##############总结##########
数据库中专门帮助用户快速找到数据的一种数据结构
类似于字典的目录的索引
索引的作用:约束和加速查找
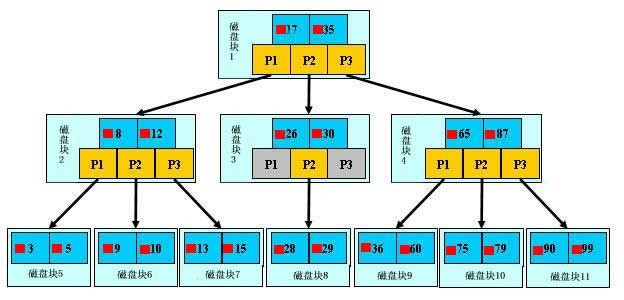
工作原理: b+树形结构 最上层是树根,中间是树枝,最下面是叶子节点(真实数据)
先找根节点: 存枝节点 索引的空间位子 : 然后根据枝节点的空间位子,来找叶子节点的真实数据
常见的几种索引:
普通索引
唯一索引
主键索引
联合索引(多列)
-联合主键索引
-联合唯一索引
-联合普通索引
无索引:从前往后一条一条查询
有索引:创建索引的本质,就是创建额外的文件(某种格式存储,查询的时候,先去格外的文件找,定好位置,然后再去原始表中直接查询,但是创建索引越多对磁盘也有消耗)
建立索引的目的:
a.额外的文件保存特殊的数据结构
b.查询快,但是插入更新删除依然慢
c.创建索引之后,唏嘘命中索引才能有效
#索引的种类
hash索引和btree索引 (1)hash类型的索引:查询单条快,范围查询慢 (2)btree类型的索引,b+树,层数越多,数据量指数级增长(innodb默认支持它)
1.主键索引(聚合索引)
#主键索引 create table t1(
id int primary key
)
create table t1(
id int
primary key(id)
) #主键索引 alter table 表名 add primary key(列名); #删除主键索引 alter table 表名 drop primary key;
2.唯一索引
#创建表 & 唯一索引 create table userinfo( id int primary key auto_increment, name char(30) not null, unique key ix_name(name) ) #唯一索引 alter table userinfo add unique 索引名字(name); #删除唯一索引 alter table 表名字 drop index 索引名字
3.普通索引(辅助索引)
#创建表 & 普通索引
create table userinfo(
id int not null auto_increment primary key,
name varchar(32) not null,
index ix_name(name)
)
#普通索引
alter table 表名 add index 索引名字(name) 或者 create index 索引名字 on 表名(name)
#删除索引
alter table 表名 drop index 索引名字
#查看索引
show index from 表名
4.组合索引
组合索引是将 n个列组合 合成一个索引
其应用场景为:频繁的同时使用n列来进行查询,如:where name = 'alex' and email = 'alex@qq.com'。
#联合普通索引 create index 索引名 on 表名(列名1,列名2);
最左前缀匹配: create index ix_name_email on user(name,email); select * from userinfo where name = 'alex'; select * from userinfo where name = 'alex' and email='alex@oldBody'; select * from userinfo where email='alex@oldBody'; 如果使用组合索引如上,name和email组合索引之后,查询 (1)name和email ---使用索引 (2)name ---使用索引 (3)email ---不适用索引 对于同时搜索n个条件时,组合索引的性能好于多个单列索引
索引注意点
注意点: 1.条件1 and 条件2:所有条件都成立才算成立,但凡要有一个条件不成立则最终结果不成立 这个mysql做了优化 查询的时候 只要其中有一条有索引,就会走索引 2.条件1 or 条件2:只要有一个条件成立则最终结果就成立,这个未做优化 3.加完索引后 只要带加索引的那一列才会起到加速作用 4.用四则运算条件的时候 把计算写后面 where id = 3000/3; 不能写成id*3=3000 5.like 这类语法的时候 尽量精准 能匹配多少算多少
优化神器 explain
explain显示了mysql如何使用索引来处理select语句以及连接表。可以帮助选择更好的索引和写出更优化的查询语句。
mysql> explain select id from s1 where id=1000; #在辅助索引中就找到了全部信息,Using index代表覆盖索引 +----+-------------+-------+------------+------+---------------+--------+---------+-------+------+----------+-------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+------+---------------+--------+---------+-------+------+----------+-------------+ | 1 | SIMPLE | s1 | NULL | ref | idx_id | idx_id | 4 | const | 1 | 100.00 | Using index | +----+-------------+-------+------------+------+---------------+--------+---------+-------+------+----------+-------------+ 1 row in set, 1 warning (0.03 sec)
#主要查看 rows 影响的行
详情看 这里 http://www.cnblogs.com/yycc/p/7338894.html
慢查询优化的基本步骤
慢日志 - 执行时间 > 10 - 未命中索引 - 日志文件路径 my.conf 内容
slow_query_log = ON slow_query_log_file = d:/...
show variables like '%query%';
注意:修改配置文件之后,需要重启服务
MySQL 5.6: slow-query-log=1 slow-query-log-file=slow.log long_query_time=37