使用的第三方库:
爬虫:requests
解析HTML:lxml中的etree ,使用的是xpath语法
操作excel 的 三个: xlrd,xlwt,xlutils,使用参考:https://blog.csdn.net/qq_30242609/article/details/68953172
注:前提博客园设置中要显示积分和排名才能爬取到,接口是:https://www.cnblogs.com/***/ajax/sidecolumn.aspx
代码:


from lxml import etree import requests import re,os.path,datetime import xlrd, xlwt from xlutils.copy import copy # 注意只能操作 .xls,不能操作新版的 .xlsx res = requests.get("https://www.cnblogs.com/zach0812/ajax/sidecolumn.aspx") print(res.status_code) if res.status_code == 200: # with open("content.html", "w", encoding="utf8") as f: # f.write(res.content.decode()) content_str = res.content.decode() # 将字符串 转为HTML d_html = etree.HTML(content_str) # 使用xpath 进行解析 res_objs = d_html.xpath('//div[@id="sidebar_scorerank"]//li') data = [] for obj in res_objs: s = obj.text data.append(int(re.findall("(d+)", s)[0])) print(data) # [积分,排名] int,int # 写入到excel 中 # 判断 excel 文件是否存在 path = "D:.projectpro_pythoncnblog_jf_pm.xls" date = datetime.date.today().strftime("%Y-%m-%d") if os.path.isfile(path): workbook = xlrd.open_workbook(path) rows = workbook.sheets()[0].nrows # 已经存在的行数 new_workbook = copy(workbook) # 使用copy 复制 原有的workbook new_workbook.get_sheet(0).write(rows, 0, date) new_workbook.get_sheet(0).write(rows, 1, data[0]) new_workbook.get_sheet(0).write(rows, 2, data[1]) new_workbook.save(path) else: workbook = xlwt.Workbook() sheet = workbook.add_sheet("sheet1") sheet.write(0,0,"日期") sheet.write(0,1,"积分") sheet.write(0,2,"排名") # ================== sheet.write(1,0,date) sheet.write(1,1,data[0]) sheet.write(1,2,data[1]) workbook.save(path)
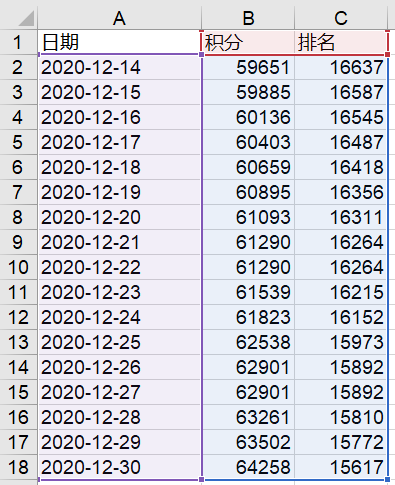
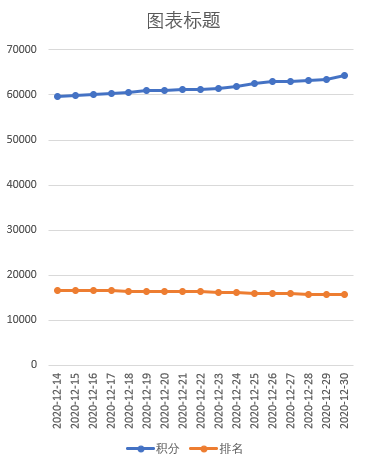
可以将代码部署到服务器,每天爬一次,累积数据就可以进行可视化展示了!