爬虫框架的基础和运行流程
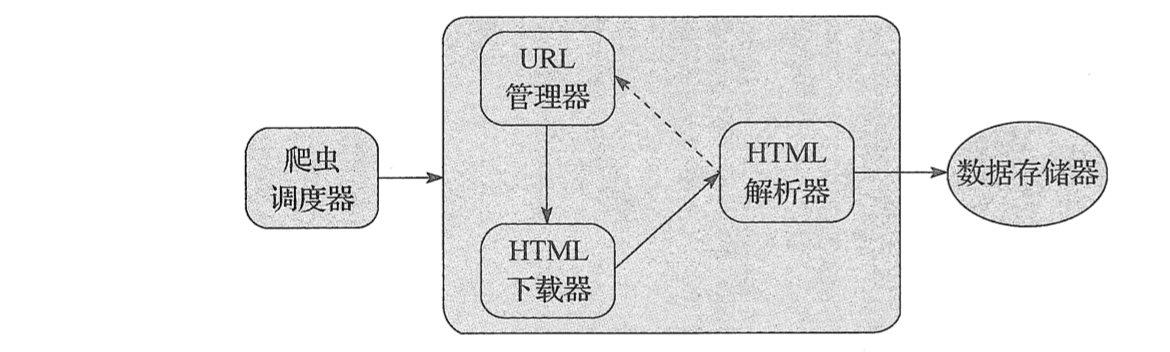
基本的框架流程
基础爬虫框架主要包括五大模块、分别为爬虫调度器、URL管理器、HTML下载器、HTML解析器、数据存储器。功能分析如下:
爬虫调度器主要负责统筹其他四个模块的协调工作。
URL管理器负责URL链接的管理,维护已经爬取的URL集合和未爬取的URL集合,提供获取新URL链接的接口。
HTML下载器用于从URL管理器中获取未爬取的URL链接并下载HTML网页。
HTML解析器用于从HTML下载器中获取已经下载的HTML页面,并从中解析出新的URL链接交给URL管理器,解析出有效数据交给数据存储器。
数据存储器用于将HTML解析器解析出来的数据通过文件或者数据库的形式存储起来。

运行流程
1.1URL管理器
URL管理器主要包括两个变量,一个是已爬取URL的集合,另一个是未爬取URL的集合。采用Python中的set类型,主要是使用set的去重复功能,防止链接重复爬取,因为爬取连接重复时容易造成死循环。链接去重复在Python爬虫开发中是必备的功能,解决方案主要有三种:
1.内存去重
2.关系数据库去重
3.缓存数据库去重
大型的成熟的爬虫基本上采用缓存数据库的去重方案,尽可能避免内存大小的限制,又比关系型数据库去重性能高很多。由于基础爬虫的爬取数量较小,因此我们可以使用Python中set这个内存去重方式。
URL管理器除了具有两个URL集合,还需要提供一下接口,用于配合其他模块使用,接口如下:
判断是否有待取的URL,方法定义为has_new_url()。
添加新的URL到未爬取集合中,方法定义为add_new_url(url),add_new_urls(urls)。
获取一个未爬取的URL,方法定义为get_new_url()。
获取未爬取URL集合的大小,方法定义为new_url_size()。
获取已经爬取的URL集合的大小,方法定义为old_url_size()


1.2 HTML下载器
HTML下载器用来下载网页,这时候需要注意网页的编码,以保证下载的网页没有乱码。
下载器需要用到Requests模块,里面只需要实现一个接口即可:download(url)。


1.3 HTML解析器
这里使用的是BeautifulSoup4进行HTML解析。需要解析的部分主要分为提取相关词条页面的URL和提取当前词条的标题和摘要信息。


