20/04/28 19:40:00 ERROR JobScheduler: Error generating jobs for time 1588074000000 ms java.lang.IllegalArgumentException: requirement failed: numRecords must not be negative at scala.Predef$.require(Predef.scala:224) at org.apache.spark.streaming.scheduler.StreamInputInfo.<init>(InputInfoTracker.scala:38) at org.apache.spark.streaming.kafka010.DirectKafkaInputDStream.compute(DirectKafkaInputDStream.scala:233) at org.apache.spark.streaming.dstream.DStream$$anonfun$getOrCompute$1$$anonfun$1$$anonfun$apply$7.apply(DStream.scala:342) at org.apache.spark.streaming.dstream.DStream$$anonfun$getOrCompute$1$$anonfun$1$$anonfun$apply$7.apply(DStream.scala:342) at scala.util.DynamicVariable.withValue(DynamicVariable.scala:58) at org.apache.spark.streaming.dstream.DStream$$anonfun$getOrCompute$1$$anonfun$1.apply(DStream.scala:341) at org.apache.spark.streaming.dstream.DStream$$anonfun$getOrCompute$1$$anonfun$1.apply(DStream.scala:341) at org.apache.spark.streaming.dstream.DStream.createRDDWithLocalProperties(DStream.scala:416) at org.apache.spark.streaming.dstream.DStream$$anonfun$getOrCompute$1.apply(DStream.scala:336) at org.apache.spark.streaming.dstream.DStream$$anonfun$getOrCompute$1.apply(DStream.scala:334) at scala.Option.orElse(Option.scala:289) at org.apache.spark.streaming.dstream.DStream.getOrCompute(DStream.scala:331) at org.apache.spark.streaming.dstream.TransformedDStream$$anonfun$6.apply(TransformedDStream.scala:42) at org.apache.spark.streaming.dstream.TransformedDStream$$anonfun$6.apply(TransformedDStream.scala:42) at scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:234) at scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:234) at scala.collection.immutable.List.foreach(List.scala:381) at scala.collection.TraversableLike$class.map(TraversableLike.scala:234) at scala.collection.immutable.List.map(List.scala:285) at org.apache.spark.streaming.dstream.TransformedDStream.compute(TransformedDStream.scala:42) at org.apache.spark.streaming.dstream.DStream$$anonfun$getOrCompute$1$$anonfun$1$$anonfun$apply$7.apply(DStream.scala:342) at org.apache.spark.streaming.dstream.DStream$$anonfun$getOrCompute$1$$anonfun$1$$anonfun$apply$7.apply(DStream.scala:342) at scala.util.DynamicVariable.withValue(DynamicVariable.scala:58) at org.apache.spark.streaming.dstream.DStream$$anonfun$getOrCompute$1$$anonfun$1.apply(DStream.scala:341) at org.apache.spark.streaming.dstream.DStream$$anonfun$getOrCompute$1$$anonfun$1.apply(DStream.scala:341)
Spark streaming2.2.0 + kafka_2.11_0.10.0.1
设置 enable.auto.commit 为 false,通过ZK手动维护offset,程序正常运行,分别通过zkClint和kafka脚本查看偏移量,发现kafka中偏移量确实没有提交,zk中每个批次正常提交,程序stop,然后再次启动报上图错误。
异常原因:
定位代码:
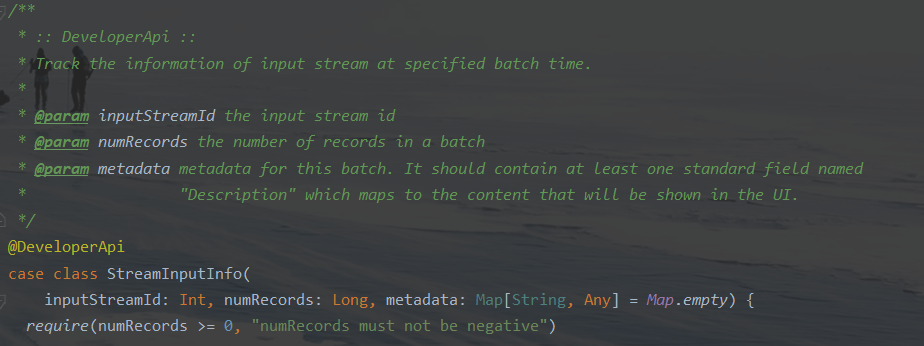
此处判断了numRecords>=0,否则会抛出异常

rdd.count的逻辑


fromOffset来自zk中保存;
untilOffset通过DirectKafkaInputDStream第211行

计算得到最新的offset,然后使用spark.streaming.kafka.maxRatePerPartition做clamp,得到允许的最大untilOffsets,而此时kafka中offset并没有提交,偏移量小于zk中的偏移量,导致计算的numRecords为负数。
解决办法:
手动设置zk中偏移量和kafka中相同,并且在kafka异步提交偏移量。