新型冠状病毒来袭,在此全国人民齐心抗疫之际,身为软件工程专业的一员,也要充分发挥专业能力,为疫情做点什么。
到目前为止,很多网站或者APP都新增了疫情数据分析这样一个栏目,这样一个专栏帮助用户充分了解全国各地乃至全世界的疫情情况,今天就特地做了这样的一个实战项目,来实现疫情数据的实时可视化。
首先,设计思路如下:
(1)使用爬虫爬取网站中的数据并存入数据库
(2)使用java做后端将数据库的内容传送到前端
(3)前端使用echarts框架对数据进行可视化
在爬取数据的时候,还是经历了一些小插曲,我爬取的网站如下:
https://news.qq.com/zt2020/page/feiyan.htm#/
首先就是按照爬虫套路查看网页源代码,可以看到效果如下:
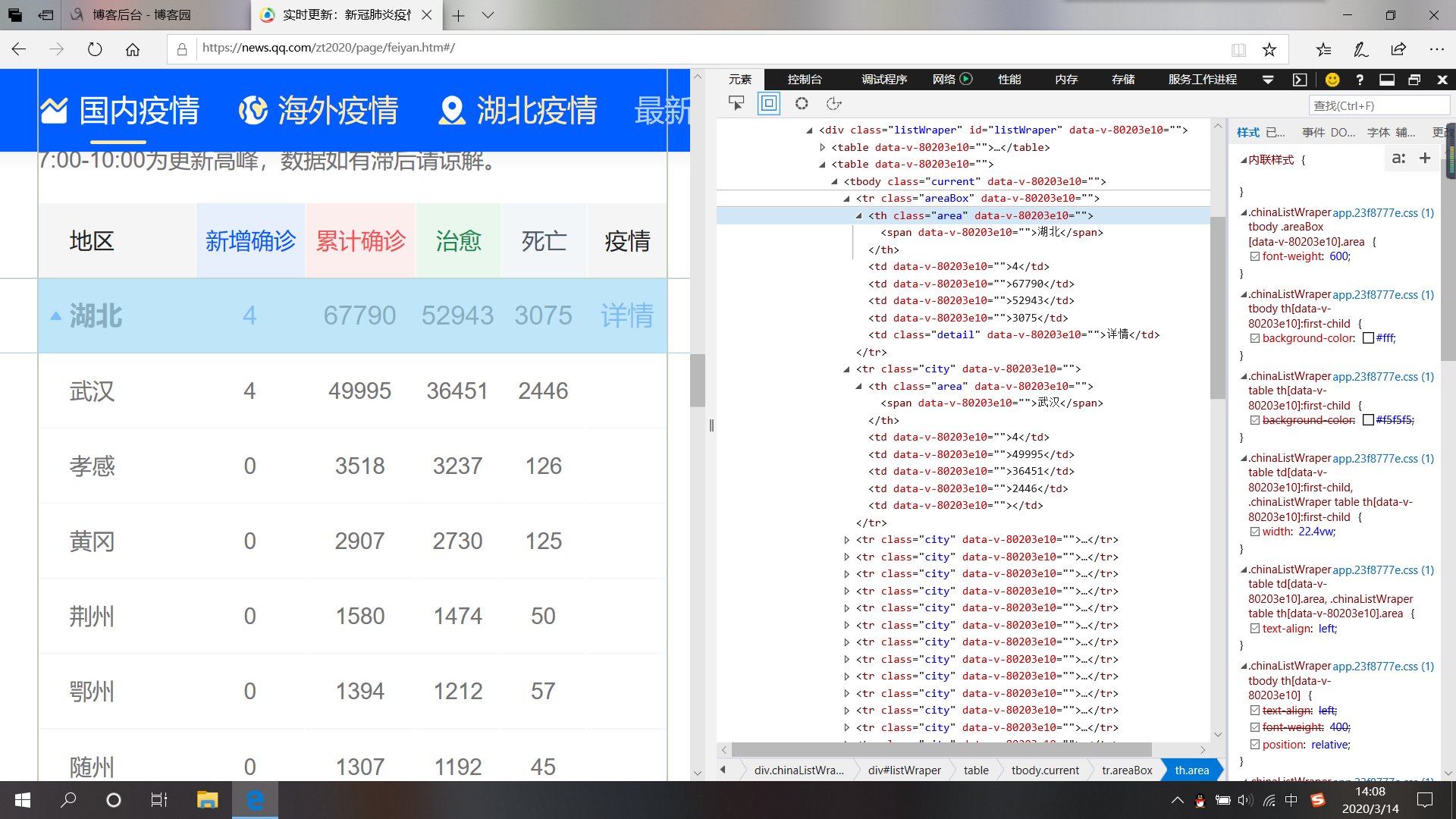
很容易发现,class为areaBox的 tr 标签中保存的是各省的数据,其中的area为省份名称,其余不包含class的 td保存的是疫情的各项人数,而class为 city 的tr中保存的是各个城市的数据,其中,area为城市名称,其余td保存的疫情各项的人数。
在这样的简单分析之后,顿时感觉这实在是太小儿科了,两个嵌套for循环就可以搞定,于是开始编写爬虫,初始测试爬虫代码如下:
import requests from bs4 import BeautifulSoup url = "https://news.qq.com/zt2020/page/feiyan.htm#/" r = requests.get(url) html = r.text soup = BeautifulSoup(html,"lxml") print(soup.prettify())
运行之后,打印数据是这样的
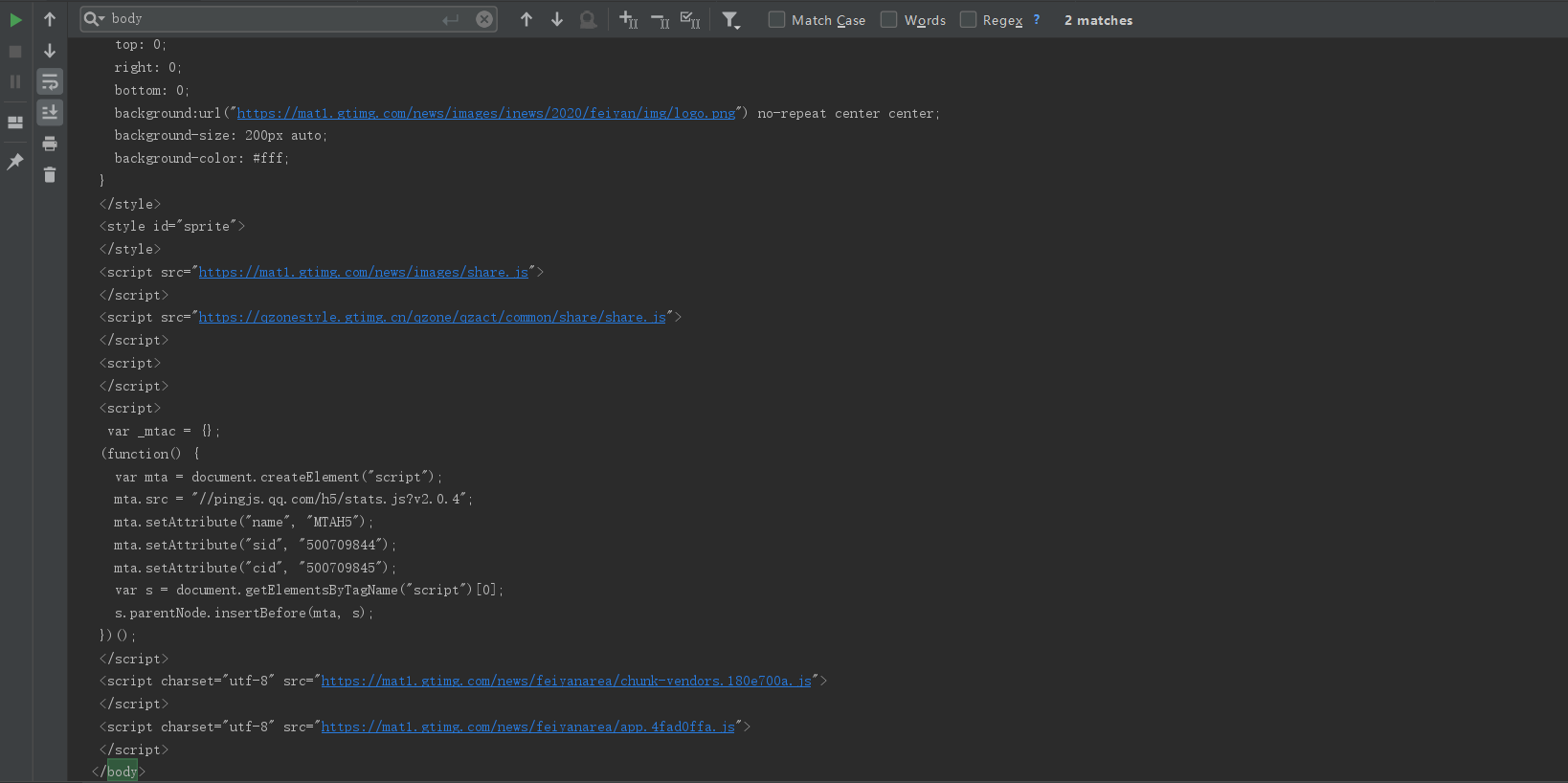
只有一坨 js 代码还有页面头部的几个div,并没有找到我们想要的标签。迟疑了一瞬间,恍然醒悟数据应该是通过js发送请求之后从后台传回来的。直接看这一段HTML代码,果然什么都看不出来。没办法,F12去浏览器控制台看看到底发生了什么数据交换的操作吧。(微软的浏览器用的有点鸡肋,这里切一下Chrome)可以看到服务器返回了这些数据:
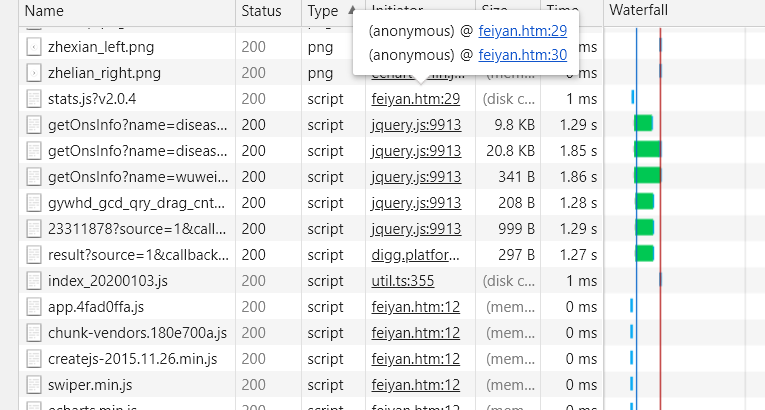
可以看到除了无关紧要的png图片等资源,还返回了这样一堆js文件,一看名字,这些get***Info可能就是我们需要的,检查一下它的地址,然后复制打开


瞬间激动了有木有!!这不就是现成的json数据么,还分析个球的HTML标签,直接爬起来!!!
(激动过头了)先分析一下json的格式和我们需要的“树”,首先可以看到开头有个name 中国的字样,由于该网站支持其他国家的数据,如下:
所以我们解析json的时候就要通过它来筛选本国的数据,那么,在中国下面,又有这样一些数据:
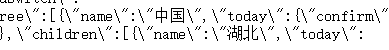
很显然,在name的子数据中,key为children的数据就是对应的各省份的数据(其他省份格式相同,不再给出截图),与此同时,在省份下面的各个城市,同样是以children标签保存数据的
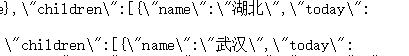
![]()
以武汉为例,today中是今日新增的确诊,total中是截止到目前的总人数,也是我们需要的数据,简单翻译可知,confirm为确诊人数,dead为死亡人数,heal为治愈人数,那么数据的更新时间在哪儿呢?json开头我们可以看到这样的字样:
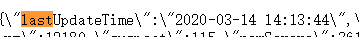
在该文件的其余地方均没有类似时间字样的key,不难推断出,它就是最新的数据更新时间。
OK,到此为止,分析完成,代码搞起来!
import requests import json from pymysql import * #连接数据库的方法 def connectDB(): try: db=connect(host='localhost',port=3306,user='root',password='010218',db='payiqing_db') print("数据库连接成功") return db except Exception as e: print(e) return NULL db=connectDB() #向数据库中插入数据的方法 def insertInformation(db,table,Date,Province,City,Confirmed_num,Yisi_num,Cured_num,Dead_num,Code): cursor=db.cursor() try: cursor.execute("insert into %s(Date,Province,City,Confirmed_num,Yisi_num,Cured_num,Dead_num,Code) values('%s','%s','%s','%s','%s','%s','%s','%s')" % (table,Date,Province,City,Confirmed_num,Yisi_num,Cured_num,Dead_num,Code)) print("插入成功") db.commit() cursor.close() return True except Exception as e: print(e) db.rollback() return False def queryInformation(city): cursor = db.cursor() sql = "SELECT * FROM info WHERE City = '%s'" % (city) try: # print(sql) # 执行SQL语句 cursor.execute(sql) # 获取所有记录列表 results = cursor.fetchone() return results[-1] except Exception as e: print(e) db.rollback() def clearTable(date): cursor = db.cursor() sql="delete from info2 where Date = '%s'"% (date) try: print(sql) # 执行SQL语句 cursor.execute(sql) except Exception as e: print(e) db.rollback() def get_data(): url = 'https://view.inews.qq.com/g2/getOnsInfo?name=disease_h5' json_text = requests.get(url).json() data = json.loads(json_text['data']) update_time = data['lastUpdateTime'] all_counties = data['areaTree'] all_list = [] for country_data in all_counties: if country_data['name'] == '中国': all_provinces = country_data['children'] for province_data in all_provinces: province_name = province_data['name'] all_cities = province_data['children'] for city_data in all_cities: city_name = city_data['name'] city_total = city_data['total'] province_result = {'province': province_name, 'city': city_name,'update_time': update_time} province_result.update(city_total) all_list.append(province_result) clearTable(all_list[0].get("update_time")) for info in all_list: print(info) insertInformation(db,"info2",info.get("update_time"),info.get("province"),info.get("city"),info.get("confirm"),info.get("suspect"),info.get("heal"),info.get("dead"),queryInformation(info.get("city"))) if __name__ == '__main__': get_data()
以上代码包含数据库的更新,读者可根据自己数据库的配置自行修改。
然后就是数据可视化了,这里只给出截图吧,完整代码后续会上传到我的GitHub中。
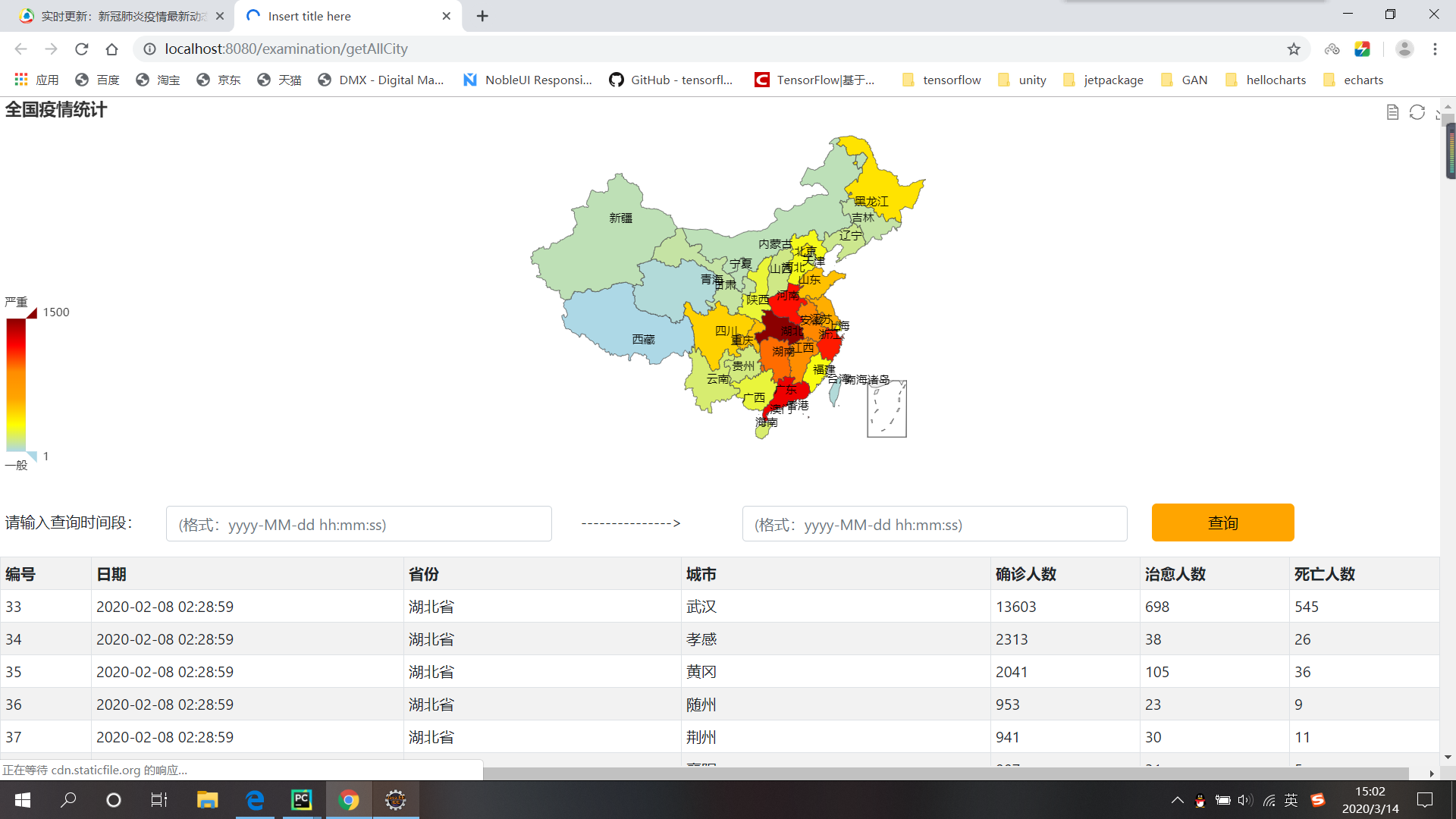
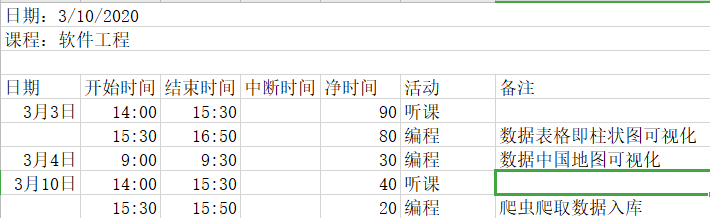
最后,附上实现本次项目的PSP表格