InnoDB主要数据结构及调用流程
- InnoDB是MySQL中常用的数据引擎。本文将从源码级别对InnoDB重点数据结构和调用流程进行分析。
- 主要数据结构(buf0buf.h)
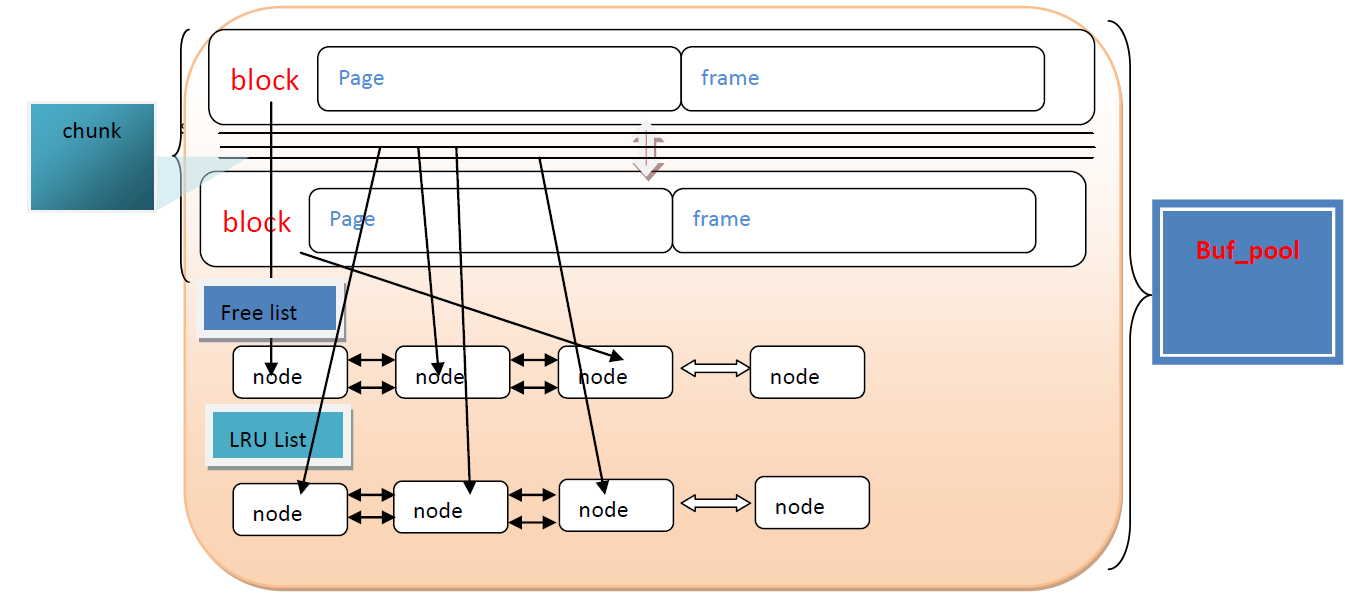
- Buf_pool

Buf_pool是整个buffer系统中核心数据结构,数据库中所有的操作都会在这缓冲层得到体现。我们可以在配置文件中(InnoDB_buffer_pool_size)指定该缓冲池的大小。
Buffer pool中又包含了多层数据结构:为了实现对buffer_pool的在线大小调整,引入了chunk数据结构;
- Chunk

在chunk数据结构是更具体的内存缓存,主要包含控制内存块的block结构。
Block
Block主要的数据结构是page和frame,这两个结构是用来存储硬盘上的数据库page的。当硬盘存储未使用压缩时,数据会被读取到frame中;当使用压缩后,会存储到page.zip中。
Page结构必须要放在该结构体的第一个位置,方便以后使用指针时可以方便的在page和block间进行转换。
例如:(buf_page_t *) buf_block_t *p
可以得到一个类型为buf_page的指针
- Page

Page结构主要是存储硬盘上的文件,通过space和offset唯一对应到硬盘上的数据库文件;io_fix指出该page的类型(读或写);Zip存储压缩过的page。 - Buf_pool示意图
- Io_threads
在InnoDB内部,使用默认配置参数时,共有10个线程,其中:
4个read线程,4个write线程,负责进行异步的读写操作。
1个log write线程,负责将操作记录进日志文件
1个srv_master线程,负责定时写数据到磁盘等工作。
在InnoDB插件初始化时,会调用innobase_start_or_create_for_mysql,此函数将完成InnoDB存储引擎的初始化工作。创建io threads的部分在函数是os_thread_create(io_handler_thread, n + i, thread_ids + i)其中io_handler_thread是回调函数,主要是为每个后台线程分配任务for (i = 0;; i++) {
fil_aio_wait(segment);
mutex_enter(&ios_mutex);
ios++;
mutex_exit(&ios_mutex);
}
fil_aio_wait中起主要作用的是os_aio_simulated_handle,该函数根据线程在InnoDB中的编号进行模拟的异步IO设置。
segment = os_aio_get_array_and_local_segment(&array, global_segment);
Aio 与 sync aio
在mysql诞生时,Linux上还未出现AIO机制,于是InnoDB自己实现了一套异步io的框架。
关于Linux aio的介绍,AIO first entered the Linux kernel in 2.5 and is now a standard feature of 2.6 production kernels. http://www.ibm.com/developerworks/linux/library/l-async/
最近Innobase在innodb plugin中实现了真正的AIO机制。http://blogs.innodb.com/wp/2010/04/innodb-performance-aio-linux/ 我们会在以后的时间来介绍他。 - Arrays
- os_aio_read_array //异步读
- os_aio_write_array //异步写
- os_aio_ibuf_array //insert bufer
- os_aio_log_array //日志array
- os_aio_sync_array //同步io array
在InnoDB中引入了sync aio,目标是为了在代码级别上与aio的形式保持一致。

为了实现InnoDB的异步IO所引入的数组,系统中一共存在五类数组:
当出现IO请求时,异步机制会将此请求插入其中一个插槽(slot),并等待执行请求的信号;IO完毕,从该插槽中删除。
- os_aio_read_array //异步读
- Segment
在array中,segment被用作array的标识符,根据segment值可以得到array的种类。例如在默认的array数量下(4个read,4个write)3号表示read array
- Slot

存放异步读写请求的插槽。
- Buf_pool
- 调用流程
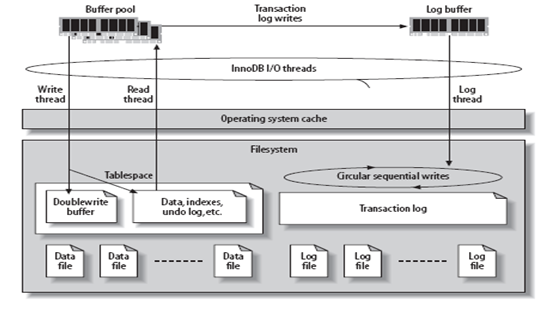
在InnoDB中,为了提高响应速度,有时需要立即返回数据,此时采用同步的读机制;而另一些对速度要求不是很高的情况下,例如预读取,InnoDB会采用异步读的方式来加载数据到内存。而在开启double write buffer写数据的情况下,InnoDB会先将数据写一遍到硬盘上某一块称之为double write buffer的区域,然后再在将来某时写到磁盘上,此时会根据系统的当前负载、当前内存中脏的页数有不同的延迟。
异步读写时等待请求:
当缓存块/文件读写完毕时,发出信号:fil_io() -> os_aio()->
os_aio_simulated_wake_handler_threads()->os_aio_simulated_wake_handler_thread->
os_event_set()->pthread_cond_broadcast()





