LISTS = [] 11 with open("zcb/USER_AGENT.json","r",encoding="utf8") as f: 12 USER_AGENT_LISTS = json.load(f) 13 # PROXY_LISTS_ALL = [] 14 # with open("zcb/PROXY_LISTS.json", "r", encoding="utf8") as f: 15 # PROXY_LISTS_ALL = json.load(f) 16 17 class QiuShiBaiKe: 18 def __init__(self): 19 self.base_url = "http://www.lovehhy.net/News/List/ALL/{}/" 20 self.headers = {"User-Agent": random.choice(USER_AGENT_LISTS)} 21 22 #创建三个队列 23 self.url_queue = Queue() # url 队列 24 self.response_queue = Queue() # response 队列 25 self.parsed_data_queue = Queue() # parse_data_queue 队列 26 27 28 #1, 获取所有的url 29 def get_url_lists(self): # --> url_lists [] 30 for i in range(1,21): #爬取 1-20 页 ! 31 # for i in range(1,2): #爬取 1-2页 ! 32 #q1 url 入队列 33 self.url_queue.put(self.base_url.format(i)) 34 35 #2, 发送请求 36 def send_requests(self): 37 while True: 38 #q1' url 出队列 39 url = self.url_queue.get() 40 41 time.sleep(1) #加上延迟 42 response = requests.get(url,headers = self.headers) 43 44 #q2 响应对像 入队列 45 self.response_queue.put(response) 46 47 # url_response 出队列,如果想让计数器 减一,需要如下设置: 48 self.url_queue.task_done() 49 50 51 #3,解析数据 52 def parase_data(self): 53 while True: 54 #q2' response 队列 出队 55 data_str = self.response_queue.get().content.decode("gbk") 56 57 #a,转换类型 58 data_html = etree.HTML(data_str) 59 #b,解析数据 60 div_lists = data_html.xpath('//div[@class="post_recommend_new"]') #获取所有的帖子 61 62 for div in div_lists: 63 title = div.xpath('.//h3/a/text()')[0] 64 #q3 解析后的data 入队列 65 self.parsed_data_queue.put(title) 66 67 # response_queue出队列,如果想让计数器 减一,需要如下设置: 68 self.response_queue.task_done() 69 70 #4,保存数据 71 def save_to_file(self): 72 while True: 73 # parsed_data_queue 出队, 74 data_str = self.parsed_data_queue.get() 75 print(data_str) 76 77 # parsed_data_queue 出队列,如果想让计数器 减一,需要如下设置: 78 self.parsed_data_queue.task_done() 79 80 def _start(self): 81 # 开多线程 步骤: 1,创建线程 ,2, .setDameon(True)设置守护线程 3, .start() 开始执行 82 th_lists = [] 83 #1 获取url 线程 84 th_url = threading.Thread(target=self.get_url_lists ) #不需要传参数 85 th_lists.append(th_url) 86 #2 发送请求线程 87 # 把发送请求线程 开多一点: 88 for i in range(20): 89 #手动设置 并发数 90 th_send = threading.Thread(target=self.send_requests ) #不需要传参数 91 th_lists.append(th_send) 92 93 #3 解析数据线程 94 th_parse = threading.Thread(target=self.parase_data ) #不需要传参数 95 th_lists.append(th_parse) 96 #4 保存数据线程 97 th_save = threading.Thread(target=self.save_to_file) # 不需要传参数 98 th_lists.append(th_save) 99 100 #对四个线程 统一 设置守护线程 和 开始 101 for th in th_lists: 102 th.setDaemon(True) 103 th.start() 104 105 #注意,此时用队列来阻塞主线程 当三个队列都为0 时, 才不阻塞. 106 for q in [self.url_queue,self.response_queue,self.parsed_data_queue]: 107 q.join() 108 109 110 def run(self): 111 start_time = time.time() 112 self._start() 113 end_time = time.time() 114 115 print("总耗时:{} s".format(end_time-start_time)) #输出: 总耗时:3.2620434761047363 s 116 117 118 if __name__ == '__main__': 119 QiuShiBaiKe().run()
但是,一般还是要合理设置 并发数,这个要考虑当前cpu ,当前带宽等。
例如:5M 带宽:5M:5000kb ,
==================================2================================
1 import requests 2 import random 3 import json 4 from lxml import etree 5 import time 6 from queue import Queue #线程队列! 7 import threading 8 9 #用户代理池 10 USER_AGENT_LISTS = [] 11 with open("USER_AGENT.json","r",encoding="utf8") as f: 12 USER_AGENT_LISTS = json.load(f) 13 PROXY_LISTS = [] 14 with open("PROXY_LISTS.json", "r", encoding="utf8") as f: 15 PROXY_LISTS = json.load(f) 16 17 class QiuShiBaiKe: 18 def __init__(self): 19 self.base_url = "http://www.lovehhy.net/News/List/ALL/{}" 20 self.url_queues = Queue() #url 队列 21 self.response_queues = Queue() #response 队列 22 self.parsed_data_queues = Queue() #parsed_data 队列 23 24 def getUrl_lists(self): 25 for i in range(1,51): #50个 url 的数据! 26 self.url_queues.put(self.base_url.format(i)) 27 28 def getResponses(self): 29 while True: 30 myHeaders = {"User-Agent":random.choice(USER_AGENT_LISTS)} 31 response = None 32 url = None 33 while True: 34 try: 35 url = self.url_queues.get() 36 self.url_queues.task_done() 37 response = requests.get(url,headers = myHeaders,proxies = random.choice(PROXY_LISTS),timeout = 3) 38 self.response_queues.put(response) 39 time.sleep(1) 40 break 41 except Exception as e: 42 print("出现异常") 43 self.url_queues.put(url) 44 self.getResponses() 45 46 def parse_data(self,response): 47 #1 转换类型 48 if response is None: 49 return None 50 data_html = etree.HTML(response.content.decode("gbk")) 51 #2, 解析数据 52 if data_html is None: 53 return None 54 titles = data_html.xpath('//div[@class="post_recommend_new"]//h3/a/text()') # 获取所有的帖子标题! 55 return titles 56 57 def getParsedData(self): 58 while True: 59 response = self.response_queues.get() 60 self.response_queues.task_done() 61 if self.parse_data(response) is None: 62 continue 63 for title in self.parse_data(response): 64 self.parsed_data_queues.put(title) 65 66 def save_to_file(self): 67 while True: 68 parsed_data = self.parsed_data_queues.get() 69 print(parsed_data) 70 self.parsed_data_queues.task_done() 71 72 73 def _start(self): 74 self.getUrl_lists() #使得 URL 存放到 url_queue 中 ! 75 76 #开启线程! 线程可以最多开 5*cpu = 20 77 # 5个线程 去 获取response ! 78 thread_lists = [] 79 for i in range(5): 80 thread = threading.Thread(target=self.getResponses) 81 thread_lists.append(thread) 82 83 # 1个线程 去 解析数据 84 thread_parse_data = threading.Thread(target=self.getParsedData) 85 thread_lists.append(thread_parse_data) 86 87 88 # 1个线程去 保存数据 89 thread_save_to_file = threading.Thread(target=self.save_to_file) 90 thread_lists.append(thread_save_to_file) 91 92 93 #统一设置所有线程为 守护线程 并 开始 线程 94 for thread in thread_lists: 95 thread.daemon = True 96 thread.start() 97 98 # 统一阻塞 主线程 这里使用队列 来阻塞主线程 ! 99 self.url_queues.join() 100 self.response_queues.join() 101 self.parsed_data_queues.join() 102 time.sleep(10) 103 104 105 def run(self): 106 t = time.time() 107 self._start() 108 print("总耗时:",time.time()- t) #总耗时:0.06149625778198242 109 110 if __name__ == '__main__': 111 #http://www.lovehhy.net/News/List/ALL/1 112 QiuShiBaiKe().run()
1 import requests 2 import random 3 import json 4 from lxml import etree 5 import time 6 from queue import Queue #线程队列! 7 import threading 8 9 class QiuShiBaiKe: 10 def __init__(self): 11 self.base_url = "http://www.lovehhy.net/News/List/ALL/{}" 12 self.USER_AGENT_LISTS = [] 13 self.PROXY_LISTS = [] 14 self.init_ua_proxy() 15 16 self.url_queues = Queue() #url 队列 17 self.response_queues = Queue() #response 队列 18 self.parsed_data_queues = Queue() #parsed_data 队列 19 self.count = 0 20 21 def init_ua_proxy(self): 22 with open("USER_AGENT.json", "r", encoding="utf8") as f: 23 self.USER_AGENT_LISTS = json.load(f) 24 with open("PROXY_LISTS.json", "r", encoding="utf8") as f: 25 self.PROXY_LISTS = json.load(f) 26 27 def getUrl_lists(self): 28 for i in range(1,301): #301 29 self.url_queues.put(self.base_url.format(i)) 30 31 def getResponses(self): 32 while True: 33 response = None #仅仅是声明 作用 34 url = self.url_queues.get() 35 self.url_queues.task_done() 36 while True: 37 try: 38 myHeaders = {"User-Agent": random.choice(self.USER_AGENT_LISTS)} 39 response = requests.get(url,headers = myHeaders,proxies = random.choice(self.PROXY_LISTS),timeout = 3) 40 self.response_queues.put(response) 41 time.sleep(1) 42 break 43 except Exception as e: 44 print("出现异常...",e) 45 # print("urlqueue size: ",self.url_queues.qsize()) 46 self.url_queues.put(url) 47 print("urlqueue size: ",self.url_queues.qsize()) 48 self.getResponses() 49 50 def parse_data(self,response): 51 #1 转换类型 52 if response is None: 53 return None 54 55 data_html = None 56 try: 57 data_html = etree.HTML(response.content.decode("gbk")) 58 except Exception as e: 59 print("解析数据出现错误!") 60 #2, 解析数据 61 if data_html is None: 62 return None 63 titles = data_html.xpath('//div[@class="post_recommend_new"]//h3/a/text()') # 获取所有的帖子标题! 64 return titles 65 66 def getParsedData(self): 67 while True: 68 response = self.response_queues.get() 69 self.response_queues.task_done() 70 if self.parse_data(response) is None: 71 continue 72 for title in self.parse_data(response): 73 self.parsed_data_queues.put(title) 74 75 def save_to_file(self): 76 while True: 77 parsed_data = self.parsed_data_queues.get() 78 # print(parsed_data) 79 self.count += 1 80 self.parsed_data_queues.task_done() 81 82 def _start(self): 83 self.getUrl_lists() #使得 URL 存放到 url_queue 中 ! 84 85 #开启线程! 线程可以最多开 5*cpu = 20 86 # 5个线程 去 获取response ! 87 thread_lists = [] 88 for i in range(20): #5*cpu 89 thread = threading.Thread(target=self.getResponses) 90 thread_lists.append(thread) 91 92 # 1个线程 去 解析数据 93 thread_parse_data = threading.Thread(target=self.getParsedData) 94 thread_lists.append(thread_parse_data) 95 96 97 # 1个线程去 保存数据 98 thread_save_to_file = threading.Thread(target=self.save_to_file) 99 thread_lists.append(thread_save_to_file) 100 101 102 #统一设置所有线程为 守护线程 并 开始 线程 103 for thread in thread_lists: 104 thread.daemon = True 105 thread.start() 106 107 # 统一阻塞 主线程 这里使用队列 来阻塞主线程 ! 108 self.url_queues.join() 109 self.response_queues.join() 110 self.parsed_data_queues.join() 111 112 for i in range(5): 113 time.sleep(5) # timeout + sleep = 5 114 self.url_queues.join() 115 self.response_queues.join() 116 self.parsed_data_queues.join() 117 118 def run(self): 119 t = time.time() 120 self._start() 121 print("总耗时:",time.time()- t -25) #总耗时:0.06149625778198242 122 print("总共有 :",self.count) 123 return self.count 124 if __name__ == '__main__': 125 #http://www.lovehhy.net/News/List/ALL/1 126 QiuShiBaiKe().run()
1 import requests 2 import random 3 import json 4 from lxml import etree 5 import time 6 from queue import Queue #线程队列! 7 import threading 8 9 class QiuShiBaiKe: 10 def __init__(self): 11 self.base_url = "http://www.lovehhy.net/News/List/ALL/{}" 12 self.USER_AGENT_LISTS = [] 13 self.PROXY_LISTS = [] 14 self.init_ua_proxy() 15 16 self.url_queues = Queue() #url 队列 17 self.response_queues = Queue() #response 队列 18 self.parsed_data_queues = Queue() #parsed_data 队列 19 self.count = 0 20 self.exceptionNum = 0 21 22 def init_ua_proxy(self): 23 with open("USER_AGENT.json", "r", encoding="utf8") as f: 24 self.USER_AGENT_LISTS = json.load(f) 25 with open("PROXY_LISTS.json", "r", encoding="utf8") as f: 26 self.PROXY_LISTS = json.load(f) 27 28 def getUrl_lists(self): 29 # 400 ----》 480 30 # 350 -----》 417 31 # 300 ---》 318 32 for i in range(1,300): #301 33 self.url_queues.put(self.base_url.format(i)) 34 35 def getResponses(self): 36 while True: 37 response = None #仅仅是声明 作用 38 url = self.url_queues.get() 39 self.url_queues.task_done() 40 while True: 41 try: 42 myHeaders = {"User-Agent": random.choice(self.USER_AGENT_LISTS)} 43 response = requests.get(url,headers = myHeaders,proxies = random.choice(self.PROXY_LISTS),timeout = 3) 44 self.response_queues.put(response) 45 time.sleep(1) 46 break 47 except Exception as e: 48 print("出现异常...",e) 49 self.exceptionNum += 1 50 # print("urlqueue size: ",self.url_queues.qsize()) 51 self.url_queues.put(url) 52 print("urlqueue size: ",self.url_queues.qsize()) 53 self.getResponses() 54 55 def parse_data(self,response): 56 #1 转换类型 57 if response is None: 58 return None 59 data_html = None 60 try: 61 data_html = etree.HTML(response.content.decode("gbk")) 62 except Exception as e: 63 print("解析数据出现错误!") 64 #2, 解析数据 65 if data_html is None: 66 return None 67 titles = data_html.xpath('//div[@class="post_recommend_new"]//h3/a/text()') # 获取所有的帖子标题! 68 return titles 69 70 def getParsedData(self): 71 while True: 72 response = self.response_queues.get() 73 self.response_queues.task_done() 74 titles = self.parse_data(response) 75 if titles is None: 76 continue 77 for title in titles: 78 self.parsed_data_queues.put(title) 79 80 def save_to_file(self): 81 while True: 82 parsed_data = self.parsed_data_queues.get() 83 # print(parsed_data) 84 self.count += 1 85 self.parsed_data_queues.task_done() 86 87 def _start(self): 88 self.getUrl_lists() #使得 URL 存放到 url_queue 中 ! 89 90 #开启线程! 线程可以最多开 5*cpu = 20 91 # 5个线程 去 获取response ! 92 thread_lists = [] 93 for i in range(20): #5*cpu 94 thread = threading.Thread(target=self.getResponses) 95 thread_lists.append(thread) 96 97 # 1个线程 去 解析数据 98 thread_parse_data = threading.Thread(target=self.getParsedData) 99 thread_lists.append(thread_parse_data) 100 101 102 # 1个线程去 保存数据 103 thread_save_to_file = threading.Thread(target=self.save_to_file) 104 thread_lists.append(thread_save_to_file) 105 106 107 #统一设置所有线程为 守护线程 并 开始 线程 108 for thread in thread_lists: 109 thread.daemon = True 110 thread.start() 111 112 # 统一阻塞 主线程 这里使用队列 来阻塞主线程 ! 113 self.url_queues.join() 114 self.response_queues.join() 115 self.parsed_data_queues.join() 116 117 for i in range(5): 118 time.sleep(6) # timeout + sleep = 5 119 self.url_queues.join() 120 self.response_queues.join() 121 self.parsed_data_queues.join() 122 123 def run(self): 124 t = time.time() 125 self._start() 126 print("总耗时:",time.time()- t) #总耗时:0.06149625778198242 127 print("总共有 :",self.count) 128 print("总共发生异常数:",self.exceptionNum) 129 130 return self.count 131 if __name__ == '__main__': 132 #http://www.lovehhy.net/News/List/ALL/1 133 QiuShiBaiKe().run()
多进程:
多进程 使用的队列 是 :
from multiprocessing.queue import JoinableQueue as Queue
起别名 是为了 和 线程的程序统一!!
线程池:
from multiprocessing.dummy import Pool
1 import requests 2 import random 3 import json 4 from lxml import etree 5 import time 6 from multiprocessing.dummy import Pool as ThreadPool #线程池! 7 from queue import Queue #线程队列! 8 9 class QiuShiBaiKe: 10 def __init__(self): 11 self.base_url = "http://www.lovehhy.net/News/List/ALL/{}" 12 self.USER_AGENT_LISTS = [] 13 self.PROXY_LISTS = [] 14 self.init_ua_proxy() 15 16 self.url_queues = Queue() #url 队列 17 self.threadPool = ThreadPool(5) #线程池 18 self.count = 0 19 20 self.task_num = 0 21 self.solved_task_num = 0 22 23 def init_ua_proxy(self): 24 with open("USER_AGENT.json", "r", encoding="utf8") as f: 25 self.USER_AGENT_LISTS = json.load(f) 26 with open("PROXY_LISTS.json", "r", encoding="utf8") as f: 27 self.PROXY_LISTS = json.load(f) 28 def getUrl_lists(self): 29 for i in range(1,301): #301 30 self.url_queues.put(self.base_url.format(i)) 31 self.task_num += 1 32 #=================================== 33 def getResponses(self,url): 34 response = None #仅仅是声明 作用 35 while True: 36 try: 37 myHeaders = {"User-Agent": random.choice(self.USER_AGENT_LISTS)} 38 response = requests.get(url,headers = myHeaders,proxies = random.choice(self.PROXY_LISTS),timeout = 3) 39 time.sleep(1) 40 break 41 except Exception as e: 42 print("出现异常...",e) 43 print("urlqueue size: ",self.url_queues.qsize()) 44 self.getResponses(url) 45 return response 46 47 def parse_data(self,response): 48 #1 转换类型 49 if response is None: 50 return None 51 52 data_html = None 53 try: 54 data_html = etree.HTML(response.content.decode("gbk")) 55 except Exception as e: 56 print("解析数据出现错误!") 57 #2, 解析数据 58 if data_html is None: 59 return None 60 titles = data_html.xpath('//div[@class="post_recommend_new"]//h3/a/text()') # 获取所有的帖子标题! 61 return titles 62 def getParsedData(self,response): 63 titles = self.parse_data(response) 64 if titles is None: 65 return None 66 return titles 67 68 def save_to_file(self,titles): 69 if titles is not None: 70 for title in titles: 71 # print(title) 72 self.count += 1 73 #=================================== 74 75 # 我们的主任务!!! 76 def _start(self): 77 url = self.url_queues.get() 78 self.url_queues.task_done() 79 80 response = self.getResponses(url) 81 titles = self.getParsedData(response) 82 self.save_to_file(titles) 83 self.solved_task_num += 1 84 85 def cl_bk(self,temp): #temp 一定要有 86 self.threadPool.apply_async(self._start, callback=self.cl_bk) 87 # print(temp) 88 def async_entry(self): 89 self.getUrl_lists() # 首先把构建所有的url 90 91 for i in range(5): # 一次看 20个线程 92 self.threadPool.apply_async(self._start,callback=self.cl_bk) 93 94 while True: # 在此阻塞 主线程 ! 95 #最重要的问题是:什么时候 解阻塞! 当 任务的已经解决数 大于 总任务数 的时候 ! 96 if self.solved_task_num >= self.task_num : 97 break 98 time.sleep(0.1) 99 100 def run(self): 101 t = time.time() 102 self.async_entry() 103 print("总耗时:",time.time()- t) 104 print("总共有 :",self.count) 105 106 if __name__ == '__main__': 107 #http://www.lovehhy.net/News/List/ALL/1 108 QiuShiBaiKe().run()
协程:
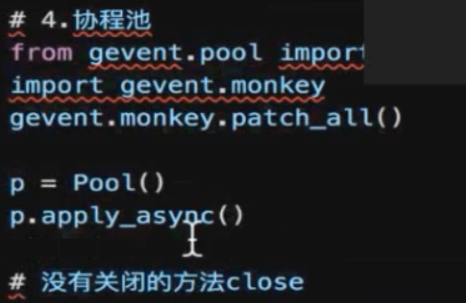
上面 的线程池 也没用close !
1 from gevent import monkey 2 from gevent.pool import Pool as gPool #协程池 3 monkey.patch_all() 4 import gevent 5 6 import requests 7 import random 8 import json 9 from lxml import etree 10 import time 11 12 from queue import Queue #线程队列! 13 14 class QiuShiBaiKe: 15 def __init__(self): 16 self.base_url = "http://www.lovehhy.net/News/List/ALL/{}" 17 self.USER_AGENT_LISTS = [] 18 self.PROXY_LISTS = [] 19 self.init_ua_proxy() 20 21 self.url_queues = Queue() #url 队列 22 self.gPool = gPool(5) #线程池 23 self.count = 0 24 25 self.task_num = 0 26 self.solved_task_num = 0 27 28 def init_ua_proxy(self): 29 with open("USER_AGENT.json", "r", encoding="utf8") as f: 30 self.USER_AGENT_LISTS = json.load(f) 31 with open("PROXY_LISTS.json", "r", encoding="utf8") as f: 32 self.PROXY_LISTS = json.load(f) 33 def getUrl_lists(self): 34 for i in range(1,5): #301 35 self.url_queues.put(self.base_url.format(i)) 36 self.task_num += 1 37 #=================================== 38 def getResponses(self,url): 39 response = None #仅仅是声明 作用 40 while True: 41 try: 42 myHeaders = {"User-Agent": random.choice(self.USER_AGENT_LISTS)} 43 response = requests.get(url,headers = myHeaders,proxies = random.choice(self.PROXY_LISTS),timeout = 3) 44 time.sleep(1) 45 break 46 except Exception as e: 47 print("出现异常...",e) 48 print("urlqueue size: ",self.url_queues.qsize()) 49 self.getResponses(url) 50 return response 51 52 def parse_data(self,response): 53 #1 转换类型 54 if response is None: 55 return None 56 57 data_html = None 58 try: 59 data_html = etree.HTML(response.content.decode("gbk")) 60 except Exception as e: 61 print("解析数据出现错误!") 62 #2, 解析数据 63 if data_html is None: 64 return None 65 titles = data_html.xpath('//div[@class="post_recommend_new"]//h3/a/text()') # 获取所有的帖子标题! 66 return titles 67 def getParsedData(self,response): 68 titles = self.parse_data(response) 69 if titles is None: 70 return None 71 return titles 72 73 def save_to_file(self,titles): 74 if titles is not None: 75 for title in titles: 76 print(title) 77 self.count += 1 78 #=================================== 79 80 # 我们的主任务!!! 81 def _start(self): 82 url = self.url_queues.get() 83 self.url_queues.task_done() 84 85 response = self.getResponses(url) 86 titles = self.getParsedData(response) 87 self.save_to_file(titles) 88 self.solved_task_num += 1 89 90 def cl_bk(self,temp): #temp 一定要有 91 self.gPool.apply_async(self._start, callback=self.cl_bk) 92 # print(temp) 93 def async_entry(self): 94 self.getUrl_lists() # 首先把构建所有的url 95 96 for i in range(5): # 5个线程 97 self.gPool.apply_async(self._start,callback=self.cl_bk) 98 99 while True: # 在此阻塞 主线程 ! 100 #最重要的问题是:什么时候 解阻塞! 当 任务的已经解决数 大于 总任务数 的时候 ! 101 if self.solved_task_num >= self.task_num : 102 break 103 time.sleep(0.1) 104 105 def run(self): 106 t = time.time() 107 self.async_entry() 108 print("总耗时:",time.time()- t) 109 print("总共有 :",self.count) 110 111 if __name__ == '__main__': 112 #http://www.lovehhy.net/News/List/ALL/1 113 QiuShiBaiKe().run()
selenium 的基本使用:
1 from selenium import webdriver 2 3 4 if __name__ == '__main__': 5 # #1, 创建浏览器 对象 6 driver = webdriver.Chrome() 7 # #2, get发送请求 8 driver.get("http://www.jsons.cn/urlencode/") 9 10 driver.save_screenshot("01.png") 11 12 # 新开了一个 窗口! 13 element = driver.find_element_by_xpath('//div[@class="copyright"]//span[2]/a') 14 element.click() 15 16 # 查看浏览器 打开的窗口 17 print(driver.window_handles) 18 19 #打开 新的窗口 20 # driver.switch_to_window(driver.window_handles[1]) 21 driver.switch_to.window(driver.window_handles[1]) 22 driver.save_screenshot("02.png") 23 24 25 # #4,关闭浏览器 26 # driver.quit() 27 28 pass