1. 决策树和决策森林
- 决策树算法家族能自然地处理类别型和数值型特征
- 决策树算法容易并行化
- 它们对数据中的离群点(outlier)具有鲁棒性(robust),这意味着一些极端或可能错误的数据点根本不会对预测产生影响
2. Covtype数据集
https://archive.ics.uci.edu/ml/machine-learning-databases/covtype/
wget https://archive.ics.uci.edu/ml/machine-learning-databases/covtype/covtype.data.gz
wget https://archive.ics.uci.edu/ml/machine-learning-databases/covtype/covtype.info
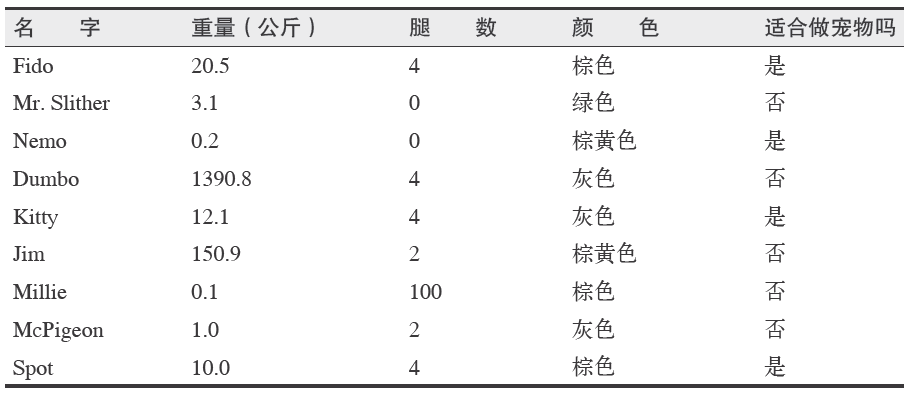
该数据集记录了美国科罗拉多州不同地块的森林植被类型,每个样本包含了描述每块土地的若干特征,包括海拔、坡度、到水源的距离、遮阳情况和土壤类型,并且随同给出了地块的已知森林植被类型。
3. labeledPoint
Spark Mllib 将特征向量抽象为 LabeledPoint,它由一个包含多个特征值的 Spark Mllib Vector 和一个称为 label 的目标值组成。该目标为Double 类型,而 Vector 本质上是由多个 Double 类型值的抽象。
这说明 LabeledPoint 只适用于数值型特征。但只要经过适当编码,LabeledPoint 也可用于类别型特征。
4. one-hot 编码
one-hot 编码或 1-of-n 编码。在这种编码中,一个有 N 个不同取值的类别型特征可以变成 N 个数值型特征,变换后的每个数值型特征的取值为 0 或 1
比如,类别型特征“天气”可能的取值有“多云”,“有雨”或“晴朗”。在 1-of-n 编码中,它就变成了三个数值型特征:多云用 1, 0, 0 表示,“有雨”用 0, 1, 0 表示。就可以为这三个数值型特征分别取名:is_cloudy、is_rainy 和 is_clear
5. 第一颗决策树
决策树(DecisionTree)的实现,以及Spark Mllib 中其他几个实现,都要求输入必须是 LabeledPoint 对象格式:
val data = rawData.map{ line =>
val values = line.split(',').map(_.toDouble)
val featureVector = Vectors.dense(values.init)
val label = values.last - 1
LabeledPoint(label, featureVector)
}
init 返回除最后一个值之外的所有值;最后一列是label
决策树要求label 从0开始,所以要减一 value.last - 1
6. 评估模型
这里我们使用精确度为评价指标
首先我们将数据分成完整三部分:训练集、交叉检验集(CV)和测试集
训练集占80%,交叉检验集和测试集各占10%。
val Array(trainData, cvData, testData) = data.randomSplit(Array(0.8, 0.1, 0.1))
trainData.cache
cvData.cache
testData.cache
DecisionTree 实现也有几个超参数,我们需要为它选择值;
训练集和cv集用于给这些超参数选择一个合适的值。而测试集,用于对基于选定超参数的模型期望准确度做无偏估计。
7. 第一棵决策树
scala> val model = DecisionTree.trainClassifier( trainData, 7, Map[Int,Int](), "gini", 4, 100)
model: org.apache.spark.mllib.tree.model.DecisionTreeModel = DecisionTreeModel classifier of depth 4 with 31 nodes
def getMetrics(model: DecisionTreeModel, data: RDD[LabeledPoint]):
MulticlassMetrics = {
val predictionsAndLabels = data.map(example =>
(model.predict(example.features), example.label)
)
new MulticlassMetrics(predictionsAndLabels)
}
上面两个函数,第一个定义了决策树的模型生成函数;
第二个getMetrics 定义了:使用生成的模型,对输入数据做预测,然后比对模型预测的结果与真实结果。
MulticlassMetrics 以不同方式计算分类器预测质量的标准指标,这里我们用cvData来查看预测结果metrics:
scala> val metrics = getMetrics(model, cvData)
8. 混淆矩阵
scala> metrics.confusionMatrix
res3: org.apache.spark.mllib.linalg.Matrix =
14421.0 6333.0 10.0 1.0 0.0 0.0 378.0
5691.0 22125.0 388.0 32.0 0.0 0.0 40.0
0.0 432.0 3070.0 82.0 0.0 0.0 0.0
0.0 0.0 155.0 114.0 0.0 0.0 0.0
0.0 960.0 31.0 0.0 9.0 0.0 0.0
0.0 472.0 1178.0 95.0 0.0 0.0 0.0
1130.0 22.0 0.0 0.0 0.0 0.0 929.0
因为目标类别的取值有7个,所以混淆矩阵是一个 7 x 7 的矩阵,矩阵每一行对应一个实际的正确类别值,矩阵每一列按顺序对应预测值。
第 i 行第 j 列的元素代表一个正确类别为 i 的样本被预测为类别为 j 的次数。
因此,对角线上的元素代表预测正确的次数,而其他元素则代表预测错误的次数,而其他元素则代表预测错误的次数。对角线上的次数多是好的。但也确实出现了一些分类错误的情况,比如分类器甚至没有将任何一个样本类别预测为 5。
9. 精确度和召回率
scala> metrics.accuracy
res8: Double = 0.6999896726221212
scala> metrics.recall
res11: Double = 0.6999896726221212
准确度(accuracy)是二分类问题中一个常用的指标。二分类问题中的目标类别只有两个可能的取值,一个类代表正,另一类代表负,精确度就是被标记为“正”而且确实是“正”的样本占所有标记为“正”的样本的比例。
召回率:指被分类器标注为“正”而且确实为“正”的样本与所有本来就是“正”的样本比率。
比如:假设数据集有50 个样本,其中20 个为正。分类器将50 个样本中的10 个标记为正,在这10个被标记为“正”的样本中,只有4个确实是“正”(也就是 4 个分类正确)。所以这里的精确度是 4/10 = 0.4,召回率就是 4/20 = 0.2
我们可以把这些概念应用到多元分类问题,把每个类别单独视为“正”,所有其他类型视为“负”。比如,要计算每个类别相对其他类别的精确度:
scala> (0 until 7).map(
cat => (metrics.precision(cat), metrics.recall(cat))
).foreach(println)
(0.6788908765652951,0.6820697157451638)
(0.7291392037964671,0.7824656952892912)
(0.6353476821192053,0.8565848214285714)
(0.35185185185185186,0.42379182156133827)
(1.0,0.009)
(0.0,0.0)
(0.6896807720861173,0.44641999038923597)
可以看到每个类型的准确度都各不相同。就本例而言,我们没道理认为某个类型的准确度要比其他类型的准确度更重要,因此用一个多元分类的总体精确度就可以较好地度量分类准确度。
10. 决策树的超参数
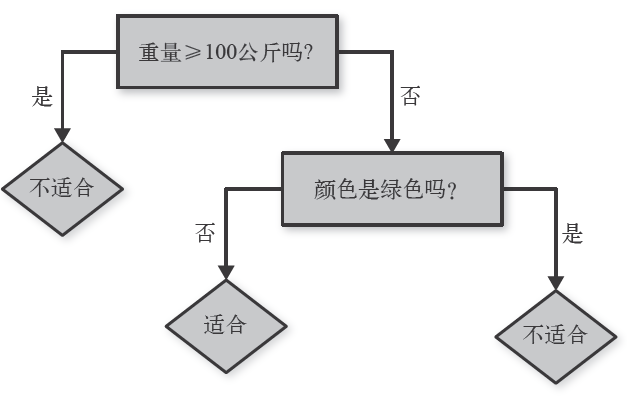
控制决策树选择过程的超参数为最大深度、最大桶数和不纯性度量。
最大深度:对决策树的层数作出限制,它是分类器为了对样本进行分类所做的一连串判断的最大次数。限制判断次数有利于避免对训练数据产生过拟合。
决策树算法负责为每层生成可能的决策规则。对数值型特征,采用特征大于等于等形式;对类别型特征,决策采用特征在(值1,值2,…)中的形式。Spark Mllib 的实现把决策规则集合称为“桶”(bin)。桶的数目越多,需要处理的时间越多但找到的决策规则可能最优。
11. 不纯度
在决策树中,好的规则把训练数据的目标值分为相对是同类或“纯”(pure)的子集。选择最好的规则也就意味着最小化规则对应的两个子集的不纯性(impurity)。
不纯性有两种常用的度量方式:Gini 不纯度、熵
Gini不纯度:
Gini 不纯度直接和随机猜测分类器的准确度相关。在每个子集中,它就是对一个随机挑选的样本进行随机分类时分类错误的概率(随机挑选样本和随机分类时要参照子数据集的类别分布)。
也就是 1 减去每个类别的比例与自身的乘积之和。假设子数据集包含 N 个类别的样本,pi 是类别 I 的样本所占的比例,于是可以得到如下 Gini 不纯度公式:
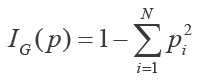
如果子数据集中所有的样本都属于一个类别,则 Gini 不纯度的值为 0,因为这个子数据集完全是纯的。当子数据集中的样本来自 N 个不同的类别时,Gini 不纯度的值大于 0,并且是在每个类别的样本数都相同时达到最大,也就是最不纯的情况。
信息熵:
熵代表了子集中目标取值集合的不确定程度。如果子集只包含一个类别,则是完全确定的,熵为 0。
熵可以用以下熵计算公式定义:
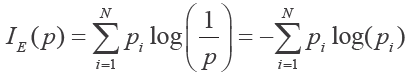
不确定性是有单位的。由于取自然对数(以 e 为底),熵的单位是纳特(nat)。相对于以 e 为底的纳特,我们更熟悉它对应的比特(以 2 为底取对数即可得到)。它实际上度量的信息,因此在使用熵的决策树中,我们也常说决策规则的信息增益。
不同的数据集上对于挑选好的决策规则方面,这两个度量指标各有千秋。Spark 的实现默认采用 Gini 不纯度。
12. 决策树的调优
采用哪个不纯性度量所得到的决策树的准确度更高,或者最大深度或桶数取多少合适,从数据上看,回答这些问题是困难的。
不过我们可以让Spark 来尝试这些值的许多组合并报告结果:
val evaluations = for (impurity <- Array("gini", "entropy");
depth <- Array(1, 20);
bins <- Array(10, 300))
yield {
val model = DecisionTree.trainClassifier(
trainData, 7, Map[Int, Int](), impurity, depth, bins)
val predictionsAndLabels = cvData.map(example =>
(model.predict(example.features), example.label))
val accuracy = new MulticlassMetrics(predictionsAndLabels).accuracy
((impurity, depth, bins), accuracy)
}
scala> evaluations.sortBy(_._2).reverse.foreach(println)
((entropy,20,300),0.9098076857152652)
((gini,20,300),0.9050083987521854)
((entropy,20,10),0.8989921497377532)
((gini,20,10),0.8900106269925611)
((gini,1,10),0.6373967296287408)
((gini,1,300),0.6361454869562236)
((entropy,1,300),0.4895101299235542)
((entropy,1,10),0.4895101299235542)
通过比较最后的准确率,可以发现从这些组合中,最优的为:entropy,20,300
从上面的结果可以看到:
- 最大深度为1 太小,得到的结果比较差
- 增加桶数帮助并不大
- 两种不纯性度量的效果差不多
- 增加最大深度效果比较好(一般最大深度会有拐点,超过此点,即使再增加,也不会有太大用处)
到目前为止,我们用到的只是 train data 和 cv data,一直没用到 test data。
如果说 cv 集的目的是为了评估适合训练集的参数,那么测试集的目的是评估适合 cv 集的超参数。也就是说,测试集保证了对最终选定的超参数及模型准确度的无偏估计。
到目前为止,超参数的最佳选择是:entropy,20,300。精准度为91%。
cv集只是帮助了我们选择这些超参数,但是最重要的是,我们要评估的是这个最佳模型在将来的样本上的表现,也就是 test 集上的表现。
最后,我们将cv 集加入到训练集,并使用之前获得的最佳超参数:
val model = DecisionTree.trainClassifier(trainData.union(cvData), 7, Map[Int, Int](), "entropy", 20, 300)
最终对 test 集上的正确率为:91.6%
13. Map[Int, Int]()
这个 Map 中元素的键是特征在输入向量 Vector 中的下标,Map 元素中的值是类别型特征的不同取值个数。
参数取为空 Map(),则表示算法不需要把任何特征作为类别型,也就是说,所有的特征都是数值型。
上面的例子里没有类别型变量,因为数据集对部分特征已经做了one-hot 编码。但是对树模型并不友好,且会消耗更多的内存并减慢决策速度。
如果我们不使用 one-hot 编码?
val data = rawData.map{ line =>
val values = line.split(',').map(_.toDouble)
val wilderness = values.slice(10, 14).indexOf(1.0).toDouble
val soil = values.slice(14, 54).indexOf(1.0).toDouble
val featureVector = Vectors.dense(values.slice(0, 10) :+ wilderness :+ soil)
val label = values.last - 1
LabeledPoint(label, featureVector)
}
val Array(trainData, cvData, testData) = data.randomSplit(Array(0.8, 0.1, 0.1))
trainData.cache
cvData.cache
testData.cache
val evaluations =
for (impurity <- Array("gini", "entropy");
depth <- Array(10, 20, 30);
bins <- Array(40, 300))
yield {
val model = DecisionTree.trainClassifier(trainData, 7, Map(10 -> 4, 11 -> 40), impurity, depth, bins)
val trainAccuracy = getMetrics(model, trainData).accuracy
val cvAccuracy = getMetrics(model, cvData).accuracy
((impurity, depth, bins), (trainAccuracy, cvAccuracy))
}
scala> evaluations.sortBy(_._2._2).reverse.foreach(println)
((entropy,30,300),(0.9998000644953241,0.9417916609329847))
((entropy,30,40),(0.9995463828872406,0.9369925691482042))
((gini,30,300),(0.9995098355369235,0.9352380624741984))
((gini,30,40),(0.99941309255079,0.9337415714875464))
((entropy,20,300),(0.9728474685585295,0.9272051740745837))
((gini,20,300),(0.9701451144792003,0.9239025732764552))
((entropy,20,40),(0.9692787272922713,0.9225264896105683))
((gini,20,40),(0.9684488874556595,0.9207719829365626))
((gini,10,300),(0.7954552294958616,0.7914545204348424))
((gini,10,40),(0.7891389874234118,0.78765308930783))
((entropy,10,40),(0.7802816295818553,0.7756639603687904))
((entropy,10,300),(0.7808642373427926,0.7754919499105546))
从上面的结果可以看到:
- 深度为30时,准确率最高
- 在使用类别型变量后,准确率得到提升
14. 随机森林
在决策树的每层,算法并不会考虑所有可能的决策规则,因为这会让算法的运行时间长到无法想象。
决策树会使用一些启发式策略,找到需要实际考虑的少数规则。在选择规则的过程中也涉及一些随机性;每次只考虑随机选择少数特征,而且只考虑训练数据中一个随机子集。在牺牲一些准确度的同时换回了速度的大幅提升,但也意味着每次决策树算法构造的树都不同。
团体智慧比个体预测要准确:
考虑一个场景,猜测一下一个外卖多少钱?
假设正确答案是26,我猜测是20,稍微有些偏差。
而如果我问一下办公室里所有同事,然后取平均值,结果会更接近一个准确值。
但是这基于一个条件:就是所有猜测都相互独立。任何两个人之间都没有信息交互,如果有了交互,可能会影响一个人的预测。
基于上述考虑,最好树不止有一棵,而是很多棵,每一棵都能对正确目标值给出合理、独立且互不相同的估计。这些树的集体平均预测应该比任一个体预测更接近正确答案。正式由于决策树构建过程中的随机性,才有了这种独立性,这就是随机森林的关键所在。
val forest = RandomForest.trainClassifier(trainData, 7, Map(10 -> 4, 11 -> 40), 20, "auto", "entropy", 30, 300)
这里多了两个参数:
第一个代表构建多少棵树,这里是 20。所以它构建的时间会较长。
第二个是特征决策树每层的评估特征选择策略,这里设置为“auto”。随机森林在实现过程中决策规则不会考虑全部特征,而只考虑全部特征的一个子集。所以这个参数是控制算法如何选择该特征子集。只检查少数特征速度明显要更快,并且由于速度快,随机森林才得以构造多棵决策树。
在构造随机森林的时候,每棵树没必要用到全部训练数据,同时,每棵树的输入数据可以随机选择。
随机森林的预测只是所有决策树预测的加权平均。对于类别型目标,这就是得票最多的类别,或有决策树概率平均后的最大可能值。随机森林和决策树一样也支持回归问题,这时森林做出的预测就是每颗树预测值的平均。
15. 预测
scala> val predictionAndLabels = testData.map( example =>
(forest.predict(example.features), example.label)
val accuracy = new MulticlassMetrics(predictionAndLabels).accuracy
accuracy: Double = 0.9633613969441845