python字典的键值对输出次序问题:
在2.7-3.5的python版本中,字典的键值对是按照哈希表的存储顺序排列输出的,
而在3.6及以上版本中, 字典的键值对是按照初始化时的排列顺序输出的。
python 中 可变类型 和 不可变类型:
将python中的类型分为 两个大类,可变 和 不可变,
可变:list dict set
不可变:str,int(float),bool,tuple
python 中的缓存 和 小数据池:

小数据池 指的是 不同代码块下的 缓存机制,只是 缩小了 数字 的范围, 和 少的字符串, 都是为了提升性能,
python 中 深浅copy:
对于一个 嵌套的列表,
浅copy 是只新 copy 一个列表外壳,
深copy 除了copy 一个新的列表外壳,内部的也会copy新的内存,
1 def func(): 2 #1, 赋值 不 创建新内存空间 3 ''' 4 a = [1,2,3 ,[4,5,6]] 5 b = a 6 print(id(a),id(b)) 7 print(id(a[-1]),id(b[-1])) 8 ''' 9 10 # copy 指的就是要创建新的 内存空间 11 #2,浅copy 12 ''' 13 c = [1, 2, 3, [4, 5, 6]] 14 d = c.copy() # 这是浅copy 15 print(id(c),id(d)) 16 print(id(c[-1]),id(d[-1])) 17 # 所以浅copy 只是copy 一个外壳 18 ''' 19 20 #3,深copy 创建新的内存空间最多 21 ''' 22 from copy import deepcopy 23 e = [1, 2, 3, [4, 5, 6]] 24 f = deepcopy(e) 25 print(id(e),id(f)) 26 print(id(e[-1]),id(f[-1])) 27 ''' 28 # 所以,深copy 不只是新创建了一个壳子,而且也新创建了 里面的小壳子 29 30 if __name__ == '__main__': 31 func()
注: python 对深copy 也不是一味的开辟新内存,它是有条件的,对于不可变类型是不会 开辟的,例如:str,int ,float ,tuple!
还有,切片操作是 浅copy ,
1 l1 = [1,2,3,[11,22,33]] 2 l2 = l1[:] (浅copy ) 3 l1.append(666) 4 print(l1) 5 print(l2)
Python中 可以给数据 组合加上 索引的enumerate 函数:
enumerate() 函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中:
1 def func(): 2 ''' 3 l = ["tom","a","b"] 4 5 ret = enumerate(l) 6 print(ret) # <enumerate object at 0x0371E198> #该对象 可迭代 7 for item in ret: 8 print(item) 9 ''' 10 11 ''' 12 s = "abcdefg" 13 ret = enumerate(s) 14 print(ret) 15 for item in ret: 16 print(item) 17 ''' 18 19 s = "woqu" 20 # 多用于 for in 结构 21 for item in enumerate(s): 22 print(item) 23 24 25 26 27 if __name__ == '__main__': 28 func()
Python中 编码 Unicode 和 utf-8/gbk 相关:
1 def func(): 2 3 s = "hello 世界" #s 是在内存中,它是Unicode 编码,(必须要转为 非unicode 才可以用于 网络传输 或 保存到硬盘 ) 4 print(s,type(s)) 5 6 #Python 中 所有的数据类型里,只有 字节类型(bytes) 的编码方式 是 非unicode 7 8 b = s.encode() # 默认编码 utf8 一个汉字 3个字节 # b此时在内存 是utf8 编码 b数据类型是bytes 9 print(b,type(b)) 10 11 c = s.encode(encoding="gbk") #gbk 一个汉字2个字节 # c 此时在内存中是 gbk编码 c数据类型是 bytes 12 print(c,type(c)) 13 14 # 如何将c (gbk): hello xcaxc0xbdxe7 转为 b(utf8) :hello xe4xb8x96xe7x95x8c 呢? 15 # 这要通过 unicode 中间 转化, 因此需要通过 str 类型 (unicode) 转化, 16 ''' 17 # d = c.decode(encoding="utf8") # 这肯定不行,c 是以 gbk编码的,必须以 gbk解码 18 d = c.decode(encoding="gbk") 19 print(d,type(d)) 20 21 # 然后 再将 d 转为 utf8 22 e = d.encode(encoding="utf8") 23 print(e,type(e)) 24 25 ''' 26 27 # 总结: 28 # 1,内存中的数据类型 除了bytes 都是 Unicode , 29 # 2,要想保存硬盘 或网络传输 必须要是 非Unicode ( utf8 / gbk), 所以,保存 或 传输 要转为 bytes 类型 30 # 3,非 Unicode 之间 如果想互转 要通过Unicode 来转 31 32 if __name__ == '__main__': 33 func()
bytes 的使用:
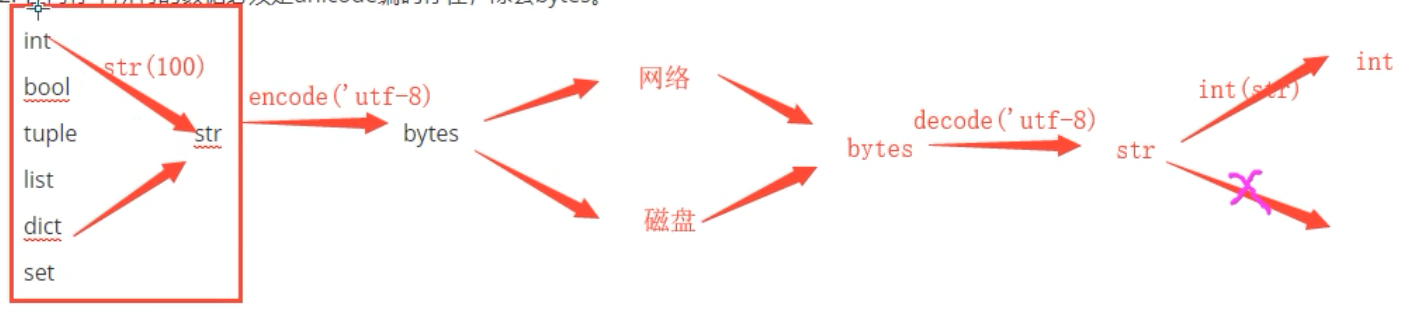
不过,以后不会直接用 str 中转 ,因为如果字典 没办法直接 变为 str ,和 从str 再变回来, 一般使用json 模块 的loads() 和 dumps() ,
如下:
1 import json 2 def func(): 3 d = {'name':'a'} 4 5 # 将字典 变为 utf8 用于传输 6 ret = json.dumps(d).encode("utf8") 7 print(ret,type(ret) ) 8 9 # loads 直接可以转为 程序中使用的字典 10 ret2 = json.loads(ret) 11 print(ret2,type(ret2)) 12 13 if __name__ == '__main__': 14 func()
Python 中的 *args 和 **kwargs :
1 def func(a,*args,b=0,**kwargs): #位置参数 和 关键字参数 和 args 和 kwargs 的顺序 2 print(a) 3 print(b) 4 print(args) 5 print(kwargs) 6 7 if __name__ == '__main__': 8 func(1,2,1,2,b=10,d=1)
注:形参位置 * 和 ** 代表的都是聚合, *代表把位置参数聚合成一个元祖, ** 代表把关键字参数聚合成一个 字典 。
实参位置的* 和 ** 代表 的是打散,


1 ''' 2 def func(): 3 a= [1,2,3] 4 print(a) 5 print(*a) # 在实参位置 * 代表打散 6 ''' 7 def func2(a,b,c): 8 print(a) 9 print(b) 10 print(c) 11 12 def func3(name,age): 13 print(name) 14 print(age) 15 16 17 if __name__ == '__main__': 18 # func() 19 20 temp = [1,2,3] 21 func2(*temp) # * 在实参位置 处代表 打散 --> func2(1,2,3) 22 23 temp = {"name":"tom","age":18} 24 func3(**temp) # ** 在实参位置 代表 打散 --> func3(name='tom',age=18) 25 26 # 注: 实参位置要求 只要是可迭代对象 都可以被* 或 ** 打散 27 # 例如 28 ''' 29 temp = "abc" 30 def func4(a,b,c): 31 print(a) 32 print(b) 33 print(c) 34 35 func4(*temp) 36 '''
*的其他用法:
* 除了可以 聚合 和 打散之外,还可以用于 处理剩下的元素:
1 def func(): 2 a,*b = range(1,10) 3 print(a) #1 4 print(b) #[2, 3, 4, 5, 6, 7, 8, 9] 5 6 if __name__ == '__main__': 7 func()
Python 中的 命名空间 :
总共有 三个命名空间: 内置 命名空间, 全局命名空间,局部命名空间,
它的加载顺序是 : 内置命名空间 --> 全局命名空间 --> 局部命名空间。
查找变量顺序 符合 就近原则 !
Python 中的 作用域:
总共两个 作用域:
全局作用域: 内置命名空间 和 全局命名空间
局部作用域: 局部命名空间
局部作用域 里 只可以使用(不可修改)全局作用域里的 变量,
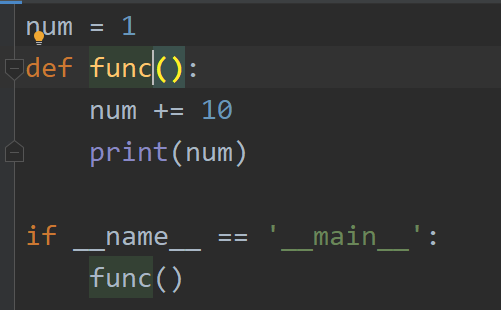
此时会报错,为什么?
因为 当我们在局部作用域中修改一个 变量的时候,解释器会认为我们已经在局部作用域定义了这个变量,所以报错,
UnboundLocalError: local variable 'num' referenced before assignment
解决方法:可以使用global 关键字 把num 声明为 全局作用域中 的变量num ,此时就可以更改了。
除了,局部 和 全局, 如果局部中又有 局部,也是如此~
Python 中的 高阶函数 :
高阶函数:一个函数可以作为参数传给另外一个函数,或者作为一个函数的返回值,满足其一则为高阶函数。
1 def test(): 2 print("I am test") 3 4 def func(f): 5 print("I am func") 6 f() 7 return f 8 9 if __name__ == '__main__': 10 ret = func(test) # func() 函数的参数为 一个函数, 故func() 为高阶函数 11 12 # func() 函数的 返回值 为一个函数,故func() 为高阶函数 13 ret()
常见的高阶函数: map() reduce() filter() 它们也都是内置函数
1 def add(x): 2 return x+1 3 4 def test(): 5 l = [1, 2, 3, 4, 5] 6 ret = map(add,l) # 因为 内置函数map 的参数 有一个为函数,故为高阶函数 7 print(ret) 8 print(list(ret)) 9 10 11 if __name__ == '__main__': 12 test()
1 def isTrue(x): 2 if x>20: 3 return True 4 5 def func(): 6 l = [17,18,19,20,21,22,23] 7 ret = filter(isTrue,l) 8 print(ret) 9 print(list(ret)) 10 11 12 if __name__ == '__main__': 13 func()
1 from functools import reduce # reduce 使用的时候要先导入 2 3 def test(x,y): # 定义 reduce 的方式 4 return 2*x + y 5 6 def func(): 7 l = [17,18,19,20,21,22] 8 ret = reduce(test,l) # 整个过程等同于: 2*(2*(2*(2*(2*17 + 18)+19)+20)+21)+22 9 print(ret) 10 print(2*(2*(2*(2*(2*17 + 18)+19)+20)+21)+22) 11 12 if __name__ == '__main__': 13 func()
注:reduce 使用前要导入
总结: map 和 filter 是迭代的时候 不管前后元素, reduce 迭代的时候 是前后元素一起来的,
Python 中的 globals() 和 locals() 两个内置函数 :
globals() 返回一个字典:包含全局作用域(内置+全局) 中的所有内容
locals() 返回一个字典:包含当前作用域 中的所有内容
1 name = "tom" 2 age = 18 3 def func(): 4 a = 1 5 b = 'jack' 6 7 print(globals()) 8 print(locals()) 9 10 11 if __name__ == '__main__': 12 print(globals()) 13 print(locals()) 14 func() 15 ''' 16 总结: 17 globals() 返回一个字典:包含全局作用域(内置+全局) 中的所有内容 18 locals() 返回一个字典:包含当前作用域 中的所有内容 19 '''
Python 函数的 默认参数的坑:
默认参数针对的是形参,
1 def func(a,l=[]): # 默认参数的 坑 (只针对 可变数据类型 ) 2 l.append(a) 3 return l 4 5 if __name__ == '__main__': 6 ret = func('tom') 7 print(ret) # ['tom'] 8 ret2 = func('jack') 9 print(ret2) # ['tom', 'jack'] 按理说应该是 ['jack'] 10 #总结: 对于默认参数,如果是可变数据类型,那么为了 提高性能 也是不会重复创建的
1 def func(a,l=[]): 2 l.append(a) 3 return l 4 5 if __name__ == '__main__': 6 ret1 = func(1) 7 print(ret1) 8 ret2 = func(2,[]) 9 print(ret2) 10 ret3 = func(3) 11 print(ret3) 12 # 其中 ret1 和 ret3 是同一个内存地址 ret2 是另一个内存地址
对于 默认参数,如果是可变类型,如果不传入的话,沿用的还是同一个,如果传入 的话,是新的一个 。
Python 中的 偏函数:
它的作用是:将函数 和 实参 存起来,执行时一起执行,
from functools import partial # 偏函数 def sumTwo(a,b): return a+b new_sum = partial(sumTwo,1,2) # print(new_sum) print(new_sum())
它在flask 的源码中可以看到,
Python 中 global 和 nonlocal 关键字:
1,global 关键字 是在 “局部” 作用域 声明一个全局变量 。
1 def func(): 2 global num 3 num = 10 4 5 if __name__ == '__main__': 6 func() 7 print(num)
在局部的局部也可用 global 声明一个全局变量,
1 def func(): 2 def test(): 3 global num 4 num = 10 5 test() 6 7 8 if __name__ == '__main__': 9 func() 10 print(num)
global 关键字也可以修改全局变量,
2,nonlocal 关键字
(1)不能操作全局变量
(2)它主要是 内层函数 对 外层函数 变量 进行修改
1 def func(): 2 num = 1 3 def a(): 4 def test(): 5 nonlocal num 6 num = 10 7 test() 8 print(num) 9 a() 10 print(num) 11 12 if __name__ == '__main__': 13 func()
Python 中 获取一个对象的所有方法名字 返回一个列表 dir() 内置函数:
1 l = [1,2,3,4] 2 3 if __name__ == '__main__': 4 print(dir(l)) 5 ''' 6 ['__add__', '__class__', '__contains__', '__delattr__', '__delitem__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__gt__', '__hash__', '__iadd__', '__imul__', '__init__', '__init_subclass__', '__iter__', '__le__', '__len__', '__lt__', '__mul__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__reversed__', '__rmul__', '__setattr__', '__setitem__', '__sizeof__', '__str__', '__subclasshook__', 'append', 'clear', 'copy', 'count', 'extend', 'index', 'insert', 'pop', 'remove', 'reverse', 'sort'] 7 ''' 8 #因为 __iter__ 在里面,__next__ 不在里面,所以列表对象是 可迭代对象, 但是不是迭代器对象
Python 中 dir() 和 __dict__() 的区别:
在python中__dict__与dir()都可以返回一个对象的属性,区别在于:
1,__dict__是对象的一个属性,而dir()是一个内置函数
2,__dict__返回一个对象的属性名和值,即dict类型,而dir()返回一个属性名的list;
3,__dict__不是每一个对象都有,而dir()对各种类型对象都起作用,如module, type, class, object;
4,_dict__只返回对象的可写属性(writable attributes),而dir()返回各种相关(relavent)属性,且对于不同类型对象,作用不同。
Python 中 可迭代对象 和 迭代器对象:
可迭代对象: 对象所对应类 的中 有 __iter__() 保留方法,
迭代器对象:对象所对应的类 中有 __iter__() 并且 也有 __next__() 保留方法,
因此,一个对象如果是迭代器对象,那么必是可迭代对象,但是是可迭代对象 不一定是迭代器对象 。
1 from _collections_abc import Iterable,Iterator 2 l = [1,2,3,4] 3 if __name__ == '__main__': 4 print(issubclass(type(l), Iterable)) # Iterable 内部是验证 是否有 __iter__ 保留方法 5 print(issubclass(type(l), Iterator)) # Iterator 内部是验证 是否有 __iter__ 和 __next__ 保留方法 6
Iterable 用来检查是否是 可迭代对象,
Iterator 用来检查是否是 迭代器对象 ,
可迭代对象 不可以直接遍历, 迭代器才可以遍历,
Python 中如何将 可迭代对象 转化为 迭代器对象:
通过 iter() 内置函数 / .__Iter__() 进行转换
1 from _collections_abc import Iterator 2 l = [1,2,3,4] 3 4 if __name__ == '__main__': 5 # 已知 l 是可迭代对象,但不是 迭代器对象 6 ret = iter(l) 7 print(type(ret),issubclass(type(ret),Iterator))
可迭代对象 是不可以直接取值的,(之所以 for 循环可以取值,是for in 结构内部做了转换 ,已经转换为了 迭代器对象, )
Python 中如何 使用 迭代器对象:
通过next() 内置函数,或者 .__next__() 方法来取 迭代器对象中的值,
使用 迭代器对象 的特点:
优点:
1,节省内存
2,惰性机制,next()一次,取一个值
缺点:
1,速度慢
2,只能遍历一次
Python 中 生成器 对象:
生成器对象 是迭代器对象 的一种,
构建 生成器对象 的方法:
1,生成器函数 的返回值,
什么是生成器函数呢? 函数中有 yield 关键字 即为生成器函数
1 def func(): 2 print('a') 3 print('a') 4 yield 3 5 6 print(func) # func 仍然是个 函数 <function func at 0x10E8EFA8> 7 ret = func() 8 print(ret) # ret 是个生成器对象 <generator object func at 0x0362F150>
2,生成器表达式 的返回值
1 ret = (i for i in range(10)) 2 print(ret) #<generator object <genexpr> at 0x0362F120>
1,生成器 函数:
在 Python 中,有 yield 的 函数 被称为生成器函数 ,
生成器每次到 调用yield时 会暂停,而可以使用next()函数和send()函数恢复生成器。
1 def func(): 2 print('a') 3 a = yield 3 #暂停点 4 print("=======") 5 print(a) 6 print('b') 7 yield 2 8 9 ret = func() 10 # ret 为一个生成器对象 11 ret1 = next(ret) 12 print(ret1) 13 14 ret2 = next(ret) 15 print(ret2) 16 17 ''' 18 a 19 3 20 ======= 21 None 22 b 23 2 24 25 '''
1 def func(): 2 print('a') 3 a = yield 3 4 print("=======") 5 print(a) 6 print('b') 7 yield 2 8 9 ret = func() 10 # ret 为一个生成器对象 11 ret1 = next(ret) 12 print(ret1) 13 14 ret2 = ret.send({'name':'tom'}) 15 print(ret2) 16 ''' 17 a 18 3 19 ======= 20 {'name': 'tom'} 21 b 22 2 23 '''
1 def func(): 2 print('a') 3 a = yield 3 4 print("b") 5 return 1 6 yield 2 7 ret = func() 8 # ret 为生成器 9 ret1 = next(ret) # 第一次没问题 10 ret2 = next(ret) # 第二次 return 就终止了生成器
yield from :
1 def func(): 2 yield [1,2,3,4] 3 4 ret = func() 5 # ret 为生成器 6 ret1 = next(ret) 7 print(ret1) 8 # =========================================== 9 def func(): 10 yield from [1,2,3,4] 11 ret2 = func() 12 # ret2 为生成器 13 ret3 = next(ret2) 14 print(ret3)
1 def func01(): 2 l1 = ['a','b','c'] 3 l2 = ['d','e','f'] 4 yield l1 5 yield l2 6 ret = func01() 7 # ret 为生成器 8 ret2 = next(ret) 9 print(ret2) 10 11 ret3 = next(ret) 12 print(ret3) 13 print('======') 14 15 #==================================================================================== 16 def func02(): 17 l1 = ['a','b','c'] 18 l2 = ['d','e','f'] 19 yield from l1 20 yield from l2 21 22 ret = func02() 23 # ret 为生成过期 24 ret2 = next(ret) 25 print(ret2) 26 27 ret3 = next(ret) 28 print(ret3) 29 30 ret4 = next(ret) 31 print(ret4) 32 33 ret5 = next(ret) 34 print(ret5) 35 36 ''' 37 ['a', 'b', 'c'] 38 ['d', 'e', 'f'] 39 ====== 40 a 41 b 42 c 43 d 44 '''
yield from 作用:
优化了内层循环, 下例:
1 def func01(): 2 for i in [1,2,3]: 3 for j in [4,5,6]: 4 yield j 5 ret = func01() 6 ###############二者相比 少了一层循环################## 7 def func02(): 8 for i in [1,2,3]: 9 yield [4,5,6] 10 ret = func02()
2,生成器 表达式 :
它只是把 列表 表达式 的[ ] 换成 ( ) 即可, 表达式的返回值 也是生成器对象 ,
但是,列表 表达式 费内存, 生成器表达式 则是很省内存,
Python 的 for in 结构:
Python 中使用迭代器对象,生成器对象不用 一步一步 next() ,
可以直接用 for in 结构 来遍历,而且遍历完 也不会 报错,
Python 68个内置函数:
一带而过:
all() any() bytes() callable() chr() complex() divmod() eval() exec() format() frozenset() globals() hash() help() id() input() int() iter() locals() next() oct() ord() pow() repr() round()
repr() 原型毕露 函数 :
1 # 正常打印 一个字符串 2 print("hello") # 看不到引号 3 4 print(repr("hello"))
all():
判断一个可迭代对象 中 所有的元素都是真,才返回 True
any():
判断一个可迭代对象 中 有一个元素都是真,即返回 True
重点:
abs() enumerate() filter() map() max() min() open() range() print() len() list() dict() str() float() reversed() set() sorted() sum() tuple() type() zip() dir()
classmethod() delattr() getattr() hasattr() issubclass() isinstance() object() property() setattr() staticmethod() super()
reversed():
它返回的是一个 迭代器对象, 它不会修改原来的数据
Python 中 匿名函数 :
所谓的匿名 指的是定义函数的时候 没有函数名,但是调用的时候,还是得用函数名调用。
1 f = lambda x,y:x+y
ret = f(1,6) # 7
Python 中 闭包:
闭包: 在一个外函数中定义了一个内函数,内函数里 用了外函数作用域 的变量,并且 外函数的返回值是内函数的引用。
1 def outter(): 2 a = 10 3 def innter(): 4 print(a) 5 return innter 6 outter()()
一般情况下,如果一个函数结束,函数的内部所有东西都会释放掉,还给内存,局部变量都会消失。
但是闭包是一种特殊情况,如果外函数在结束的时候发现有自己作用域的 变量将来会在内部函数中用到,就把这个 变量绑定给了内部函数,然后自己再结束。
这个变量会一直存在在内存中,啥时候 调用内函数,啥时候用它 。
1 def outter(): 2 l = [1,2,3,4,5] 3 def innter(): 4 l.append(6) # 可变类型 l 是可以不用 nonlocal 的 5 print(l) 6 return l 7 return innter 8 ret = outter() 9 # 此时outter() 已经结束了 10 for i in ret(): 11 print(i)
Python 中 装饰器 :
当多个装饰器的时候,执行是从下往上执行,
装饰器 本质就是一个函数,这个函数的参数是 要被装饰的函数名字,
python装饰器(fuctional decorators)就是用于拓展原来函数功能的一种函数,目的是在不改变原函数名(或类名)的情况下,给函数增加新的功能。
这个函数的特殊之处在于它的返回值也是一个函数,这个函数是内嵌“原“”函数。
1, 被装饰的函数 无参数 无返回值 :
a, 内函数 无返回值:
1 import time 2 def func(): 3 print("hello world") 4 time.sleep(1) # 模拟代码执行 5 6 # 为了能不改func() 代码的前提下 测量func执行时间,要使用装饰器了 7 8 def dec(f): # 装饰器函数的参数f 是个要被装饰的 函数 9 def inner(): 10 t1 = time.time() 11 f() 12 t = time.time() - t1 13 print("耗时:",t) 14 return inner 15 # 此时 dec 就是个装饰器函数 16 dec(func)()
b, 内函数 有返回值:
1 import time 2 def func(): 3 print("hello world") 4 time.sleep(1) # 模拟代码执行 5 print("hello world") 6 7 # 为了能不改func() 代码的前提下 测量func执行时间,要使用装饰器了 8 9 def dec(f): # 装饰器函数的参数 f 是个要被装饰的 函数 10 def inner(): 11 t1 = time.time() 12 f() 13 t = time.time() - t1 14 return t 15 return inner 16 # 此时 dec 就是个装饰器函数 17 ret = dec(func)() 18 print("总耗时: ",ret)
2, 被装饰的函数 有参数 有返回值 :
内函数也有返回值:
1 import time 2 def func(name,age): 3 print("hello I am ",name) 4 time.sleep(1) # 模拟代码执行 5 return age 6 7 def dec(f): # 装饰器函数的参数f 是个要被装饰的 函数 8 def inner(name,age): 9 t1 = time.time() 10 ret = f(name,age) 11 t = time.time() - t1 12 print("func 函数的返回值: ",age) 13 return t 14 return inner 15 16 ret = dec(func)("tom",18) 17 print("总耗时: ",ret)
但是,上面的调用方式太麻烦,Python 提供了一个语法糖 即@ + 装饰器名字 ,
语法糖(Syntactic sugar)是英国计算机科学家彼得·约翰·兰达发明的一个术语,指计算机语言中添加的某种语法,这些语法没有给程序增加新功能,但是对于程序员更“甜蜜”。语法糖提供了更易读的编码方式,可以提高开发效率。
1 import time 2 3 def dec(f): # 装饰器函数的参数f 是个要被装饰的 函数 4 def inner(name,age): 5 t1 = time.time() 6 ret = f(name,age) 7 t = time.time() - t1 8 print("func 函数的返回值: ",age) 9 return t 10 return inner 11 12 @dec # --> func = dec(func) 13 def func(name,age): 14 print("hello I am ",name) 15 time.sleep(1) # 模拟代码执行 16 return age 17 18 ret = func("tom",18) 19 print("总耗时: ",ret)
@ 后接的是个函数,不是直接的函数名,
1 import time 2 def test(): 3 def dec(f): # 装饰器函数的参数f 是个要被装饰的 函数 4 def inner(name,age): 5 t1 = time.time() 6 ret = f(name,age) 7 t = time.time() - t1 8 print("func 函数的返回值: ",age) 9 return t 10 return inner 11 return dec 12 13 @test() # 这里是先执行 test() 函数,这个函数返回dec 装饰器 14 def func(name,age): 15 print("hello I am ",name) 16 time.sleep(1) # 模拟代码执行 17 return age 18 19 ret = func("tom",18) 20 print("总耗时: ",ret)
多个装饰器 装饰同一个函数:
1 import time 2 3 def dec(f): # 装饰器函数的参数f 是个要被装饰的 函数 4 def inner(name,age): 5 t1 = time.time() 6 ret = f(name,age) 7 t = time.time() - t1 8 print("func 函数的返回值: ",age) 9 return t 10 return inner 11 12 def dec2(f): 13 def inner(name,age): 14 f(name,age) 15 print("你好,",name,"我再次装饰一下") 16 return inner 17 @dec 18 @dec2 # --> func = dec(dec2(func)) 19 def func(name,age): 20 print("hello I am ",name) 21 time.sleep(1) # 模拟代码执行 22 return age 23 24 ret = func('tom',18) # --> dec(dec2(func))('tom',18) 25 print("总耗时: ",ret)
多个装饰器的 顺序:与声明顺序 相反,

Python 中 内置装饰器 :
在Python中有三个内置的装饰器,都是跟class相关的:staticmethod、classmethod 和property。
- staticmethod 是类静态方法,其跟成员方法的区别是没有 self 参数,并且可以在类不进行实例化的情况下调用
- classmethod 与成员方法的区别在于所接收的第一个参数不是 self (类实例的指针),而是cls(当前类的具体类型)
- property 是属性的意思,表示可以通过通过类实例直接访问的信息
property 装饰器 的 作用是:把一个方法 伪装成一个属性。 这个方法必须要有返回值, 而且一般它只有self 一个参数。
property装饰器的应用场景 ---- 结合私有属性使用 :
1 class Person: 2 def __init__(self,name): 3 self.__name = name 4 5 @property 6 def name(self): 7 return self.__name 8 9 p = Person('jack') 10 print(p.name) 11 p.name = 'tom' 12 ''' 13 jack 14 Traceback (most recent call last): 15 File "D:/.project/project_python/test02/bin/start.py", line 11, in <module> 16 p.name = 'tom' 17 AttributeError: can't set attribute 18 '''
property 进阶:
上面代码,如果我们是真的想改个名字,怎么办呢?
1 class Person: 2 def __init__(self,name): 3 self.__name = name 4 5 @property 6 def name(self): 7 return self.__name 8 9 @name.setter 10 def name(self,new_val): 11 self.__name = new_val 12 13 14 p = Person('jack') 15 print(p.name) # 此时调用的是 @property装饰的 name 16 p.name = 'tom' # 此时调用的是 @name.setter装饰的 name 17 print(p.name) # 此时调用的是 @property装饰的 name 18 ''' 19 jack 20 tom 21 '''
参看: https://www.liaoxuefeng.com/wiki/897692888725344/923030547069856
Python 中 模块 :
什么是模块:本质的就是 .py 文件, 它是封装语句的 最小单位, 一行语句也得放到一个模块中,
sys 模块:
模块对象的使用:
1 import sys 2 def f(): 3 print('aaaaaaa') 4 num = 10 5 6 m_obj = sys.modules['__main__'] 7 print(m_obj) 8 m_obj.f() 9 print(m_obj.num)
datetime模块:
1 from datetime import date,time,timedelta 2 # 年月日 3 date = date(2020,2,27) 4 print(date) 5 6 # 时分秒 7 time = time(10,10,10) 8 print(time) 9 10 # 时间 delta 11 # timedelta()
1 import datetime 2 3 4 t0 = datetime.datetime(2010,2,20) 5 t1 = datetime.datetime(2020,3,30) 6 7 res = t1 - t0 8 print(res) 9 print(type(res)) 10 print(res.days)
json 和 pickle 模块:
json 模块,不能完全将Python中 的全部数据类型 都序列化,
于是,就有了 pickle 模块,它可以完全序列化, 使用方法 和 json 模块一样, dump 和 load
二者区别: json 是跨语言的, pickle 不跨语言(只是Python 中使用),
hashlib 模块:
它 封装了一些 用于加密的类,
加密的目的:是用于 判断 和 验证, 不是用于解密,
不同模块之间导入方法:
直接将项目 目录添加到 sys.path ,然后每次 使用from import 使用 例如:
1 import sys 2 sys.path.append("../..") # 添加了 项目的 根目录 3 from core import src 4 from lib import test 5 def run(): 6 print("开始执行吧") 7 src.main() 8 9 if __name__ == '__main__': 10 run()
re模块:
正则表达式
logging模块:
为什么要有log ,
1,排错
2,做数据分析
3,追责
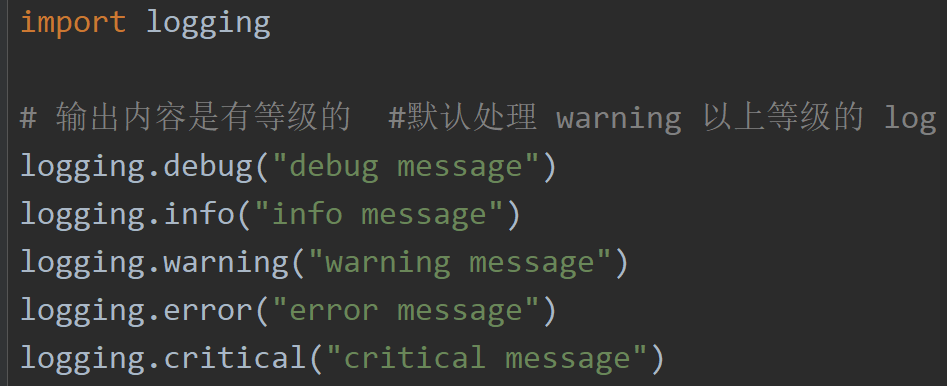
可以通过 logging.basicConfig(level = logging.DEBUG) 类似的调整等级,
写日志,都是自己觉得 可能出错的地方,写一下,(都是自己写)
日志的格式 设置 -- logging.basicConfig() 来设置:
1 import logging 2 3 logging.basicConfig( 4 format='%(asctime)s | %(name)s | %(levelname)s |%(module)s: %(lineno)d | %(message)s', 5 datefmt='%Y-%m-%d %H:%M:%S %p' 6 ) 7 logging.warning("func(1+20)") '''2020-02-27 17:27:25 PM | root | WARNING |start: 7 | func(1+20) '''
上面都是输出到 屏幕,下面输出到 文件:
还是在 logging.basicConfig()
使用关键字 filename 来指定,一般文件命名以.log 结尾,而且,是追加的方式 写文件,
1 import logging 2 3 logging.basicConfig( 4 format='%(asctime)s | %(name)s | %(levelname)s |%(module)s: %(lineno)d | %(message)s', 5 datefmt='%Y-%m-%d %H:%M:%S %p', 6 filename='my.log' 7 ) 8 logging.warning("func(1+20) ")
如何同时 输出到 屏幕 和 文件?
这时要用handlers 来指定 要输出的文件描述符了, 此时也可以指定写入文件时候的编码了,
1 import logging 2 3 4 fh = logging.FileHandler('my.log',encoding="utf8") 5 sh = logging.StreamHandler() 6 logging.basicConfig( 7 format='%(asctime)s | %(name)s | %(levelname)s |%(module)s: %(lineno)d | %(message)s', 8 datefmt='%Y-%m-%d %H:%M:%S %p', 9 handlers=[fh,sh] 10 ) 11 logging.warning("func(1+20) ")
日志切割:
1 import time 2 import logging 3 from logging import handlers 4 5 sh = logging.StreamHandler() 6 rh = handlers.RotatingFileHandler('myapp.log', maxBytes=1024,backupCount=5) # 按大小切割 最多5个备份 7 fh = handlers.TimedRotatingFileHandler(filename='x2.log', when='s', interval=5, encoding='utf-8') # 按时间切, when:按秒 ,
8 logging.basicConfig( 9 format='%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s', 10 datefmt='%Y-%m-%d %H:%M:%S %p', 11 handlers=[fh,sh,rh], 12 level=logging.ERROR 13 ) 14 15 for i in range(1,100000): 16 time.sleep(1) 17 logging.error('KeyboardInterrupt error %s'%str(i))
Python 面向对象相关知识:
参看:
https://www.cnblogs.com/linhaifeng/articles/6204014.html#_label6
https://www.cnblogs.com/linhaifeng/articles/8029564.html
类对象 和 实例对象 的 属性字典:
1 class Demo: 2 def __init__(self,name,age): 3 self.name = name 4 self.age = age 5 6 def run(self): 7 print("跑") 8 9 # 类对象的 属性字典 10 print(Demo.__dict__) 11 demo = Demo('tom',18) 12 # 实例对象的 属性字典 13 print(demo.__dict__) 14 ''' 15 {'__module__': '__main__', '__init__': <function Demo.__init__ at 0x10FCE0C0>, 'run': <function Demo.run at 0x10FCE078>, '__dict__': <attribute '__dict__' of 'Demo' objects>, '__weakref__': <attribute '__weakref__' of 'Demo' objects>, '__doc__': None} 16 {'name': 'tom', 'age': 18} 17 '''
类中的 一般方法 和 类方法 和 静态方法:
1 class Demo: 2 def __init__(self,name,age): 3 self.name = name 4 self.age = age 5 6 def run(self): 7 print("跑") 8 9 @classmethod 10 def test(cls): 11 print("hahaha") 12 13 @staticmethod 14 def test02(): 15 print("我去") 16 17 18 Demo.test() # 类方法 (其实里面有 参数 ) 19 Demo.test02() # 静态方法 (没参数 ) 20 #=========== 21 demo = Demo("name",18) 22 demo.run() # 一般方法 (里面有 参数)
注:类方法 和 静态方法 在使用的时候,其实是差不多的,
类的 类 type(元类) :
类的类 是type ,即类对象 是由 type 类产生的,
type 是Pyhton一个内置类,Python中,任何class 定义的类 其实都是type 实例化的对象,
其实定义类有两种方式:
1,用class
2, 用type 类
1 Demo = type('Demo',(object,),{'name':'tom',"age":18}) 2 print(Demo.__dict__) 3 4 class Demo02: 5 name:'tom' 6 age:18 7 print(Demo02.__dict__ ) 8 ''' 9 {'name': 'tom', 'age': 18, '__module__': '__main__', '__dict__': <attribute '__dict__' of 'Demo' objects>, '__weakref__': <attribute '__weakref__' of 'Demo' objects>, '__doc__': None} 10 {'__module__': '__main__', '__annotations__': {'name': 'tom', 'age': 18}, '__dict__': <attribute '__dict__' of 'Demo02' objects>, '__weakref__': <attribute '__weakref__' of 'Demo02' objects>, '__doc__': None} 11 '''
1 def init(self,name,age): 2 self.name = name 3 self.age = age 4 def run(self): 5 print("跑") 6 7 Demo = type('Demo',(object,),{'__init__':init,'run':run}) 8 demo =Demo('tom',18) 9 print(demo.__dict__) 10 demo.run() 11 12 # ========================================================== 13 14 class Demo02: 15 def __init__(self,name,age): 16 self.name = name 17 self.age = age 18 def run(self): 19 print("跑") 20 demo02 =Demo02('tom',18) 21 print(demo02.__dict__) 22 demo02.run()
type() 的三个参数:1,类名,2,继承的对象(必须是 元组),3类对象的 属性字典
metaclass 关键字 :
Python 内置的元类 只有一个type ,
其实,平时 用class 定义类的时候,默认就加了 metaclass = type 的, 只是我们不知道,
1 class Demo: 2 pass 3 4 class Demo(metaclass=type): 5 pass
自定义元类 :
因为type 是Python 内置的元类,我们可以通过自己创建继承 type 就构建成了 我们自己的元类,
1 class MyType(type,metaclass=type): # metaclass=type 可以省略 2 pass
通过自定义元类 研究 “实例化”:
实例化就是 类名 + 括号,
1 class MyType(type,metaclass=type): # metaclass=type 可以省略 2 def __init__(self,a,b,c): 3 print('自定义 元类 的 init 方法 ') 4 print(a) 5 print(b) 6 print(c) 7 def __call__(self,a): 8 print("hhh ") 9 print(a) 10 obj = object.__new__(self) # 这里的self 是 Demo 类对象,生成的obj 是demo 对象 11 self.__init__(obj,a) 12 return obj 13 14 15 class Demo(metaclass=MyType): # 如果不写 metaclass ,默认是 metaclass = type 16 name = 'tom' 17 def __init__(self,age): 18 self.age = age 19 20 demo = Demo(18) 21 # Demo(18) 会做如下 操作: 22 #第一步:MyType('Demo',(),{{'__module__': '__main__', '__qualname__': 'Demo', 'name': 'tom', '__init__': <function Demo.__init__ at 0x10E4E0C0>}}) 23 #第二步:把 18 参数 传给MyType 中的 __call__ 方法 24 #第三步:在__call__ 方法中,创建demo 对象,初始化 ,并返回
总结:所以平时 我们实例化的过程实际上是 type 帮我们创建demo 对象,然后 初始化它,然后返回给我们的, 上面用重写的方式,重现了这一过程,
类对象 属性 和 实例对象属性的 寻找范围:
1 class MyType(type,metaclass=type): # metaclass=type 可以省略 2 name = "aaa" 3 def __init__(self,*args,**kwargs): 4 self.name = 'aaa2' 5 pass 6 7 def __call__(self, *args, **kwargs): 8 obj = object.__new__(self) 9 self.__init__(obj,*args,**kwargs) 10 return obj 11 12 class Demo(object,metaclass=MyType): # 其实 默认也是继承 object 13 name = 'bbb' 14 def __init__(self): 15 self.name = 'bbb2' 16 pass 17 18 class Demo2(Demo): # metaclass=MyType 也继承过来了 19 name = 'ccc' 20 def __init__(self): 21 self.name = 'ccc2' 22 pass 23 24 class Demo3(Demo2): # metaclass=MyType 也继承过来了 25 name = 'ddd' 26 def __init__(self): 27 self.name = 'ddd2' 28 pass 29 30 # print(Demo3.name) # 先找 aaa2-->ddd --> ccc ---> bbb --> aaa 类对象的属性 寻找范围 31 32 demo = Demo3() 33 print(demo.name) # 先找 ddd2 --> aaa2 -->ddd --> ccc --> bbb 对象的属性 寻找范围
类 中的 __new__() 函数 :
1 class MyType(type,metaclass=type): # metaclass=type 可以省略 2 def __init__(self,name,bases,attrs): 3 print('4') 4 print(name) 5 print(bases) 6 print(attrs) 7 8 def __new__(cls, name,bases,attrs): #新建 MyType 它自己,之后会初始化 它 9 print('2') 10 print(name) 11 print(bases) 12 print(attrs) 13 # 重写 type 中 __new__ 14 return type.__new__(cls,name,bases,attrs) 15 16 class Demo(object,metaclass=MyType): # 其实 默认也是继承 object 17 print('1') 18 def __init__(self): 19 print('3')
'''
1
2
Demo
(<class 'object'>,)
{'__module__': '__main__', '__qualname__': 'Demo', '__init__': <function Demo.__init__ at 0x1091E0C0>}
4
Demo
(<class 'object'>,)
{'__module__': '__main__', '__qualname__': 'Demo', '__init__': <function Demo.__init__ at 0x1091E0C0>}
'''
Python 中的组合 :
一个类的对象 作为了另一个类的属性,
1 class Course: 2 def __init__(self,course_name,dur,price): 3 self.course_name = course_name 4 self.dur = dur 5 self.price =price 6 7 class Banji: 8 def __init__(self,name,course): 9 self.name = name 10 self.course = course 11 12 bj1 = Banji('八年级',Course('数学','10个月',10000)) 13 bj2 = Banji('八年级',Course('英语','5个月',1000))
Python 中的 抽象类 :
与java一样,python也有抽象类的概念但是同样需要借助模块实现,抽象类是一个特殊的类,它的特殊之处在于只能被继承,不能被实例化
1 from abc import ABCMeta,abstractmethod 2 class Animal(metaclass=ABCMeta): 3 ''' 4 所有动物 都会跑 和 吃 5 ''' 6 @abstractmethod 7 def run(self): 8 pass 9 10 @abstractmethod 11 def eat(self): 12 pass 13 14 class Dog(Animal): 15 def __init__(self,name): 16 self.name = name 17 18 dog = Dog('tom')
Python 中的 多态:
处处是 多态,因为 Python 是 不是很 重视类型 的语言,
鸭子类型:
https://www.jianshu.com/p/e97044a8169a
Python 中的 super() :
super() 寻找是 按照 mro 顺序 寻找父类的 ,
Python 中的反射:
反射的概念是由Smith在1982年首次提出的,主要是指程序可以访问、检测和修改它本身状态或行为的一种能力。这一概念的提出很快引发了计算机科学领域关于应用反射性的研究。它首先被程序语言的设计领域所采用,并在Lisp和面向对象方面取得了成绩。
上面一点用都没有,就四个内置函数 ,用于判断一个对象有没有 一个属性的
hasattr()
getattr()
setattr()
delattr()
1 class Person: 2 def __init__(self,name): 3 self.name = name 4 def run(self): 5 print('run') 6 7 8 p = Person('jack') 9 ret = hasattr(p,'name') 10 print(ret) 11 12 #================================ 13 print(p.name) 14 setattr(p,'name','tom') 15 print(p.name) 16 17 #================================ 18 ret = getattr(p,'name') 19 print(ret) 20 21 #================================ 22 print(p.__dict__) 23 delattr(p,'name') 24 print(p.__dict__) 25 26 #===============类也是 对象================= 27 ret = hasattr(Person,'run') 28 print(ret) 29 30 #===============模块也是 对象================= 31 import sys 32 m = sys.modules[__name__] 33 ret = hasattr(m,'Person') 34 print(ret) 35 36 ret = getattr(m,'Person') 37 print(ret)
Python 中的 类的 三个保留方法 __setattr__ ,__getattr__,__delattr__:
1,__setattr__: 给对象 添加/修改 属性的时候会 调用它
2,__getattr__: 在使用对象 调用一个不存在的属性的时候 会调用它 (p.name = 'tom' 这不算调用属性了,这是设置属性 )
3,__delattr__: 在删除 对象的 属性的时候回调用它
如果我们不写 __getattr__() 方法的话,如果直接引用一个不存在的 的属性,那么此时就会报错,如果写了就不报错了,这也是它的作用。
1 class Person: 2 def __init__(self,name): 3 self.name = name 4 5 def run(self): 6 print('run') 7 8 def __setattr__(self, key, value): 9 self.__dict__[key] = value 10 11 12 # def __getattr__(self, item): 13 # print(item) 14 # print('h') 15 16 def __delattr__(self, item): 17 print(item) 18 print('w') 19 20 p = Person('jack') 21 p.age = 19 22 23 # p.sex
1 ''' 2 class Person: 3 def __init__(self,name,age): 4 self.name = name 5 self.age = age 6 7 p = Person('jack') 8 p.name = 'tom' 9 p.age = 18 10 ''' 11 #需求 控制 name 必须是字符串, 控制 age 的范围是 [30-50] 12 class Person: 13 def __init__(self,name,age): 14 self.name = name 15 self.age = age 16 17 def __setattr__(self, key, value): 18 if key == 'name': 19 if type(value) == str: 20 self.__dict__[key] = value 21 else: 22 print('name 属性类型应为字符串') # 此时就不会 设置到self 的属性字典中 23 if key == 'age': 24 if type(value) == int: 25 if value > 50 or value < 30: 26 print('age 属性的范围有误 ,应为 [30,50] ') 27 else: 28 self.__dict__[key] = value 29 else: 30 print('age 属性类型应为int') 31 32 33 # p = Person(10,18) # name 属性类型应为字符串 age 属性的范围有误 ,应为 [30,50] 34 # p = Person('tom',18) #age 属性的范围有误 ,应为 [30,50] 35 p = Person('tom',30) # √ 36 p = Person('tom',51) # age 属性的范围有误 ,应为 [30,50]
Python 中的 包装 :
基于标准数据类型来定制我们自己的数据类型。
1 class List_Str(list): 2 def append(self,val): 3 if type(val) == str: 4 super().append(val) 5 else: 6 print("添加失败,列表中只允许添加字符串") 7 8 9 l = List_Str() 10 l.append(10) 11 print(l) 12 13 #================================ 14 l.append('tom') 15 l.append('jack') 16 print(l) 17 ''' 18 添加失败,列表中只允许添加字符串 19 [] 20 ['tom', 'jack'] 21 '''
这就是包装,说到底 还是封装,
Python 中的 授权:
1 class Open: 2 def __init__(self,filename,mode='r',encoding='utf8'): 3 self.f = open(filename,mode,encoding=encoding) 4 self.name = 'tom' 5 6 def write(self,line): 7 # 控制用户写的内容 8 if 'hello' in line: 9 print('您的内容 违法,清重新输入 hhh') 10 else: 11 self.f.write(line) 12 13 def __getattr__(self, item): 14 return getattr(self.f,item) 15 16 ''' 17 op = Open('test.txt','w') 18 # op.write('hello world') # 违法 19 op.write('hell world') 20 ''' 21 22 #================================ 23 # 下面再 读文件 24 op = Open('test.txt') 25 ret = op.read() # 此时会调用 __getattr__, 然后,就可以获取到 文件对象的 read() 方法了 26 print(ret)
说到底,还是 封装,
Python 类 中的 __getattribute__ 保留方法 :
1,如果对象 调用一个已存在的 属性,它是不会调用 __getattr__ 的, 会调用 __getattribute__方法,
2,如果对象调用一个不存在的 属性,
a) 如果此时只有 __getattr__ 没有 __getattribute__,那么 调用 __getattr__ ,
b) 如果此时一旦存在 __getattribute__ 没有 ,那么无论存不存在__getattr__ ,都只是 调用 __getattribute__ ,
一句话:__getattribute__ 是大哥, __getattrr__ 是小弟,
其实, 真正触发 __getattr__ 的原因是 一个异常的抛出, AttributeError ,所以,可以在大哥中 抛出这个异常,就可以召唤 小弟了。
1 class Demo: 2 def __init__(self,name ): 3 self.name = name 4 5 def __getattr__(self, item): 6 print(item) 7 print('h') 8 9 def __getattribute__(self, item): 10 print(item ) 11 print('hh') 12 raise AttributeError("小弟快来...") 13 14 demo =Demo('tom') 15 demo.name 16 demo.age
总结:
__getattribute__ :是只要是 调用了 属性,不管有没有,就触发它,
__getattr__ : 捕获 AttributeError 异常时,才会触发 。
python 类中的 保留方法 __getitem,__setitem__,__delitem__:
它们 和 attr 很类似,主要是 attr 是点操作, 它们是 [ ] 操作,
__getitem__:
1 class Demo: 2 def __init__(self,name ): 3 self.name = name 4 5 def __getitem__(self, item): 6 print(item) 7 8 9 demo =Demo('tom') 10 # demo.name #此时不触发 __getitem__ 11 demo['name'] #这种形式的时候触发 12 demo['age'] # 没有该属性也触发
1 class Demo: 2 def __init__(self,name ): 3 self.name = name 4 5 def __getitem__(self, item): 6 print(item) 7 8 def __setitem__(self, key, value): 9 print(key) 10 print(value) 11 12 def __delitem__(self, key): 13 print(key) 14 15 demo =Demo('tom') 16 demo['name'] = 'jack' 17 18 del demo['name']
python 中的 另一个保留方法---- 析构方法 __del__ :
析构方法,当对象在内存中被释放时,自动触发执行。
python 类 中的 保留方法 __get__ , __set__ , __delete__ :
它们的调用时机不是 实例对象操作属性的时候,
1 class Demo: 2 def __init__(self,name ): 3 self.name = name 4 5 def __get__(self, instance, owner): 6 print(instance) 7 print(owner) 8 9 def __set__(self, instance, value): 10 print(instance) 11 print(value) 12 13 def __delete__(self, instance): 14 print(instance) 15 16 17 demo =Demo('tom') 18 demo.name = 'jack' 19 del demo.name
它们的调用时机,是这个类的对象 作为另一个类的类属性的时候,
1 class MyStr: 2 def __get__(self, instance, owner): 3 print('get') 4 print(instance) # 这里的instance 指的是下面的 People 对象 5 print(owner) 6 def __set__(self, instance, value): 7 print('set') 8 print(instance) 9 print(value) 10 def __delete__(self, instance): 11 print('delete') 12 print(instance) 13 14 class People: 15 name = MyStr() 16 def __init__(self,name,age): 17 self.name = name #对象字典中 不会有name 了,跑到 类属性字典了, 18 self.age = age 19 20 p = People('tom',18) 21 print(p.__dict__) 22 print(People.__dict__) 23 print("#================================") 24 p.name 25 print("#================================") 26 del p.name
它们的应用场景:
1 class MyType: 2 def __init__(self,key,type): 3 self.type = type 4 self.key = key 5 6 def __set__(self, instance, value): 7 if type(value) == self.type: 8 instance.__dict__[self.key] = value 9 else: 10 print(self.key,"的类型应该是 ",self.type ) 11 12 class People: 13 name = MyType('name',str) 14 age = MyType('age',int) 15 def __init__(self,name,age): 16 self.name = name #对象字典中 不会有name 了,跑到 类属性字典了, 17 self.age = age #对象字典中 不会有age ,跑到 类属性字典了, 18 19 p = People('tom',18) 20 print('===============') 21 p1 = People('tom','18') 22 print('===============') 23 p2 = People(18,18) 24 print('===============') 25 p3 = People(18,'18') 26 print('===============')
模仿内置装饰器 @property :
一个类 也可以成为一个装饰器,(不仅仅是 函数)
1 class MyProperty: 2 def __init__(self,func): 3 self.func = func 4 5 def __get__(self, instance, owner): 6 print(instance) # Demo 实例对象 7 print(owner) # instance 的类型 8 return self.func(instance) 9 10 11 class Demo: 12 def __init__(self,w,h): 13 self.w = w 14 self.h = h 15 16 @MyProperty # --> area = MyProperty(area) # 此时,area 是个类变量~ 会触发 __get__方法 17 def area(self): 18 return self.w*self.h 19 20 demo = Demo(18,10) 21 print(demo.area)
再看 @property :
1 ''' 2 3 class Demo: 4 def __init__(self,w,h): 5 self.w = w 6 self.h = h 7 8 @property 9 def area(self): 10 return self.w*self.h 11 12 demo = Demo(18,10) 13 14 # demo.area = 18 15 # del demo.area 16 # 此时如果是真的想给 area 赋值 ,或者 删除 area 均会报错, 17 ''' 18 #============================================================ 19 class Demo: 20 def __init__(self,w,h): 21 self.w = w 22 self.h = h 23 self.__area = w*h 24 25 @property 26 def area(self): 27 if not hasattr(self,"_Demo__area"): 28 print('没有此属性') 29 return None; 30 return self.__area 31 32 @area.setter 33 def area(self,val): 34 self.__area = val 35 36 @area.deleter 37 def area(self): 38 del self.__area 39 40 demo = Demo(18,10) 41 print(demo.area) 42 #================================ 43 demo.area = 18 44 print(demo.area) 45 # 46 #================================ 47 del demo.area 48 print('============================') 49 print(demo.area) 50 51 print('============================') 52 demo.area = 10 53 print(demo.area)
python 类 中的 保留方法 __call__ :
如果 实现了它,那么就可以用对象 + 括号 了,
1 class Demo: 2 def __init__(self,name,age): 3 self.name = name 4 self.age = age 5 6 def __call__(self, *args, **kwargs): 7 print('ha') 8 9 Demo('tom',18)() 10 ''' 11 ha 12 '''
Python 中 类的装饰器:
装饰器 不仅可以装饰函数 也可以装饰类,
1 class Demo: 2 def __init__(self,name,age): 3 self.name = name 4 self.age = age 5 6 def dec(c): 7 def inner(name,age): 8 print("给类 加额外功能") 9 obj = c(name,age) 10 return obj 11 return inner 12 13 ret = dec(Demo)('tom',18) 14 print(ret) 15 print(ret.name) 16 print(ret.age)
1 def dec(c): 2 def inner(name,age): 3 print("给类 加额外功能") 4 obj = c(name,age) 5 return obj 6 return inner 7 8 @dec 9 class Demo: 10 def __init__(self,name,age): 11 self.name = name 12 self.age = age 13 14 demo = Demo('tom',18) 15 print(demo.name) 16 print(demo.age)
单例模式:
单例模式(Singleton Pattern)是 Java 中最简单的设计模式之一。
这种模式涉及到一个单一的类,该类确保只有单个对象被创建。
注意:
- 1、单例类只能有一个实例。
- 2、单例类必须自己创建自己的唯一实例。
- 3、单例类必须给所有其他对象提供这一实例。
单例模式的应用场景:
1. Windows的Task Manager(任务管理器)就是很典型的单例模式(这个很熟悉吧),想想看,是不是呢,你能打开两个windows task manager吗? 不信你自己试试看哦~
2. windows的Recycle Bin(回收站)也是典型的单例应用。在整个系统运行过程中,回收站一直维护着仅有的一个实例。
3. 操作系统的文件系统,也是大的单例模式实现的具体例子,一个操作系统只能有一个文件系统。
Python实现单例模式:
参看:
https://www.cnblogs.com/huchong/p/8244279.html
最简单的单例模式是 :Python的一个模块 即可以实现单例模式,
1 ''' 2 class Demo: 3 def __init__(self,name,age): 4 self.name = name 5 self.age = age 6 7 demo = Demo('tom',18) 8 print(demo) 9 demo2 = Demo('a',20) 10 print(demo2) 11 12 <__main__.Demo object at 0x02FBF990> 13 <__main__.Demo object at 0x02FBFA70> 14 15 ''' 16 # 如何将 上面 改为一个单例模式的 类呢? 17 class Demo: 18 __singleInstance = None 19 20 def __init__(self,name,age): 21 self.name = name 22 self.age = age 23 24 def __new__(cls, *args, **kwargs): 25 if cls.__singleInstance is None: 26 cls.__singleInstance = object.__new__(cls) 27 return cls.__singleInstance 28 29 30 demo = Demo('tom',18) 31 print(demo) 32 demo2 = Demo('a',20) 33 print(demo2) 34 ''' 35 <__main__.Demo object at 0x02BCFA30> 36 <__main__.Demo object at 0x02BCFA30> 37 '''
其实,默认 调用new 也是object.__new__( ) 。
new的调用时机,它在init 之前,其实它是在call里被调用的,
Python 的with 关键字 的使用 :
1 class Demo: 2 def __init__(self,name): 3 self.name = name 4 5 def __enter__(self): 6 print("我来了 ") 7 return 'zcb' 8 9 def __exit__(self, exc_type, exc_val, exc_tb): 10 # __exit__()方法的3个参数,分别代表异常的类型、值、以及堆栈信息 11 print('===========') 12 print(exc_type) 13 print(exc_val) 14 print(exc_tb) 15 print("我走了") 16 17 # with 后跟的对象的类中 一定要有 __enter__ 和 __exit__方法,不然报错 18 # as 可以省略, as 后跟的是 __enter__ 的返回值 19 with Demo('tom') as ret: 20 print(ret)
我来了
zcb
===========
None
None
None
我走了
1 class Demo: 2 def __enter__(self): 3 print('1') 4 return self 5 6 def run(self): 7 print('跑') 8 print(1/0) 9 10 def __exit__(self, exc_type, exc_val, exc_tb): 11 print(exc_type) 12 print(exc_val) 13 print(exc_tb) 14 15 with Demo() as d: # d是__enter__ 的返回值 16 d.run() 17 18 ''' 19 Traceback (most recent call last): 20 File "D:/.project/project_python/test02/bin/start.py", line 16, in <module> 21 d.run() 22 File "D:/.project/project_python/test02/bin/start.py", line 8, in run 23 print(1/0) 24 ZeroDivisionError: division by zero 25 1 26 跑 27 <class 'ZeroDivisionError'> 28 division by zero 29 <traceback object at 0x102CC350> 30 '''
网络通信:
粘包 现象:
TCP才可能出现 粘包现象,UDP 不可能粘包,
所谓粘包问题主要还是因为接收方不知道消息之间的界限,不知道一次性提取多少字节的数据所造成的。
此外,发送方引起的粘包是由TCP协议本身造成的,TCP为提高传输效率,发送方往往要收集到足够多的数据后才发送一个TCP段。若连续几次需要send的数据都很少,通常TCP会根据优化算法把这些数据合成一个TCP段后一次发送出去,这样接收方就收到了粘包数据。
参看:
https://www.cnblogs.com/steve214/p/10022692.html
解决粘包的方法:设置边界 ,
发送消息之前,先发送消息的字节长度,然后,再发送真实的消息。注:消息的发送长度的 字节要固定,因为要防止 长度 和 真实消息 也粘在一起。
1 import socket 2 ''' 3 server 端 4 ''' 5 sk = socket.socket() 6 7 sk.bind(('127.0.0.1',8080)) 8 sk.listen() 9 10 import time 11 12 while 1: 13 conn,addr = sk.accept() 14 while 1: 15 time.sleep(30) 16 size = conn.recv(4) #先接受 消息 字节数 17 print(size) 18 size = int(size.decode().zfill(4)) 19 data = conn.recv(size) 20 print(data) 21 22 d = input(">>> [server]") 23 conn.send(str(len(d.encode())).zfill(4).encode()) # 先发送 消息字节数 24 conn.send(d.encode()) 25 26 27 conn.close() 28 29 sk.close()
1 import socket 2 ''' 3 client 端 4 ''' 5 sk = socket.socket() 6 7 sk.connect(('127.0.0.1',8080)) 8 9 while 1: 10 d = input(">>> [client]") 11 sk.send(str(len(d.encode())).zfill(4).encode()) # 先发送 消息字节数 12 sk.send(d.encode()) 13 14 size = sk.recv(4) # 先接受 消息 字节数 15 print(size) 16 size = int(size.decode().zfill(4)) 17 data = sk.recv(size) 18 print(data) 19 20 sk.close()
但是,上面代码里 最多接受字节的长度是 9999,也就是最多10000 个字节(有点少), 如果多于,就不行了, 上面用 zfill ( ) 直接在 左面加0 , 不是很好,
Python有个模块,struct ,
参看: https://www.cnblogs.com/leomei91/p/7602603.html
它的pack() 可以将 Python中的数据 按照 fmt ,转为 对应的字节流对象。
它的unpack() 可以将 字节流对象,转换回 python 中的数据 。
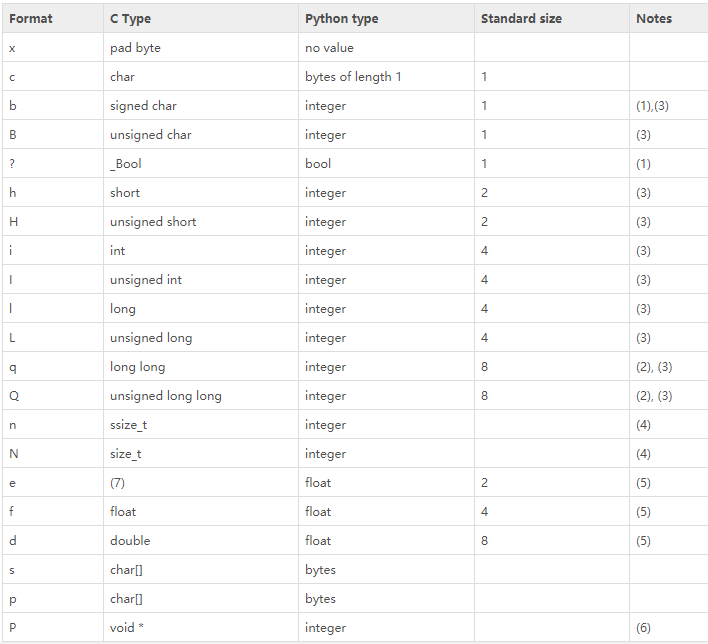
1 import struct 2 3 a = 111111111 4 b = 111111 5 c = 1 6 7 ret1 = struct.pack('i',a) 8 ret2 = struct.pack('i',b) 9 ret3 = struct.pack('i',c) 10 11 print(ret1) 12 print(ret2) 13 print(ret3) 14 15 print(struct.unpack('i',ret1)) 16 print(struct.unpack('i',ret2)) 17 print(struct.unpack('i',ret3))
所以,我们可以将我们的 len 用 struct.pack() 转换为 二进制形式(int ,4个字节), 这4个字节 最大的数 是 2^32 - 1 (4294967295) ,
所以,这已经足够我们使用了, 4294967295个字节是 4294967295/(1024 ^2 ) = 3.9G ,所以,单次传输 不可能这么大的数据量。
1 import socket 2 import struct 3 ''' 4 server 端 5 ''' 6 sk = socket.socket() 7 8 sk.bind(('127.0.0.1',8080)) 9 sk.listen() 10 11 import time 12 13 while 1: 14 conn,addr = sk.accept() 15 while 1: 16 time.sleep(10) 17 size = conn.recv(4) #先接受 消息 字节数 18 size = struct.unpack('i',size)[0] 19 print(size) 20 data = conn.recv(size) 21 print(data) 22 23 d = input(">>> [server]") 24 conn.send(struct.pack('i',len(d.encode()))) # 先发送 消息字节数 25 conn.send(d.encode()) 26 27 28 conn.close() 29 sk.close()
1 import socket 2 import struct 3 ''' 4 client 端 5 ''' 6 7 sk = socket.socket() 8 9 sk.connect(('127.0.0.1',8080)) 10 11 while 1: 12 d = input(">>> [client]") 13 14 sk.send(struct.pack('i',len(d.encode()))) # 先发送 消息字节数 15 sk.send(d.encode()) 16 17 size = sk.recv(4) # 先接受 消息 字节数 18 size = struct.unpack('i',size)[0] 19 print(size) 20 data = sk.recv(size) 21 print(data) 22 23 sk.close()
大文件 多次传输 :
1 import socket 2 import struct 3 ''' 4 server 端 5 ''' 6 sk = socket.socket() 7 8 sk.bind(('127.0.0.1',8080)) 9 sk.listen() 10 11 while 1: 12 conn,addr = sk.accept() 13 while 1: 14 size = conn.recv(4) #先接受 消息 字节数 15 size = struct.unpack('i',size)[0] 16 print(size) 17 i = 0 18 while 1: 19 with open("recv.txt","ab") as f: 20 if size > 1024: 21 data = conn.recv(1024) 22 else: 23 data = conn.recv(size) 24 size = size - len(data) # 每次不一定 接收的是 1024 ,所以最好用 len(data) 25 f.write(data) 26 i += 1 27 if size <= 0: 28 break 29 print('总次数: ',i) 30 input() 31 conn.close() 32 sk.close()
1 import socket 2 import struct 3 ''' 4 client 端 5 ''' 6 7 sk = socket.socket() 8 9 sk.connect(('127.0.0.1',8080)) 10 11 while 1: 12 with open("test.txt","rb") as f: 13 d = f.read() 14 sk.send(struct.pack('i',len(d))) # 先发送 消息字节数 15 sk.send(d) 16 17 sk.close()
验证 客户端的合法性 :
如何生成一个随机的字节,
os.urandom(32) 可以随机生成一个32位的随机字节,
用算法 将它 和 密钥 在一起生成结果,
1 import os,hashlib 2 r_b = os.urandom(32) 3 4 key = 'towqndsjfkgn%$#@skg&*(ngn)!@sliengah' # 密钥 服务端 和 客户端 都有 5 ret = hashlib.md5(key.encode()) 6 ret.update(r_b) 7 res = ret.hexdigest() 8 print(res)
1 import socket 2 import os,hashlib 3 4 key = 'towqndsjfkgn%$#@skg&*(ngn)!@sliengah' 5 6 sk = socket.socket() 7 sk.bind(('127.0.0.1',8080)) 8 sk.listen() 9 10 while 1: 11 #================================ 12 r_b = os.urandom(32) 13 ret = hashlib.md5(key.encode()) 14 ret.update(r_b) 15 res = ret.hexdigest() 16 #================================ 17 conn,addr = sk.accept() 18 conn.send(r_b) 19 recv = conn.recv(1024) 20 if recv.decode() == res: 21 print('合法,开始通信') 22 # 合法 23 while 1: 24 data = conn.recv(1024) 25 print(data) 26 27 ret = input('>>>[server]').encode() 28 conn.send(ret) 29 else: 30 print('不合法,拜拜') 31 # 不合法 关闭连接 32 conn.close()
1 import socket 2 import hashlib 3 4 key = 'towqndsjfkgn%$#@skg&*(ngn)!@sliengah' 5 sk = socket.socket() 6 sk.connect(('127.0.0.1',8080)) 7 8 r_b = sk.recv(1024) 9 # ================================ 10 ret = hashlib.md5(key.encode()) 11 ret.update(r_b) 12 res = ret.hexdigest() 13 # ================================ 14 sk.send(res.encode()) 15 while 1: 16 d = input('>>> [client]') 17 sk.send(d.encode()) 18 19 data = sk.recv(1024) 20 print(data.decode())
Python 的 sockserver 模块 :
sockserver 和 socket 模块的关系, 它是基于 socket 的, 而且,它们都是Python 内置的模块 ,
它帮我们做的事情是: 帮助我们处理 并发的客户端请求 ,
1 import socketserver 2 3 class MyServer(socketserver.BaseRequestHandler): 4 # 重写 handle 方法 5 def handle(self): 6 conn = self.request 7 while 1: 8 try: 9 data = conn.recv(1024) 10 print(data.decode()) 11 except ConnectionResetError: 12 break 13 14 server = socketserver.ThreadingTCPServer(('127.0.0.1',8080),MyServer) 15 server.serve_forever()
1 import socket 2 3 sk = socket.socket() 4 5 sk.connect(('127.0.0.1',8080)) 6 7 while 1: 8 d = input(">>> [client]").encode() 9 sk.send(d)
1 import socket 2 3 sk = socket.socket() 4 5 sk.connect(('127.0.0.1', 8080)) 6 7 while 1: 8 d = input(">>> [client]").encode() 9 sk.send(d)
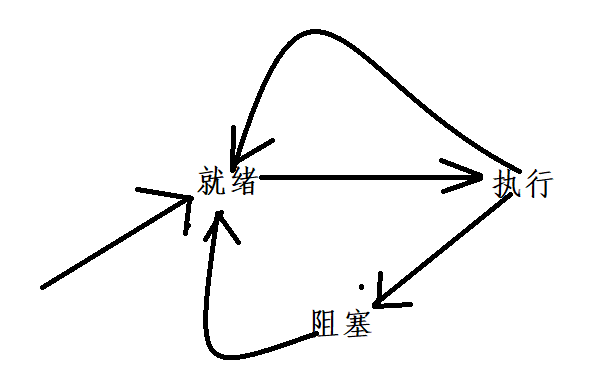
进程的三种状态:
就绪, 运行 ,还有阻塞 三个状态 ,
操作系统 :
我们日常生活中的系统 都是 分时 系统,分时是 分时间片。
也又实时系统, 它是一个cpu 只为一个 程序工作,它一般都是用于 飞机飞行,导弹发射之类的,不能有一分一毫的 差错,对响应度要求高(不能 分时间片)。
分布式 :
只要是把 大的任务分解为小的任务 都可以称为分布式,
分布式,可以在操作系统级别实现,也可以在 程序级别实现, Python 的框架: celery
Python 的进程 :
进程 相关的模块 及函数 :
和进程 相关的 模块: multiprocessing
from multiprocessing import Processing
os 模块中的两个 函数 getpid() 进程id , getppid() 父进程 id
子进程.join() :
只要有子进程.join() ,那么主进程就会阻塞,直到 .join()使用的子进程 执行完毕!

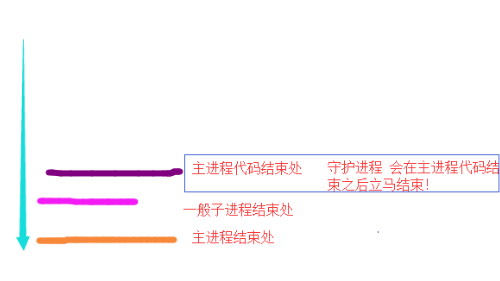
守护进程 :
通过 子进程.daemon = True ,可以将其设置为 守护进程,
该进程 会在 主进程代码执行彻底完之后 自动结束。
利用 多进程 实现 socket 并发:
1 import socket 2 from multiprocessing import Process 3 4 def commun_with_client(conn): 5 while 1: 6 d = conn.recv(1024) 7 print(d) 8 9 if __name__ == '__main__': 10 sk = socket.socket() 11 sk.bind(('127.0.0.1', 8080)) 12 sk.listen() 13 14 while 1: 15 conn,addr = sk.accept() #不停的 accept, 来一个client 开一个子进程 16 p = Process(target=commun_with_client,args=(conn,)) 17 p.start()
1 import socket 2 sk = socket.socket() 3 4 sk.connect(('127.0.0.1',8080)) 5 6 while 1: 7 d = input(">>> [client]").encode() 8 sk.send(d)
1 import socket 2 sk = socket.socket() 3 4 sk.connect(('127.0.0.1',8080)) 5 6 while 1: 7 d = input(">>> [client]").encode() 8 sk.send(d)
进程 之间的数据共享 --- Manager :
Python 多进程 无法直接获得 一个函数的 返回值, 但是,可以通过共享变量来实现,
我们可以通过 Manager 去创建 共享变量,它有很多数据类型: list dict Queue 等等,
进程 同步 --- Lock :
为什么要用锁:
1 from multiprocessing import Process,Manager 2 import time 3 4 def add(d): 5 temp = d['num'] + 1 6 time.sleep(0.001) 7 d['num'] = temp 8 9 if __name__ == '__main__': 10 m = Manager() 11 d = m.dict({'num':0}) 12 p_list = [] 13 for i in range(10): 14 p = Process(target=add,args=(d,)) 15 p_list.append(p) 16 for p in p_list: 17 p.start() 18 19 for p in p_list: 20 p.join() 21 print(d)
下面使用 锁: 上锁 .acquire() 下锁: .release() 。 除了用 .acquire() 和 .release()也可以使用 with 语句,更方便,
1 from multiprocessing import Process,Manager,Lock 2 import time 3 4 def add(d,lock): 5 lock.acquire() 6 temp = d['num'] + 1 7 time.sleep(0.001) 8 d['num'] = temp 9 lock.release() 10 11 if __name__ == '__main__': 12 m = Manager() 13 d = m.dict({'num':0}) 14 lock = Lock() 15 p_list = [] 16 for i in range(10): 17 p = Process(target=add,args=(d,lock)) 18 p_list.append(p) 19 for p in p_list: 20 p.start() 21 22 for p in p_list: 23 p.join() 24 print(d)
1 from multiprocessing import Process,Manager,Lock 2 import time 3 4 def add(d,lock): 5 with lock: # 它会自动 上锁, 然后执行完代码 自动解锁 6 temp = d['num'] + 1 7 time.sleep(0.001) 8 d['num'] = temp 9 10 if __name__ == '__main__': 11 m = Manager() 12 d = m.dict({'num':0}) 13 lock = Lock() 14 p_list = [] 15 for i in range(10): 16 p = Process(target=add,args=(d,lock)) 17 p_list.append(p) 18 for p in p_list: 19 p.start() 20 21 for p in p_list: 22 p.join() 23 print(d)
注: 不能连续 acquire () 傻子也知道,
死锁 现象:使用多个锁才会出现的情况,
进程 间通信 --- Queue :
进程间 通信 ( IPC inter process communciate ) 的方式 :
1,基于文件 : 同一台机器上 进程间通信
2,基于网络 : 同一台 或者 不同电脑 都可
这里的队列 Queue 就是基于文件 来实现 进程间通信的, 它在 multiprocessing 模块中,
1 from multiprocessing import Process,Queue 2 import time 3 4 def func(q): 5 q.put('hello') 6 7 def func2(q): 8 time.sleep(1) 9 q.get() 10 11 if __name__ == '__main__': 12 q = Queue() 13 p_list = [] 14 for i in range(10): # 10 个进程 放 到队列中 15 p = Process(target=func,args=(q,)) 16 p_list.append(p) 17 18 for i in range(5): # 5 个进程 去 从队列中拿出来 , 最终应该是只剩 5个hello 19 p = Process(target=func2,args=(q,)) 20 p_list.append(p) 21 22 for p in p_list: 23 p.start() 24 25 for p in p_list: 26 p.join() 27 while not q.empty(): 28 print(q.get())
除了上面的基本方法: q.put() q.get() q.empty(),
还有其他方法:
1,get_nowait() :
当队列为空,时,如果是q.get(),那么程序就会阻塞了, 而使用 get_nowait() 则不会阻塞,但是 它会抛出一个异常 , queue.Empty 异常 (queue 为普通的队列 )
q.get_nowait() 取不到值时触发异常:queue.Empty
捕获这个异常 需要导入import queue(普通的队列,不是进程间的Queue)
1 from multiprocessing import Process,Queue 2 import time 3 import queue 4 5 def func(q): 6 q.put('hello') 7 8 def func2(q): 9 try: 10 q.get_nowait() 11 except queue.Empty as e: 12 print(e) 13 14 15 if __name__ == '__main__': 16 q = Queue() 17 p_list = [] 18 # for i in range(10): # 10 个进程 放 到队列中 19 # p = Process(target=func,args=(q,)) 20 # p_list.append(p) 21 22 for i in range(5): # 5 个进程 去 从队列中拿出来 , 最终应该是只剩 5个hello 23 p = Process(target=func2,args=(q,)) 24 p_list.append(p) 25 26 for p in p_list: 27 p.start() 28 29 for p in p_list: 30 p.join() 31 while not q.empty(): 32 print(q.get())
2,put_nowait() :
与 get_nowait() , 当队列满了,此时再put 数据的话,
如果使用q.put(),就阻塞了,直到 q不为空, 如果使用put_nowait() 则不会阻塞,但是,它会抛出异常, queue.Full ,同样它也在 queue中。
1 from multiprocessing import Process,Queue 2 import time 3 import queue 4 5 def func(q): 6 q.put('hello') 7 8 def func2(q): 9 time.sleep(1) 10 try: 11 q.put_nowait('hello') 12 except queue.Full as e: 13 print('满了') 14 print(e) 15 16 17 if __name__ == '__main__': 18 q = Queue(10) # 最多10个 19 p_list = [] 20 for i in range(10): # 10 个进程 放 到队列中 21 p = Process(target=func,args=(q,)) 22 p_list.append(p) 23 24 p = Process(target=func2,args=(q,)) 25 p_list.append(p) 26 27 28 for p in p_list: 29 p.start() 30 31 for p in p_list: 32 p.join() 33 while not q.empty(): 34 print(q.get())
3,full() :
创建队列时,如果有指明大小则有大小,反之,不限大小。
如果队列满了,返回True,反之False;
Queue 的一个子类:JoinableQueue:
JoinableQueue类 ,相对于 Queue 类来说,多了两个方法 一个是 task_done() ,一个是join()
JoinableQueue 的 put 方法时,Queue 计数器加一,但是 get方法时,不会主动减一,我们调用 task_done()才会减一。
join() 方法时,当计数器为 0 时候,才不阻塞,否则一直阻塞。
1 from multiprocessing import Process,JoinableQueue 2 import time 3 4 def func(q): 5 print('put hello') 6 q.put('hello') 7 8 def func2(q): 9 time.sleep(1) 10 print('get hello') 11 q.get() 12 13 if __name__ == '__main__': 14 q = JoinableQueue(10) # 最多10个 15 p_list = [] 16 for i in range(10): 17 p = Process(target=func,args=(q,)) 18 p_list.append(p) 19 20 for i in range(10): 21 p = Process(target=func2,args=(q,)) 22 p_list.append(p) 23 for p in p_list: 24 p.start() 25 26 time.sleep(1) 27 q.join() # 此时会一直 阻塞 28 print('h') 29 while not q.empty(): 30 print(q.get())
上面之所以 一直阻塞,是因为 没有调用task_done()
1 from multiprocessing import Process,JoinableQueue 2 import time 3 4 def func(q): 5 print('put hello') 6 q.put('hello') 7 8 def func2(q): 9 time.sleep(1) 10 print('get hello') 11 q.get() 12 q.task_done() 13 14 15 if __name__ == '__main__': 16 q = JoinableQueue(10) # 最多10个 17 p_list = [] 18 for i in range(10): 19 p = Process(target=func,args=(q,)) 20 p_list.append(p) 21 22 for i in range(10): 23 p = Process(target=func2,args=(q,)) 24 p_list.append(p) 25 for p in p_list: 26 p.start() 27 28 time.sleep(1) 29 q.join() # 此时 不会一直阻塞 30 print('h') 31 while not q.empty(): 32 print(q.get())
Python 的线程:
一般处理 并发 都是多线程,不会开启 多进程,
Python 的GIL 锁:
它是CPython 解释器的产物, 它带来的影响是 多线程 同一时刻 只有一个线程 可以被cpu执行,
这就造成了 Python 中的 多线程 不能利用多核, 即Python中的多线程 是 fake 多线程。
GIL 不会影响我们很多 。
线程 相关的模块 及函数 :
和线程 相关的 模块: threading
from threading import Thread
threading 模块 是模仿着 multiprocessing 来写的,所以 学习线程就变得 很轻松 ~
线程也又线程id (搜)
多线程用法:
多线程 大部分 和 进程 写法一致 :
1 from threading import Thread 2 import time 3 4 def func(): 5 time.sleep(1) 6 print('hello world') # 这个时候 就是阻塞的 7 8 if __name__ == '__main__': 9 t_list = [] 10 for i in range(10): 11 t = Thread(target=func) 12 t_list.append(t) 13 14 for t in t_list: # 开启10 个线程 15 t.start() 16 17 for t in t_list: 18 t.join() 19 20 print('wo shi zhu xiancheng')
与 多进程不同的是:
多线程的 守护线程 守护的是 其他非守护线程(包含 主线程)
多进程的 守护进程 守护的是 主进程。
1 from threading import Thread 2 import time 3 4 def test01(): 5 while True: 6 time.sleep(1) 7 print("我是守护子线程~") 8 9 def test02(): 10 time.sleep(3) 11 print("我是子线程....") 12 13 if __name__ == '__main__': 14 thread = Thread(target=test01) 15 thread.daemon = True 16 thread.start() 17 18 thread2 = Thread(target=test02) 19 thread2.start() 20 print("主线程的代码结束!") # 证明: 守护线程 守护的是 其他子线程。
1 from threading import Thread 2 import time 3 4 def test01(): 5 while True: 6 time.sleep(1) 7 print("我是守护子线程~") 8 9 def test02(): 10 time.sleep(1) 11 print("我是子线程....") 12 13 if __name__ == '__main__': 14 thread = Thread(target=test01) 15 thread.daemon = True 16 thread.start() 17 18 thread2 = Thread(target=test02) 19 thread2.start() 20 21 time.sleep(10) 22 print("主线程的代码结束!") # 证明: 守护线程 也守护 主线程。
所以,守护线程 守护的是 其他非守护线程 。
多线程 数据共享:
1 from threading import Thread 2 3 def add(): 4 global num 5 num += 1 6 7 if __name__ == '__main__': 8 num = 0 9 t_list = [] 10 for i in range(100): # 开100个子线程 11 t = Thread(target=add) 12 t_list.append(t) 13 14 for t in t_list: 15 t.start() 16 17 for t in t_list: 18 t.join() 19 print(num)
1 from threading import Thread 2 import time 3 4 def add(): 5 global num 6 temp = num + 1 7 time.sleep(0.001) 8 num = temp 9 10 if __name__ == '__main__': 11 num = 0 12 t_list = [] 13 for i in range(100): # 开100个子线程 14 t = Thread(target=add) 15 t_list.append(t) 16 17 for t in t_list: 18 t.start() 19 20 for t in t_list: 21 t.join() 22 print(num)
下面通过加锁 解决:
1 from threading import Thread,Lock 2 import time 3 4 def add(lock): 5 global num 6 with lock: 7 temp = num + 1 8 time.sleep(0.001) 9 num = temp 10 11 if __name__ == '__main__': 12 num = 0 13 lock = Lock() 14 t_list = [] 15 for i in range(100): # 开100个子线程 16 t = Thread(target=add,args=(lock,)) 17 t_list.append(t) 18 19 for t in t_list: 20 t.start() 21 22 for t in t_list: 23 t.join() 24 print(num)
多线程 中的队列:
线程中使用队列的话,就使用普通的 queue 就行,
threading 中的Timer 函数:
它相当于 js 中的setTimeout()
1 from threading import Timer 2 3 import time 4 5 def func(): 6 print('hello',time.time()) 7 8 9 if __name__ == '__main__': 10 print('hello',time.time()) 11 t = Timer(1,func) 12 t.start()
Python 的 池:
之前 进程 和 线程 都是 有多少个任务 开多少个 进程 /线程, 不好。
如果 先开好 一个数量的 池, 有任务可以直接执行,而且也可以重复利用 池子,减少了 很大的时间开销 。
池 相关的模块:
concurrent.futures 模块
from concurrent.futures import ProcessPoolExecutor,ThreadPoolExecutor
进程池:
1 from concurrent.futures import ProcessPoolExecutor,ThreadPoolExecutor 2 import os,time 3 4 def func(): 5 time.sleep(0.1) 6 print('我是一个任务, 进程id 为: ',os.getpid()) 7 8 def func2(): 9 time.sleep(0.1) 10 print('我是另一个任务, 进程id 为: ',os.getpid()) 11 12 13 if __name__ == '__main__': 14 p_pool = ProcessPoolExecutor(4) # 池中有 4个进程 15 16 for i in range(30): 17 p_pool.submit(func) # 提交10个 func 任务 给 池 18 19 for i in range(15): 20 p_pool.submit(func2) # 提交 5 个func2 任务 给池 21 ''' 22 我是一个任务, 进程id 为: 1320 23 我是一个任务, 进程id 为: 14628 24 我是一个任务, 进程id 为: 18492 25 我是一个任务, 进程id 为: 15896 26 我是一个任务, 进程id 为: 18492 27 我是一个任务, 进程id 为: 14628 28 我是一个任务, 进程id 为: 15896 29 我是一个任务, 进程id 为: 1320 30 我是一个任务, 进程id 为: 1320 31 我是一个任务, 进程id 为: 18492 32 我是一个任务, 进程id 为: 14628 33 我是一个任务, 进程id 为: 15896 34 我是一个任务, 进程id 为: 1320 35 我是一个任务, 进程id 为: 14628 36 我是一个任务, 进程id 为: 18492 37 我是一个任务, 进程id 为: 15896 38 我是一个任务, 进程id 为: 1320 39 我是一个任务, 进程id 为: 18492 40 我是一个任务, 进程id 为: 14628 41 我是一个任务, 进程id 为: 15896 42 我是一个任务, 进程id 为: 15896 43 我是一个任务, 进程id 为: 18492 44 我是一个任务, 进程id 为: 1320 45 我是一个任务, 进程id 为: 14628 46 我是一个任务, 进程id 为: 1320 47 我是一个任务, 进程id 为: 18492 48 我是一个任务, 进程id 为: 14628 49 我是一个任务, 进程id 为: 15896 50 我是另一个任务, 进程id 为: 18492 51 我是一个任务, 进程id 为: 15896 52 我是一个任务, 进程id 为: 1320 53 我是另一个任务, 进程id 为: 14628 54 我是另一个任务, 进程id 为: 18492 55 我是另一个任务, 进程id 为: 14628 56 我是另一个任务, 进程id 为: 1320 57 我是另一个任务, 进程id 为: 15896 58 我是另一个任务, 进程id 为: 15896 59 我是另一个任务, 进程id 为: 18492 60 我是另一个任务, 进程id 为: 1320 61 我是另一个任务, 进程id 为: 14628 62 我是另一个任务, 进程id 为: 15896 63 我是另一个任务, 进程id 为: 18492 64 我是另一个任务, 进程id 为: 1320 65 我是另一个任务, 进程id 为: 14628 66 我是另一个任务, 进程id 为: 15896 67 '''
传参数:
之前都是 元组,这里直接传 位置 参数即可,
1 from concurrent.futures import ProcessPoolExecutor,ThreadPoolExecutor 2 import os,time 3 4 def func(a,b): 5 time.sleep(0.1) 6 print('我是一个任务, 进程id 为: ',os.getpid(),' 参数:',a,b) 7 8 def func2(a,b): 9 time.sleep(0.1) 10 print('我是另一个任务, 进程id 为: ',os.getpid(),' 参数:',a,b) 11 12 13 if __name__ == '__main__': 14 p_pool = ProcessPoolExecutor(4) # 池中有 4个进程 15 16 for i in range(10): 17 p_pool.submit(func,i,i+1) # 提交10个 func 任务 给 池 18 19 for i in range(5): 20 p_pool.submit(func2,i,i+1) # 提交 5 个func2 任务 给池 21 22 23 ''' 24 我是一个任务, 进程id 为: 4488 参数: 2 3 25 我是一个任务, 进程id 为: 21540 参数: 3 4 26 我是一个任务, 进程id 为: 12624 参数: 0 1 27 我是一个任务, 进程id 为: 21324 参数: 1 2 28 我是一个任务, 进程id 为: 4488 参数: 5 6 29 我是一个任务, 进程id 为: 12624 参数: 7 8 30 我是一个任务, 进程id 为: 21324 参数: 6 7 31 我是一个任务, 进程id 为: 21540 参数: 4 5 32 我是一个任务, 进程id 为: 12624 参数: 8 9 33 我是另一个任务, 进程id 为: 21324 参数: 0 1 34 我是另一个任务, 进程id 为: 21540 参数: 1 2 35 我是一个任务, 进程id 为: 4488 参数: 9 10 36 我是另一个任务, 进程id 为: 12624 参数: 3 4 37 我是另一个任务, 进程id 为: 21324 参数: 4 5 38 我是另一个任务, 进程id 为: 21540 参数: 2 3 39 '''
获取返回值:
1 from concurrent.futures import ProcessPoolExecutor,ThreadPoolExecutor 2 import os,time 3 4 def func(a,b): 5 time.sleep(0.1) 6 print('我是一个任务, 进程id 为: ',os.getpid(),' 参数:',a,b) 7 return a+b+1 8 9 def func2(a,b): 10 time.sleep(0.1) 11 print('我是另一个任务, 进程id 为: ',os.getpid(),' 参数:',a,b) 12 return a+b+2 13 14 15 if __name__ == '__main__': 16 p_pool = ProcessPoolExecutor(4) # 池中有 4个进程 17 18 for i in range(10): 19 ret = p_pool.submit(func,i,i+1) # ret 的类型是 Future 对象 可以通过 .result() 获取(.result() 会阻塞的) 20 print(ret.result()) 21 for i in range(5): 22 ret = p_pool.submit(func2,i,i+1) # ret 的类型是 Future 对象 23 print(ret.result()) 24 25 ''' 26 我是一个任务, 进程id 为: 20516 参数: 0 1 27 2 28 我是一个任务, 进程id 为: 8468 参数: 1 2 29 4 30 我是一个任务, 进程id 为: 4836 参数: 2 3 31 6 32 我是一个任务, 进程id 为: 7648 参数: 3 4 33 8 34 我是一个任务, 进程id 为: 20516 参数: 4 5 35 10 36 我是一个任务, 进程id 为: 8468 参数: 5 6 37 12 38 我是一个任务, 进程id 为: 4836 参数: 6 7 39 14 40 我是一个任务, 进程id 为: 7648 参数: 7 8 41 16 42 我是一个任务, 进程id 为: 20516 参数: 8 9 43 18 44 我是一个任务, 进程id 为: 8468 参数: 9 10 45 20 46 我是另一个任务, 进程id 为: 4836 参数: 0 1 47 3 48 我是另一个任务, 进程id 为: 7648 参数: 1 2 49 5 50 我是另一个任务, 进程id 为: 20516 参数: 2 3 51 7 52 我是另一个任务, 进程id 为: 8468 参数: 3 4 53 9 54 我是另一个任务, 进程id 为: 4836 参数: 4 5 55 11 56 '''
上面 主要是 .result()是个同步 阻塞的过程,
我们可以先加入,后面统一 .result() :
1 from concurrent.futures import ProcessPoolExecutor,ThreadPoolExecutor 2 import os,time 3 4 def func(a,b): 5 time.sleep(0.1) 6 print('我是一个任务, 进程id 为: ',os.getpid(),' 参数:',a,b) 7 return a+b+1 8 9 def func2(a,b): 10 time.sleep(0.1) 11 print('我是另一个任务, 进程id 为: ',os.getpid(),' 参数:',a,b) 12 return a+b+2 13 14 15 if __name__ == '__main__': 16 p_pool = ProcessPoolExecutor(4) # 池中有 4个进程 17 18 res = [] 19 for i in range(10): 20 ret = p_pool.submit(func,i,i+1) # ret 的类型是 Future 对象 可以通过 .result() 获取(.result() 会阻塞的) 21 res.append(ret) 22 for i in range(5): 23 ret = p_pool.submit(func2,i,i+1) # ret 的类型是 Future 对象 24 res.append(ret) 25 26 27 p_pool.shutdown() # 阻塞, 直到所有任务 结束 28 # 等所有 任务都结束之后 ,再一起看结果 29 for item in res: 30 print(item.result()) # .result() 是同步 , 阻塞的 31 ''' 32 我是一个任务, 进程id 为: 17700 参数: 0 1 33 我是一个任务, 进程id 为: 13092 参数: 2 3 34 我是一个任务, 进程id 为: 9452 参数: 1 2 35 我是一个任务, 进程id 为: 13324 参数: 3 4 36 我是一个任务, 进程id 为: 17700 参数: 4 5 37 我是一个任务, 进程id 为: 13092 参数: 5 6 38 我是一个任务, 进程id 为: 13324 参数: 7 8 39 我是一个任务, 进程id 为: 9452 参数: 6 7 40 我是一个任务, 进程id 为: 17700 参数: 8 9 41 我是另一个任务, 进程id 为: 13092 参数: 0 1 42 我是另一个任务, 进程id 为: 9452 参数: 1 2 43 我是一个任务, 进程id 为: 13324 参数: 9 10 44 我是另一个任务, 进程id 为: 17700 参数: 2 3 45 我是另一个任务, 进程id 为: 13324 参数: 4 5 46 我是另一个任务, 进程id 为: 9452 参数: 3 4 47 2 48 4 49 6 50 8 51 10 52 12 53 14 54 16 55 18 56 20 57 3 58 5 59 7 60 9 61 11 62 '''
map() 方法 :
它是为了 取代 for 循环 submit 这个操作,
1 from concurrent.futures import ProcessPoolExecutor,ThreadPoolExecutor 2 import os,time 3 4 def func(a): 5 b = a+1 6 time.sleep(0.1) 7 print('我是一个任务, 进程id 为: ',os.getpid(),' 参数:',a,b) 8 return a+b+1 9 10 def func2(a): 11 b = a+1 12 time.sleep(0.1) 13 print('我是另一个任务, 进程id 为: ',os.getpid(),' 参数:',a,b) 14 return a+b+2 15 16 17 if __name__ == '__main__': 18 p_pool = ProcessPoolExecutor(4) # 池中有 4个进程 19 20 ret1 = p_pool.map(func,range(10)) # func 为任务函数 ,第二个要求是可迭代对象,为传入的参数,返回 ret1 为可迭代对象 ,里面放的 直接是 任务函数的返回值 21 ret2 = p_pool.map(func2,range(5)) 22 23 p_pool.shutdown() # 阻塞, 直到所有任务 结束 24 # 等所有 任务都结束之后 ,再一起看结果 25 for item in ret1: 26 print(item) 27 for item in ret2: 28 print(item) 29 30 ''' 31 我是一个任务, 进程id 为: 8972 参数: 0 1 32 我是一个任务, 进程id 为: 15204 参数: 1 2 33 我是一个任务, 进程id 为: 18936 参数: 3 4 34 我是一个任务, 进程id 为: 22288 参数: 2 3 35 我是一个任务, 进程id 为: 8972 参数: 4 5 36 我是一个任务, 进程id 为: 18936 参数: 6 7 37 我是一个任务, 进程id 为: 22288 参数: 7 8 38 我是一个任务, 进程id 为: 15204 参数: 5 6 39 我是一个任务, 进程id 为: 8972 参数: 8 9 40 我是另一个任务, 进程id 为: 18936 参数: 0 1 41 我是另一个任务, 进程id 为: 22288 参数: 1 2 42 我是一个任务, 进程id 为: 15204 参数: 9 10 43 我是另一个任务, 进程id 为: 8972 参数: 2 3 44 我是另一个任务, 进程id 为: 22288 参数: 3 4 45 我是另一个任务, 进程id 为: 15204 参数: 4 5 46 2 47 4 48 6 49 8 50 10 51 12 52 14 53 16 54 18 55 20 56 3 57 5 58 7 59 9 60 11 61 '''
不过 map 传参时 稍显复杂,只能传递一个 可迭代对象,
add_done_callback(fn):
1 from concurrent.futures import ProcessPoolExecutor,ThreadPoolExecutor 2 import os,time 3 4 def func(a,b): 5 time.sleep(0.1) 6 print('我是一个任务, 进程id 为: ',os.getpid(),' 参数:',a,b) 7 return a+b+1 8 9 def func2(a,b): 10 time.sleep(0.1) 11 print('我是另一个任务, 进程id 为: ',os.getpid(),' 参数:',a,b) 12 return a+b+2 13 14 def ck(ret): 15 print(ret.result()) 16 17 if __name__ == '__main__': 18 p_pool = ProcessPoolExecutor(4) # 池中有 4个进程 19 20 for i in range(10): 21 ret = p_pool.submit(func,i,i+1) 22 ret.add_done_callback(ck) #ret 获取成功 之后 执行回调 函数 23 for i in range(5): 24 ret = p_pool.submit(func2,i,i+1) 25 ret.add_done_callback(ck) 26 27 ''' 28 我是一个任务, 进程id 为: 14096 参数: 2 3 29 我是一个任务, 进程id 为: 18004 参数: 0 1 30 我是一个任务, 进程id 为: 7292 参数: 1 2 31 我是一个任务, 进程id 为: 20532 参数: 3 4 32 6 33 2 34 4 35 8 36 我是一个任务, 进程id 为: 7292 参数: 5 6 37 我是一个任务, 进程id 为: 14096 参数: 4 5 38 我是一个任务, 进程id 为: 20532 参数: 7 8 39 我是一个任务, 进程id 为: 18004 参数: 6 7 40 12 41 10 42 16 43 14 44 我是一个任务, 进程id 为: 14096 参数: 9 10 45 我是另一个任务, 进程id 为: 18004 参数: 1 2 46 我是另一个任务, 进程id 为: 20532 参数: 0 1 47 我是一个任务, 进程id 为: 7292 参数: 8 9 48 20 49 18 50 3 51 5 52 我是另一个任务, 进程id 为: 14096 参数: 2 3 53 我是另一个任务, 进程id 为: 7292 参数: 3 4 54 我是另一个任务, 进程id 为: 18004 参数: 4 5 55 9 56 7 57 11 58 '''
Python 的协程 Coroutines:
协程 是 操作系统也不可见的,操作系统能调度的最小单位是 线程,
协程 做的工作 是 利用 阻塞的时间,然后执行其他任务,(还是在 一个线程上 )

协程相关的模块:
两个 模块:
1,gevent (第三方) :它是利用了 greenlet (c语言写)这个模块 进行 切换任务 ,还有自己内部加的自动规避 io 的功能
2,asyncio :它是利用了 yield(python 的语法)进行 切换任务 , 还有自己内部加的自动规避 io 的功能
协程间 是 数据安全的:

之所以,进程 和 线程 数据不安全,是因为它们都是由 操作系统 控制切换的, 而协程 是 用户控制切换的。
进程 ,线程,协程 的开销:
进程 很大
线程 小
协程 更小,(几乎 和 调用一个函数一样小)
Python 中 多线程 是否 无用:

通过上述对比,明显感到 协程 比多线程 好,那么都用协程不就可以了 ,多线程 不用不就行了?
no ,no,no ,
协程有个很大的弊端,它的所有切换都是 基于用户的 ,只能切换一些 网络,sleep 等用户可以感知到的,
但是,像 print, 文件操作 等用户感知不到的,它是无法切换的,所以只能用 多线程,
所以,多线程 是有用的,
协程 使用:
1 import gevent 2 3 def func1(): 4 print('任务一:开始') 5 gevent.sleep(1) # 切出去执行 别的没有阻塞的任务 6 print('任务一:结束') 7 8 if __name__ == '__main__': 9 cor = gevent.spawn(func1) 10 print('主任务') 11 gevent.sleep(1) # 切出去执行 别的没有阻塞的任务 12 ''' 13 主任务 14 任务一:开始 15 '''
1 import gevent 2 3 def func1(): 4 print('任务一:开始') 5 gevent.sleep(1) # 切出去执行 别的没有阻塞的任务 6 print('任务一:结束') 7 8 if __name__ == '__main__': 9 cor = gevent.spawn(func1) 10 print('主任务') 11 gevent.sleep(2) # 切出去执行 别的没有阻塞的任务 12 ''' 13 主任务 14 任务一:开始 15 任务一:结束 16 '''
协程.join() 方法:
1 import gevent 2 3 def func1(): 4 print('任务一:开始') 5 gevent.sleep(1) # 切出去执行 别的没有阻塞的任务 6 print('任务一:结束') 7 8 if __name__ == '__main__': 9 cor = gevent.spawn(func1) 10 print('主任务') 11 cor.join() 12 print('所有 协程 任务都完成了') 13 14 15 16 ''' 17 主任务 18 任务一:开始 19 任务一:结束 20 所有 协程 任务都完成了 21 '''
1 import gevent 2 3 def func1(): 4 print('任务一:开始') 5 gevent.sleep(1) # 切出去执行 别的没有阻塞的任务 6 print('任务一:结束') 7 8 def func2(): 9 print('任务二:开始') 10 gevent.sleep(1) # 切出去执行 别的没有阻塞的任务 11 print('任务二:结束') 12 13 14 15 if __name__ == '__main__': 16 cor_list = [] 17 for i in range(10): 18 cor = gevent.spawn(func1) # 10个协程任务 处理 func1 19 cor_list.append(cor) 20 21 for i in range(5): 22 cor = gevent.spawn(func2) # 5个协程任务 处理 func2 23 cor_list.append(cor) 24 25 for cor in cor_list: 26 cor.join() 27 print('所有 协程 任务都完成了') 28 29 30 31 ''' 32 任务一:开始 33 任务一:开始 34 任务一:开始 35 任务一:开始 36 任务一:开始 37 任务一:开始 38 任务一:开始 39 任务一:开始 40 任务一:开始 41 任务一:开始 42 任务二:开始 43 任务二:开始 44 任务二:开始 45 任务二:开始 46 任务二:开始 47 任务一:结束 48 任务一:结束 49 任务一:结束 50 任务一:结束 51 任务一:结束 52 任务一:结束 53 任务一:结束 54 任务一:结束 55 任务一:结束 56 任务一:结束 57 任务二:结束 58 任务二:结束 59 任务二:结束 60 任务二:结束 61 任务二:结束 62 所有 协程 任务都完成了 63 '''
简便写法 gevent.joinall() 方法:
1 import gevent 2 3 def func1(): 4 print('任务一:开始') 5 gevent.sleep(1) # 切出去执行 别的没有阻塞的任务 6 print('任务一:结束') 7 8 def func2(): 9 print('任务二:开始') 10 gevent.sleep(1) # 切出去执行 别的没有阻塞的任务 11 print('任务二:结束') 12 13 14 15 if __name__ == '__main__': 16 cor_list = [] 17 for i in range(10): 18 cor = gevent.spawn(func1) # 10个协程任务 处理 func1 19 cor_list.append(cor) 20 21 for i in range(5): 22 cor = gevent.spawn(func2) # 5个协程任务 处理 func2 23 cor_list.append(cor) 24 25 gevent.joinall(cor_list) # gevent.joinall() 更方便 26 print('所有 协程 任务都完成了') 27 28 29 30 ''' 31 任务一:开始 32 任务一:开始 33 任务一:开始 34 任务一:开始 35 任务一:开始 36 任务一:开始 37 任务一:开始 38 任务一:开始 39 任务一:开始 40 任务一:开始 41 任务二:开始 42 任务二:开始 43 任务二:开始 44 任务二:开始 45 任务二:开始 46 任务一:结束 47 任务一:结束 48 任务一:结束 49 任务一:结束 50 任务一:结束 51 任务一:结束 52 任务一:结束 53 任务一:结束 54 任务一:结束 55 任务一:结束 56 任务二:结束 57 任务二:结束 58 任务二:结束 59 任务二:结束 60 任务二:结束 61 所有 协程 任务都完成了 62 '''
协程 传递参数:
直接 放入 位置参数即可,
协程 不认是 time.sleep() 类似 问题 :
如何解决:
1 import gevent 2 3 #================================ 4 from gevent import monkey 5 monkey.patch_all() 6 import time 7 #================================ 8 def func1(): 9 print('任务一:开始') 10 time.sleep(1) # 切出去执行 别的没有阻塞的任务 11 print('任务一:结束') 12 13 def func2(): 14 print('任务二:开始') 15 time.sleep(1) # 切出去执行 别的没有阻塞的任务 16 print('任务二:结束') 17 18 if __name__ == '__main__': 19 cor_list = [] 20 for i in range(10): 21 cor = gevent.spawn(func1) # 10个协程任务 处理 func1 22 cor_list.append(cor) 23 24 for i in range(5): 25 cor = gevent.spawn(func2) # 5个协程任务 处理 func2 26 cor_list.append(cor) 27 28 gevent.joinall(cor_list) # gevent.joinall() 更方便 29 print('所有 协程 任务都完成了')
使用 gevent 协程实现 socket 并发:
1 import gevent 2 3 #================================ 4 from gevent import monkey 5 monkey.patch_all() 6 import socket 7 #================================ 8 9 def comm_withclient(conn): 10 while 1: 11 d = conn.recv(1024) 12 print(d.decode()) 13 14 15 16 if __name__ == '__main__': 17 sk = socket.socket() 18 sk.bind(('127.0.0.1', 8080)) 19 sk.listen() 20 21 while 1: 22 conn,addr = sk.accept() 23 # 开协程 来一个 客户端 开一个协程 24 cor = gevent.spawn(comm_withclient,conn)
1 import socket 2 sk = socket.socket() 3 4 sk.connect(('127.0.0.1',8080)) 5 6 while 1: 7 d = input(">>> [client]").encode() 8 sk.send(d)
1 import socket 2 sk = socket.socket() 3 4 sk.connect(('127.0.0.1',8080)) 5 6 while 1: 7 d = input(">>> [client]").encode() 8 sk.send(d)
一台4cpu的电脑 开 5个进程,每个进程开 20个线程,每个线程可以开 500个协程 这一共是:5w 的并发量 (很多了)。
asyncio 模块 :
参考:https://www.cnblogs.com/Eva-J/articles/10437164.html
它是Python 自带的一个模块,
1 import asyncio 2 3 async def func(a): 4 print('开始',a) 5 await asyncio.sleep(1) # 此时会 切换出去执行 没有阻塞的任务~ 6 print('结束',a+1) 7 8 # await 后面 是个可能会阻塞的方法 9 # await 必须在 async 函数里 10 11 #================================ 12 # 上面操作后, 就不能直接 调一个 协程函数 func 了, | func() × 13 14 evt_loop = asyncio.get_event_loop() 15 # evt_loop.run_until_complete(func(0)) # 这是 开启一个任务 16 evt_loop.run_until_complete(asyncio.wait([func(1),func(2),func(3)]) ) # 这是 开启 多个任务
数据库:
基础点:
通配符:
% :不限长度,
_:匹配一个字符,
mysql 引擎介绍(存储引擎):
https://www.cnblogs.com/eva-J/articles/9682063.html
存储数据的格式,
默认的存储引擎是 innodb , 它支持 事务(transactions ),行级锁(row-level locking), 外键(foreign keys)
只有 innodb 支持行级锁,例如myisam 支持的是 表级锁, (innodb 行级锁 肯定比 myisam 的表级锁 效率高 )
各种存储引擎的使用场景:
一般 默认 innnodb
当只查时, myisam
当数据不是很重要,而且要求速度时:memory ,例如:每个用户的登录状态,
innodb :是一个文件存表结构,一个文件存 数据,
myisam: 三个表,一个文件存结构,一个存数据,还有就是索引,(这也是它快的原因)
memory 和 blackhole :都是只存表结构,
mysql中的数据类型:
https://www.cnblogs.com/eva-J/articles/9683316.html
数值,
1,小数精度要求高的场景(汇率,科研,利息,金融,银行等),要使用 decimal ,float 和 double 不准,
为什么decimal 准确度:它底层是以 字符串来存的,
不过 decimal 有缺点:就是它
2,整型的约束,没用,
时间,
date 年月日,
time 时分秒 ,
datetime 年月日时分秒,( 常用 范围 1000-01-01 ---> 9999-12-31 )
还有timestramp (范围较小, 1970 - 2038)
平时常用:date , datetime
注:
timestramp 不能为空,默认当前时间,
mysql 中 now() 函数 是当前时间,
字符串,
常用的是 char varchar ,如果要有的话,longtext(存个视频),但是一般已经不用mysql 存大量数据了,
char : 定长,浪费硬盘,存取速度非常快
varchar:变长,节省空间,存取速度相对慢, (varchar 除了数据以外,要额外存 长度)
char :适合 数据 的长度变化小, 例如手机号,身份证,学号,
varchar:数据长度变化大 ,
枚举 和 集合 :
枚举:单选 例如, 性别
集合:多选 例如, 兴趣爱好
表的完整性约束:
是否允许空(not null / null ),是否唯一( unique ),主键(primary key),外键(foreign key),自增(auto)等,
一般是:唯一 非空,
主键的特点也是 :唯一,非空,
外键:只有innodb 支持外键,
连级: cascade , 连级 删除 ,连级更新,
补: 数据库的模式很重要,一般要设置为 严格模式,
联合主键:
为一个以上的字段 设置 唯一非空,
例如 ip 和 端口 唯一,
create table t (id int, ip char(12) ,port char(10) ,primary key(ip,port ) )
联合唯一:
unique
create table t(id int primary key ,ip char(12),port char(10) ,unique(ip,port) )
上面ip 和 port 作为主键,我们一般习惯 将id 作为主键,所以可以用联合唯一,代替联合 主键:
create table t(id int ,ip char(12) not null ,port char(10) not null ,unique(ip,port) );
注: 不写主键,默认第一个就是,
修改表结构:
https://www.cnblogs.com/eva-J/articles/9677452.html
修改字段名,修改约束 ,修改字段排列顺序等,
SQL三种类型:
DDL 语句(数据库,表,视图,索引,存储过程)
DML 语句 (增删改查)
DCL语句 (权限控制)
记录操作:
https://www.cnblogs.com/eva-J/articles/9688293.html
主要有 增删改查:
它是DML ,
查询:
单表查询:
https://www.cnblogs.com/Eva-J/articles/9688313.html

多表查询:
https://www.cnblogs.com/eva-J/articles/9688383.html
表连接:
内连接,
左外连接 (左优先)
右外连接 (右优先)
全外连接 (mysql 中 使用 左 ,右连接, 然后union 关联下 ),#注意 union与union all的区别:union会去掉相同的记录
union 的 作用: union查询就是把2条或者多条sql语句的查询结果,合并成一个结果集
子查询:
#1:子查询是将一个查询语句嵌套在另一个查询语句中。 #2:内层查询语句的查询结果,可以为外层查询语句提供查询条件。 #3:子查询中可以包含:IN、NOT IN、ANY、ALL、EXISTS 和 NOT EXISTS等关键字 #4:还可以包含比较运算符:= 、 !=、> 、<等
pymysql 模块 的使用:
它是个第三方模块,
pymysql的基本使用
1 import pymysql 2 conn = pymysql.connect(host='127.0.0.1', 3 user='root', 4 password="123456", 5 database='course',) 6 cursor = conn.cursor() #cursor 游标 7 cursor.execute('show tables;') 8 ret = cursor.fetchall() 9 print(ret) #(('course',), ('dept',), ('dept_temp',), ('students',), ('teacher',)) 10 11 #================================ 12 13 cursor.execute('select * from dept') 14 ret = cursor.fetchall() 15 print(ret) 16 #================================ 17 cursor.execute('select * from dept') 18 ret = cursor.fetchone() 19 print(ret) 20 #================================ 21 22 cursor.execute('select * from dept') 23 ret = cursor.fetchmany(3) 24 print(ret) 25 26 27 #================================ 28 cursor = conn.cursor(cursor=pymysql.cursors.DictCursor) # 此时返回的是 字典~ 29 cursor.execute('select * from dept') 30 ret = cursor.fetchmany(3) 31 print(ret) 32 33 34 cursor.close() # 用完之后 关闭 游标 35 conn.close() # conn 也要断开连接 36 37 ''' 38 (('course',), ('dept',), ('dept_temp',), ('students',), ('teacher',)) 39 ((1002, 'a'), (1003, 'a'), (1004, '高中部'), (1005, '大学')) 40 (1002, 'a') 41 ((1002, 'a'), (1003, 'a'), (1004, '高中部')) 42 [{'id': 1002, 'dept_name': 'a'}, {'id': 1003, 'dept_name': 'a'}, {'id': 1004, 'dept_name': '高中部'}] 43 '''
pymysql 增 删 改 (要 commit ):
1 import pymysql 2 conn = pymysql.connect(host='127.0.0.1', 3 user='root', 4 password="123456", 5 database='course',) 6 cursor = conn.cursor() 7 #================================ 8 try: 9 cursor.execute('insert into dept values(1001,"中")') 10 11 12 conn.commit() # 当对 表 增删改 的时候,都需要 进行 commit 提交 13 except: 14 #如果出现 问题就 进行 回滚 15 print('Q') 16 conn.rollback() 17 18 cursor.close() # 用完之后 关闭 游标 19 conn.close() # conn 也要断开连接
cursor.rowcount() :
1 import pymysql 2 conn = pymysql.connect(host='127.0.0.1', 3 user='root', 4 password="123456", 5 database='course',) 6 cursor = conn.cursor() 7 #================================ 8 cursor.execute('select * from dept') 9 10 count = cursor.rowcount # 行数 11 12 for i in range(count): 13 print(cursor.fetchone()) 14 15 16 cursor.close() # 用完之后 关闭 游标 17 conn.close() # conn 也要断开连接
python 代码登陆 数据库 (sql 注入 问题) :
![]()
如果是用 拼接 参数 来登录会有下面的问题:
1,是要记得 用户名 和 密是是双引号,
2,要注意 -- 代表注释掉 后面的内容,
3,使用 or 条件
它叫 sql 注入 问题,
我们可以利用 cursor.execute(sql, (user,pwd) ) 来帮我们做,它会防止一些 sql 注入的问题 ,

总结: 一定不能自己拼接 字符串,
python 趣实现:
Python代码实现进度条:
1 import time 2 for i in range(0,101): 3 time.sleep(0.2) 4 char_num = i # 打印多少个 字符 5 if i == 100: 6 s = ' {}% : {} '.format(i,'*'*char_num) 7 else: 8 s = ' {}% : {}'.format(i,'*'*char_num) 9 print(s,end='',flush=True)